 [监控表] — 建表切分策略避免热点
[监控表] — 建表切分策略避免热点
# 一、前序章节回忆
笔记
我们已在前文完成三件事:
- 业务表(秒表、分表、聚合表)的执行逻辑梳理;
- 基础表与业务表的关联关系;
- 控制器/Provider 协作模式与启动主链路。
本文继续深入 hBaseAccessor.initMetricSchema(),把 “建表切分策略” 拆到每一步,让“如何避免热点”变成具体可操作的工程实践。
// 入口之一:初始化业务表结构与分区
hBaseAccessor.initMetricSchema();
2
# 二、章节引入:为何要在建表阶段“切分”?
读写热点的本质
AMS 的高频写表(如秒表、分钟表)若只建为单 Region,大量相同前缀的 RowKey 会在同一 Region 聚集,写入与 compact 压力集中到单台 RegionServer,形成热点。
如下图所示,高频表在建表时会添加 SPLIT ON(...),使其天然跨多个 Region:
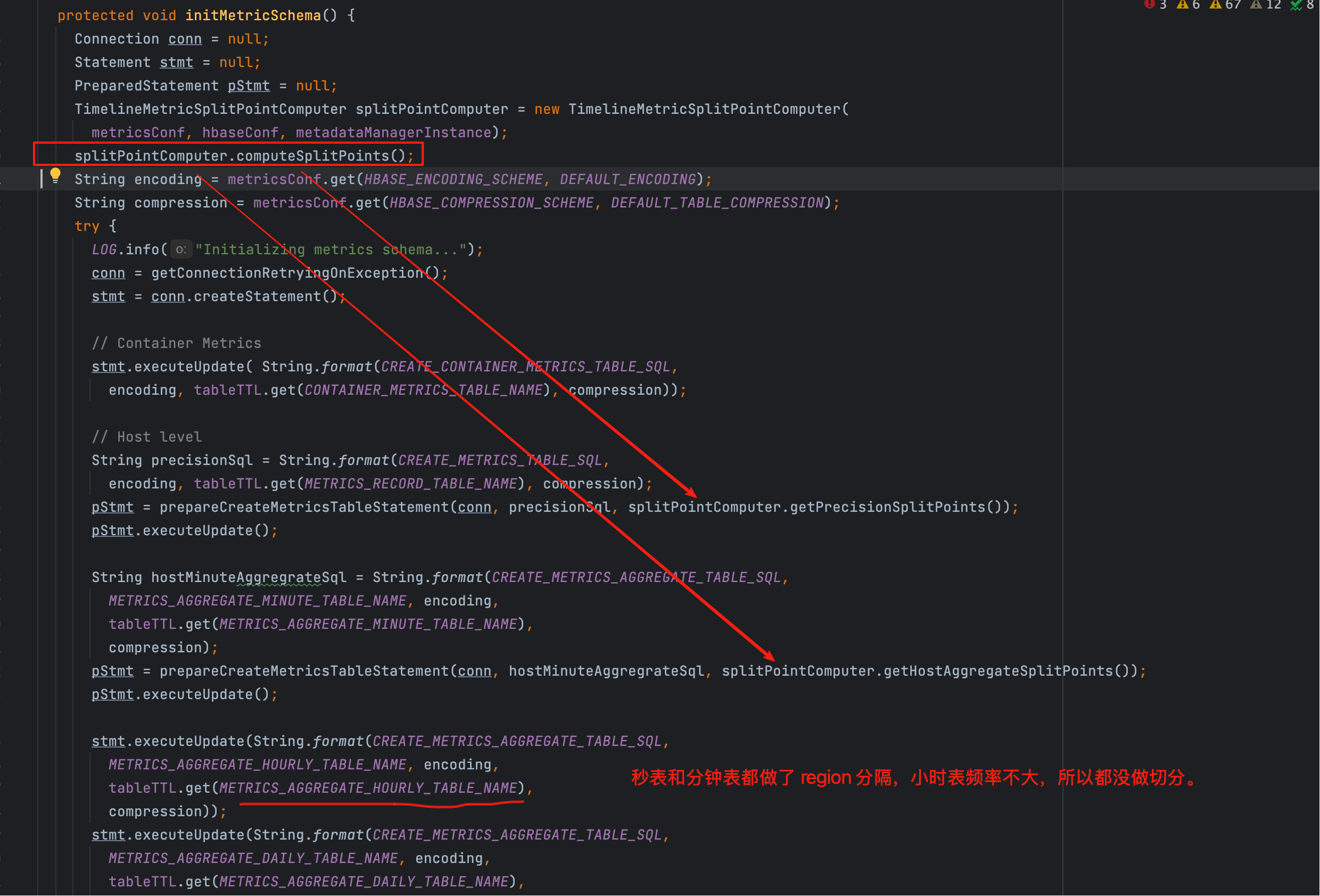
这里的“切分点”是什么?
Phoenix 的 SPLIT ON(...) 接收有序的 rowkey 前缀边界(字节序),HBase 会按该边界创建多个 Region。AMS 的做法是:
以Metric 维度的 UUID 前缀作为切分点,将不同 Metric 的写入均摊到不同 Region。
# 三、总体流程鸟瞰(从“参数→计算→建表”)
flowchart TD
A[加载 hbase-site.xml / ams-site.xml] --> B[读取内存阈值与 flush 策略]
B --> C[估算 maxInMemoryRegions]
C --> D[确定目标 Region 数: 精度表/聚合表]
D --> E[收集并排序 Metric 清单: Master/Slave, appId, metricName]
E --> F[按步长选点: idx=ceil(total/regionCount)]
F --> G[将选中 Metric 转换为 UUID (cluster-level)]
G --> H[得到 splitPoints(precision/aggregate)]
H --> I[拼接 Phoenix 建表 SQL: SPLIT ON(...)]
2
3
4
5
6
7
8
9
关键边界
- RowKey 设计:精度表通常以
UUID + SERVER_TIME DESC作为联合主键 → 以UUID做切分最“稳”。 - SPLIT ON 顺序:切分点必须有序且去重,否则建表报错或 Region 不如预期。
# 四、关键类与方法定位
# 1、代码落点与职责
| 模块/类名 | 作用 | 备注 |
|---|---|---|
hBaseAccessor.initMetricSchema() | 入口 | 初始化所有业务表(精度/聚合/临时) |
computeSplitPoints() | 计算切分点 | 决定目标 Region 数与具体 split 列表 |
getSortedMetricListForSplitPoint() | 构造并排序 Metric 清单 | 按组件(Master/Slave)、指标体量构造列表 |
timelineMetricMetadataManager.getUuid(...) | 度量标识映射 | 将(metricName, appId, …)映射到 UUID |
CREATE TABLE ... SPLIT ON(...) | 最终建表 | Phoenix/HBase 侧实际生效 |
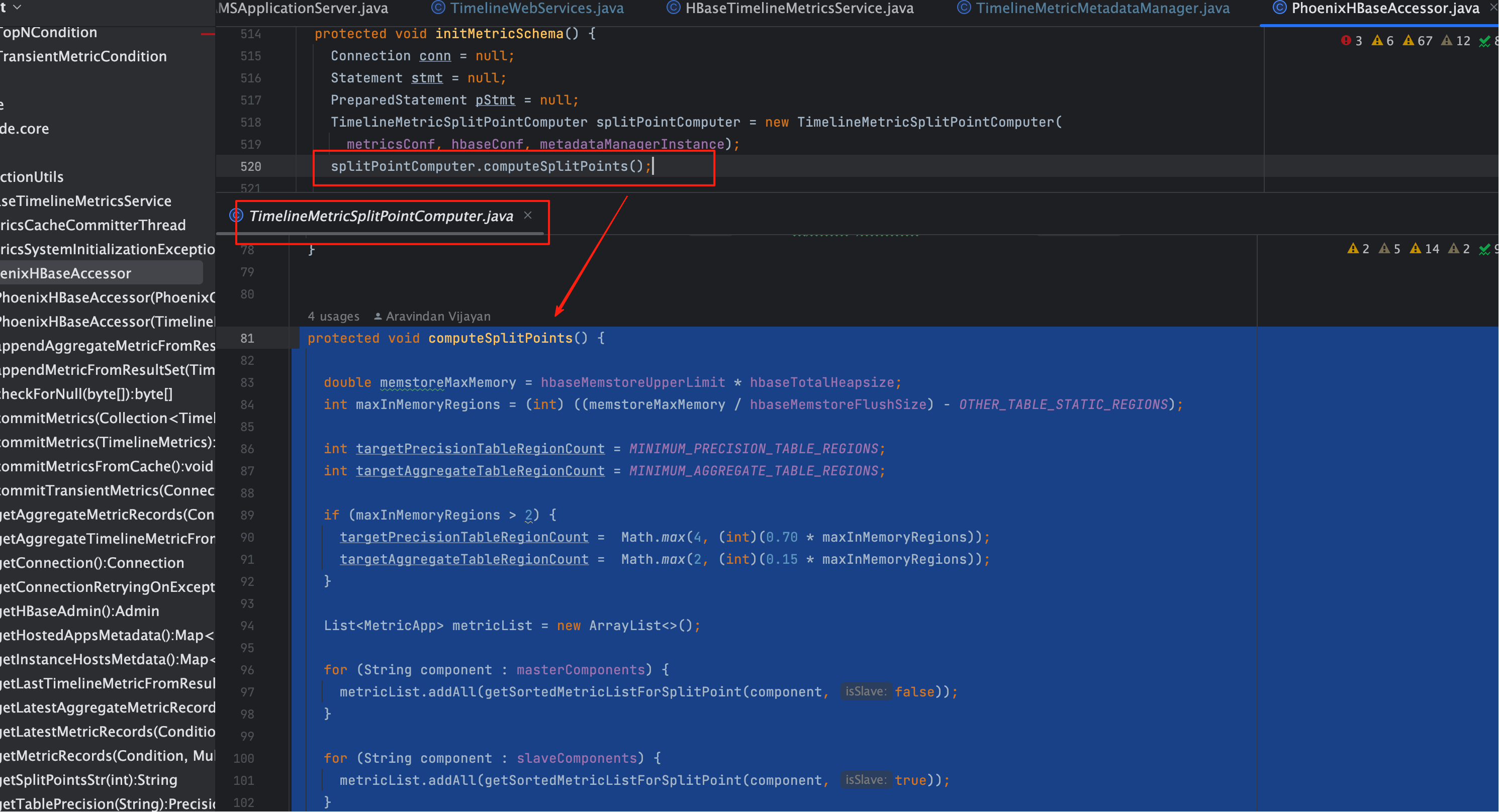
# 2、示意源码(节选 + 释义)
protected void computeSplitPoints() {
// 4.1 依据 RegionServer 内存与 flush 策略估算“可承载的活跃 Region 数”
double memstoreMaxMemory = hbaseMemstoreUpperLimit * hbaseTotalHeapsize;
int maxInMemoryRegions = (int) ((memstoreMaxMemory / hbaseMemstoreFlushSize) - OTHER_TABLE_STATIC_REGIONS);
// 4.2 分别给“精度表/聚合表”设定目标 Region 数(默认值 + 动态放大系数)
int targetPrecisionTableRegionCount = MINIMUM_PRECISION_TABLE_REGIONS;
int targetAggregateTableRegionCount = MINIMUM_AGGREGATE_TABLE_REGIONS;
if (maxInMemoryRegions > 2) {
targetPrecisionTableRegionCount = Math.max(4, (int)(0.70 * maxInMemoryRegions));
targetAggregateTableRegionCount = Math.max(2, (int)(0.15 * maxInMemoryRegions));
}
// 4.3 收集待切分的 Metric 清单(Master/Slave 组件)
List<MetricApp> metricList = new ArrayList<>();
for (String component : masterComponents) {
metricList.addAll(getSortedMetricListForSplitPoint(component, false)); // false=master
}
for (String component : slaveComponents) {
metricList.addAll(getSortedMetricListForSplitPoint(component, true)); // true=slave
}
// 4.4 按“步长 idx = ceil(total / regionCount)”选取分隔点
int totalMetricLength = metricList.size();
if (targetPrecisionTableRegionCount > 1) {
int idx = (int) Math.ceil(totalMetricLength / targetPrecisionTableRegionCount);
int index = idx;
for (int i = 0; i < targetPrecisionTableRegionCount; i++) {
if (index < totalMetricLength - 1) {
MetricApp m = metricList.get(index);
byte[] uuid = timelineMetricMetadataManager.getUuid(
new TimelineClusterMetric(m.metricName, m.appId, null, -1), true);
precisionSplitPoints.add(uuid);
index += idx;
}
}
}
if (targetAggregateTableRegionCount > 1) {
int idx = (int) Math.ceil(totalMetricLength / targetAggregateTableRegionCount);
int index = idx;
for (int i = 0; i < targetAggregateTableRegionCount; i++) {
if (index < totalMetricLength - 1) {
MetricApp m = metricList.get(index);
byte[] uuid = timelineMetricMetadataManager.getUuid(
new TimelineClusterMetric(m.metricName, m.appId, null, -1), true);
aggregateSplitPoints.add(uuid);
index += idx;
}
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
# 五、参数来源与公式解释
# 1、参数来自哪里?
| 参数 | 含义 | 建议来源 |
|---|---|---|
hbaseTotalHeapsize | RegionServer JVM 堆大小 | hbase-env.sh / 监控探测 |
hbaseMemstoreUpperLimit | memstore 使用上限(比例) | hbase-site.xml:hbase.regionserver.global.memstore.upperLimit |
hbaseMemstoreFlushSize | 单 Region flush 阈值 | hbase-site.xml:hbase.hregion.memstore.flush.size |
OTHER_TABLE_STATIC_REGIONS | 预留给其他系统表的 Region 数 | 代码常量/经验值 |
MINIMUM_*_TABLE_REGIONS | 最小 Region 数 | 代码常量/配置 |
估算含义
maxInMemoryRegions ≈ (可用 memstore 总量 / 单 Region flush 阈值) - 预留
它是单机能稳定承载的活跃 Region 数近似值,后续映射为“目标分区数”。
# 2、目标 Region 数如何给?
- 精度表(秒/分级):默认至少 4 个,若内存足够 → 取
max * 70%; - 聚合表(5m/1h/1d):默认至少 2 个,若内存足够 → 取
max * 15%。
为什么比例不同?
精度表写入频次高,必须更强的并发承载能力;聚合表写入相对低,但读查询较多,Region 数偏保守更有利于 scan 合并。
# 六、指标清单如何构造与排序?
# 1、源数据来自哪里?
- 组件与指标的“定义清单”通常来自 指标定义文件(dat) 与 组件注册信息(appId);
getSortedMetricListForSplitPoint(component, isSlave)会把同一组件下的metricName + appId拼成候选列表。
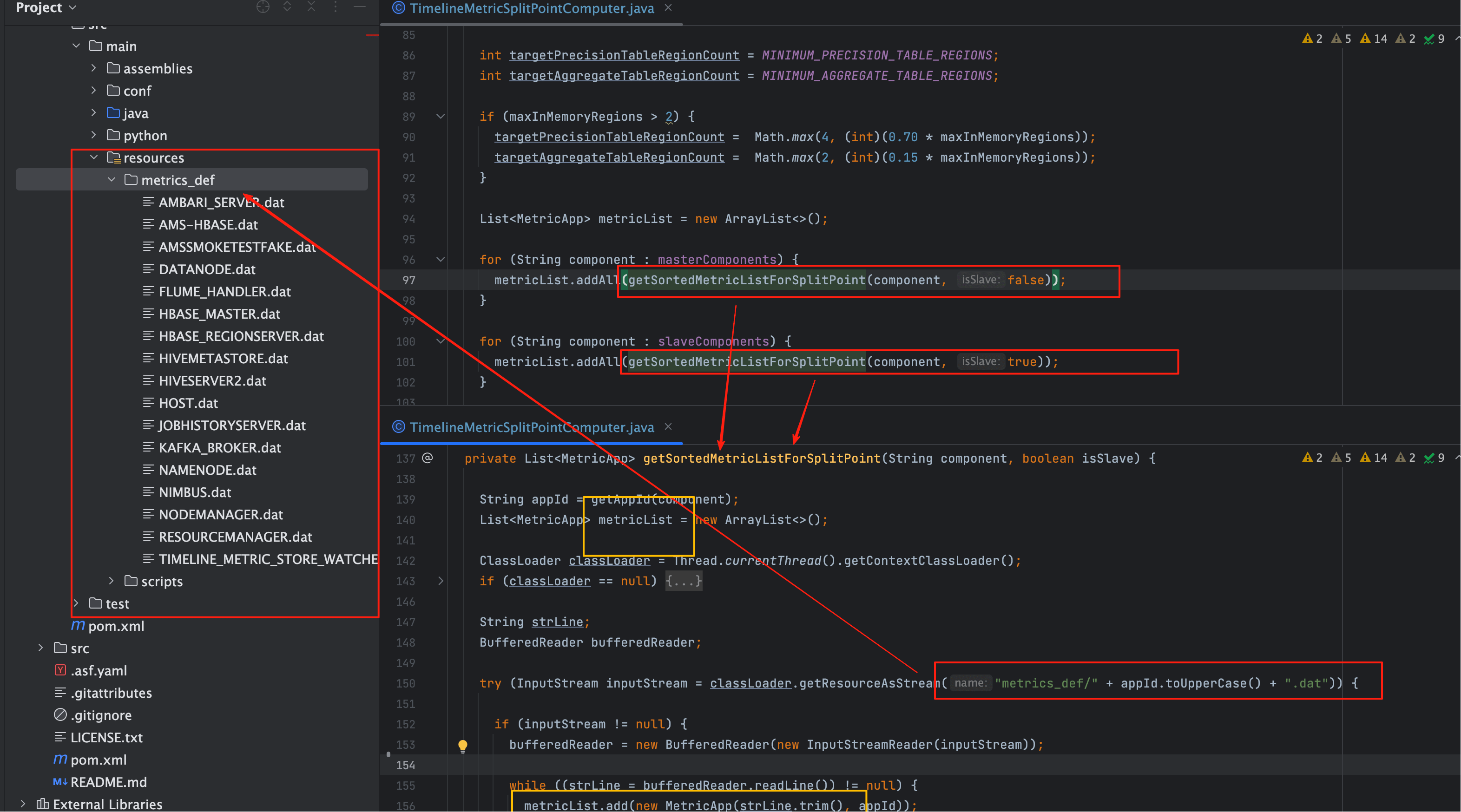
# 2、Master/Slave 差异
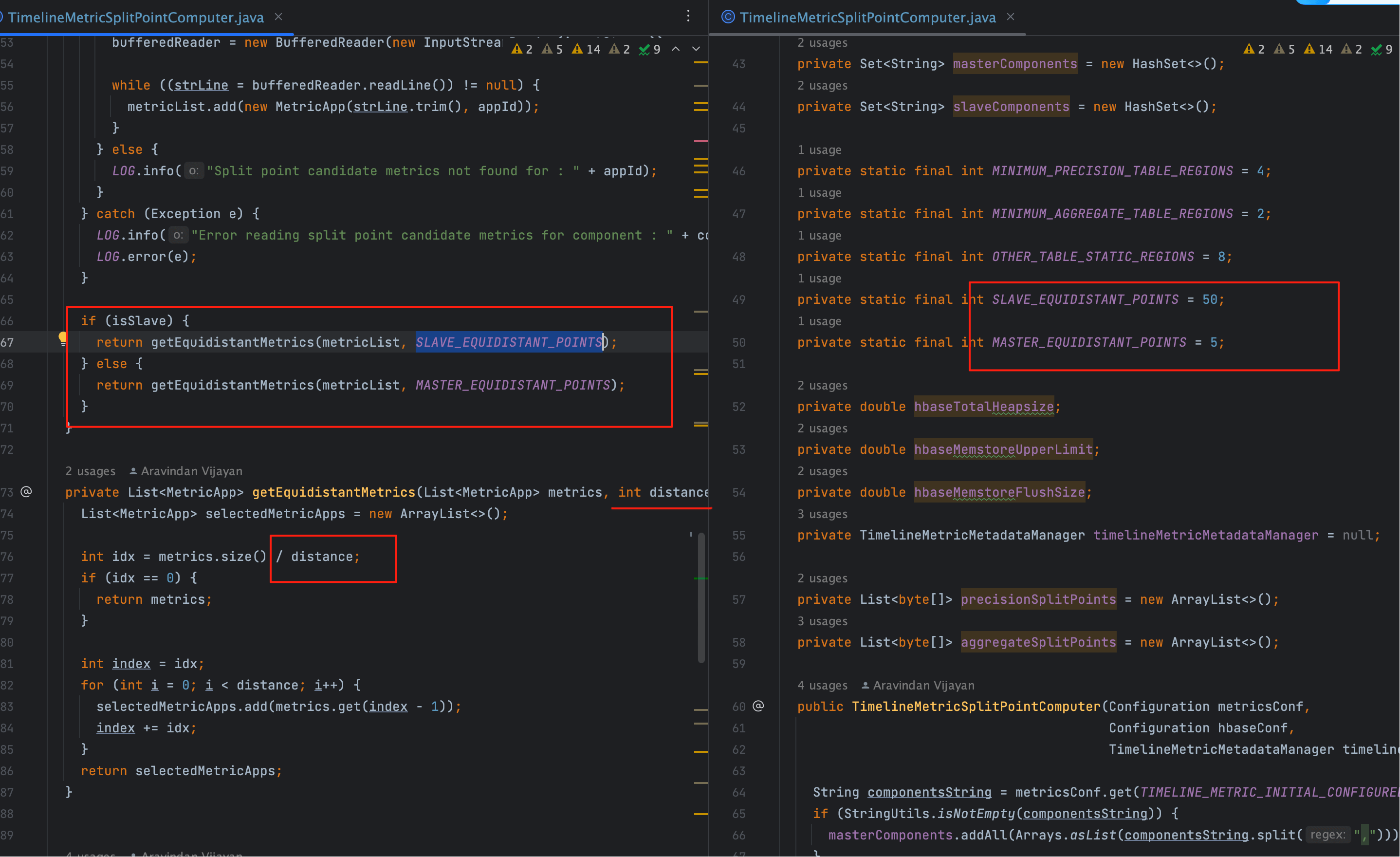
- Slave 组件(如 Datanode、NodeManager):数量多、指标体量大 → 步长粗(≈50 条/点);
- Master 组件(如 HBase Master、RM):实例少、指标相对精简 → 步长细(≈10 条/点)。
这样做的好处
- 大体量组件不会把切分点“挤”在少数几个指标附近;
- 小体量但关键的 Master 指标也能得到较均匀的 Region 覆盖。
# 3、指标体量直观示例
# 七、如何“从清单到切分点”?
# 1、步长与取点规则
公式
设 N = metricList.size(),目标 Region 数为 R (>1),
则步长 idx = ceil(N / R);
取点索引序列:idx, 2*idx, 3*idx, ...(越界/末尾会跳过)。
# 2、为什么用“cluster 级 UUID”作为切分点?
// 注意:以 cluster 级维度构造 UUID —— 不带 instanceId/host
new TimelineClusterMetric(metricName, appId, null, -1)
2
- RowKey 前缀:精度表主键一般是
(UUID, SERVER_TIME DESC); - 切分点只需对“首维”生效 → 用
UUID作为边界即可把写入均衡到不同 Region; - 不带实例:避免千万级 instanceId/host 维度导致切分点数量失控。
# 3、均衡性分析
- 指标越多的组件,越有机会被选为“分界点” → 数据量与 Region 覆盖大致正相关;
- Master/Slave 的不同“步长”进一步减少极端倾斜;
- 结合
precision/aggregate两套切分点集合,精度与聚合层分别达成合理均衡。
# 八、Phoenix 建表与 SPLIT ON 拼接
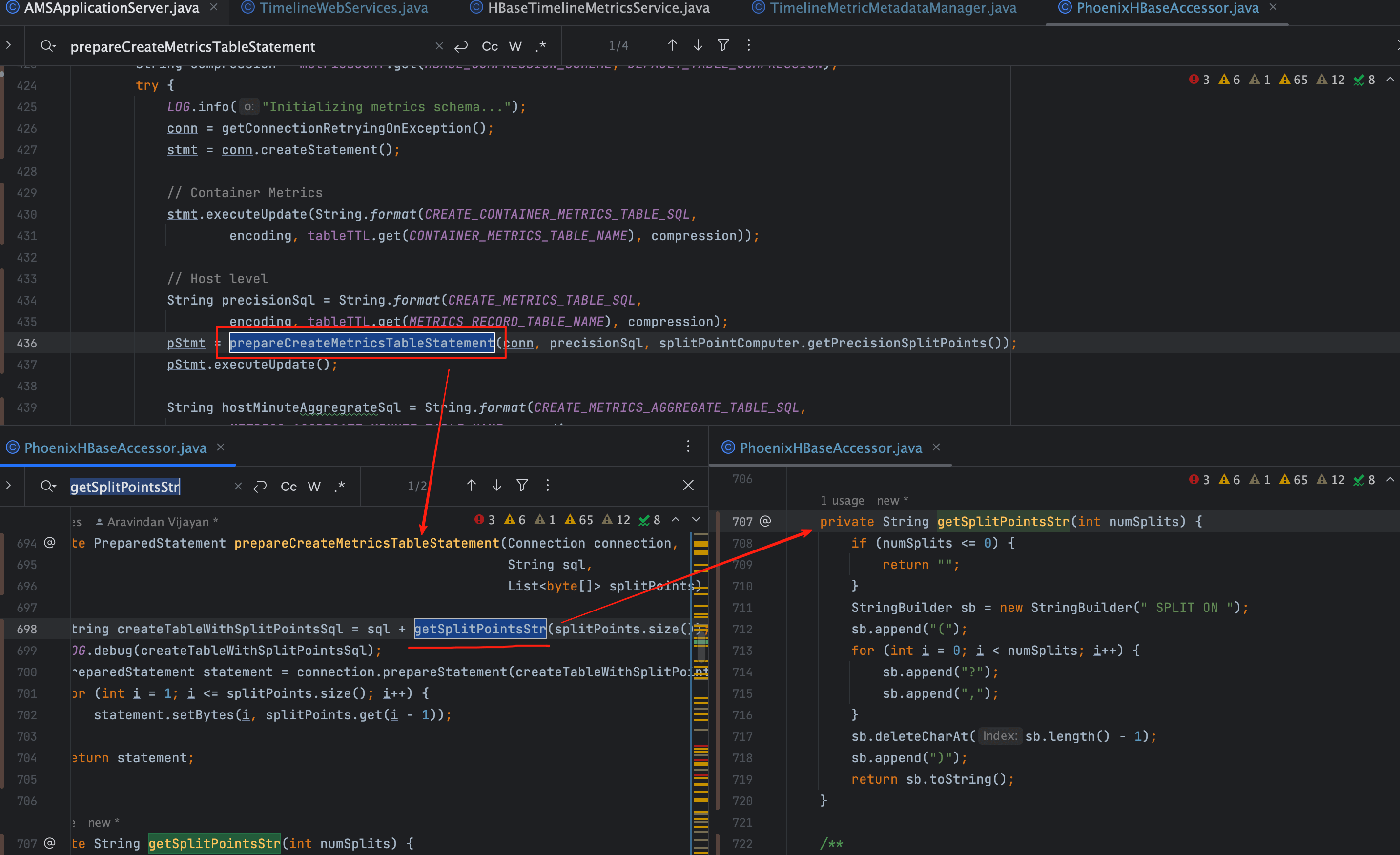
# 1、主键与切分维度
| 表 | 主键示例 | 切分维度 |
|---|---|---|
METRIC_RECORD_UUID(秒/分精度) | (UUID, SERVER_TIME DESC) | UUID |
METRIC_AGGREGATE_UUID(聚合层) | (UUID, SERVER_TIME) | UUID |
提示
若主键首列不是 UUID,则需要相应调整切分点生成逻辑,确保切分点落在主键排序最前沿的维度。
# 2、字节序与格式
- Phoenix 的
SPLIT ON期望字节序(通常写为X'..'或\x..形式); - 由
timelineMetricMetadataManager.getUuid(...)返回的byte[]会按升序写入到SPLIT ON(...)。
# 3、示例 SQL(示意)
CREATE TABLE METRIC_RECORD_UUID (
UUID BINARY(16) NOT NULL,
SERVER_TIME UNSIGNED_LONG NOT NULL,
METRIC_SUM DOUBLE,
METRIC_COUNT DOUBLE,
METRIC_MIN DOUBLE,
METRIC_MAX DOUBLE,
CONSTRAINT PK PRIMARY KEY (UUID, SERVER_TIME DESC)
)
SPLIT ON (
X'1009A3...', X'201F7B...', X'3090CC...', X'40AF12...'
);
2
3
4
5
6
7
8
9
10
11
12
常见坑
- 切分点无序 → Phoenix 报错或被重排;
- 切分点太少 → Region 不足,热点仍在;
- 切分点太多 → Region 过多,增加 compaction/开销;
- RowKey 设计与切分维度不一致 → 切分“无效化”。
# 九、写热点是如何被彻底规避的?
# 1、RowKey 层面
- 以
UUID为前缀的联合主键使得同一时间片的数据不会按时间聚集在同一 Region; SERVER_TIME放在二级列(且常为 DESC)→ 写入在“同一 UUID”内部更趋向时间散列。
# 2、组件/指标层面
- 以 metric/appId 映射到
UUID,天然把不同指标族路由到不同 Region; - Master/Slave 的步长差异 + 指标体量排序 → 缩小“超大组件吞噬 Region”的风险。
# 3、资源承载层面
- 目标 Region 数与
maxInMemoryRegions挂钩 → 保证单机不会过载; - 精度表/聚合表独立计算 → 写多与读多层面各取所需。
# 十、验证与运维检查(强烈建议掌握)
# 1、建表后核对 Region 列表
HBase Shell
list_namespace_tables 'default'/describe 'METRIC_RECORD_UUID'scan 'hbase:meta'过滤该表,确认 Region 边界是否与SPLIT ON对齐
# 2、Phoenix Explain 观察“并行度”
EXPLAIN SELECT ... FROM METRIC_RECORD_UUID ...- 关注输出中的
N-WAY PARALLEL SCAN、RANGE SCAN、FIRST KEY ONLY等关键词,确认是否多 Region 扫描。
# 3、监控维度
| 观察项 | 工具/位置 | 判定要点 |
|---|---|---|
| Region 分布 | HBase UI / hbase shell | Region 个数 ≈ 目标;分布均衡 |
| 写入吞吐 | AMS Collector 日志/指标 | 队列无持续积压 |
| Compact 频次 | HBase UI | 频次与时长是否异常 |
| GC/堆使用 | RegionServer/JVM | 符合期望阈值,无频繁 Full GC |
# 十一、参数调优与规模化建议
# 1、不同规模集群的经验映射
| 规模 | RS 堆(示例) | upperLimit | flush.size | 精度表 Region 目标 | 聚合表 Region 目标 |
|---|---|---|---|---|---|
| 小型(≤5 RS) | 8–16G | 0.4–0.5 | 128–256MB | 4–8 | 2–4 |
| 中型(5–20 RS) | 16–32G | 0.4–0.6 | 256–512MB | 8–32 | 4–12 |
| 大型(20+ RS) | 32–64G | 0.5–0.7 | 512–1024MB | 32–96 | 8–24 |
笔记
此表为起步建议,以“写入峰值/查询模式/硬件配置”为准微调,重点观察 compaction 与 GC。
# 2、手工加 Region 的正确姿势
- 业务量增长后,可用
SPLIT指令在线加 Region; - 优先对写热点明显的 UUID 前缀区间进行二分;
- 逐步分裂,避免一次性倍增导致 compaction 风暴。
# 3、何时重建更合适?
- 早期未使用
SPLIT ON、RowKey 选型不当造成“天然热点”; - 单表已达超大 Region 数(> 数千)且历史数据多,可结合归档/冷热分层策略重建。
# 十二、常见误区与规避清单
误区清单
- 只看 QPS,不核对 RowKey 维度 与 切分维度 是否一致;
- 误把
SERVER_TIME当切分点 → 时间热点没解决; - 所有表统一用同一套切分点 → 忽略“精度 vs 聚合”的模式差异;
- 忽略
upperLimit / flush.size,盲目堆 Region 数 → 反而导致频繁 flush/compact。
# 十三、落地清单(Checklist)
- [ ] 明确 RowKey:
(UUID, SERVER_TIME[ DESC ]) - [ ] 校核 HBase 内存参数:
upperLimit / flush.size / 堆 - [ ] 估算
maxInMemoryRegions - [ ] 设定精度/聚合的目标 Region 数(≥最小值)
- [ ] 收集 Metric 清单(Master/Slave + appId + metricName)并排序
- [ ] 用
idx=ceil(N/R)取点 → 生成UUID切分点 - [ ] Phoenix 建表附带
SPLIT ON(...)(有序/去重) - [ ] HBase/Phoenix 校验 Region 与 Explain Plan
- [ ] 运行期监控写入/compact/GC,必要时逐步加 Region
# 十四、配图与源码定位(便捷回顾)
# 1、SPLIT ON 实参注入点
# 2、计算切分点核心方法
# 3、Master/Slave 步长与指标体量示例