 [/metrics/aggregated] — 反向分析接口参数
[/metrics/aggregated] — 反向分析接口参数
# 一、问题背景与结论先行
先看结论
- 线上并未观察到对
/ws/v1/timeline/metrics/aggregated的 POST 请求,推断该接口并未被常规采集/查询链路使用。 - 聚合表有数据并非来自上述 REST 接口,而是由 Collector 内部的聚合与落库任务写入(分钟/小时/日粒度),走 HBase/Phoenix 的 upsert 语句完成持久化。
- 需要定位聚合异常时,应优先排查 内部聚合调度与
saveHostAggregateRecords写入路径,而不是关注对外 REST。
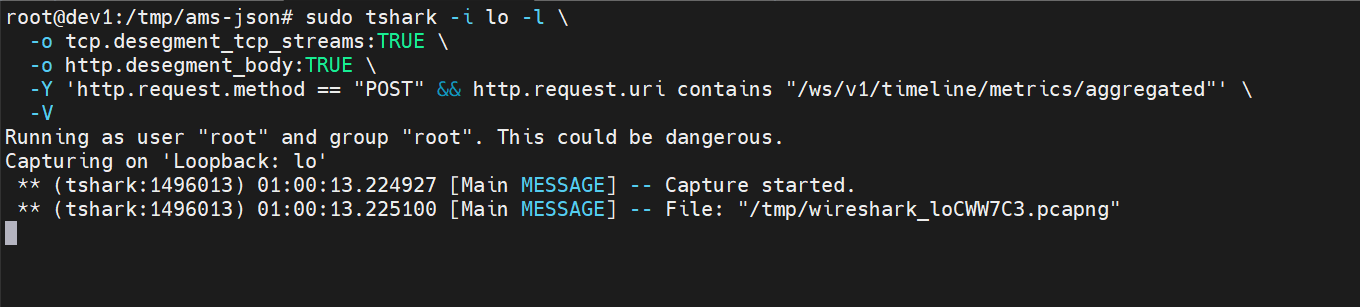
我们最初尝试用抓包来验证“是否有客户端在调这个聚合接口”,思路是对本机 6188 端口持续监听 HTTP POST。
本地Collector 6188 持续监听sudo tshark -i lo -l \
-o tcp.desegment_tcp_streams:TRUE \
-o http.desegment_body:TRUE \
-Y 'http.request.method == "POST" && http.request.uri contains "/ws/v1/timeline/metrics/aggregated"' \
-V
1
2
3
4
5
2
3
4
5
我们将程序运行超过 12 小时仍无任何输出,说明没有外部请求命中该 URI。 下文将基于“表里有数据 → 反推谁写的 → 源码定位”进行完整闭环分析。
# 二、从数据面反推:聚合表为何在“动”
为了避免“没有请求就一定没有数据”的误判,我们直接查 Phoenix 聚合总表:
SELECT metric_sum,
hosts_count,
metric_max,
metric_min,
uuid,
server_time,
TO_CHAR(DATE '1970-01-01 00:00:00' + server_time * 0.001 / 86400, 'yyyy-MM-dd HH:mm:ss') AS server_time_fmt
FROM METRIC_AGGREGATE_UUID
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
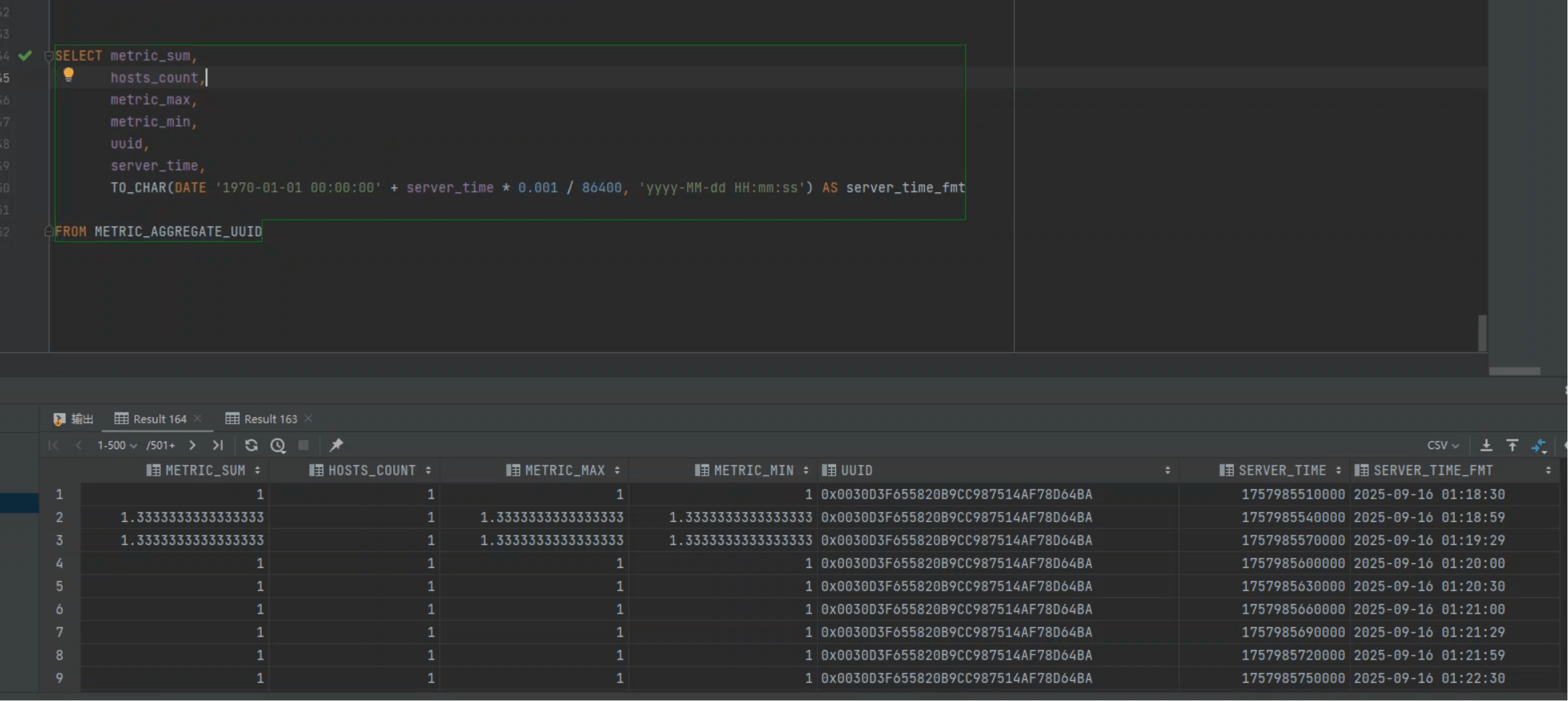
Phoenix 时间戳小贴士
server_time 为 epoch 毫秒(BIGINT)。常见误区是将毫秒直接喂给 TO_DATE/TO_TIMESTAMP 的 VARCHAR 形态,导致类型不匹配。
上面的写法通过“纪元日期 + 天数换算(毫秒÷86400÷1000)”得到可读时间,避免类型错误且性能稳定。
进一步结合 分钟/小时/日等聚合分表,可见数据在持续产出,这与抓包“无接口调用”的现象并不矛盾: 写入走的是内部聚合路径。
# 三、从代码面定位:聚合数据如何写入
# 1、关键调用链
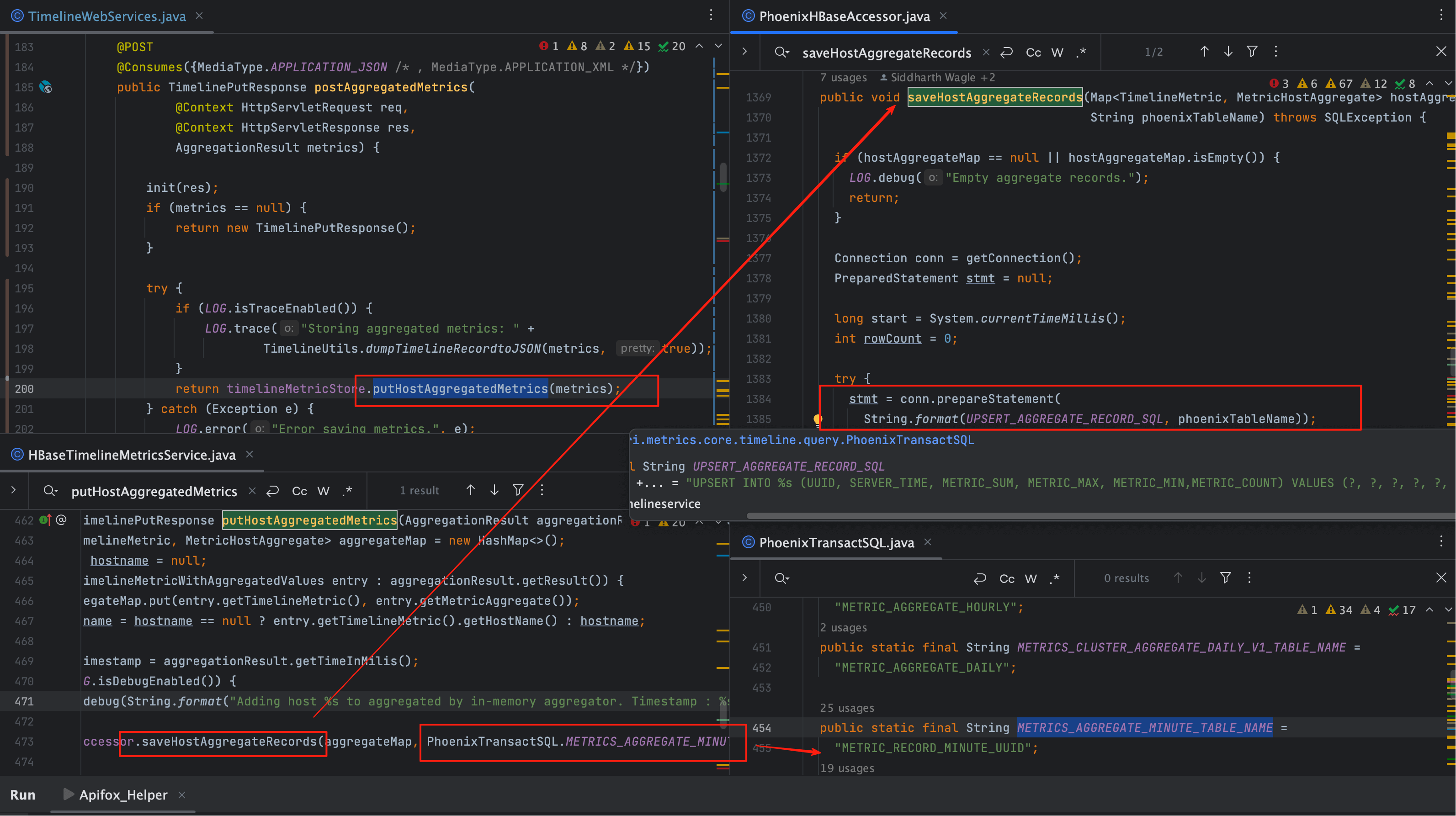
展开源码脉络(概念化)
- 业务端产生的明细指标先落入明细表;
- Collector 内部的聚合执行器触发(按分钟/小时/日窗口);
- 调用
putHostAggregatedMetrics(AggregationResult aggregationResult); - 进而转到
hBaseAccessor.saveHostAggregateRecords (aggregateMap, PhoenixTransactSQL.METRICS_AGGREGATE_MINUTE_TABLE_NAME); - Phoenix 侧执行 UPSERT,将聚合结果写入 分钟聚合表 或其他粒度表。
这里的 PhoenixTransactSQL.METRICS_AGGREGATE_MINUTE_TABLE_NAME 在实现中指向带主机维度的分钟表(20B 含 host 维度的
rowkey):
"METRIC_RECORD_MINUTE_UUID"
# 2、写入 SQL 模板与方法签名
public static final String UPSERT_AGGREGATE_RECORD_SQL = "UPSERT INTO " +
"%s (UUID, " +
"SERVER_TIME, " +
"METRIC_SUM, " +
"METRIC_MAX, " +
"METRIC_MIN," +
"METRIC_COUNT) " +
"VALUES (?, ?, ?, ?, ?, ?)";
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
public void saveHostAggregateRecords(Map<TimelineMetric, MetricHostAggregate> hostAggregateMap,
String phoenixTableName)
1
2
2
观察点
- 表名是动态参数:由调度窗口与维度决定(分钟/小时/日,不同是否含 host)。
- 值域统一:
SUM/MAX/MIN/COUNT等字段齐备,便于后续二次聚合与 TopN。 - 接口“未用”不影响写入:内部聚合任务直接 upsert,不需要外部 REST 触发。
# 四、证据链小结(抓包/表/代码的“三角验证”)
| 证据点 | 观测/结论 | 说明 |
|---|---|---|
| 抓包(12h+) | 无任何命中 POST /ws/v1/timeline/metrics/aggregated | 线上采集/查询链路并未用此 REST 接口 |
| Phoenix 查询 | METRIC_AGGREGATE_UUID 及分表数据持续更新 | 聚合数据“在动”,说明内部产出 |
| 源码路径 | putHostAggregatedMetrics → saveHostAggregateRecords → UPSERT | 聚合由内部任务写入,表名动态、语义清晰 |
误区排除
- 看不到 REST 调用 ≠ 没有聚合数据;
- 有聚合数据 ≠ 一定来自
/metrics/aggregated; - 聚合异常排查,优先看内部聚合任务与 Phoenix Upsert 是否成功。