 distro-select逻辑详解
distro-select逻辑详解
# 1. 引言与问题概述 🎯
# 1.1 背景介绍
在分布式集群的管理中,版本控制是一个不可或缺的核心环节。集群内部可能需要支持多个组件版本,以适应不同业务需求、快速迭代的技术环境和动态变化的依赖关系。为此,Ambari 通过 distro-select 模块来实现多版本管理,它在组件安装和更新过程中发挥着关键作用,确保各版本间的兼容性和一致性。
distro-select 作为 Ambari
中重要的版本控制机制,通过符号链接(symlinks)管理来提供一个标准化的指针,以便在各个版本的组件之间实现无缝切换。该模块通过自动更新版本链接,确保集群在不同版本共存时依旧能够保持稳定的运行环境,从而减少手动管理的复杂度,提高系统的可维护性和灵活性。实现逻辑中,setup_stack_symlinks(struct_out_file)
是其核心方法之一。该方法负责在组件安装后调用 <stack-selector-tool>
,并设置指向所需组件版本的符号链接,确保系统在多版本环境中的一致性。通过 setup_stack_symlinks 方法,distro-select
模块能够有效地自动化指针调整和版本控制,避免了人工干预的风险。
# 1.2 本节目标
本节的目标是系统性地解析 distro-select 的设计逻辑与具体应用,帮助读者深入理解其在多版本管理中的具体实现方式。我们将从以下几个方面展开:
distro-select 的工作原理
- 解析
distro-select的核心原理,包括其如何实现版本选择、符号链接的更新逻辑等。
- 解析
setup_stack_symlinks 方法的作用与实现
- 深入探讨
setup_stack_symlinks(struct_out_file)方法的功能,分析其在版本指针调整中的关键作用。
- 深入探讨
distro-select 的实际应用场景
- 展示多版本管理的典型应用场景,例如在升级、回滚和版本切换时的流程,以帮助用户理解如何在集群管理中高效运用 distro-select。
# 2. 核心概念解析 🧠
# 2.1 distro-select 的定义与功能
distro-select 是 Ambari 中为管理多版本组件而设计的关键模块,主要用于在集群内自动切换和选择不同版本的组件。其核心作用是通过符号链接(symlink)机制,确保集群各节点在多版本环境下能够一致地引用所需组件,从而降低版本冲突的风险。
该模块通过创建和更新符号链接的方式,使得不同组件在不同版本之间可以动态切换。这种链接更新机制让运维人员无需手动更改路径或重新配置环境变量即可实现版本切换,从而大大提升了多版本共存时的灵活性与兼容性。
# 2.2 setup_stack_symlinks 方法的作用
在 distro-select 的实现中,setup_stack_symlinks 是实现自动版本切换的核心方法之一。其具体作用和实现逻辑如下:
方法功能
setup_stack_symlinks(struct_out_file)方法用于调用<stack-selector-tool>工具,将集群内的符号链接设置为指定的版本。其主要功能是确保组件的版本指针指向系统要求的标准化版本路径,从而避免因版本不匹配而引发的兼容性问题。运行流程 方法运行时,会从系统配置中获取目标版本信息,并通过
<stack-selector-tool>将该信息写入符号链接。最终,集群内的相关指针(如 HDP、HDFS 等路径)都会自动更新为指向目标版本的路径,完成版本的切换。自动化版本控制的优势
setup_stack_symlinks提供了一个可靠的自动化版本控制方法,无需人为干预便可完成指针调整。这种方式不仅减少了手动操作的失误风险,也加快了版本切换速度,使得系统可以在版本更新、回滚等场景中快速响应。
# 2.3 符号链接管理逻辑
distro-select 通过符号链接管理来实现组件版本的切换与管理。具体的管理逻辑如下:
指针初始化
- 在组件的初始安装过程中,
setup_stack_symlinks会生成一系列符号链接,这些链接指向组件的默认版本,以便后续操作和维护。
- 在组件的初始安装过程中,
版本切换
- 当系统需要切换至不同的组件版本时,
setup_stack_symlinks会重新调用<stack-selector-tool>,并更新所有相关指针的符号链接。通过这种方式,各个组件可以在多版本共存的环境中无缝切换。
- 当系统需要切换至不同的组件版本时,
一致性检查
- 为确保所有节点的符号链接指向相同的目标版本,
distro-select还包含一致性检查机制,能够在每次指针更新后自动验证链接路径的准确性,避免多节点环境中产生版本不一致的问题。
- 为确保所有节点的符号链接指向相同的目标版本,
# 3. 实操与代码解析 🔧
# 3.1 stack-hooks(after-INSTALL)通用方法
接续上次的内容,setup_stack_symlinks 方法是所有组件安装完后必须执行的代码。它可以视为 Ambari
与各组件之间的桥梁和纽带,通过符号链接管理实现组件的动态指向更新。在 HDP 和 Bigtop
两大分发版本中,都使用了 distro-select 进行组件版本管理,这为系统在多版本共存时提供了强有力的支持。
例如,以下 AfterInstallHook 类中的 hook 方法展示了 setup_stack_symlinks 的调用逻辑:
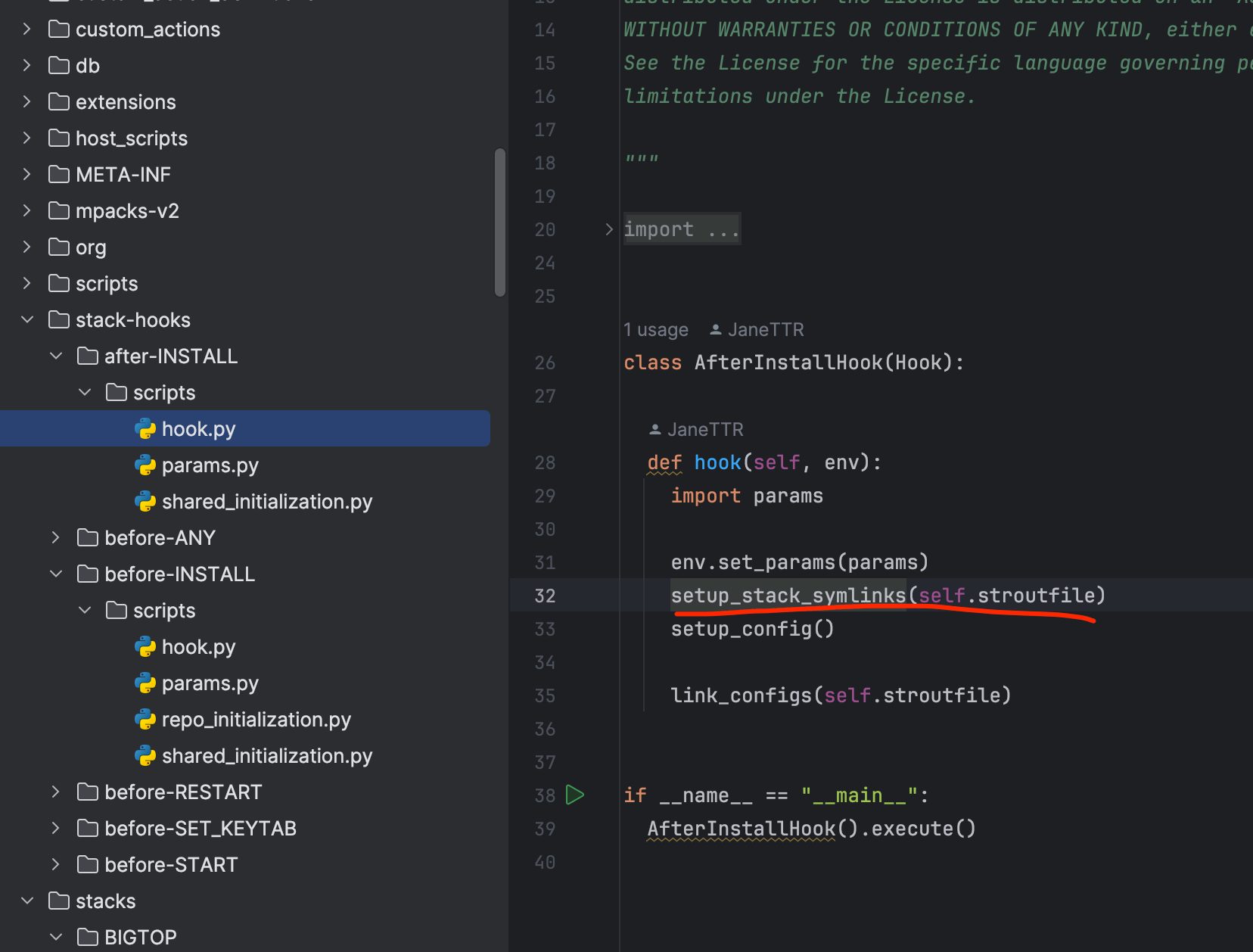
在具体应用中,setup_stack_symlinks 可以确保各组件指向目标版本,进一步提高多版本环境中的一致性和系统稳定性。
# 3.2 setup_stack_symlinks 核心逻辑
在 setup_stack_symlinks 方法中,其主要功能是调用 <stack-selector-tool> 设置符号链接。下面的内容对其具体实现和流程进行了深入解析。
# 3.2.1 shared_initialization.py 中的 setup_stack_symlinks 方法
shared_initialization.py 中的 setup_stack_symlinks 代码片段展示了版本指向的更新逻辑:

- 版本检查:在安装组件后,通过
setup_stack_symlinks调用<stack-selector-tool>,确保指针指向正确的版本路径。 - 同步执行锁:使用锁机制确保在高并发环境下的版本路径一致性,避免出现路径错误的情况。
# 3.2.2 stack_select.py 中的版本选择逻辑
stack_select.select(component, version) 函数的主要作用是使用 <stack-selector-tool> 为特定组件设定版本。示例如下:

# 具体的执行代码为:
ambari-python-wrap \
/usr/lib/bigtop-select/distro-select \
set \
kafka-broker \
3.2.0
# 对于命令执行的含义 我们在 做过精讲。这里不在赘述
# Ambari集成Dolphin实战-009-实战bigtop-select修改
2
3
4
5
6
7
8
9

执行完以后的效果,在 /usr/bigtop/current 下的所有组件通过软连接形式去关联版本组件

# 3.2.3 stack_tools.py 中的路径获取逻辑
stack_tools.py 文件提供了路径获取和管理功能,以下是主要方法的解析:

- 工具配置:
get_stack_tool根据分发版本的stack_tools配置获取各自版本管理工具的路径和名称。hdp-select、bigtop-select等工具的路径在此被动态设定。 - 路径解析:各组件的
stack_tool配置被解析为路径和文件名,以便 Ambari 在运行时调用。
路径逻辑如下图:

# 3.2.4 get_packages 方法解析
get_packages 方法用于在 Ambari 的 stack-select
工具中获取与特定服务和组件关联的包信息,以实现对多版本环境的管理和控制。该方法接收 scope、service_name
和 component_name 作为参数,通过验证和配置解析,定位到特定服务和组件的包名称列表。以下是方法的详细逻辑解析:
def get_packages(scope, service_name=None, component_name=None):
# 1. 检查 scope 的有效性
if scope not in _PACKAGE_SCOPES:
raise Fail("The specified scope of {0} is not valid".format(scope))
# 2. 加载配置,获取 service_name 和 component_name
config = Script.get_config()
if service_name is None or component_name is None:
if 'role' not in config or 'serviceName' not in config:
raise Fail("Both the role and the service name must be included in the command.")
service_name = config['serviceName'] # 例如 "KAFKA"
component_name = config['role'] # 例如 "KAFKA_BROKER"
# 3. 获取 stack_name,例如 "HDP" 或 "Bigtop"
stack_name = default("/clusterLevelParams/stack_name", None)
if stack_name is None:
raise Fail("The stack name is not present in the command. Packages for stack-select tool cannot be loaded.")
# 4. 加载 stack_packages 配置,包含所有服务和组件的包映射
stack_packages_config = default("/configurations/cluster-env/stack_packages", None)
if stack_packages_config is None:
# 此处的日志仅用于临时调试,未找到 stack_packages 时将返回 None
Logger.error("Temporary disable: The stack packages are not defined on the command.")
return None
# 解析 stack_packages_config JSON 数据
data = json.loads(stack_packages_config)
if stack_name not in data:
raise Fail("Cannot find stack-select packages for the {0} stack".format(stack_name))
# 5. 读取 stack-select 配置内容
# stack_select_key 是 "stack-select",表示 stack-select 工具的包配置
stack_select_key = "stack-select"
data = data[stack_name]
if stack_select_key not in data:
raise Fail("There are no stack-select packages defined for this command for the {0} stack".format(stack_name))
# 此处省略
# 6. 获取特定服务(如 "KAFKA")和组件(如 "KAFKA_BROKER")的包信息
# service_name 和 component_name 转为大写,以确保配置一致
data = data[service_name.upper()]
if component_name.upper() not in data:
Logger.info("Skipping stack-select on {0} because it does not exist in the stack-select package structure.".format(component_name))
return None
packages = data[component_name.upper()][scope]
# 此处省略
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
核心逻辑与变量值说明
Scope 验证:

_PACKAGE_SCOPES是预定义的支持范围列表。这也是我们stack_tools.json中的内容参数
Service 和 Component 的加载:

serviceName为"KAFKA",role为"KAFKA_BROKER"。
Stack Name 获取:

stack_name从clusterLevelParams中加载,例如"HDP"或"Bigtop"。- 如果
stack_name未定义,方法将报错并停止执行。
Stack Packages 配置解析:
stack_packages_config通过cluster-env配置加载,包含所有服务和组件的包信息。- 此配置以 JSON 格式存储,以便根据
stack_name、service_name和component_name查找匹配的包。
Service 和 Component 的包选择:
- 将
service_name和component_name转换为大写后,查找特定的服务和组件包配置。 - 若找不到特定组件,会记录日志并返回
None,表明此组件无需执行stack-select操作。
- 将
返回结果:
- 返回符合
scope要求的单个包或包列表,确保返回的包适用于当前的多版本管理环境。
- 返回符合

我们在ambari-server/src/main/resources/stacks/BIGTOP/3.2.0/properties/stack_packages.json 中定义 service 和 role
,其实就
能知道,install 阶段,我们需要对哪些组件进行软连接。
# 3.3 组件版本管理文件的目录结构
在 bigtop 和 hdp 的配置文件中可以看到两者的版本管理工具和路径。例如:
Bigtop 配置:
{ "BIGTOP": { "stack_selector": [ "distro-select", "/usr/lib/bigtop-select/distro-select", "bigtop-select" ] } }1
2
3
4
5
6
7
8
9HDP 配置:
{ "HDP": { "stack_selector": [ "hdp-select", "/usr/bin/hdp-select", "hdp-select" ] } }1
2
3
4
5
6
7
8
9
两者分别在不同的目录下设置了 stack_selector,这确保了各自环境的版本管理独立性。通过 stack-select 工具,Ambari
可以轻松地管理和切换组件的不同版本,有效支持多版本共存和灵活的升级回滚操作。
# 4. 最佳实践与技巧 💡
在 Ambari 中,distro-select
主要用于管理多版本组件,通过符号链接的方式确保集群中各节点的组件版本一致,使得在版本切换时可以平滑过渡而不影响运行环境。distro-select
通过读取 stack_packages.json 的配置来决定各组件版本的位置和规则。
在自定义组件的开发中,合理配置 stack_packages.json 是实现多版本管理的关键。以下是一些配置规则和技巧:
定义组件的包信息:
stack_packages.json文件中,每个服务和组件都需要定义其版本包,以便distro-select能够正确管理。例如,对于服务
KAFKA的组件KAFKA_BROKER,可以配置如下:
上述配置指定了安装和启动时需要的包名称,
distro-select会根据这些信息设置符号链接,确保组件指向正确的版本包。
明确作用范围 (
scope):在stack_packages.json中,scope是包的使用范围,如"INSTALL"表示安装时需要的包,为每个操作指定合适的包,有助于distro-select在各个阶段自动切换版本。自定义组件配置:在自定义组件时,可以参照已有的服务配置。例如,如果您要新增
MY_SERVICE,可按照以下结构添加:{ "BIGTOP": { "stack-select": { "MY_SERVICE": { "MY_COMPONENT": { "STACK-SELECT-PACKAGE": "填写 role name", "INSTALL": [ "填写 role name 至少" ] } } } } }1
2
3
4
5
6
7
8
9
10
11
12
13
14这样配置后,
distro-select能够识别并管理自定义组件的安装。
# 5. 总结与延伸学习 🚀
# 5.1 内容回顾
在本节中,我们深入解析了 distro-select 在 Ambari 中的作用,了解了它如何通过符号链接实现多版本环境下的组件管理。我们还探讨了如何在 stack_packages.json 文件中正确配置自定义组件,以便我们在自定义组件中环节中知道该怎么去填写。以及知道软连接设置的语法及触发的逻辑。
- 01
- bigtop-select 打包缺 compat 报错修复 deb07-16
- 02
- bigtop-select 打包缺 control 文件报错修复 deb07-16
- 03
- 首次编译-环境初始化 必装07-16