 [/metrics/aggregated] — 分时日表数据溯源
[/metrics/aggregated] — 分时日表数据溯源
# 一、doWork:聚合主线与时间窗
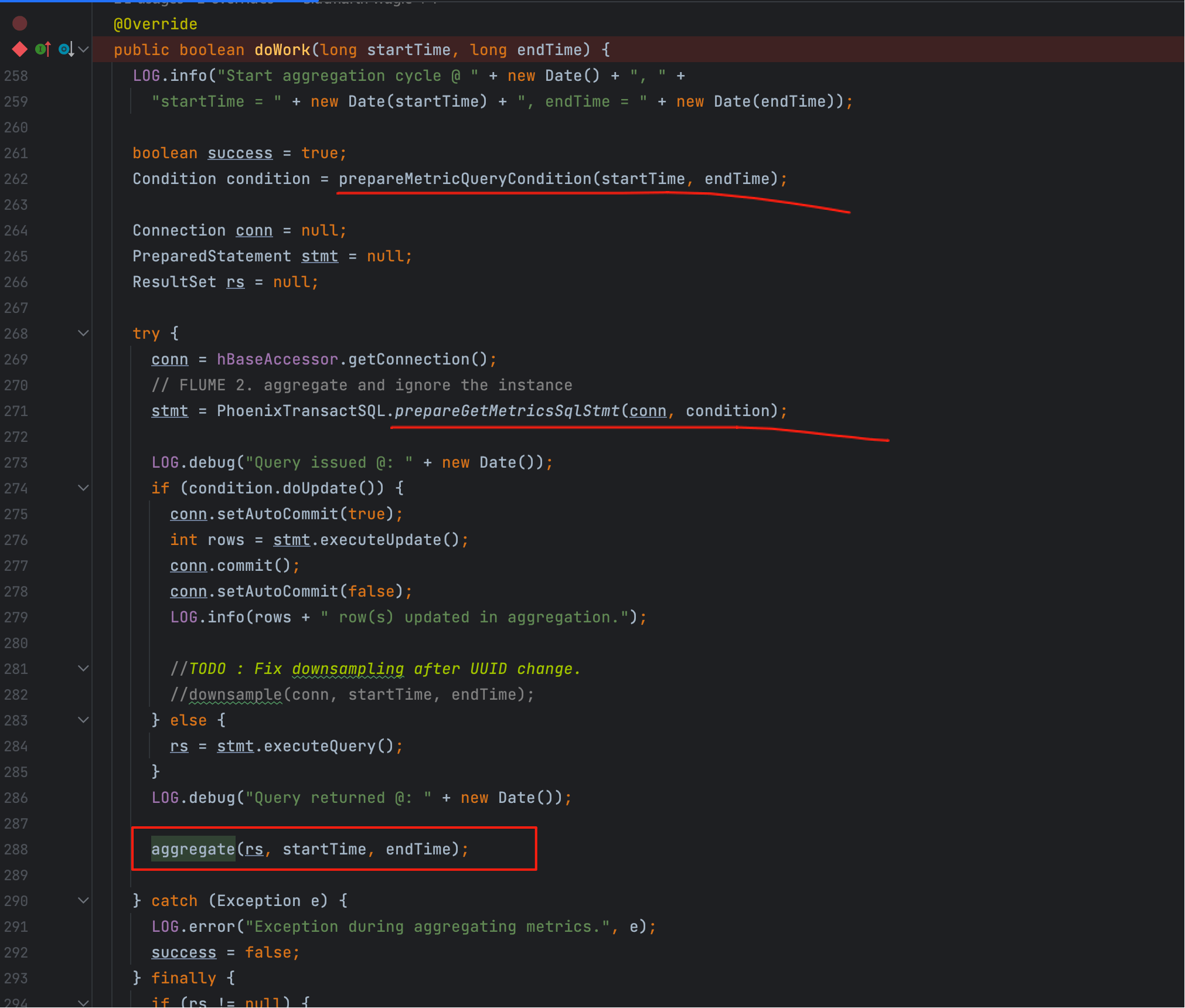
读图要点
1、入口是 doWork(startTime, endTime);
2、左闭右开窗口 [startTime, endTime) 来自“检查点对齐”;
3、三段职责:prepareMetricQueryCondition → prepareGetMetricsSqlStmt → 执行并提交。
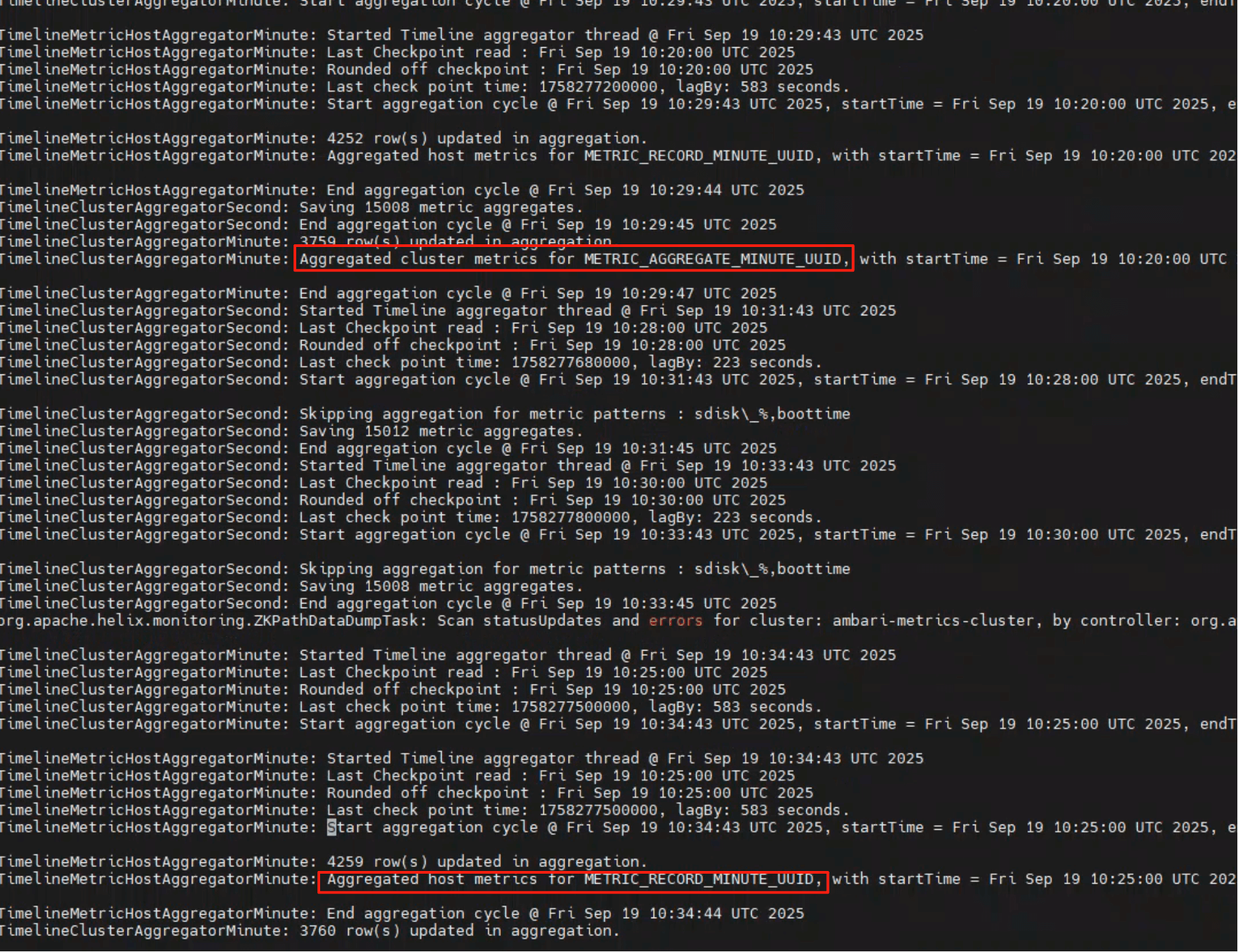
接着把“这个窗口真的被使用了吗?”用日志落点验证:

2025-09-19 10:34:43,248 INFO TimelineClusterAggregatorMinute: Start aggregation cycle ...
2025-09-19 10:34:44,602 INFO TimelineMetricHostAggregatorMinute: 4259 row(s) updated in aggregation.
2
观测口径
- Start aggregation cycle:本轮窗口;
- row(s) updated):Phoenix 端生效行数,是聚合是否成功的直接量化指标。
# 二、重要代码解读
# 1、prepareMetricQueryCondition 干什么的
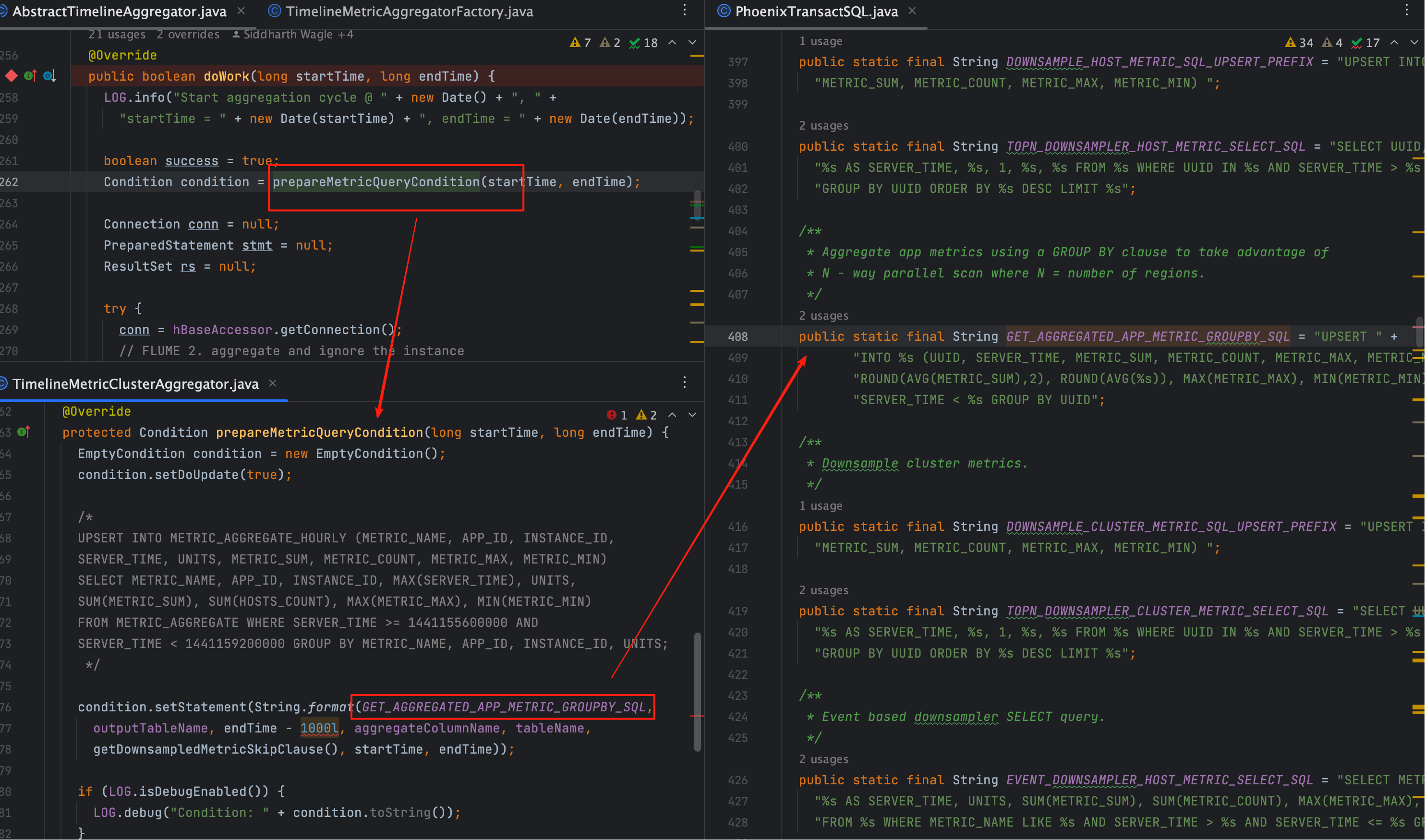
上图对应的 v2 片段将“计算+写库”内联进一条 SQL:
public static final String GET_AGGREGATED_APP_METRIC_GROUPBY_SQL = "UPSERT " +
"INTO %s (UUID, SERVER_TIME, METRIC_SUM, METRIC_COUNT, METRIC_MAX, METRIC_MIN) SELECT UUID, %s AS SERVER_TIME, " +
"ROUND(AVG(METRIC_SUM),2), ROUND(AVG(%s)), MAX(METRIC_MAX), MIN(METRIC_MIN) FROM %s WHERE%s SERVER_TIME >= %s AND " +
"SERVER_TIME < %s GROUP BY UUID";
2
3
4
关键点
SERVER_TIME取endTime - 1000,确保落库点对齐窗口右界;GROUP BY UUID保持维度一致性,避免重复或漏聚。
# 2、prepareGetMetricsSqlStmt 干什么的
- 当
condition.getStatement() != null(v2 常态)时,直接采用上一步内联语句,只补 WHERE/ORDER/LIMIT; - 当为 v1 路径时,先按精度选择
METRICS_AGGREGATE_MINUTE/HOUR/DAILY[_UUID]再拼 WHERE。
if (condition.getStatement() != null) {
stmtStr = condition.getStatement(); // v2:直接用 UPSERT…SELECT
} else {
// v1:按精度选表 + GET_METRIC_AGGREGATE_ONLY_SQL
}
2
3
4
5
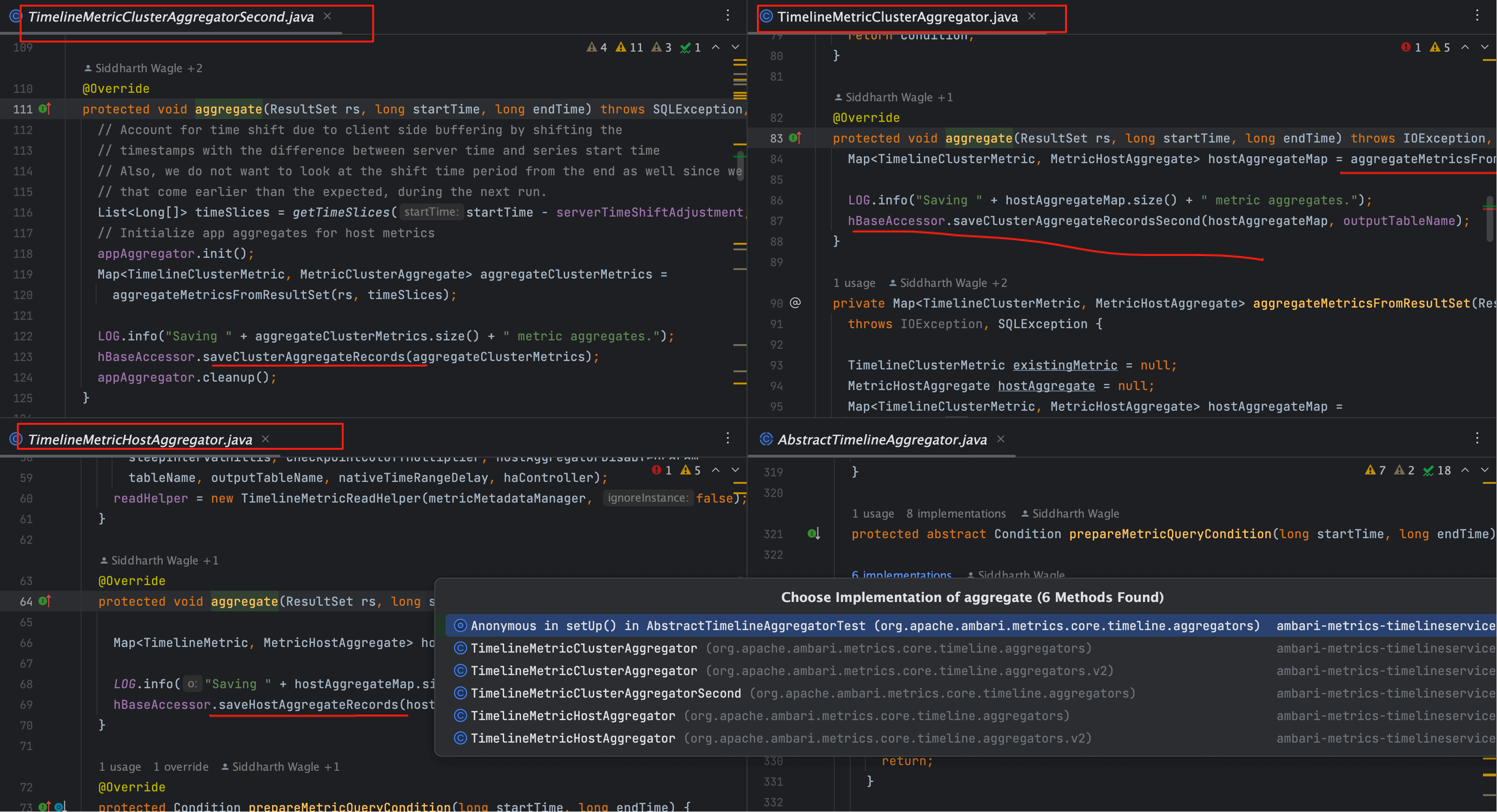
# 3、aggregate 干什么的
v2 多为记录窗口与目标表的日志;v1 则在这里触发 saveCluster/HostAggregateRecords*,把 ResultSet 分批 UPSERT。
int rows = stmt.executeUpdate();
conn.commit();
LOG.info(rows + " row(s) updated in aggregation.");
2
3
v1 的查询模板
public static final String GET_METRIC_AGGREGATE_ONLY_SQL =
"SELECT UUID, SERVER_TIME, METRIC_SUM, METRIC_MAX, METRIC_MIN, METRIC_COUNT FROM %s";
2
v1 将“查数据”和“写数据”物理解耦,便于 Java 侧进行分批封装与节奏控制。
# 三、v2 与 v1 的差异(边看图边对照)
速查表
| 维度 | v2:GroupBy 一步式 | v1:SELECT → saveXXX 分步 |
|---|---|---|
| SQL 形态 | UPSERT … SELECT … GROUP BY | 先 SELECT 后批量 UPSERT |
| Java 侧职责 | 轻(以日志/校验为主) | 重(封装行、批量提交) |
| 可观测性 | 看 row(s) updated) | 还可看分批大小和写入节奏 |
| 调优侧重 | Phoenix 计划/索引/统计 | 批量阈值、提交频率 |
继续对比 v2 的两类聚合器(主机/集群):
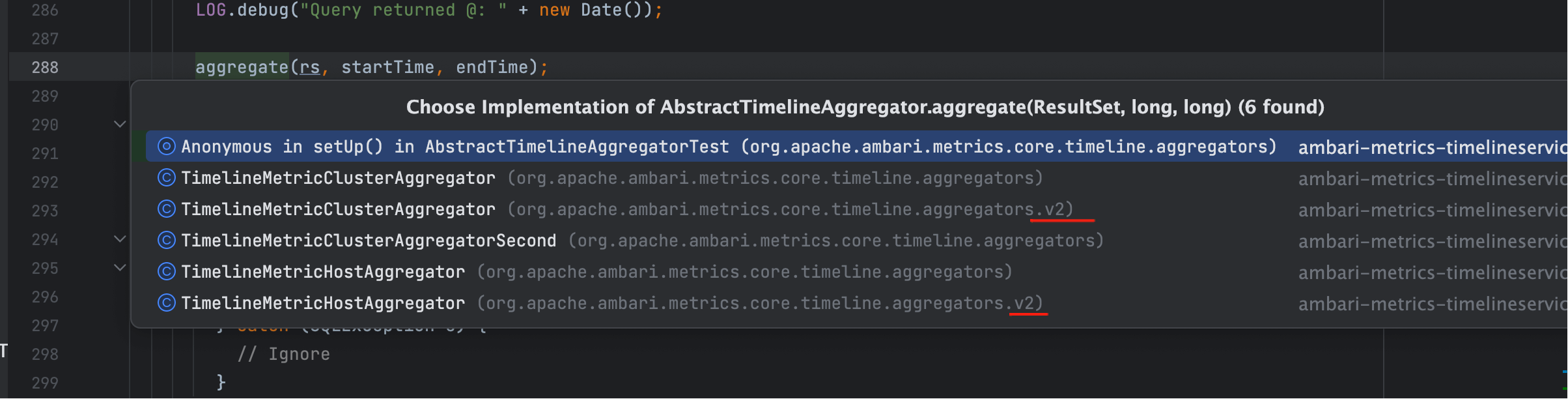
两者在 v2 中 aggregate 只做窗口记录;实际写入在 SQL 内联阶段完成。
# 四、选型与开关:谁让 v2 生效?
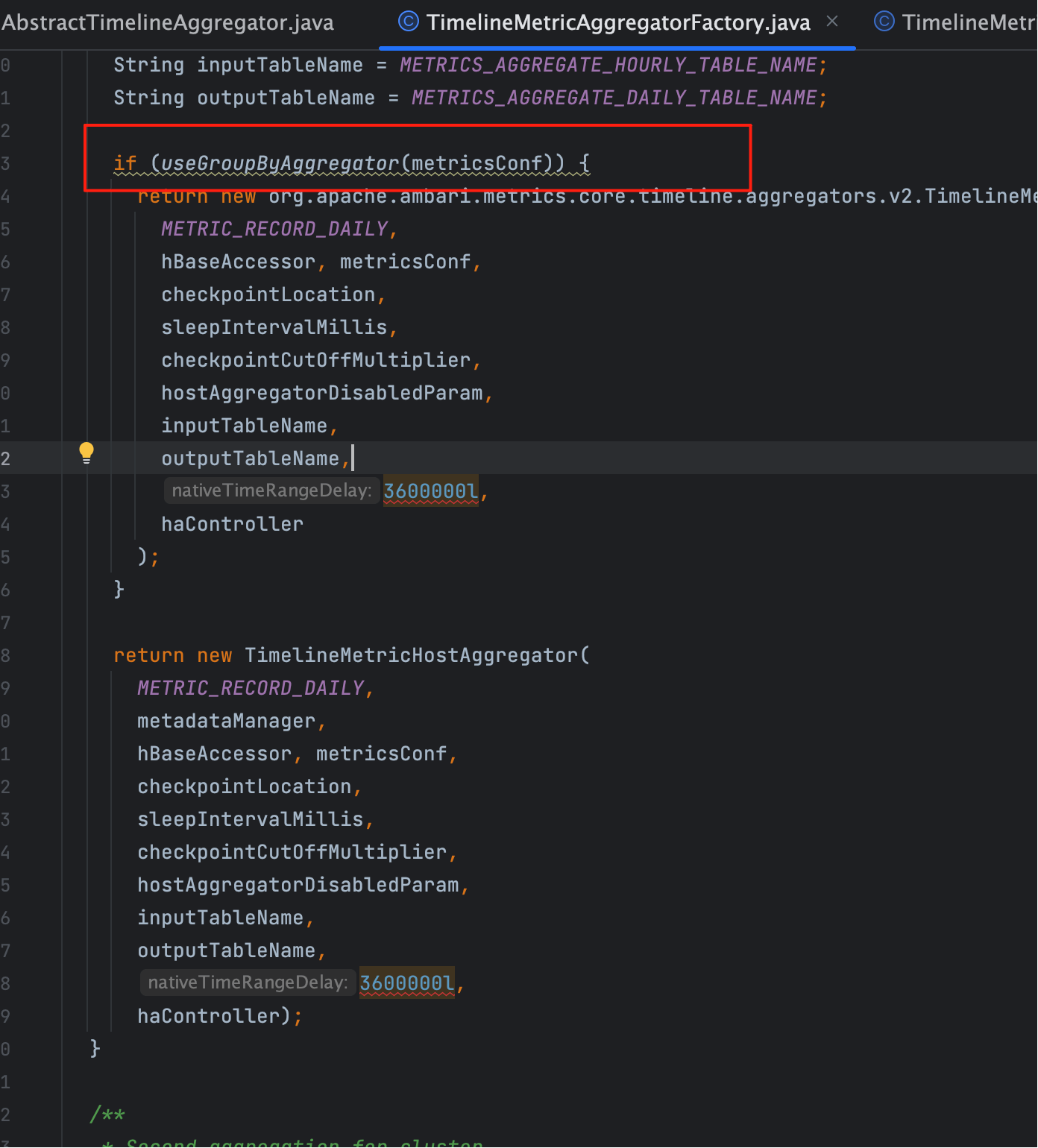
timeline.metrics.service.use.groupBy.aggregators
- true:实例化 v2 家族(Minute/Hour/Day × Host/Cluster),走 UPSERT…SELECT 主路径;
- false:回落 v1,两段式更易在 Java 侧做精细化控制。
上线建议
- 默认生产:开启 v2,减少调用栈复杂度;
- 排障回归:可短暂关闭改走 v1,观测批次/提交节奏定位非 Phoenix 侧瓶颈。
# 五、执行链路串讲:从“拼 SQL”到“写回库”
1、读取检查点并对齐窗口;
2、prepareMetricQueryCondition:v2 生成内联 UPSERT…SELECT;v1 只生成 SELECT;
3、prepareGetMetricsSqlStmt:补 WHERE/ORDER/LIMIT;
4、执行与提交:
- v2:一条语句完成聚合与写入;
- v1:
aggregate(rs)内saveXXX分批 UPSERT。
目标表定位
MINUTE → METRIC_RECORD_MINUTE_UUID
HOUR → METRIC_AGGREGATE_HOURLY[_UUID]
DAY → METRICS_AGGREGATE_DAILY[_UUID]
# 六、思考
在上文我们看到 doWork(startTime, endTime) 是聚合的真正入口。那问题来了:startTime / endTime 怎么决定?
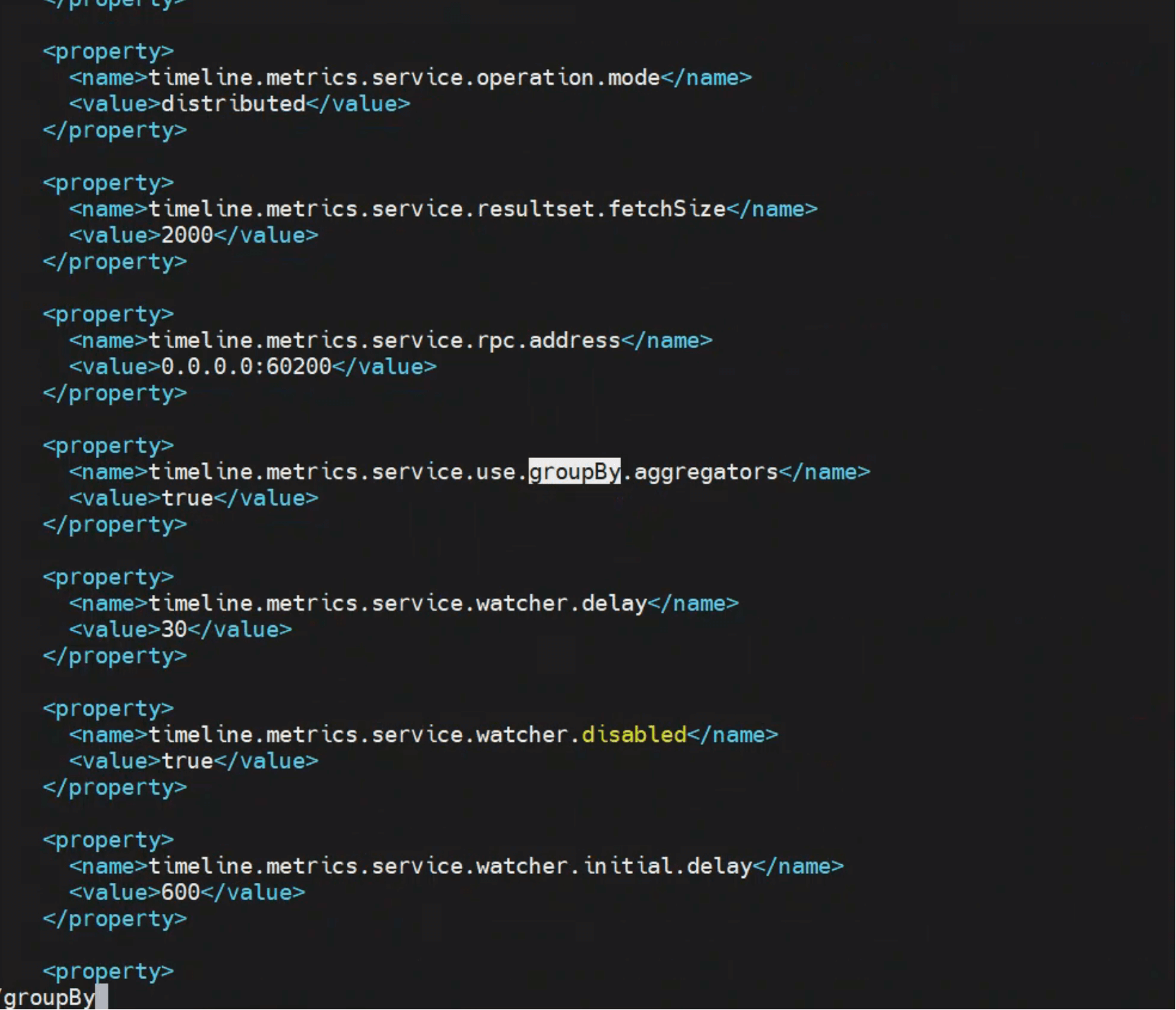
看源码(如下图红框部分):
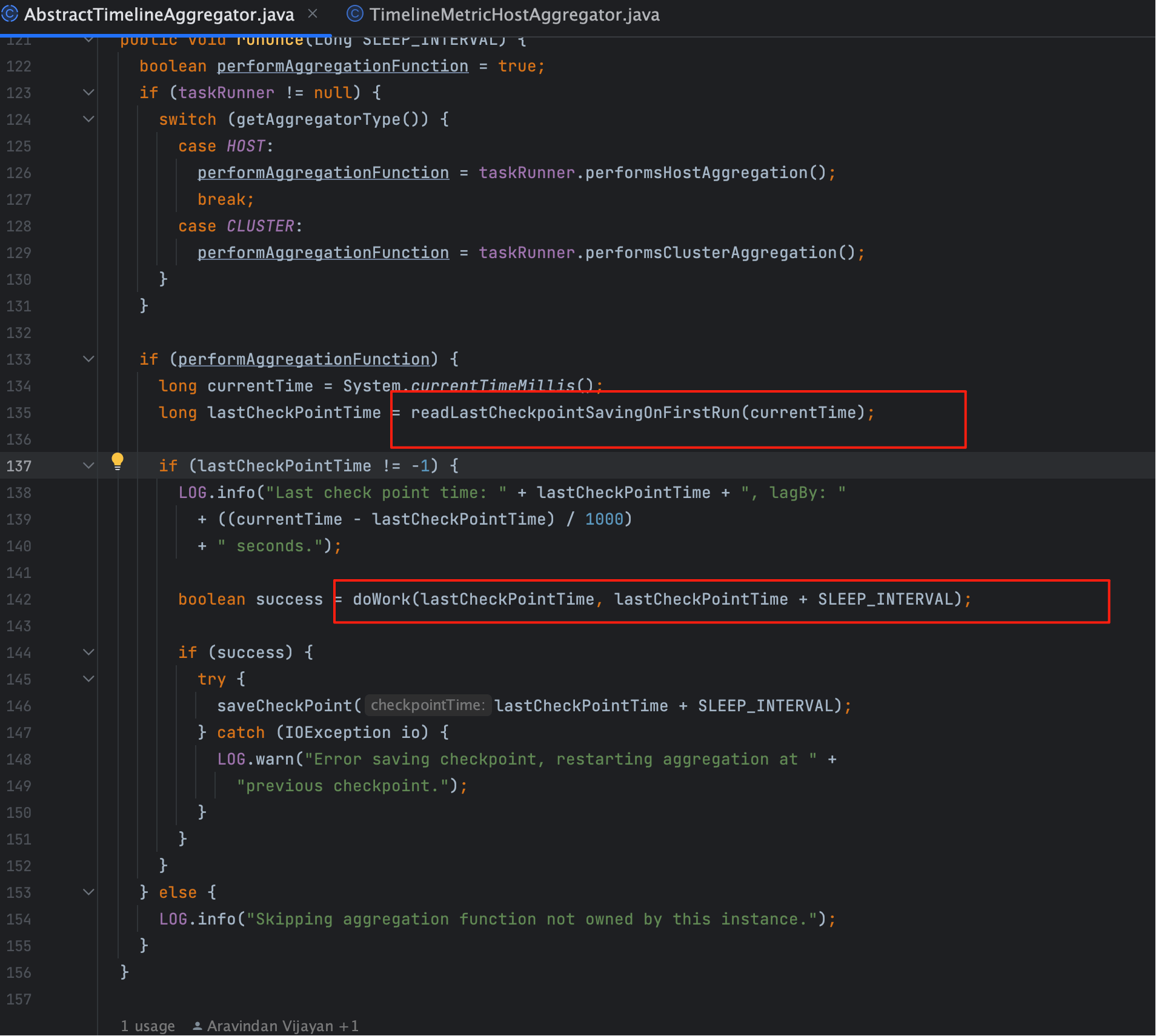
读取当前时间
long currentTime = System.currentTimeMillis();1Collector 先拿系统时间作为参考基准。
读取上次检查点
long lastCheckPointTime = readLastCheckpointSavingOnFirstRun(currentTime);1
- 如果是第一次运行,就用
currentTime做初始化(防止起点缺失); - 否则从存储中读取上次的 checkpoint。
决定窗口
doWork(lastCheckPointTime, lastCheckPointTime + SLEEP_INTERVAL);1
- startTime = 上次 checkpoint;
- endTime = checkpoint + 固定的
SLEEP_INTERVAL; - 这样每次
doWork就覆盖一个完整的窗口。
更新检查点
saveCheckPoint(lastCheckPointTime + SLEEP_INTERVAL);1聚合成功后,checkpoint 前移,等待下一轮调度。
注意
我们将在下一章,讲解检查点的原理