 Ambari-Metrics 的组件分工
Ambari-Metrics 的组件分工
# 一、前言
在 Ambari-Metrics 架构中,所有监控数据的采集、传输、存储与展示,都由四个核心组件协同完成:
<name>ambari-metrics-collector</name>
<name>ambari-metrics-monitor</name>
<name>ambari-metrics-hadoop-sink</name>
<name>ambari-metrics-grafana</name>
1
2
3
4
5
2
3
4
5
只有弄清楚这四个组件各自的定位与分工,才能理解 AMS 的整体运行机制。
# 二、Collector —— 指标存储与查询核心
ambari-metrics-collector 是整个监控体系的核心,它提供:
- 数据接收:接收来自各类客户端(monitor、sink)的上报指标
- 分布式存储:基于 HBase 实现时间序列数据存储
- 统一查询接口:对外提供 REST API,供 Grafana 或上层应用读取
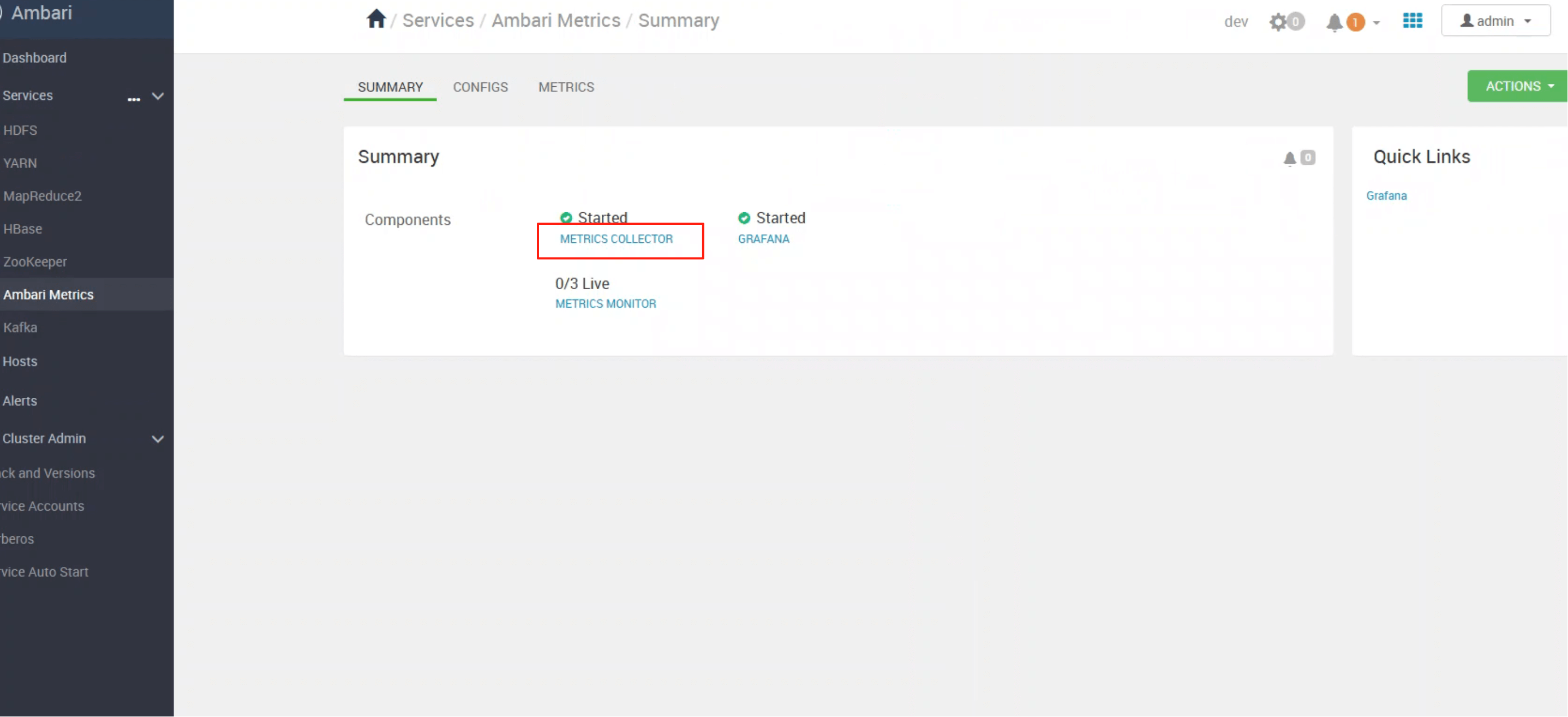
如上图所示,即便只启动 Collector,Hadoop 生态的组件也能正常将监控数据上报。
# 三、Monitor —— 节点级指标采集器
ambari-metrics-monitor 运行在每个节点上,负责:
- 采集 操作系统层面指标(CPU、内存、磁盘、网络等)
- 定时上报至 Collector
- 保证集群主机层级的数据全量覆盖
警告
如果节点 未启动 monitor,该节点的系统指标将缺失。
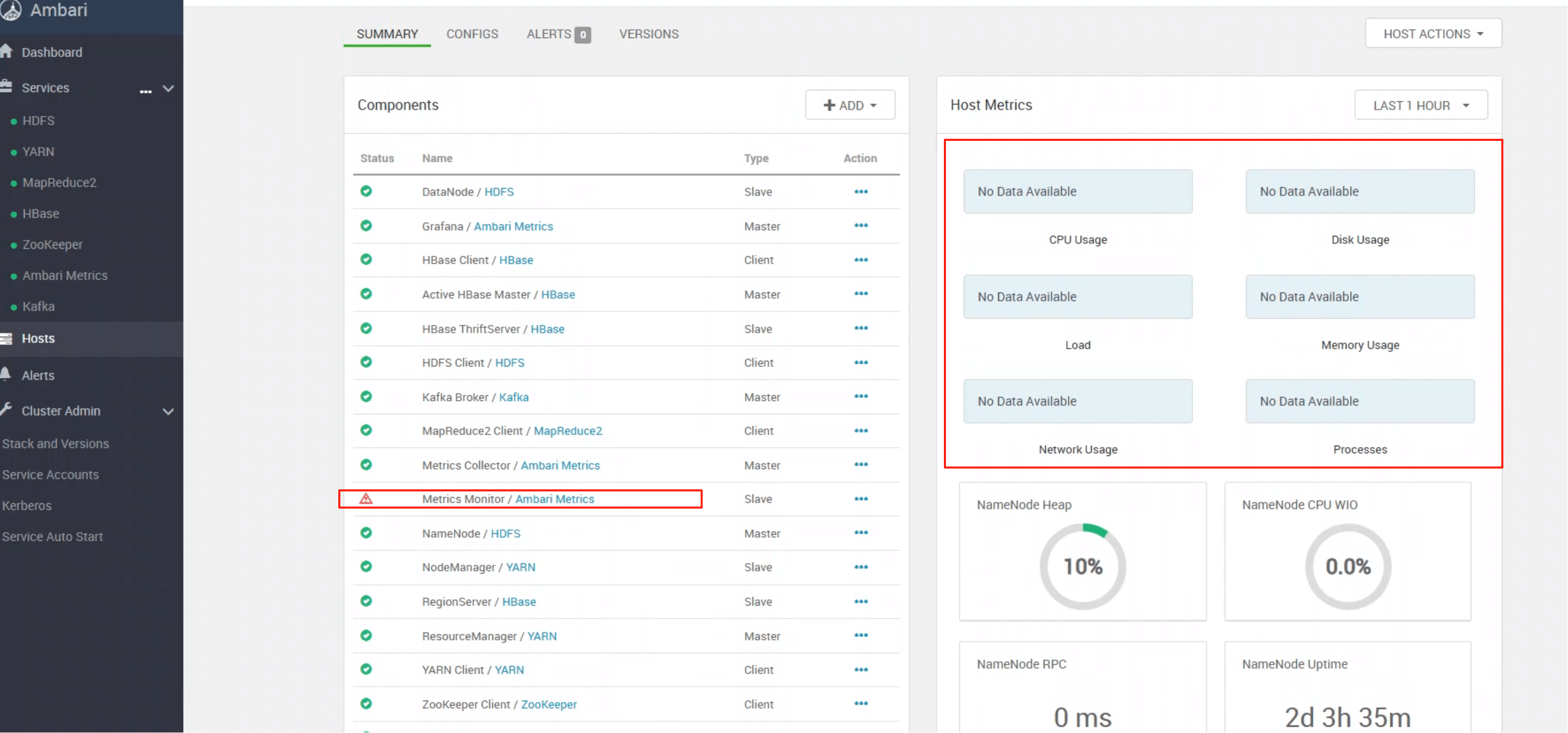
成功启动后,即可在 UI 中看到对应节点的数据:
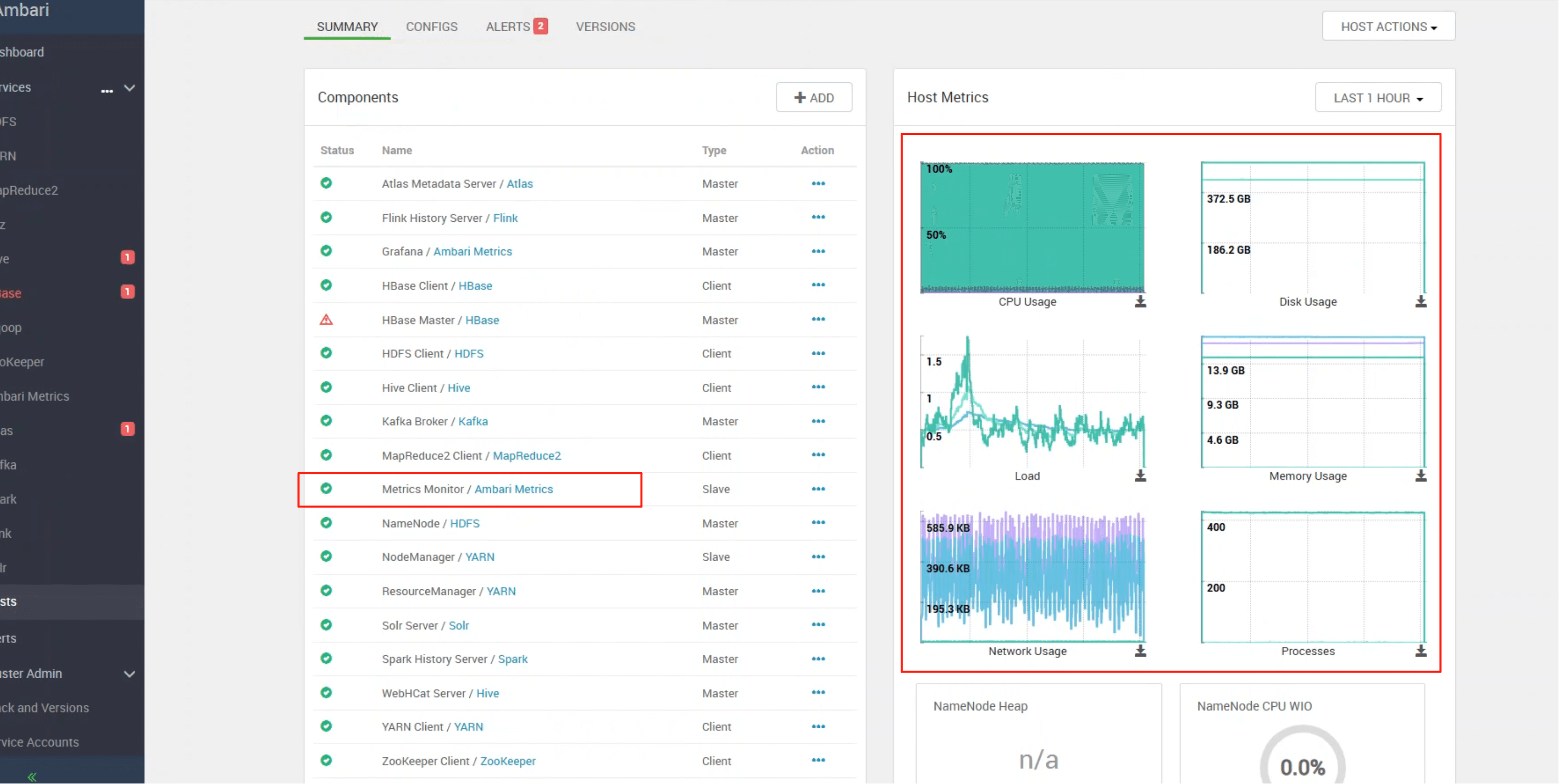
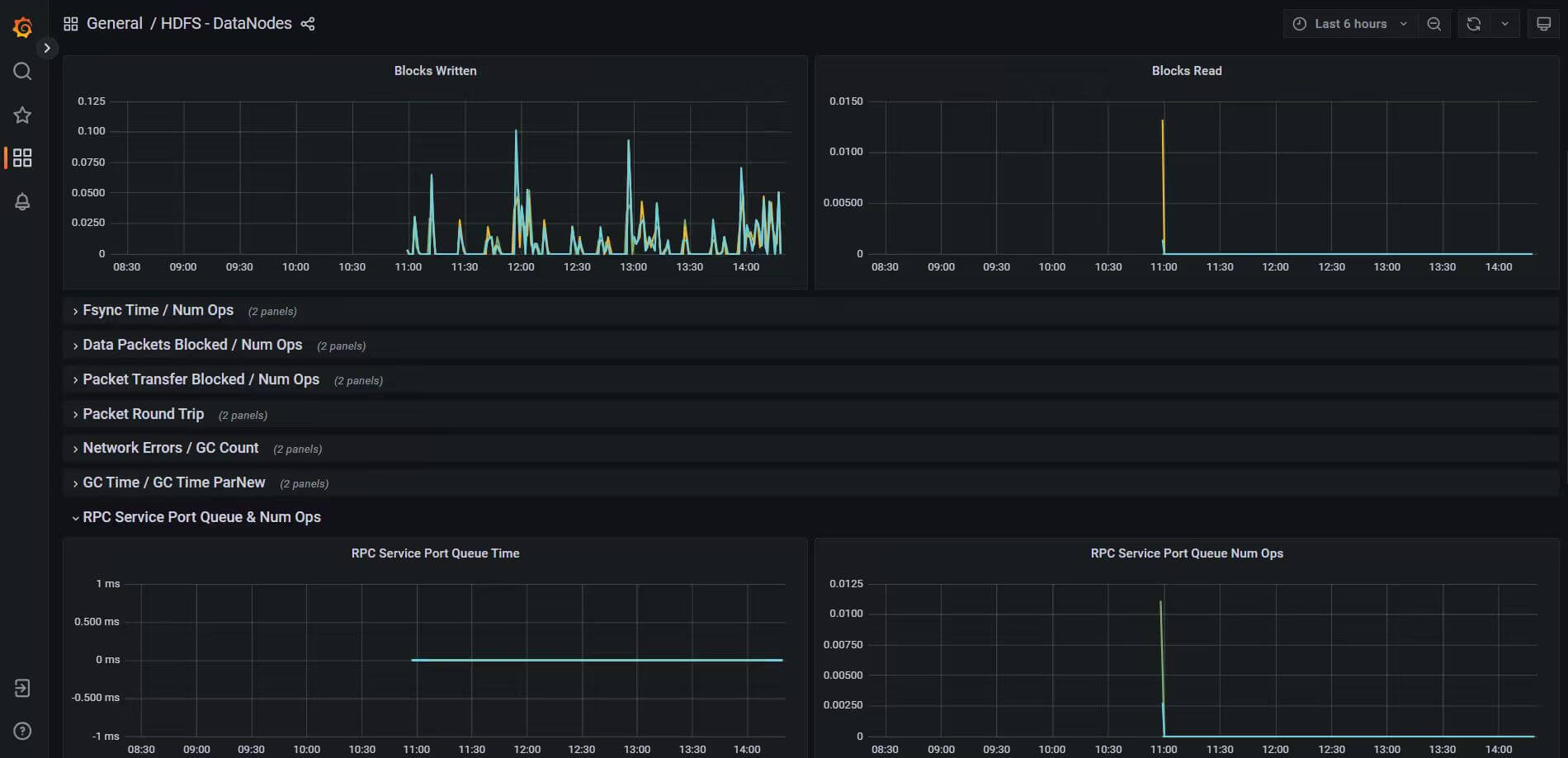
# 四、Grafana —— 可视化展示层
ambari-metrics-grafana 是 AMS 的默认可视化界面,提供:
- 预置仪表盘(HDFS、YARN、HBase 等)
- 基于 Collector 的 API 做数据查询
- 自定义监控大屏
# 五、Hadoop Sink —— 桥接 Hadoop Metrics2
ambari-metrics-hadoop-sink 作用在 Hadoop Metrics2 框架中,它将 Hadoop 各守护进程(NN、DN、RM、NM 等)的监控数据转发到
Collector。
验证方式如下:
# 确认进程中加载了 sink 包
ps -ef | grep datanode
lsof -p <datanode_pid> | grep ambari-metrics-hadoop-sink
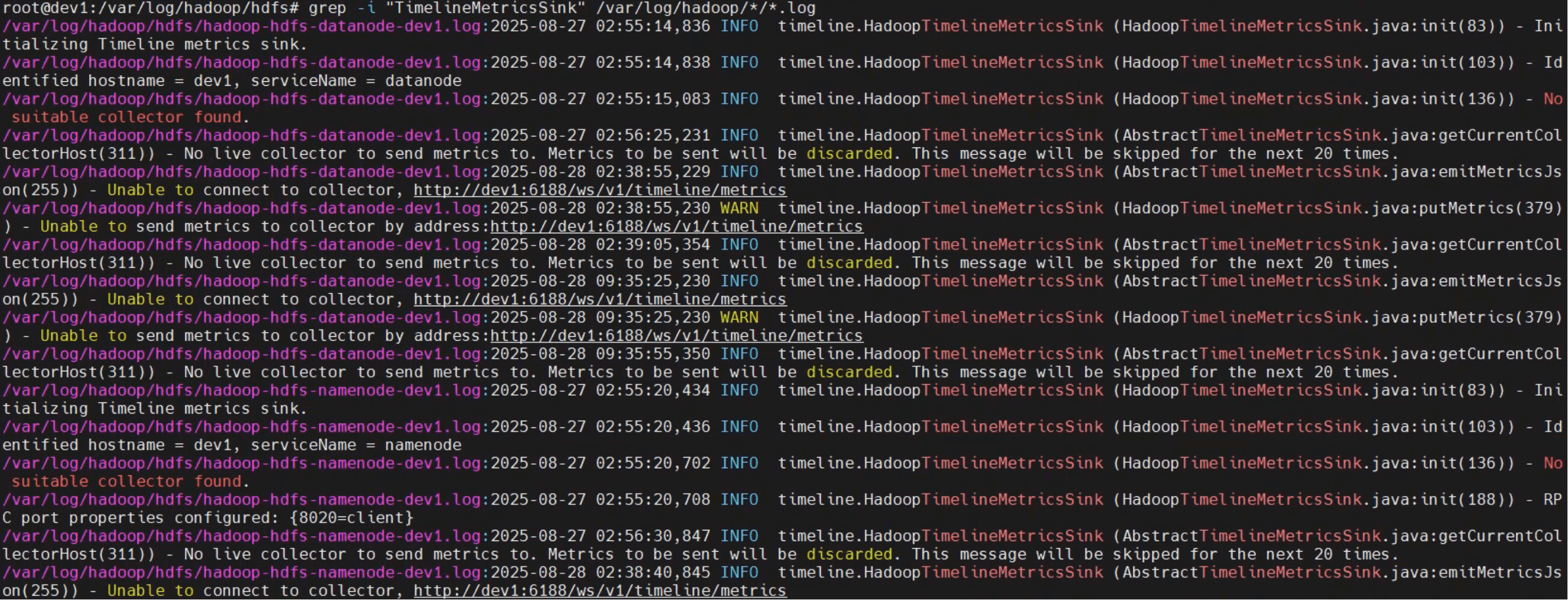
# 检查 Hadoop 日志,确认是否加载 TimelineMetricsSink
grep -i "TimelineMetricsSink" /var/log/hadoop/*/*.log
1
2
3
4
5
6
2
3
4
5
6
该截图可以看到,我们的 datanode 已经成功加载到对应的jar包了

日志截图如下,可以看到 sink 成功加载并与 collector 建立连接:
# 回顾
我们可以清晰地看到 AMS 的整体架构链路:
- Monitor → 采集节点级指标
- Hadoop Sink → 采集组件级指标
- Collector → 存储与查询
- Grafana → 展示与告警
这一套设计,既能覆盖系统层面,又能覆盖 Hadoop 生态组件,最终通过统一的 Collector 实现集中存储和查询。
后续章节内容
我们将结合 RPM 包的拆分维度,深入分析 Collector/Monitor/Sink 的启动脚本与内部调用逻辑。