 [O]Superset版本适配改造(一)
[O]Superset版本适配改造(一)
# 背景说明
Superset v4 前端构建过程中,常见“国际化语言包缺失/格式不符/占位符不生效”等问题,且在国内开发环境还经常遭遇 node/npm 拉包极慢甚至失败。i18n补丁 如何高效修正 i18n 翻译与加速依赖下载,是二次开发和企业部署中不可忽视的适配点。
场景说明
适用于 Superset 前端自定义翻译、国产化改造、CI/CD 自动化构建等需要本地化和网络优化的实际环境。
# 第一步:前端 i18n 适配补丁
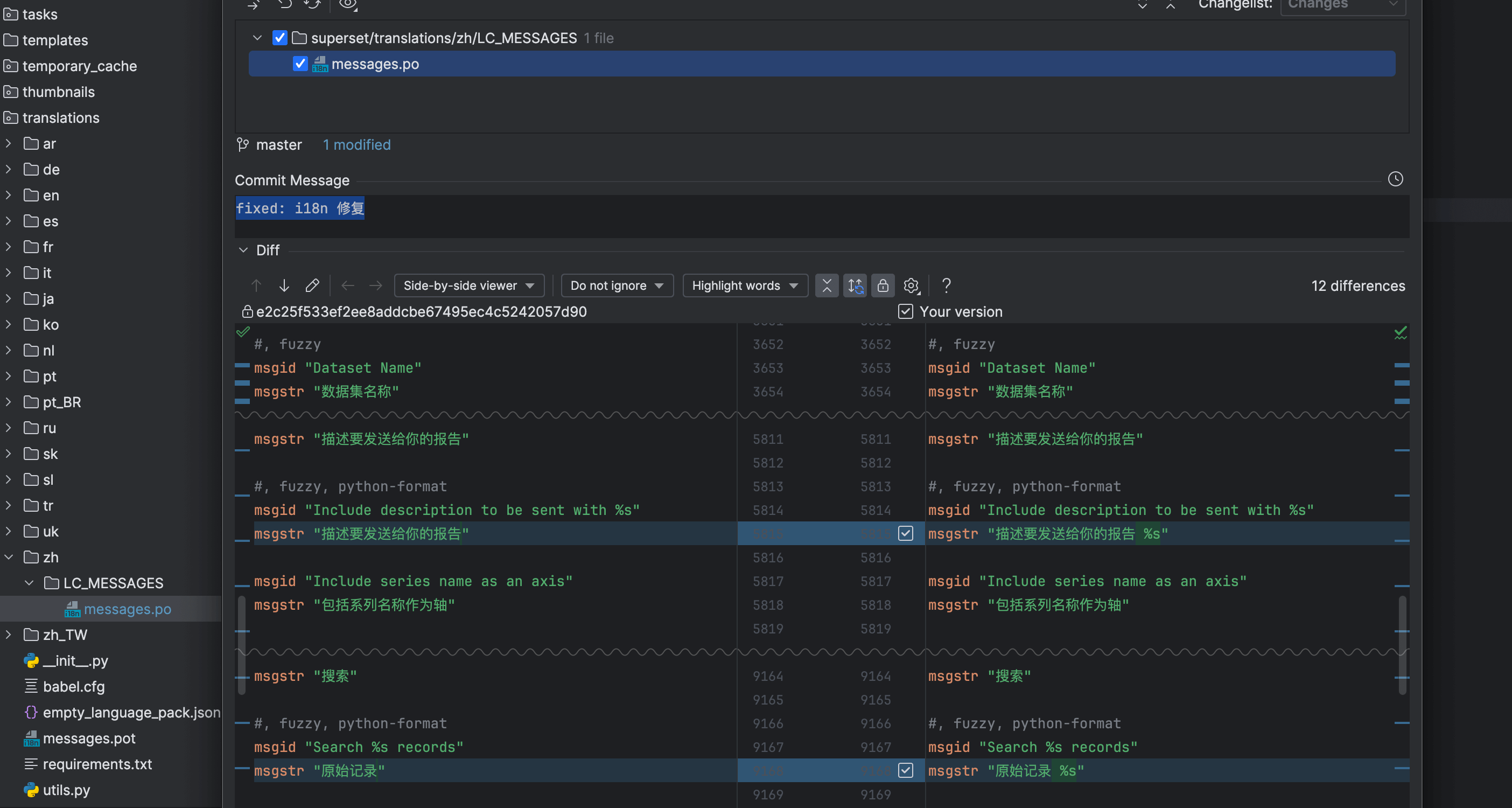
以 Superset 4.x 为例,部分 po 文件参数未格式化,容易导致翻译渲染缺失或文本错位,建议通过 patch 补丁修复。
典型的 i18n 补丁片段如下:
Subject: [PATCH] fixed: i18n 修复
---
Index: superset/translations/zh/LC_MESSAGES/messages.po
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/superset/translations/zh/LC_MESSAGES/messages.po b/superset/translations/zh/LC_MESSAGES/messages.po
--- a/superset/translations/zh/LC_MESSAGES/messages.po (revision e2c25f533ef2ee8addcbe67495ec4c5242057d90)
+++ b/superset/translations/zh/LC_MESSAGES/messages.po (date 1747980994507)
@@ -143,16 +143,16 @@
msgstr "不等于(!=)"
#, fuzzy, python-format
-msgid "% calculation"
-msgstr "% 计算"
+msgid "%s calculation"
+msgstr "%s 计算"
#, fuzzy, python-format
-msgid "% of parent"
-msgstr "父类"
+msgid "%s of parent"
+msgstr "%s 父类"
#, fuzzy, python-format
-msgid "% of total"
-msgstr "显示总计"
+msgid "%s of total"
+msgstr "%s 显示总计"
#, python-format
msgid "%(dialect)s cannot be used as a data source for security reasons."
@@ -309,7 +309,7 @@
#, fuzzy, python-format
msgid "%s recipients"
-msgstr "最近"
+msgstr "%s 最近"
#, fuzzy, python-format
msgid "%s row"
@@ -1618,7 +1618,7 @@
#, fuzzy, python-format
msgid "Applied filters (%s)"
-msgstr "应用的过滤器 (%d)"
+msgstr "应用的过滤器 (%s)"
#, fuzzy, python-format
msgid "Applied filters: %s"
@@ -3537,7 +3537,7 @@
#, fuzzy, python-format
msgid "Data for %s"
-msgstr "给JS的额外数据"
+msgstr "给%s的额外数据"
msgid "Data preview"
msgstr "数据预览"
@@ -3647,7 +3647,7 @@
#, fuzzy, python-format
msgid "Dataset %(table)s already exists"
-msgstr "数据集 %(name)s 已存在"
+msgstr "数据集 %(table)s 已存在"
#, fuzzy
msgid "Dataset Name"
@@ -5812,7 +5812,7 @@
#, fuzzy, python-format
msgid "Include description to be sent with %s"
-msgstr "描述要发送给你的报告"
+msgstr "描述要发送给你的报告 %s"
msgid "Include series name as an axis"
msgstr "包括系列名称作为轴"
@@ -9165,7 +9165,7 @@
#, fuzzy, python-format
msgid "Search %s records"
-msgstr "原始记录"
+msgstr "原始记录 %s"
msgid "Search / Filter"
msgstr "搜索 / 过滤"
@@ -9671,7 +9671,7 @@
#, fuzzy, python-format
msgid "Show %s entries"
-msgstr "显示指标"
+msgstr "显示指标 %s"
msgid "Show Bubbles"
msgstr "显示气泡"
@@ -10437,7 +10437,7 @@
msgid ""
"Table [%(table)s] could not be found, please double check your database "
"connection, schema, and table name"
-msgstr "找不到 [%(table_name)s] 表,请仔细检查您的数据库连接、Schema 和 表名"
+msgstr "找不到 [%(table)s] 表,请仔细检查您的数据库连接、Schema 和 表名"
msgid ""
"Table already exists. You can change your 'if table already exists' "
@@ -12685,7 +12685,7 @@
#, fuzzy, python-format
msgid "Waiting on %s"
-msgstr "显示 %s个 总计 %s个"
+msgstr "总计 %s个"
#, fuzzy
msgid "Waiting on database..."
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
笔记
如 % calculation → %s calculation 这种参数化占位符,是保证 Superset 数据分析界面和报表导出等场景下文本正确渲染的关键。补丁内容建议直接基于上游
po 文件修改,避免自定义开发误差。
# 补丁应用步骤
将上述 diff 片段保存为
superset-i18n.patch进入 Superset 源码目录,执行:
patch -p1 < superset-i18n.patch1重新构建前端资源,确认界面和报表多语言渲染正常。
注意
patch 匹配的 po 文件需确保和当前 Superset 版本完全一致,否则有可能出现未生效或语法报错。建议 patch 前先备份原始 po 文件。