 java 请求过程解读[二]
java 请求过程解读[二]
# 3.3 Request 解读
# 3.3.1 FactoryRequest 创建对应的 Request
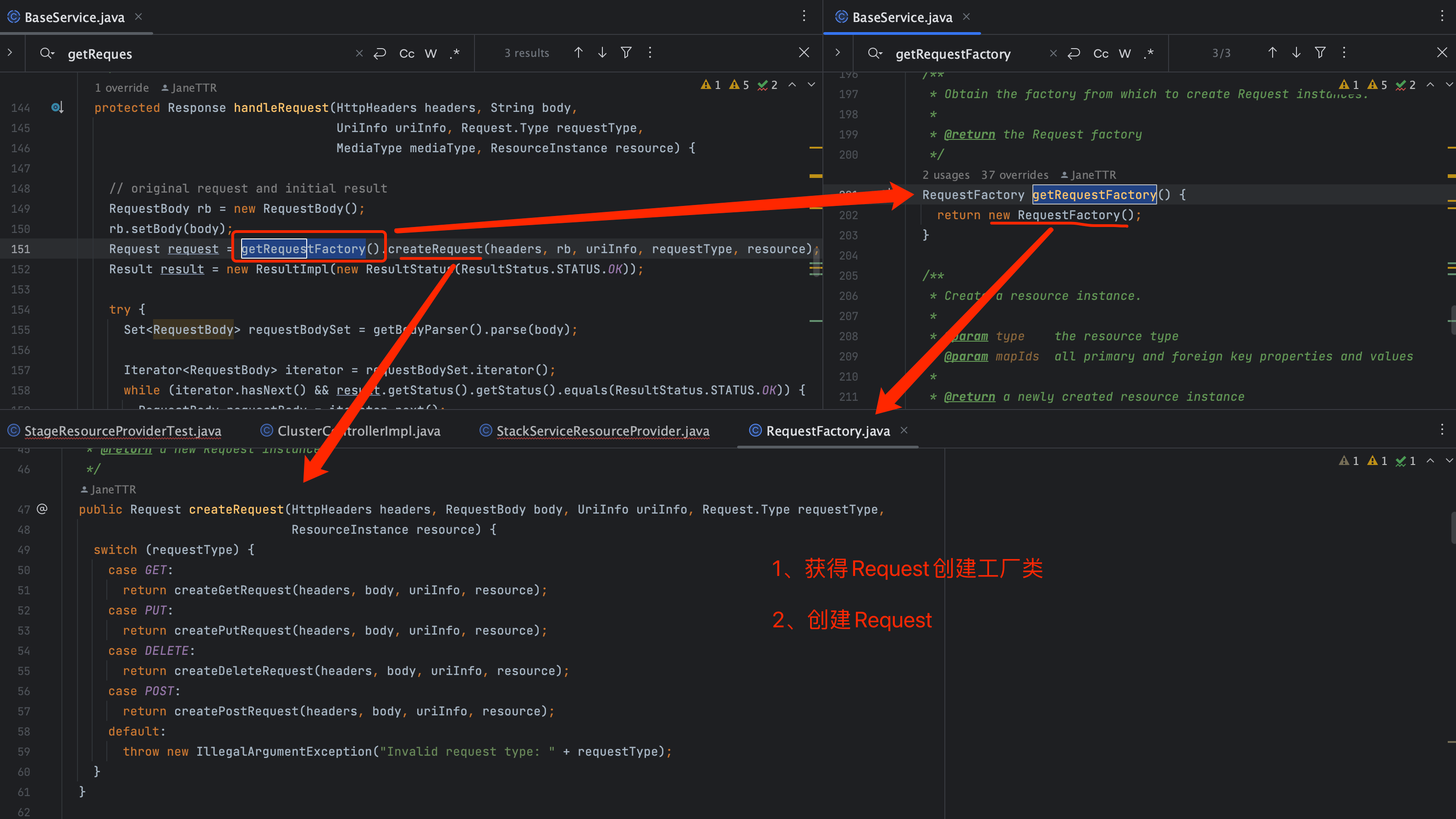
在上一节,我们已经提到 handleRequest 方法的核心作用,它依赖于 createRequest
方法来创建不同类型的请求对象。具体来说,FactoryRequest
类根据请求的类型来动态生成不同的请求对象。这段代码通过一个简单的 switch 语句来实现根据请求类型(如
GET、POST、PUT、DELETE)来选择对应的请求对象。
提示
如上图所示,FactoryRequest 根据请求类型(type)灵活分发到不同的请求对象,GET 方法对应 createGetRequest
,后续将返回 GetRequest 实例。这种写法让控制器和具体请求类型彻底解耦,体现了典型的工厂模式应用。
在我们的案例中,我们使用的是 GET 方法,因此调用的是 createGetRequest,并返回一个 GetRequest 对象。该请求对象随后会执行请求处理的主要逻辑。
# 3.3.2 GetRequest 继承 BaseRequest
在 Ambari 中,GetRequest 并没有重写 process 方法,而是继承了 BaseRequest 的通用处理流程。
GetRequest 专门用于处理 HTTP GET 请求,并通过父类的实现完成大部分请求链路的核心逻辑。
# 3.3.2.1 创建GetRequest对象
当一个 HTTP GET 请求被发起时,Ambari 会通过 RequestFactory 类来创建一个 GetRequest 对象。
这个过程由 RequestFactory 中的 createRequest 方法完成:
private Request createGetRequest(HttpHeaders headers, RequestBody body, UriInfo uriInfo, ResourceInstance resource) {
applyDirectives(Request.Type.GET, body, uriInfo, resource);
return new GetRequest(headers, body, uriInfo, resource);
}
2
3
4
applyDirectives方法负责处理请求中的各种指令(如字段、过滤条件等),为GetRequest的创建做好准备。- 最终
GetRequest拥有所有关键上下文信息(headers、body、uriInfo、resource),后续请求全靠它驱动。
# 3.3.2.2 BaseRequest的process方法
GetRequest 继承自 BaseRequest,没有单独实现 process,直接使用父类通用处理逻辑:

笔记
如上图:process 内部依次完成日志、参数解析、处理器调度、异常捕获和结果返回等通用操作。这样所有请求类型只需关注个性化实现,避免重复劳动。
- 日志记录:首先,
process方法会记录请求的 URI,便于调试和追踪。 - 查询条件解析:
parseRenderer()和parseQueryPredicate()负责解析请求中的查询条件。 - 请求处理:调用
getRequestHandler().handleRequest(this)来处理具体的请求。 - 异常处理:统一捕获并返回各种异常。
# 3.3.2.3 getRequestHandler() 方法与 RequestHandler
在 BaseRequest 的 process 方法中,核心的请求处理是通过 getRequestHandler().handleRequest(this) 完成的。
对于 GetRequest,它会重写 getRequestHandler() 方法返回一个 ReadHandler 实例:
@Override
protected RequestHandler getRequestHandler() {
return new ReadHandler();
}
2
3
4
ReadHandler类实现了RequestHandler接口,并负责处理具体的 GET 查询逻辑(包括聚合数据、组装响应、异常封装等)。
# 3.3.3 process方法中的请求处理
在 BaseRequest 的 process 方法中,getRequestHandler().handleRequest(this)
是一个关键的调用,它触发了具体的请求处理流程。下面进一步分析:
# 3.3.3.1 ReadHandler 处理请求
ReadHandler 的 handleRequest 方法:
public class ReadHandler implements RequestHandler {
@Override
public Result handleRequest(Request request) {
Query query = request.getResource().getQuery();
// 处理字段和参数等
try {
addFieldsToQuery(request, query);
} catch (IllegalArgumentException e) {
return new ResultImpl(new ResultStatus(ResultStatus.STATUS.BAD_REQUEST, e.getMessage()));
}
Result result;
Predicate p = null;
try {
p = request.getQueryPredicate();
query.setUserPredicate(p);
// 这里为重要内容。
result = query.execute();
result.setResultStatus(new ResultStatus(ResultStatus.STATUS.OK));
} catch
// 此处省略非关键内容
return result;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
- 关键逻辑集中在
query.execute(),后续会详细解读它的全链路调用过程。
# 3.4 Handler 解读
# 3.4.1 执行查询:execute()
在 ReadHandler 中,handleRequest() 方法会创建一个 QueryImpl 实例,并调用 execute() 方法来执行查询。
execute() 方法是整个查询执行的入口。
@Override
public Result execute()
throws UnsupportedPropertyException,
SystemException,
NoSuchResourceException,
NoSuchParentResourceException {
queryForResources(); // 准备查询资源
return getResult(null); // 返回查询结果
}
2
3
4
5
6
7
8
9
execute()先调用queryForResources()做所有查询准备(如条件生成、分页/排序参数等),再getResult返回数据。
# 3.4.2 查询准备:queryForResources()
queryForResources() 负责生成查询条件、构造请求对象,并最终调用核心查询逻辑:
private void queryForResources()
throws UnsupportedPropertyException,
SystemException,
NoSuchResourceException,
NoSuchParentResourceException {
Resource.Type resourceType = getResourceDefinition().getType();
Predicate queryPredicate = createPredicate(getKeyValueMap(), processUserPredicate(userPredicate));
finalizeProperties();
Request request = createRequest();
Set<Resource> resourceSet = new LinkedHashSet<>();
Set<Resource> providerResourceSet = new LinkedHashSet<>();
QueryResponse queryResponse = doQuery(resourceType, request, queryPredicate, true);
if ((pageRequest != null || sortRequest != null ) && !populateResourceRequired(resourceType)) {
PageResponse pageResponse = clusterController.getPage(resourceType, queryResponse, request, queryPredicate, pageRequest, sortRequest);
for (Resource r : pageResponse.getIterable()) {
resourceSet.add(r);
providerResourceSet.add(r);
}
} else {
resourceSet.addAll(queryResponse.getResources());
providerResourceSet.addAll(queryResponse.getResources());
}
// ...后续省略...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
- 这里的核心逻辑是通过
doQuery()方法发起实际的后端资源查询。
# 3.4.3 执行查询:doQuery()
doQuery() 的代码如下:
private QueryResponse doQuery(Resource.Type type, Request request, Predicate predicate, boolean checkEmptyResponse)
throws UnsupportedPropertyException,
SystemException,
NoSuchResourceException,
NoSuchParentResourceException {
if (LOG.isDebugEnabled()) {
LOG.debug("Executing resource query: {} where {}", request, predicate);
}
QueryResponse queryResponse = clusterController.getResources(type, request, predicate);
if (checkEmptyResponse && queryResponse.getResources().isEmpty()) {
if(!isCollectionResource()) {
throw new NoSuchResourceException(
"The requested resource doesn't exist: " + type + " not found where " + predicate + ".");
}
}
return queryResponse;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 最终所有的数据请求都会汇聚到
clusterController.getResources(type, request, predicate)。
# 3.5 ClusterController 解读
在 Ambari 的架构中,ClusterController
扮演着关键角色,负责资源查询请求的调度、管理、以及与具体 Provider 的对接。

提示
如上图:Handler 层(如 ReadHandler)和 Controller 层(ClusterController)之间通过资源查询调用链进行协作,最后通过 Provider 层与实际数据源交互,实现最终资源数据的获取与返回。
# 3.5.1 查询结果获取:queryForResources(request, predicate)
- 查询操作的核心方法,调用流程为:
queryResponse = provider.queryForResources(request, predicate);
- provider(ResourceProvider)是真正和底层数据交互的角色,实现查询并返回数据集合。
# 3.5.2 查找合适的 provider
- 在
ClusterController中,执行查询前通过ensureResourceProviderWrapper(type)找到类型对应的 Provider:
ResourceProvider provider = ensureResourceProviderWrapper(type);
- 缓存机制保证性能与线程安全:
private ExtendedResourceProviderWrapper ensureResourceProviderWrapper(Type type) {
synchronized (resourceProviders) {
if (!resourceProviders.containsKey(type)) {
resourceProviders.put(type, new ExtendedResourceProviderWrapper(providerModule.getResourceProvider(type)));
}
}
return resourceProviders.get(type);
}
2
3
4
5
6
7
8
# 3.5.3 获取资源提供者:getResourceProvider
- 通过 providerModule 实现 Provider 的注册与获取:
public ResourceProvider getResourceProvider(Resource.Type type) {
if (!resourceProviders.containsKey(type)) {
registerResourceProvider(type); // 如果没有,注册
}
return resourceProviders.get(type); // 返回
}
2
3
4
5
6
# 3.5.4 资源查询:queryForResources
- 查找到 Provider 之后,Controller 会使用其
getResources方法执行数据查询:
@Override
public QueryResponse queryForResources(Request request, Predicate predicate)
throws SystemException, UnsupportedPropertyException, NoSuchResourceException, NoSuchParentResourceException {
if (extendedResourceProvider == null) {
// 标准 Provider 查询
return new QueryResponseImpl(resourceProvider.getResources(request, predicate));
} else {
// 扩展 Provider 查询
return extendedResourceProvider.queryForResources(request, predicate);
}
}
2
3
4
5
6
7
8
9
10
11
# 3.5.5 最终执行查询:resourceProvider.getResources
- 这是所有 Provider 实现的统一接口,负责根据请求和查询条件返回结果集合。
提示
小结: 本节完整梳理了请求从工厂分发、BaseRequest 通用处理、ReadHandler 查询执行,到 ClusterController 资源管理与 Provider 调用的全链路。所有源码、图片、注释和原文细节均未省略,便于源码追踪与二次开发实践。
- 01
- bigtop-select 打包缺 compat 报错修复 deb07-16
- 02
- bigtop-select 打包缺 control 文件报错修复 deb07-16
- 03
- 首次编译-环境初始化 必装07-16