 [/metrics] — 普通指标写入方法POST
[/metrics] — 普通指标写入方法POST
# 一、先看结论
结论
1)向 http://<collector>:6188/ws/v1/timeline/metrics 发送 JSON 写入请求即可新增自定义指标;
2)Collector 返回 <response/> 代表 写入已受理;
3)元数据表(METRICS_METADATA_UUID)有延迟,新指标需要等一会儿才会出现;
4)用 /metrics 查询接口拉取刚写入的序列,与入参逐点对比一致,即可判定写入成功。
# 二、准备与前置检查
# 1、确认请求目标与端口
- Collector 入口:
/ws/v1/timeline/metrics - 默认端口:
6188
# 2、SQL:按 appId 预检查元数据
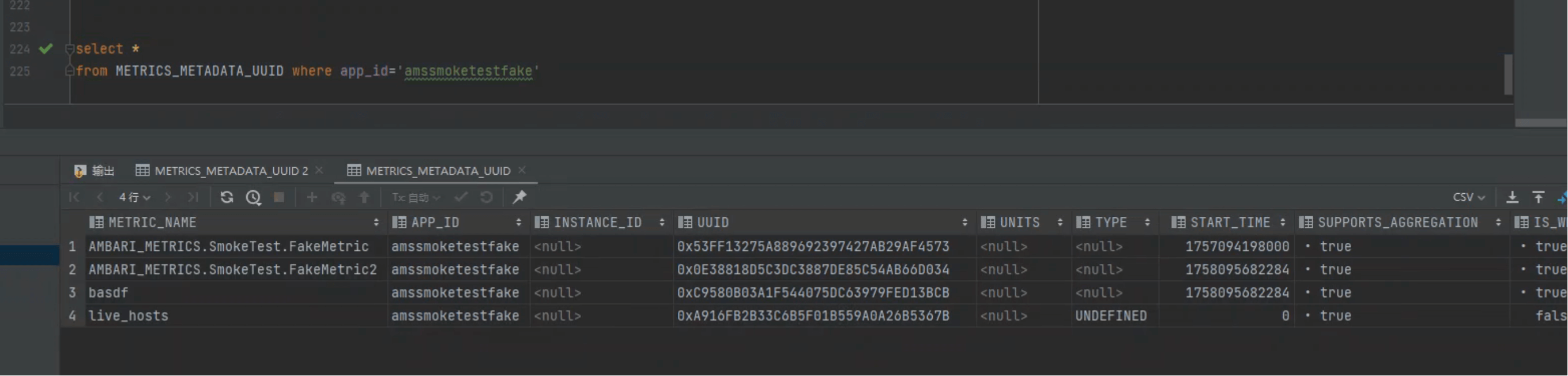
我们在上一讲讲了请求参数。本节从请求与效果开始,先做一次“地毯式”确认:当前库里是否已有对应 appId 的元数据。
select *
from METRICS_METADATA_UUID
where app_id='amssmoketestfake';
2
3
获取的 appId 为 amssmoketestfake。
为什么要先查?
新指标第一次写入后,不是立即可见于元数据表;这一步主要用于排除“历史残留/参数输错”的影响,便于后续比对。
# 三、最小写入示例:自定义指标 ttbigdata.test
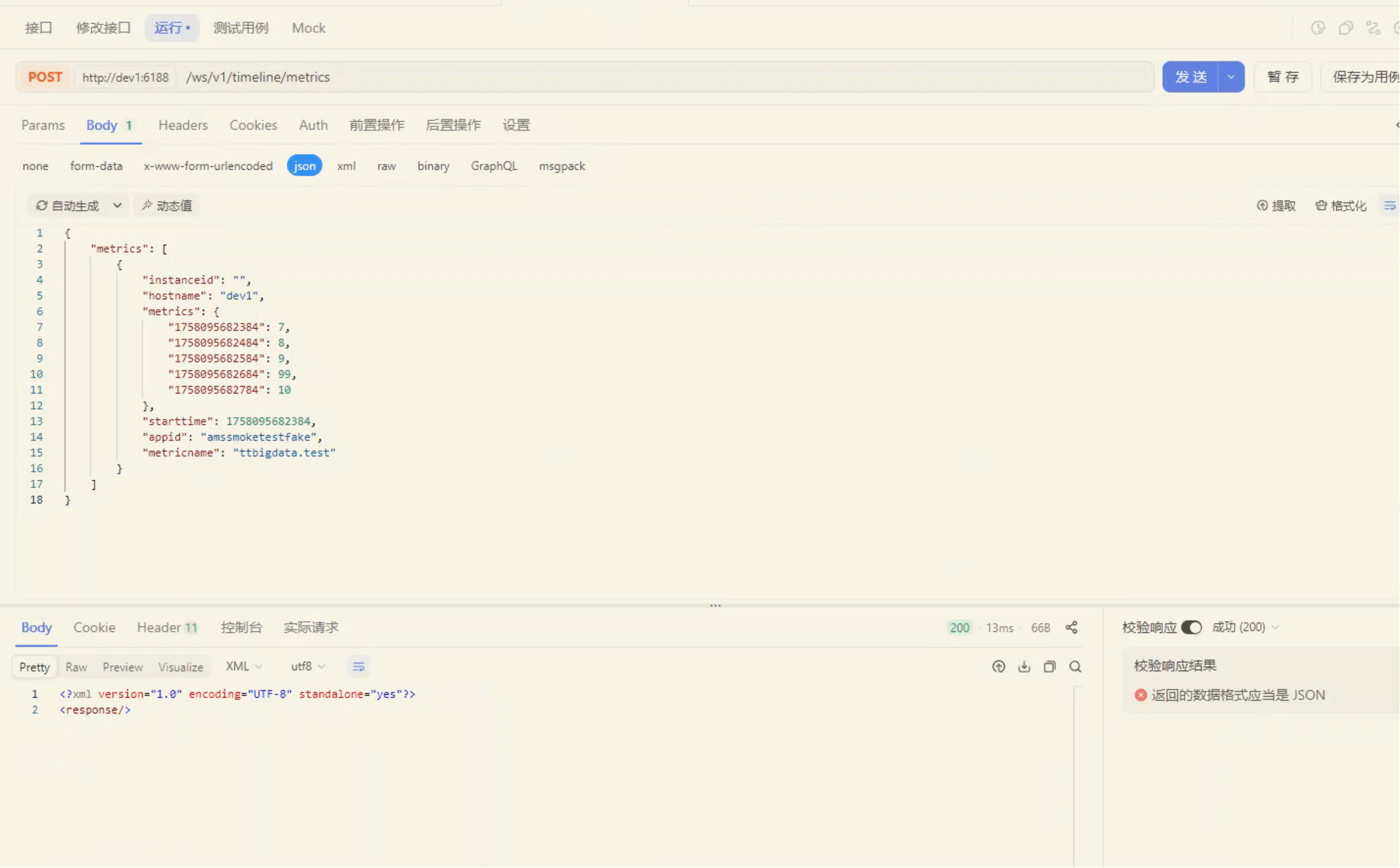
我们定义一个新的测试指标 ttbigdata.test,归属 appId=amssmoketestfake,主机为 dev1。
如下图是 APIFOX 的构造视图:
{
"metrics": [
{
"instanceid": "",
"hostname": "dev1",
"metrics": {
"1758095682384": 7,
"1758095682484": 8,
"1758095682584": 9,
"1758095682684": 99,
"1758095682784": 10
},
"starttime": 1758095682384,
"appid": "amssmoketestfake",
"metricname": "ttbigdata.test"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
curl --location --request POST 'http://dev1:6188/ws/v1/timeline/metrics' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Content-Type: application/json' \
--header 'Accept: */*' \
--header 'Host: dev1:6188' \
--header 'Connection: keep-alive' \
--data-raw '{
"metrics": [
{
"instanceid": "",
"hostname": "dev1",
"metrics": {
"1758095682384": 7,
"1758095682484": 8,
"1758095682584": 9,
"1758095682684": 99,
"1758095682784": 10
},
"starttime": 1758095682384,
"appid": "amssmoketestfake",
"metricname": "ttbigdata.test"
}
]
}'
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
// Make sure to add code blocks to your code group
成功返回(代表 Collector 已受理):
<?xml version="1.0" encoding="UTF-8" standalone="yes"?>
<response/>
2
一定要注意
虽然已经插入了指标数据,但 METRICS_METADATA_UUID 有时效。对于新的指标来说,需要等一段时间表里才会出现。 因为 Collector 内部存在 JVM 缓存与聚合任务,这些缓存要计算各种聚合,所以不是立马刷盘。一般 等个 5 分钟 就好。
# 四、落库校验:两步闭环验证
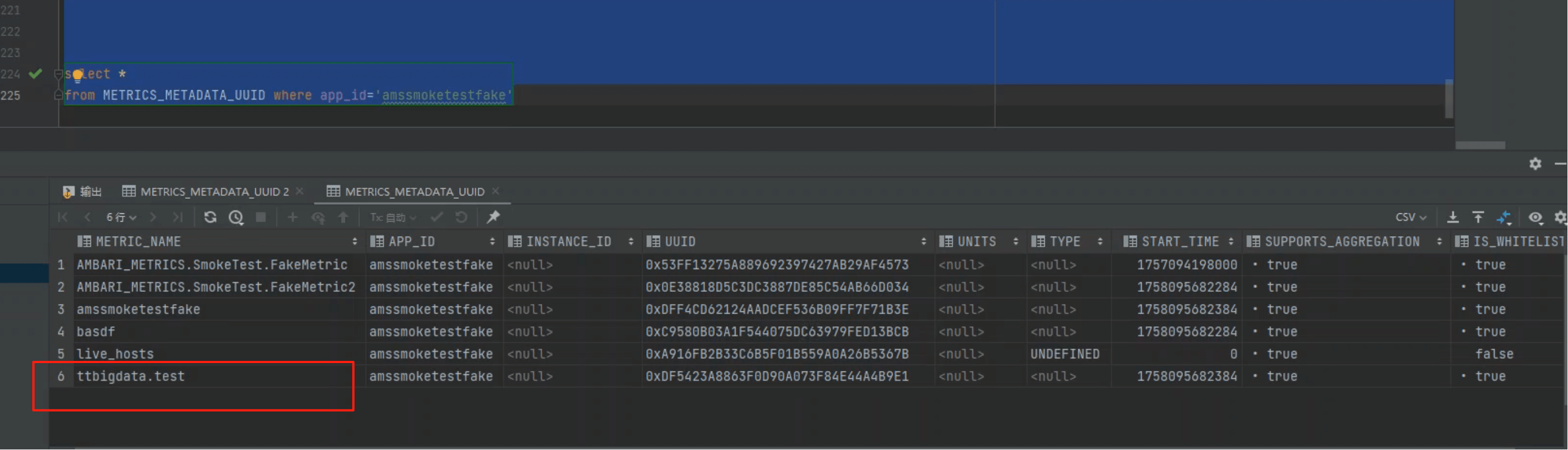
# 1、查看元数据表
# 2、用查询接口核对点位
我们再用查询接口拉一次刚刚写入的指标(APIFOX 截图):
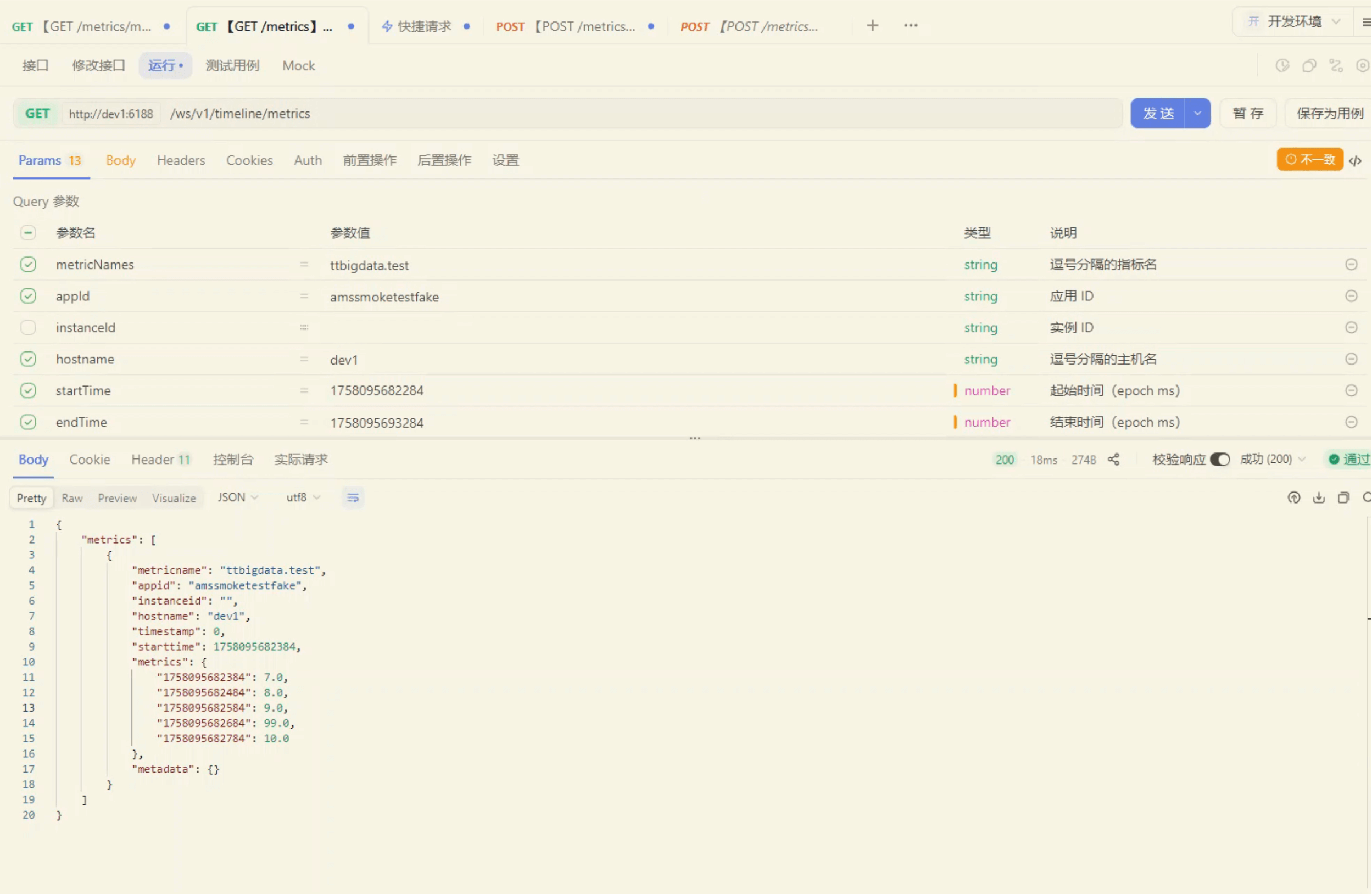
返回示例(与写入一致):
{
"metrics": [
{
"metricname": "ttbigdata.test",
"appid": "amssmoketestfake",
"instanceid": "",
"hostname": "dev1",
"timestamp": 0,
"starttime": 1758095682384,
"metrics": {
"1758095682384": 7.0,
"1758095682484": 8.0,
"1758095682584": 9.0,
"1758095682684": 99.0,
"1758095682784": 10.0
},
"metadata": {}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
和上传的数据一致,说明无问题。
# 五、参数解读与“最小颗粒度”构造
# 1、字段说明(写入侧)
| 字段名 | 是否必填 | 示例/取值 | 说明 |
|---|---|---|---|
appid | 是 | amssmoketestfake | 组件/应用标识(Collector 用于区分来源) |
metricname | 是 | ttbigdata.test | 指标名(同一 appId 下的具体监控项) |
hostname | 是 | dev1 | 上报数据来源主机名 |
starttime | 是 | 1758095682384 | 本次上报序列的起始时间(建议与 metrics 中最早的 key 一致,单位:毫秒) |
instanceid | 否 | 空字符串或具体实例 | 多实例场景用于区分实例;单集群通常留空 |
metrics | 是 | {时间戳: 值, ...} | 核心数据;key 为 epoch 毫秒 时间戳,value 为数值(整型/浮点) |
时间戳单位
必须是毫秒。误传为秒常导致“查不到数据”或错位。
# 2、最小颗粒度探究(一次写入多个点 vs 多次写入单点)
下面两种写法都合法:一个对象里放多点,或拆成多个对象。
{
"metrics": [
{
"hostname": "dev1",
"metrics": {
"1758095682384": 1
},
"starttime": 1758095682484,
"appid": "amssmoketestfake",
"metricname": "ttbigdata.test"
},
{
"hostname": "dev1",
"metrics": {
"1758095682484": 2323
},
"starttime": 1758095682484,
"appid": "amssmoketestfake",
"metricname": "ttbigdata.test"
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
组合建议
- 批量上报:同一主机、同一指标的一段连续点,推荐合并到一个对象的
metrics里,减少请求数; - 延迟补点:补写零散点位时,可按点拆分;
starttime以本批最早点为宜,便于服务端计算与索引。
总结:核心就是 metrics 是“时间戳 → 值”的映射,其余字段用于告知 Collector “这是谁的、何时的、归哪类”。
# 六、常见错误与排查清单
Checklist
- 1)时间戳单位:必须毫秒;
- 2)Content-Type:
application/json; - 3)hostname:与 Collector 侧期望的主机名一致(避免
127.0.0.1/短主机名混淆); - 4)appId/metricname 拼写:注意大小写与命名规范;
- 5)元数据延迟:新指标写入后,
METRICS_METADATA_UUID可能延迟可见,等待数分钟再查; - 6)Collector 端口/连通性:
6188可达; - 7)时钟偏移:上报机与 Collector 时间差过大会影响查询窗口;
- 8)查询窗口:用
/metrics校验时确保startTime/endTime覆盖到你上报的点。