 [/metrics] — getAggregateMetricRecords精讲
[/metrics] — getAggregateMetricRecords精讲
# 一、方法入口与整体框架
在 /metrics 查询过程中,Collector 层会调用到:
public TimelineMetrics getAggregateMetricRecords(final Condition condition,
Multimap<String, List<Function>> metricFunctions) throws SQLException, IOException {
validateConditionIsNotEmpty(condition);
Connection conn = getConnection();
PreparedStatement stmt = null;
ResultSet rs = null;
TimelineMetrics metrics = new TimelineMetrics();
try {
//get latest
if(condition.isPointInTime()) {
getLatestAggregateMetricRecords(condition, conn, metrics, metricFunctions);
} else {
if (CollectionUtils.isNotEmpty(condition.getUuids())) {
stmt = PhoenixTransactSQL.prepareGetAggregateSqlStmt(conn, condition);
rs = stmt.executeQuery();
while (rs.next()) {
appendAggregateMetricFromResultSet(metrics, condition, metricFunctions, rs);
}
}
if (CollectionUtils.isNotEmpty(condition.getTransientMetricNames())) {
stmt = PhoenixTransactSQL.prepareTransientMetricsSqlStmt(conn, condition);
if (stmt != null) {
rs = stmt.executeQuery();
while (rs.next()) {
TransientMetricReadHelper.appendMetricFromResultSet(metrics, condition, metricFunctions, rs);
}
}
}
}
} finally {
if (rs != null) {
try {
rs.close();
} catch (SQLException e) {}
}
if (stmt != null) {
try {
stmt.close();
} catch (SQLException e) {}
}
if (conn != null) {
try {
conn.close();
} catch (SQLException sql) {}
}
}
LOG.debug("Aggregate records size: " + metrics.getMetrics().size());
return metrics;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
这段代码结构很清晰,可以拆为三步:
条件校验:时间必须填写,否则直接抛错。
分支选择:
- 如果是点查询(
condition.isPointInTime()),走getLatestAggregateMetricRecords。 - 如果是区间查询(常规场景),走 Phoenix SQL。
- 如果是点查询(
聚合逻辑:
- 正常指标:
prepareGetAggregateSqlStmt+appendAggregateMetricFromResultSet - transient 指标:
prepareTransientMetricsSqlStmt+TransientMetricReadHelper.appendMetricFromResultSet
- 正常指标:
# 二、时间参数与分支逻辑
从入口代码可以看出,condition.isPointInTime() 主要对应“最新值”查询。
但 /metrics API 的参数必须带上 startTime 与 endTime,所以实际不会触发点查询逻辑,而是默认进入区间查询分支。
因此我们重点分析后续的 SQL 构造与结果拼装。
# 三、transient 指标判定
在进入 SQL 查询前,会根据 METRICS_METADATA_UUID 表来判定:
- 如果能找到指标名 → 正常指标
- 如果找不到 → transient 指标
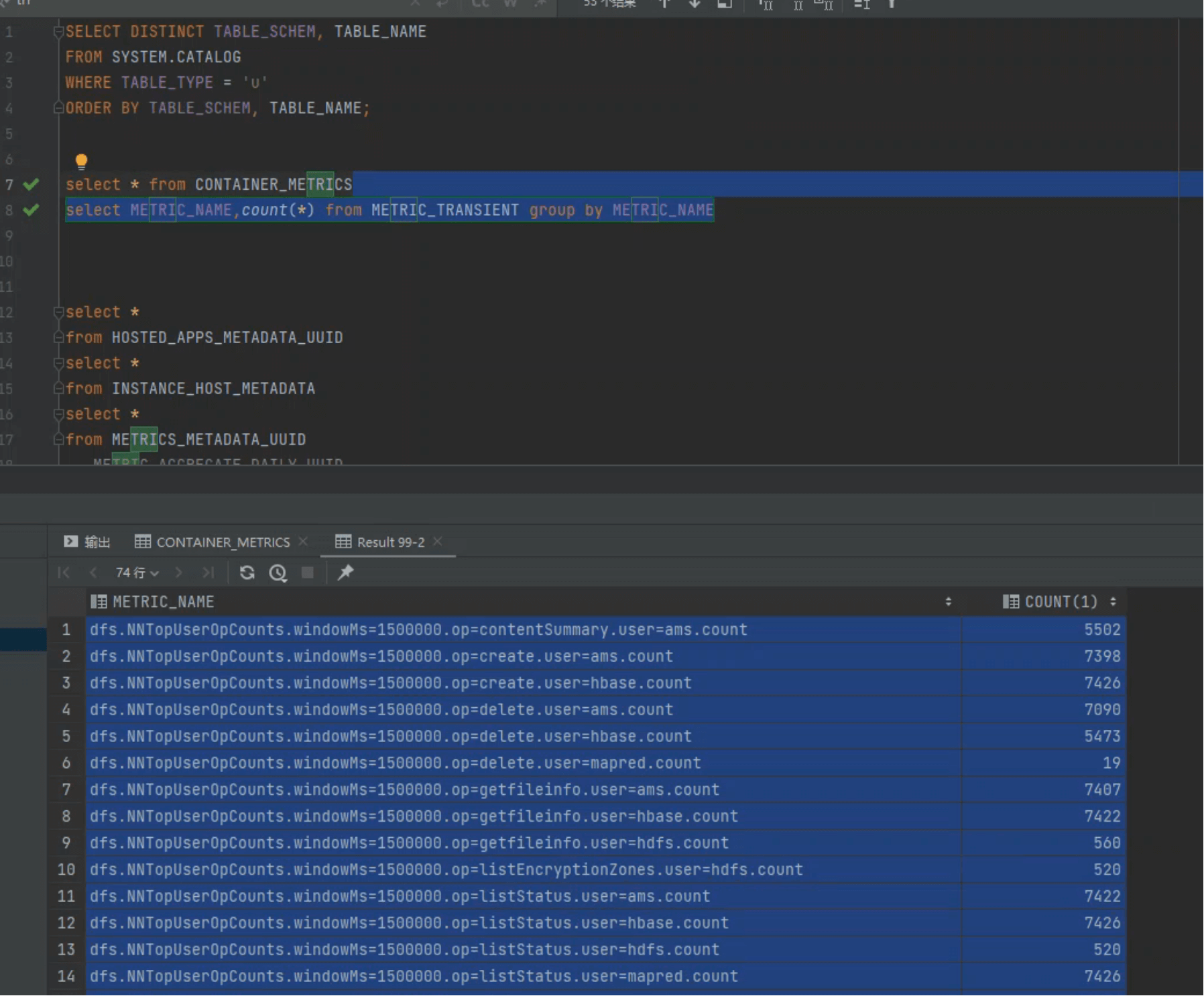
我们在库中执行:
select METRIC_NAME,count(*)
from METRIC_TRANSIENT
group by METRIC_NAME;
1
2
3
2
3
返回部分结果:
dfs.NNTopUserOpCounts.windowMs=1500000.op=contentSummary.user=ams.count,5502
dfs.NNTopUserOpCounts.windowMs=1500000.op=create.user=ams.count,7398
dfs.NNTopUserOpCounts.windowMs=1500000.op=create.user=hbase.count,7426
dfs.NNTopUserOpCounts.windowMs=1500000.op=delete.user=ams.count,7090
dfs.NNTopUserOpCounts.windowMs=1500000.op=delete.user=hbase.count,5473
dfs.NNTopUserOpCounts.windowMs=1500000.op=delete.user=mapred.count,19
dfs.NNTopUserOpCounts.windowMs=1500000.op=getfileinfo.user=ams.count,7407
dfs.NNTopUserOpCounts.windowMs=1500000.op=getfileinfo.user=hbase.count,7422
dfs.NNTopUserOpCounts.windowMs=1500000.op=getfileinfo.user=hdfs.count,560
dfs.NNTopUserOpCounts.windowMs=1500000.op=listEncryptionZones.user=hdfs.count,520
dfs.NNTopUserOpCounts.windowMs=1500000.op=listStatus.user=ams.count,7422
dfs.NNTopUserOpCounts.windowMs=1500000.op=listStatus.user=hbase.count,7426
dfs.NNTopUserOpCounts.windowMs=1500000.op=listStatus.user=hdfs.count,520
dfs.NNTopUserOpCounts.windowMs=1500000.op=listStatus.user=mapred.count,7426
dfs.NNTopUserOpCounts.windowMs=1500000.op=mkdirs.user=ams.count,5811
dfs.NNTopUserOpCounts.windowMs=1500000.op=mkdirs.user=hbase.count,21
dfs.NNTopUserOpCounts.windowMs=1500000.op=open.user=ams.count,7305
dfs.NNTopUserOpCounts.windowMs=1500000.op=open.user=hbase.count,20
dfs.NNTopUserOpCounts.windowMs=1500000.op=rename.user=ams.count,7399
dfs.NNTopUserOpCounts.windowMs=1500000.op=rename.user=hbase.count,7422
dfs.NNTopUserOpCounts.windowMs=1500000.op=rollEditLog.user=hdfs.count,524
dfs.NNTopUserOpCounts.windowMs=1500000.op=safemode_get.user=ams.count,40
dfs.NNTopUserOpCounts.windowMs=1500000.op=setPermission.user=ams.count,40
dfs.NNTopUserOpCounts.windowMs=1500000.op=setStoragePolicy.user=ams.count,40
dfs.NNTopUserOpCounts.windowMs=1500000.op=setTimes.user=ams.count,7335
dfs.NNTopUserOpCounts.windowMs=1500000.op=setTimes.user=hbase.count,7422
dfs.NNTopUserOpCounts.windowMs=300000.op=contentSummary.user=ams.count,2109
dfs.NNTopUserOpCounts.windowMs=300000.op=create.user=ams.count,5674
dfs.NNTopUserOpCounts.windowMs=300000.op=create.user=hbase.count,2691
dfs.NNTopUserOpCounts.windowMs=300000.op=delete.user=ams.count,3141
dfs.NNTopUserOpCounts.windowMs=300000.op=delete.user=hbase.count,1771
dfs.NNTopUserOpCounts.windowMs=300000.op=delete.user=mapred.count,4
dfs.NNTopUserOpCounts.windowMs=300000.op=getfileinfo.user=ams.count,5712
dfs.NNTopUserOpCounts.windowMs=300000.op=getfileinfo.user=hbase.count,2954
dfs.NNTopUserOpCounts.windowMs=300000.op=getfileinfo.user=hdfs.count,116
dfs.NNTopUserOpCounts.windowMs=300000.op=listEncryptionZones.user=hdfs.count,108
dfs.NNTopUserOpCounts.windowMs=300000.op=listStatus.user=ams.count,4518
dfs.NNTopUserOpCounts.windowMs=300000.op=listStatus.user=hbase.count,6588
dfs.NNTopUserOpCounts.windowMs=300000.op=listStatus.user=hdfs.count,108
dfs.NNTopUserOpCounts.windowMs=300000.op=listStatus.user=mapred.count,7427
dfs.NNTopUserOpCounts.windowMs=300000.op=mkdirs.user=ams.count,2467
dfs.NNTopUserOpCounts.windowMs=300000.op=mkdirs.user=hbase.count,5
dfs.NNTopUserOpCounts.windowMs=300000.op=open.user=ams.count,4681
dfs.NNTopUserOpCounts.windowMs=300000.op=open.user=hbase.count,4
dfs.NNTopUserOpCounts.windowMs=300000.op=rename.user=ams.count,5833
dfs.NNTopUserOpCounts.windowMs=300000.op=rename.user=hbase.count,2693
dfs.NNTopUserOpCounts.windowMs=300000.op=rollEditLog.user=hdfs.count,109
dfs.NNTopUserOpCounts.windowMs=300000.op=safemode_get.user=ams.count,7
dfs.NNTopUserOpCounts.windowMs=300000.op=setPermission.user=ams.count,7
dfs.NNTopUserOpCounts.windowMs=300000.op=setStoragePolicy.user=ams.count,8
dfs.NNTopUserOpCounts.windowMs=300000.op=setTimes.user=ams.count,4690
dfs.NNTopUserOpCounts.windowMs=300000.op=setTimes.user=hbase.count,2692
dfs.NNTopUserOpCounts.windowMs=60000.op=contentSummary.user=ams.count,472
dfs.NNTopUserOpCounts.windowMs=60000.op=create.user=ams.count,2167
dfs.NNTopUserOpCounts.windowMs=60000.op=create.user=hbase.count,599
dfs.NNTopUserOpCounts.windowMs=60000.op=delete.user=ams.count,702
dfs.NNTopUserOpCounts.windowMs=60000.op=delete.user=hbase.count,394
dfs.NNTopUserOpCounts.windowMs=60000.op=getfileinfo.user=ams.count,2673
dfs.NNTopUserOpCounts.windowMs=60000.op=getfileinfo.user=hbase.count,899
dfs.NNTopUserOpCounts.windowMs=60000.op=getfileinfo.user=hdfs.count,24
dfs.NNTopUserOpCounts.windowMs=60000.op=listEncryptionZones.user=hdfs.count,24
dfs.NNTopUserOpCounts.windowMs=60000.op=listStatus.user=ams.count,1345
dfs.NNTopUserOpCounts.windowMs=60000.op=listStatus.user=hbase.count,2360
dfs.NNTopUserOpCounts.windowMs=60000.op=listStatus.user=hdfs.count,24
dfs.NNTopUserOpCounts.windowMs=60000.op=listStatus.user=mapred.count,6300
dfs.NNTopUserOpCounts.windowMs=60000.op=mkdirs.user=ams.count,639
dfs.NNTopUserOpCounts.windowMs=60000.op=mkdirs.user=hbase.count,1
dfs.NNTopUserOpCounts.windowMs=60000.op=open.user=ams.count,1952
dfs.NNTopUserOpCounts.windowMs=60000.op=rename.user=ams.count,2535
dfs.NNTopUserOpCounts.windowMs=60000.op=rename.user=hbase.count,600
dfs.NNTopUserOpCounts.windowMs=60000.op=rollEditLog.user=hdfs.count,24
dfs.NNTopUserOpCounts.windowMs=60000.op=setStoragePolicy.user=ams.count,2
dfs.NNTopUserOpCounts.windowMs=60000.op=setTimes.user=ams.count,1452
dfs.NNTopUserOpCounts.windowMs=60000.op=setTimes.user=hbase.count,599
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
代码中对应逻辑:
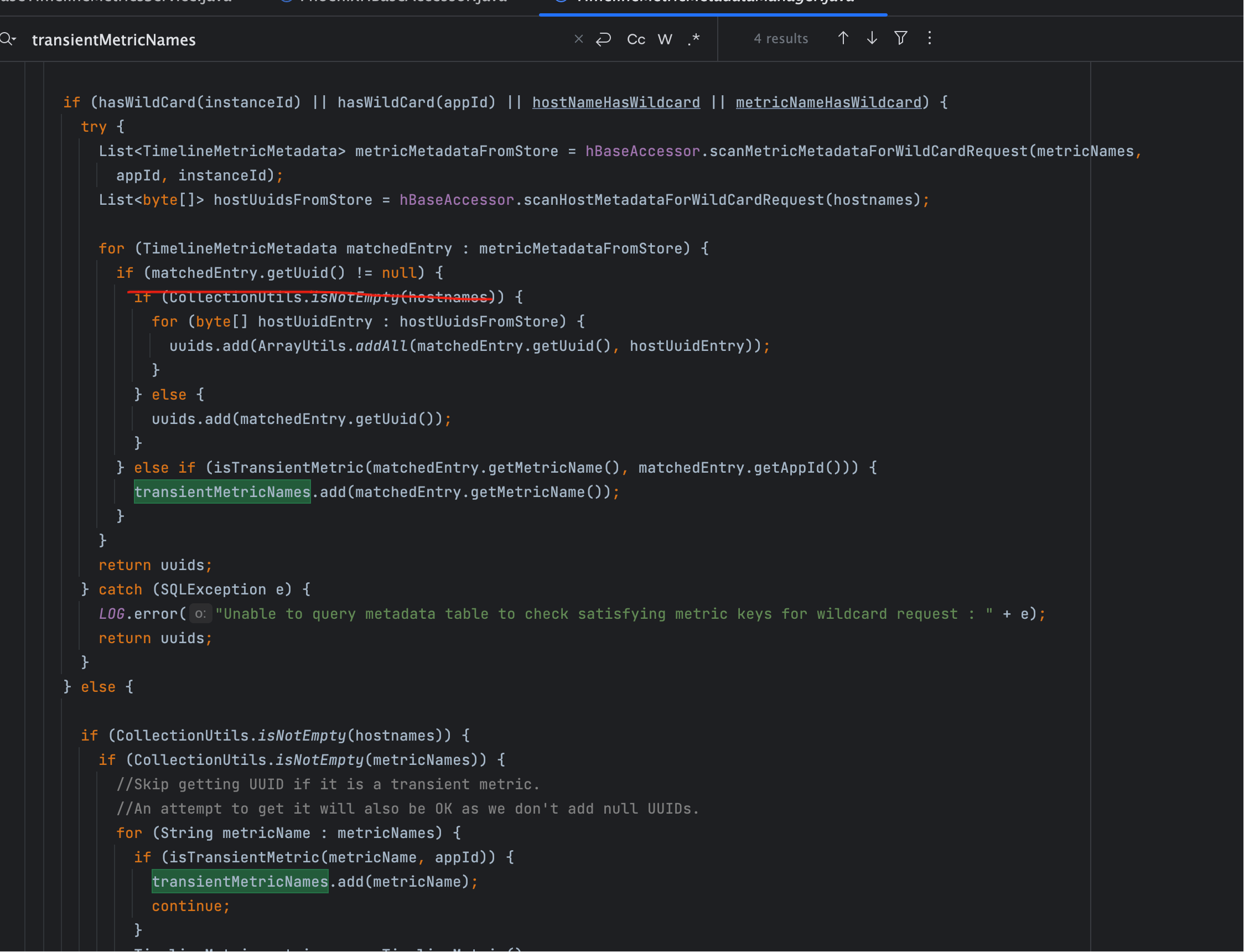
内部调用 isTransientMetric:
即通过 是否能在元数据表找到对应 UUID 来判定。
- 找不到 → 放入
condition.getTransientMetricNames()集合,后续用METRIC_TRANSIENT表查询。 - 找得到 → 走常规的聚合查询。
# 四、PhoenixTransactSQL.prepareGetAggregateSqlStmt
常规指标会走 Phoenix SQL 的准备逻辑:
stmt = PhoenixTransactSQL.prepareGetAggregateSqlStmt(conn, condition);
1
对应实现:
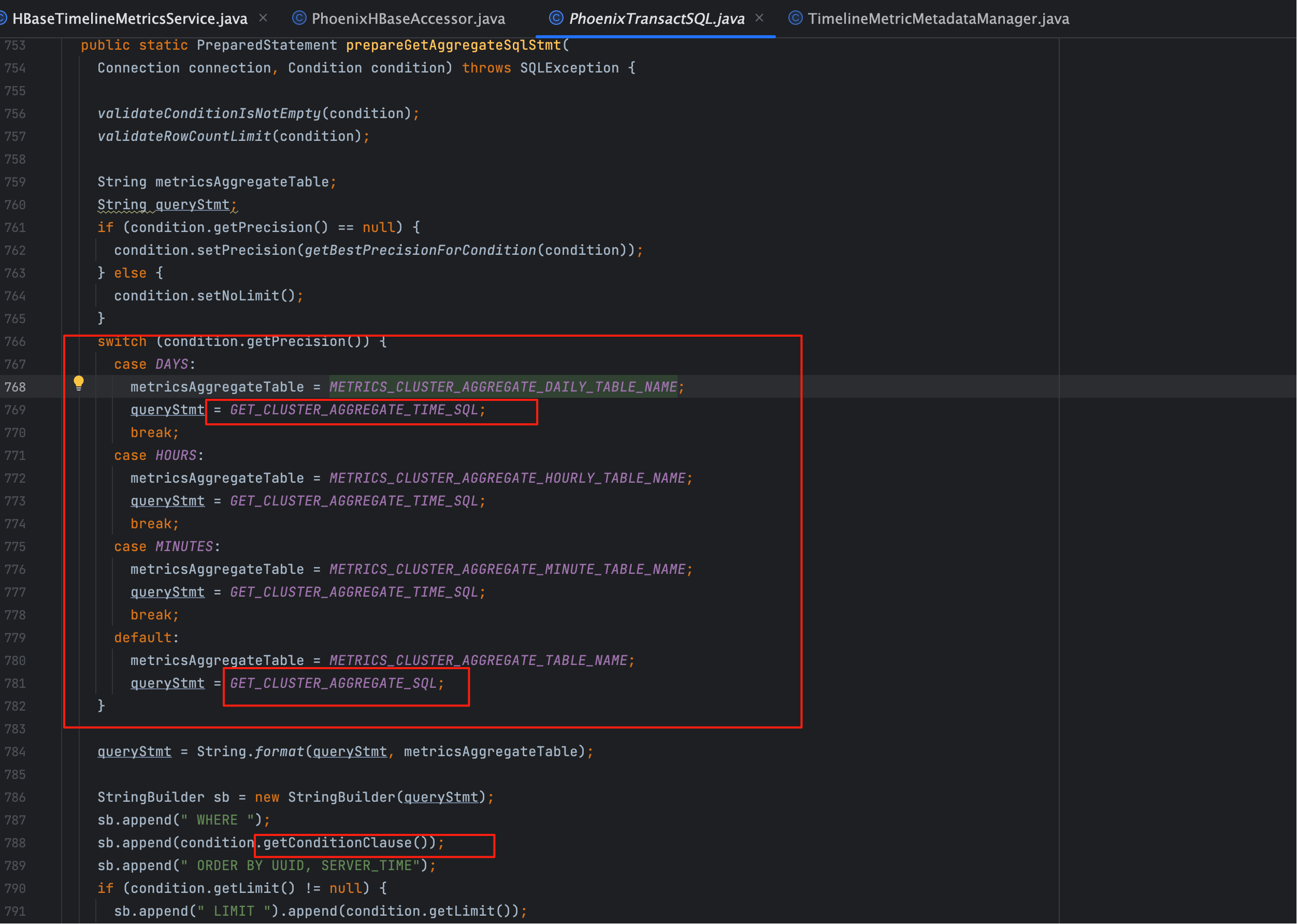
几个关键点:
SQL 模板会根据时间粒度选择不同的聚合表:
- 秒 →
METRIC_AGGREGATE - 分 →
METRIC_AGGREGATE_MINUTE - 时 →
METRIC_AGGREGATE_HOURLY - 天 →
METRIC_AGGREGATE_DAILY
- 秒 →
字段差异:
- 秒表 → 使用
HOSTS_COUNT - 其他表 → 使用
METRIC_COUNT
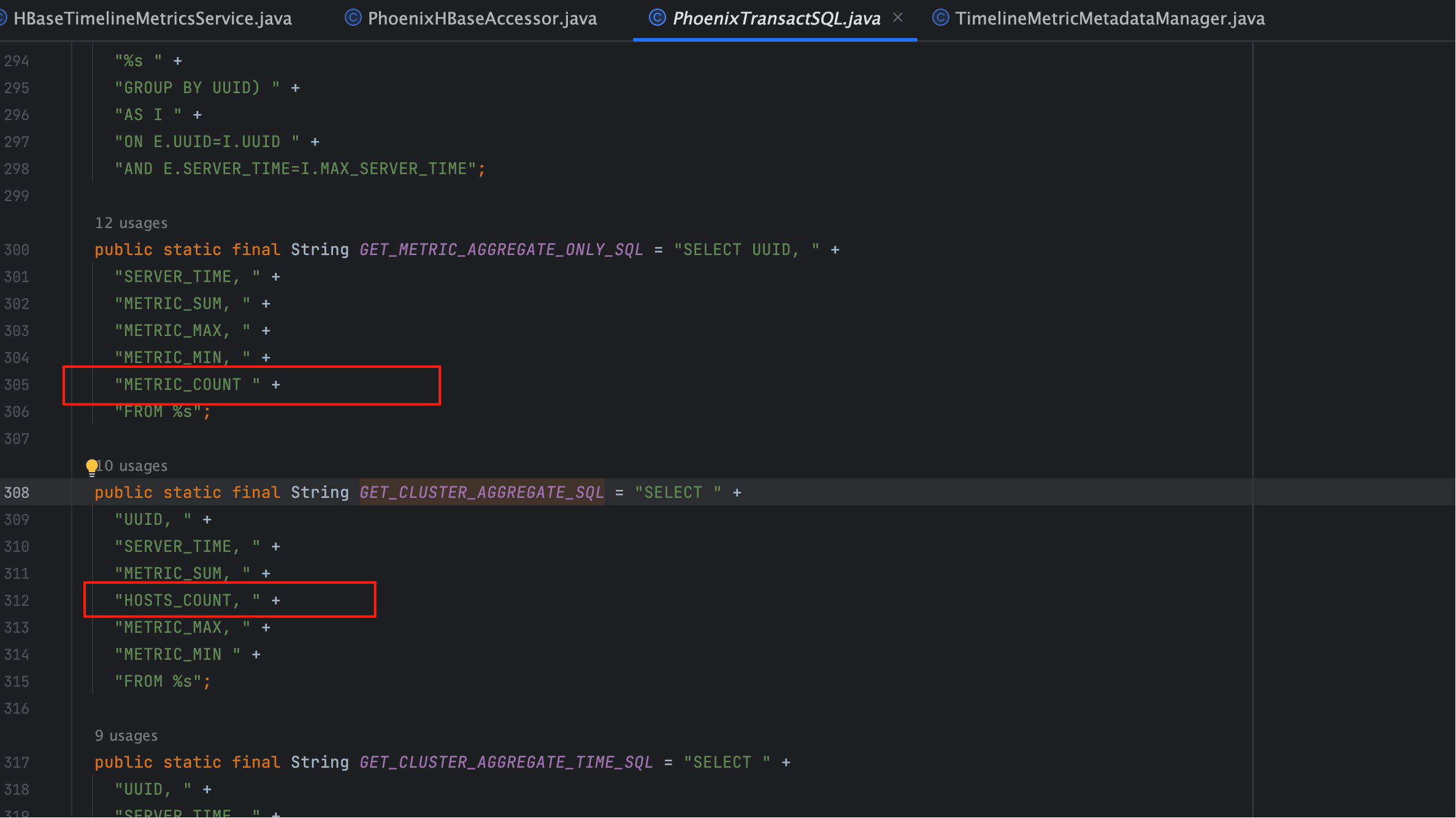
- 秒表 → 使用
条件拼接:
getConditionClause负责拼接UUID IN (...)- 如果存在多指标,会批量绑定 UUID 参数。
# 五、appendAggregateMetricFromResultSet
SQL 查询返回的 ResultSet 会通过:
appendAggregateMetricFromResultSet(metrics, condition, metricFunctions, rs);
1
来处理。
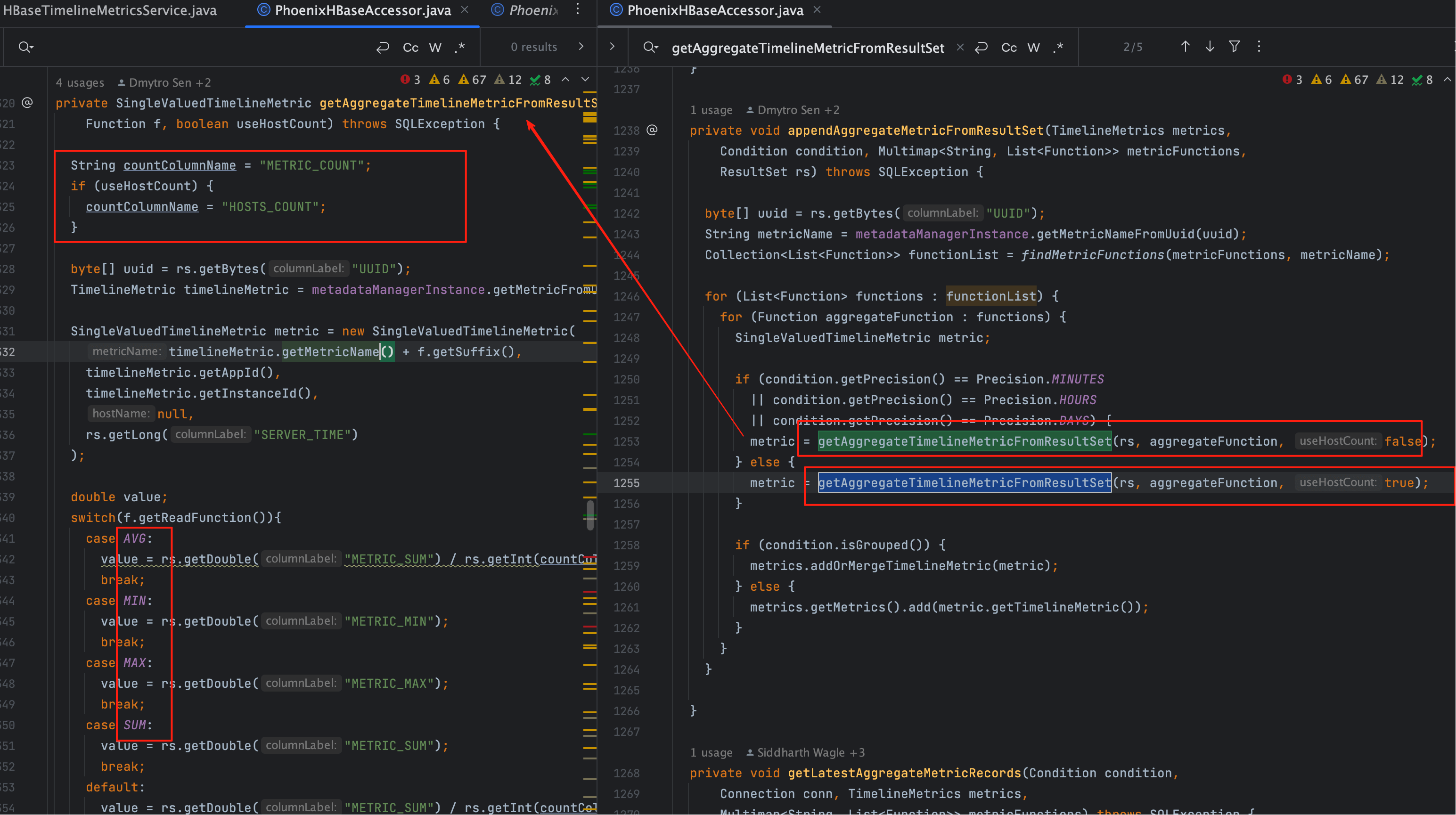
核心逻辑:
- 读取
HOSTS_COUNT或METRIC_COUNT字段 - 按照时间戳拆分数据,生成
TimelineMetric对象 - 将聚合结果填充到返回对象中
由于表中存储的本身就是聚合值,因此这里的加工逻辑很轻量,主要是数据拷贝和封装。
# 六、transient 指标的查询逻辑
当 condition.getTransientMetricNames() 不为空时,会走:
stmt = PhoenixTransactSQL.prepareTransientMetricsSqlStmt(conn, condition);
1
执行后进入:
TransientMetricReadHelper.appendMetricFromResultSet(metrics, condition, metricFunctions, rs);
1
这里不会查 METRIC_AGGREGATE_* 系列表,而是直接去 METRIC_TRANSIENT 表拉取。
这种场景比较少见,一般只在某些临时统计的指标上触发。
# 七、查询链路与表关系
整个查询链路可以串成一条线:
/metrics
→ HBaseAccessor.getAggregateMetricRecords
→ PhoenixTransactSQL.prepareGetAggregateSqlStmt
→ METRIC_AGGREGATE / MINUTE / HOURLY / DAILY
→ appendAggregateMetricFromResultSet
→ PhoenixTransactSQL.prepareTransientMetricsSqlStmt
→ METRIC_TRANSIENT
→ TransientMetricReadHelper.appendMetricFromResultSet
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
几个表的角色:
METRICS_METADATA_UUID:判断指标是否存在METRIC_AGGREGATE_*:常规聚合表METRIC_TRANSIENT:临时指标表