 requiredServices详解[一]
requiredServices详解[一]
# 1. 引言与问题概述 🎯
# 1.1 背景介绍
在 Ambari 中,metainfo.xml
文件是描述服务元数据的核心配置文件,包含了服务的基本信息、版本、配置类型、组件列表以及服务之间的依赖关系等重要内容。其中,requiredServices
字段扮演着非常重要的角色,它用于指定一个服务所依赖的其他服务。通过 requiredServices,Ambari
能够自动管理服务之间的依赖关系,确保在安装某个服务时,其所有必要的依赖服务也被正确安装。
笔记
比如安装 Kafka,必须保证 ZooKeeper 先装好。Ambari 利用 requiredServices 自动校验依赖,帮你规避部署顺序和漏装风险。
例如,安装 Kafka 时,需要确保 ZooKeeper 已经安装并运行。metainfo.xml 文件中的 requiredServices 字段便能实现这一点。当我们安装
Kafka 时,Ambari 会自动检查是否安装了 ZooKeeper,如果没有,它会提示我们先安装
ZooKeeper。通过这种方式,Ambari大大简化了服务间的依赖管理,避免了手动追踪和配置服务依赖的繁琐工作。
然而,随着集群规模的增大和服务种类的增加,服务间的依赖关系变得越来越复杂。理解和正确使用 requiredServices
字段,能够帮助我们更高效地管理服务安装过程中的依赖问题。本文将深入探讨 requiredServices 字段的作用,以及它如何影响Ambari
中的服务安装和依赖管理。
# 1.2 目标
本文的目标是:
- 解析
metainfo.xml中requiredServices字段的作用:详细讲解requiredServices字段在metainfo.xml中的功能,分析它如何影响服务的依赖校验和安装过程。 - 通过源码讲解 Ambari 的依赖校验流程:通过分析 Ambari 源码,讲解
requiredServices如何在整个 Ambari 中参与服务依赖的校验、安装顺序的管理等过程。 - 帮助读者在自定义组件开发中使用
requiredServices:了解如何在自定义组件开发中利用requiredServices来管理服务间的依赖关系,提升服务部署的效率和可靠性。
# 2. 核心概念解析 🧠
# 2.1 requiredServices 字段详解
在 Ambari 中,requiredServices 字段用于定义一个服务所依赖的其他服务。它是 metainfo.xml 文件中的关键部分,帮助
Ambari 在安装和配置服务时自动检查服务之间的依赖关系。通过这个字段,Ambari 知道在安装某个服务时,是否需要先安装其他依赖服务。
# 2.1.1 作用
requiredServices 的作用非常简单而关键:确保服务的依赖关系得到正确处理。当你尝试安装某个服务时,Ambari
会检查该服务是否列出了任何依赖服务。如果有依赖服务,Ambari 会检查这些服务是否已正确安装,如果没有,系统将提示用户先安装这些依赖服务。
# 2.1.2 示例
例如,在安装 Flink 时,Flink 依赖于 Yarn。在 metainfo.xml 文件中,requiredServices 字段会指定 Yarn 作为
Flink 的依赖服务:
<requiredServices>
<service>YARN</service>
</requiredServices>
2
3
4
提示
实际效果就是 Ambari UI 能自动校验和提示缺失依赖。避免运维手动校对依赖表,降低出错概率。
当用户在 Ambari UI 中选择安装 Flink 时,Ambari 会自动检查 Yarn 是否已安装。如果 Yarn 没有安装,Ambari 会提示用户先安装 Yarn,并暂停 Flink 的安装,直到 Yarn 被安装并运行。

# 2.2 requiredServices 在安装流程中的作用
在 Ambari 的服务安装过程中,requiredServices 字段起到了非常重要的作用。它不仅帮助 Ambari 校验依赖服务是否安装,还能自动调整安装顺序。以下是
requiredServices 在安装过程中的关键作用:
- 自动校验依赖服务:在安装任何服务时,Ambari 会读取该服务的
metainfo.xml文件,检查是否列出了requiredServices。如果列出了依赖服务,Ambari 会自动检查这些服务是否已正确安装。 - 调整安装顺序:如果一个服务依赖于另一个服务,Ambari 会确保先安装被依赖的服务,然后再安装依赖该服务的服务。例如,安装 Flink 时,Ambari 会首先安装 Yarn,确保依赖关系满足后才会继续安装 Flink。
- 提供用户提示:如果缺少依赖服务,Ambari 会在 UI 中显示明确的错误提示,告知用户安装缺失的依赖服务,确保服务间的依赖关系得到解决。
# 2.3 依赖校验流程中的关键方法
Ambari 在处理 requiredServices 字段时,涉及多个方法的协作。这些方法确保了服务的依赖关系被正确校验,避免了服务安装过程中的错误。以下是一些关键方法:
serviceDependencyValidation:该方法负责验证所有已选择的服务是否满足依赖关系。如果某个服务的依赖未安装,方法会将缺失的依赖项记录到错误堆栈中。collectMissingDependencies:该方法遍历已选择的服务,收集所有缺失的依赖项,并将它们添加到错误堆栈中。_missingDependencies:该方法负责检查哪些服务的依赖项缺失,并返回缺失的依赖项列表。_addMissingDependency:一旦缺失的依赖被确认,该方法会将它们添加到missingDependencies数组中,并生成相关的错误提示,供用户修复。
笔记
这些方法保证了服务安装的自动依赖链路“环环相扣”。日常定制和排错必备。
# 3. 实操与代码解析 🔧
# 3.1 请求部分代码详解
# 3.1.1 请求的发起
首先,我们通过一个 curl 请求从 Ambari 获取堆栈服务的信息。该请求目标是查询指定堆栈(例如 BIGTOP/3.1.0
)的所有服务信息,包括组件、依赖、版本等。
curl 'http://centos1:8080/api/v1/stacks/BIGTOP/versions/3.1.0/services?fields=StackServices/*,components/*,components/dependencies/Dependencies/scope,components/dependencies/Dependencies/service_name,components/dependencies/Dependencies/type,artifacts/Artifacts/artifact_name&_=1732686583126' \
-H 'Accept: application/json, text/javascript, */*; q=0.01' \
-H 'Accept-Language: zh-CN,zh;q=0.9' \
-H 'Connection: keep-alive' \
-H 'Content-Type: text/plain' \
-H 'Cookie: AMBARISESSIONID=node01xovhqi7a1a1qhtl09nz93i002.node0' \
-H 'Referer: http://centos1:8080/' \
-H 'User-Agent: Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/103.0.5060.66 Safari/537.36' \
-H 'X-Requested-By: X-Requested-By' \
-H 'X-Requested-With: XMLHttpRequest' \
--compressed \
--insecure
2
3
4
5
6
7
8
9
10
11
12
# 3.1.2 定位到 getStackServices 方法
该请求首先会进入 src/main/java/org/apache/ambari/server/api/services/StacksService.java 文件中的 getStackServices
方法。这个方法会调用 handleRequest,这是请求处理的核心方法。getStackServices 会构建一个 ResourceInstance
,该实例指明了请求需要处理的资源类型:StackService。这个资源实例将作为后续处理的基础。

createStackServiceResource 创建了一个 ResourceInstance,通过该实例 Ambari 知道请求是关于 StackService 类型的资源。
# 3.1.3 handleRequest 方法解析
handleRequest 方法在 BaseService.java 文件中定义,它负责请求的处理流程。该方法会调用 RequestFactory.createRequest
来生成适合当前请求的 Request 实例。不同类型的请求(如 GET、POST、PUT、DELETE)都会调用相应的处理方法。
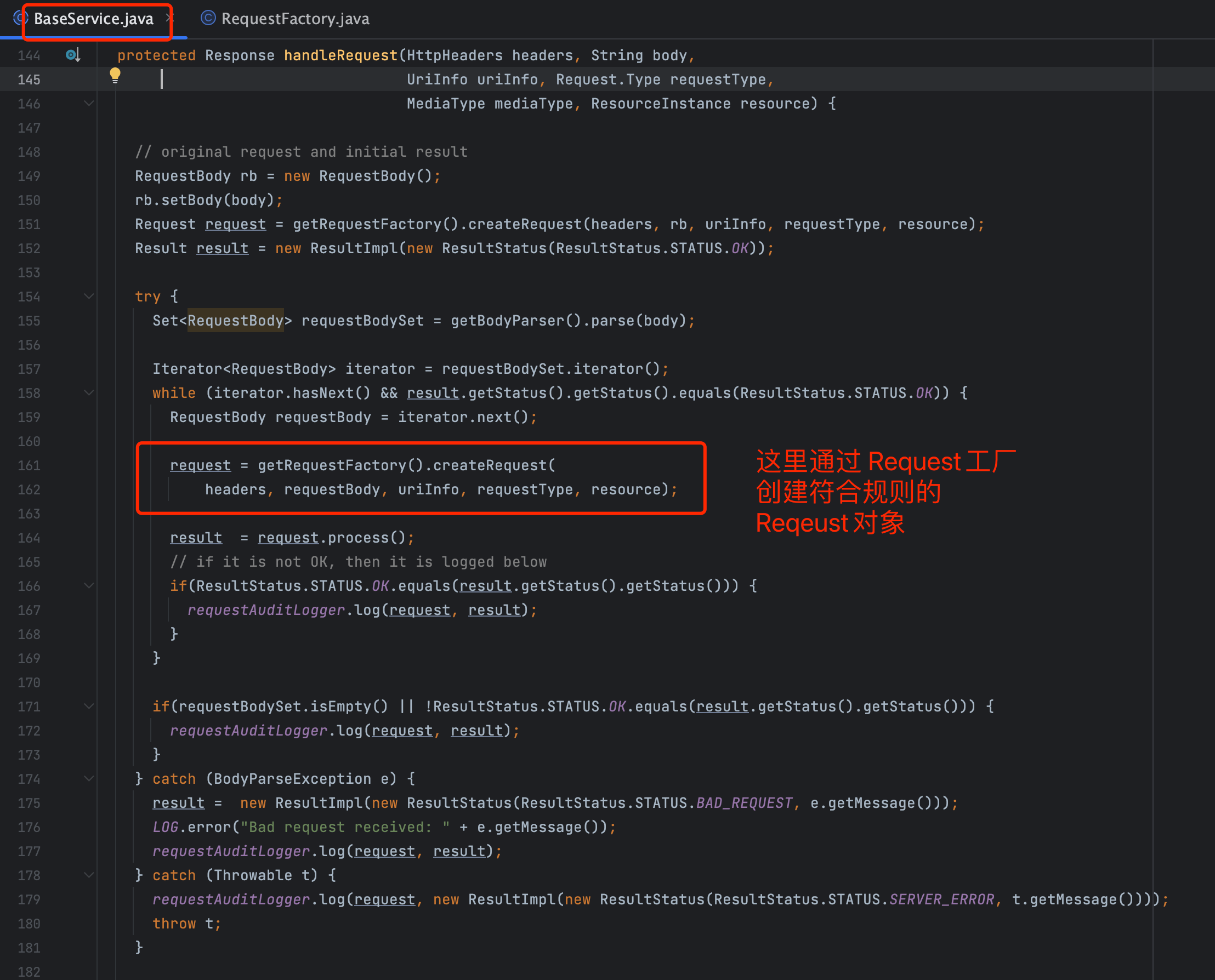
这里的核心是通过 getRequestFactory() 创建请求对象。根据不同的请求类型(例如 GET),会创建一个相应的请求实例。
# 3.1.4 RequestFactory 的角色
RequestFactory 的作用是根据请求类型(如 GET、POST 等)创建不同的请求对象。对于 GET 请求,它会创建一个 GetRequest
,这个请求对象会继承 BaseRequest,并且实现处理逻辑。

当 GET 请求类型被检测到时,RequestFactory 会创建一个 GetRequest 实例:

# 3.1.5 处理器:ReadHandler 和 process 方法
GetRequest 调用 process() 方法,进而调用 getRequestHandler().handleRequest(this),这里的 getRequestHandler()
返回的是 ReadHandler。ReadHandler 负责处理 GET 请求的业务逻辑。

ReadHandler 会执行查询操作并返回结果。

# 3.1.6 执行查询:ClusterController.getResources
在 handleRequest 中,我们看到 ReadHandler 通过调用 query.execute() 来触发查询操作。query.execute()
最终调用 ClusterController.getResources 方法,负责从 Ambari 的元数据中获取堆栈服务的信息。

紧接着调用StackServiceResourceProvider getResources 方法

private Set<StackServiceResponse> getStackServices(StackServiceRequest request) throws AmbariException {
Set<StackServiceResponse> response;
String stackName = request.getStackName();
String stackVersion = request.getStackVersion();
String serviceName = request.getServiceName();
if (serviceName != null) {
ServiceInfo service = ambariMetaInfo.getService(stackName, stackVersion, serviceName);
response = Collections.singleton(new StackServiceResponse(service));
} else {
Map<String, ServiceInfo> services = ambariMetaInfo.getServices(stackName, stackVersion);
response = new HashSet<>();
for (ServiceInfo service : services.values()) {
response.add(new StackServiceResponse(service));
}
}
return response;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19

# 3.1.7 获取堆栈信息:AmbariMetaInfo
AmbariMetaInfo 类负责获取堆栈信息。当请求需要某个特定堆栈和版本时,AmbariMetaInfo
会根据堆栈名称、版本和服务名称来查找对应的 ServiceInfo。
public ServiceInfo getService(String stackName, String version, String serviceName) throws AmbariException {
ServiceInfo service = getStack(stackName, version).getService(serviceName);
if (service == null) {
throw new StackAccessException("stackName=" + stackName + ", stackVersion=" +
version + ", serviceName=" + serviceName);
}
return service;
}
2
3
4
5
6
7
8
9
10
堆栈信息是通过文件系统加载的,并存储在 StackManager 中。
public StackInfo getStack(String stackName, String version) throws AmbariException {
StackInfo stackInfoResult = stackManager.getStack(stackName, version);
if (stackInfoResult == null) {
throw new StackAccessException("Stack " + stackName + " " + version + " is not found in Ambari metainfo");
}
return stackInfoResult;
}
2
3
4
5
6
7
8
9

这是请求结果


- 01
- bigtop-select 打包缺 compat 报错修复 deb07-16
- 02
- bigtop-select 打包缺 control 文件报错修复 deb07-16
- 03
- 首次编译-环境初始化 必装07-16