 [O]Sqoop版本适配改造(一)
[O]Sqoop版本适配改造(一)
# 操作步骤详解
修改 src/scripts/relnotes.py 这个文件
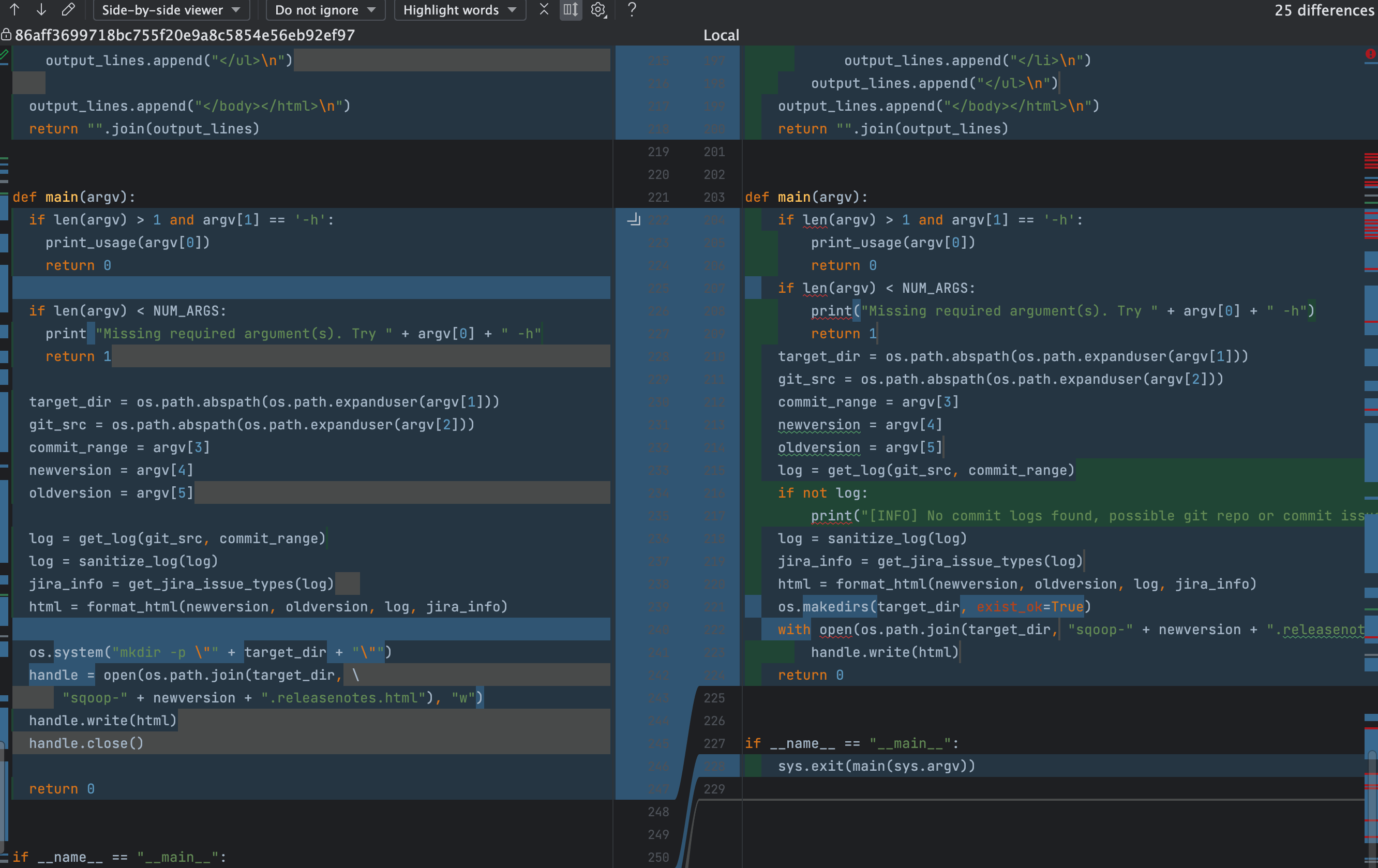
他们的 diff 文件如下:
Subject: [PATCH] feature:支持python3
---
Index: src/scripts/relnotes.py
IDEA additional info:
Subsystem: com.intellij.openapi.diff.impl.patch.CharsetEP
<+>UTF-8
===================================================================
diff --git a/src/scripts/relnotes.py b/src/scripts/relnotes.py
--- a/src/scripts/relnotes.py (revision 86aff3699718bc755f20e9a8c5854e56eb92ef97)
+++ b/src/scripts/relnotes.py (date 1749439716311)
@@ -1,4 +1,4 @@
-#!/usr/bin/env/python
+#!/usr/bin/env python3
#
# Copyright 2011 The Apache Software Foundation
#
@@ -28,165 +28,151 @@
import os
import re
import sys
+import subprocess
try:
- from xml.etree import ElementTree
+ from xml.etree import ElementTree
except ImportError:
- print "Building release notes is not supported on this platform."
- sys.exit(0)
+ print("Building release notes is not supported on this platform.")
+ sys.exit(0)
-
-
NUM_ARGS = 6
+
def print_usage(prgm_name):
- """ Print the usage for this program """
- print "Usage: " + prgm_name + " <target-dir> <git-src> <commit-range> " \
- + "<newversion> <oldversion>"
- print ""
- print " <target-dir>: Directory where release notes should be written to."
- print " <git-src>: Root of the git repository to collect info from."
- print " <commit-range>: What set of commits form this release."
- print " <newversion>: The version number to print in the release notes."
- print " <oldversion>: The previous release version number."
+ """ Print the usage for this program """
+ print("Usage: " + prgm_name + " <target-dir> <git-src> <commit-range> "
+ + "<newversion> <oldversion>")
+ print("")
+ print(" <target-dir>: Directory where release notes should be written to.")
+ print(" <git-src>: Root of the git repository to collect info from.")
+ print(" <commit-range>: What set of commits form this release.")
+ print(" <newversion>: The version number to print in the release notes.")
+ print(" <oldversion>: The previous release version number.")
def get_log(git_dir, commit_range):
- """ Return the set of lines corresponding to the git log for the specified
- commit range.
- """
-
- os.chdir(git_dir)
- cmd = "git log --no-color '--pretty=format:%s' '" + commit_range + "'"
- return os.popen(cmd).readlines()
+ os.chdir(git_dir)
+ cmd = f"git log --no-color '--pretty=format:%s' '{commit_range}'"
+ try:
+ return subprocess.check_output(cmd, shell=True, encoding="utf-8").splitlines()
+ except subprocess.CalledProcessError as e:
+ print(f"[WARN] git log failed: {e}. Release notes will be empty.", file=sys.stderr)
+ return []
def sanitize_log(in_log):
- """ 'sanitize' the log.
- Some entries do not have a separate subject and body by accident.
- Return a new log that only includes the first sentence of each
- subject. (Note that we also usually have a 'SQOOP-nn.' before this
- sentence.)
- """
- out_log = []
- for line in in_log:
- line = line.strip()
- sentences = line.split(". ")
- if len(sentences) <= 2:
- out_log.append(line) # Unchanged original input.
- else:
- out_log.append(sentences[0] + ". " + sentences[1] + ".")
-
- return out_log
+ """ 'sanitize' the log.
+ Some entries do not have a separate subject and body by accident.
+ Return a new log that only includes the first sentence of each
+ subject. (Note that we also usually have a 'SQOOP-nn.' before this
+ sentence.)
+ """
+ out_log = []
+ for line in in_log:
+ line = line.strip()
+ sentences = line.split(". ")
+ if len(sentences) <= 2:
+ out_log.append(line) # Unchanged original input.
+ else:
+ out_log.append(sentences[0] + ". " + sentences[1] + ".")
+ return out_log
def get_jira_doc(issue):
- """ Get the XML document from JIRA for a specified issue. """
-
- xml = os.popen("curl -s 'https://issues.apache.org/jira/si/jira.issueviews:" \
- + "issue-xml/%s/%s.xml?field=key&field=type&field=parent'" % (issue, issue)).read()
- return ElementTree.fromstring(xml)
+ """ Get the XML document from JIRA for a specified issue. """
+ xml = subprocess.check_output(
+ f"curl -s 'https://issues.apache.org/jira/si/jira.issueviews:issue-xml/{issue}/{issue}.xml?field=key&field=type&field=parent'",
+ shell=True, encoding="utf-8"
+ )
+ return ElementTree.fromstring(xml)
def get_jira_issue_types(log):
- """ Return a dict from issue-type -> ((issue-name, summary) list) by looking
- up the issues in our JIRA.
- """
-
- d = {}
+ """ Return a dict from issue-type -> ((issue-name, summary) list) by looking
+ up the issues in our JIRA.
+ """
+ d = {}
- def add_issue(issue, typ, line):
- try:
- d[typ].append((issue, line))
- except KeyError:
- # This issue type hasn't been seen yet. Add a new list.
- d[typ] = [ (issue, line) ]
+ def add_issue(issue, typ, line):
+ try:
+ d[typ].append((issue, line))
+ except KeyError:
+ # This issue type hasn't been seen yet. Add a new list.
+ d[typ] = [(issue, line)]
- jira_reg = r"^(SQOOP-\d+)"
- for line in log:
- matched_line = False
- for m in re.finditer(jira_reg, line, re.M):
- matched_line = True
- jira = m.group(1)
- doc = get_jira_doc(jira)
- issue_type = doc.find('./channel/item/type').text
- # Subtasks use the type of their parent item.
- if issue_type == "Sub-task":
- parent_doc = get_jira_doc(doc.find('./channel/item/parent').text)
- issue_type = parent_doc.find('./channel/item/type').text
-
- add_issue(jira, issue_type, line)
- if not matched_line and not line.startswith("CLOUDERA-BUILD."):
- # This line did not start with "SQOOP-.."
- # Unless it's a CDH buildfix, add it in as a "Task".
- add_issue("", "Task", line)
-
- return d
+ jira_reg = r"^(SQOOP-\d+)"
+ for line in log:
+ matched_line = False
+ for m in re.finditer(jira_reg, line, re.M):
+ matched_line = True
+ jira = m.group(1)
+ doc = get_jira_doc(jira)
+ issue_type = doc.find('./channel/item/type').text
+ # Subtasks use the type of their parent item.
+ if issue_type == "Sub-task":
+ parent_doc = get_jira_doc(doc.find('./channel/item/parent').text)
+ issue_type = parent_doc.find('./channel/item/type').text
+ add_issue(jira, issue_type, line)
+ if not matched_line and not line.startswith("CLOUDERA-BUILD."):
+ # This line did not start with "SQOOP-.."
+ # Unless it's a CDH buildfix, add it in as a "Task".
+ add_issue("", "Task", line)
+ return d
def get_date():
- """ Return the current month and year formatted as a string. """
- return datetime.date.today().strftime("%B, %Y")
+ """ Return the current month and year formatted as a string. """
+ return datetime.date.today().strftime("%B, %Y")
def add_links(summary_line):
- """ Given a line like "SQOOP-40. Do something", add links to the JIRA
- and any appropriate SIPs, and return the line with links.
- """
-
- initial_jira_reg = r"^(SQOOP-\d+)\. (.*)"
-
- # Reformat the issue id away from the summary.
- m = re.match(initial_jira_reg, summary_line)
- if m == None:
- # Line in unexpected format. Return as-is.
- return summary_line
- jira = m.group(1)
- text = m.group(2)
-
- # Add links to JIRA and SIP wiki.
-
- issue_reg = r"(SQOOP-\d+)"
- issue_subst = r'<a href="https://issues.cloudera.org/browse/\1">\1</a>'
-
- sip_reg = r"(SIP-\d+)"
- sip_subst = r'<a href="http://wiki.github.com/cloudera/sqoop/\1">\1</a>'
-
- output = "[" + jira + "] - " + text
- output = re.sub(issue_reg, issue_subst, output)
- output = re.sub(sip_reg, sip_subst, output)
-
- return output
+ """ Given a line like "SQOOP-40. Do something", add links to the JIRA
+ and any appropriate SIPs, and return the line with links.
+ """
+ initial_jira_reg = r"^(SQOOP-\d+)\. (.*)"
+ m = re.match(initial_jira_reg, summary_line)
+ if m == None:
+ # Line in unexpected format. Return as-is.
+ return summary_line
+ jira = m.group(1)
+ text = m.group(2)
+ issue_reg = r"(SQOOP-\d+)"
+ issue_subst = r'<a href="https://issues.cloudera.org/browse/\1">\1</a>'
+ sip_reg = r"(SIP-\d+)"
+ sip_subst = r'<a href="http://wiki.github.com/cloudera/sqoop/\1">\1</a>'
+ output = "[" + jira + "] - " + text
+ output = re.sub(issue_reg, issue_subst, output)
+ output = re.sub(sip_reg, sip_subst, output)
+ return output
__user_types = {
- "Bug" : "Bug fixes",
- "Improvement" : "Improvements",
- "New Feature" : "New features",
- "Task" : "Tasks"
+ "Bug": "Bug fixes",
+ "Improvement": "Improvements",
+ "New Feature": "New features",
+ "Task": "Tasks"
}
+
def user_issue_type(typ):
- """ Return a user-friendly issue type string based on the JIRA issue
- type string.
- """
- global __user_types
-
- try:
- return __user_types[typ]
- except KeyError:
- # If we don't have a plural-form string set, just use the input.
- return typ
+ """ Return a user-friendly issue type string based on the JIRA issue
+ type string.
+ """
+ global __user_types
+ try:
+ return __user_types[typ]
+ except KeyError:
+ # If we don't have a plural-form string set, just use the input.
+ return typ
-
def format_html(newversion, oldversion, log, jira_info):
- """ Creates the HTML representation of the release notes and returns
- it as a string.
- """
-
- output_lines = []
- output_lines.append("""<html><head>
+ """ Creates the HTML representation of the release notes and returns
+ it as a string.
+ """
+ output_lines = []
+ output_lines.append("""<html><head>
<meta http-equiv="Content-Type" content="text/html; charset=UTF-8"/>
<title>Sqoop %(newversion)s Release Notes</title>
<style type="Text/css">
@@ -198,56 +184,45 @@
<p>This document lists all Sqoop issues included in version %(newversion)s
not present in the previous release, %(oldversion)s.</p>
-""" % { "newversion" : newversion,
- "oldversion" : oldversion,
- "date" : get_date() })
+""" % {"newversion": newversion,
+ "oldversion": oldversion,
+ "date": get_date()})
-
- # Sort the output list by issue type.
- types = jira_info.keys()
- types.sort()
- for typ in types:
- output_lines.append("<h4>" + user_issue_type(typ) + ":</h4><ul>\n")
- for (issue, summary) in jira_info[typ]:
- output_lines.append("<li>")
- output_lines.append(add_links(summary))
- output_lines.append("</li>\n")
- output_lines.append("</ul>\n")
-
- output_lines.append("</body></html>\n")
- return "".join(output_lines)
+ types = sorted(jira_info.keys())
+ for typ in types:
+ output_lines.append("<h4>" + user_issue_type(typ) + ":</h4><ul>\n")
+ for (issue, summary) in jira_info[typ]:
+ output_lines.append("<li>")
+ output_lines.append(add_links(summary))
+ output_lines.append("</li>\n")
+ output_lines.append("</ul>\n")
+ output_lines.append("</body></html>\n")
+ return "".join(output_lines)
def main(argv):
- if len(argv) > 1 and argv[1] == '-h':
- print_usage(argv[0])
- return 0
-
- if len(argv) < NUM_ARGS:
- print "Missing required argument(s). Try " + argv[0] + " -h"
- return 1
-
- target_dir = os.path.abspath(os.path.expanduser(argv[1]))
- git_src = os.path.abspath(os.path.expanduser(argv[2]))
- commit_range = argv[3]
- newversion = argv[4]
- oldversion = argv[5]
-
- log = get_log(git_src, commit_range)
- log = sanitize_log(log)
- jira_info = get_jira_issue_types(log)
- html = format_html(newversion, oldversion, log, jira_info)
-
- os.system("mkdir -p \"" + target_dir + "\"")
- handle = open(os.path.join(target_dir, \
- "sqoop-" + newversion + ".releasenotes.html"), "w")
- handle.write(html)
- handle.close()
-
- return 0
+ if len(argv) > 1 and argv[1] == '-h':
+ print_usage(argv[0])
+ return 0
+ if len(argv) < NUM_ARGS:
+ print("Missing required argument(s). Try " + argv[0] + " -h")
+ return 1
+ target_dir = os.path.abspath(os.path.expanduser(argv[1]))
+ git_src = os.path.abspath(os.path.expanduser(argv[2]))
+ commit_range = argv[3]
+ newversion = argv[4]
+ oldversion = argv[5]
+ log = get_log(git_src, commit_range)
+ if not log:
+ print("[INFO] No commit logs found, possible git repo or commit issue, continue anyway.", file=sys.stderr)
+ log = sanitize_log(log)
+ jira_info = get_jira_issue_types(log)
+ html = format_html(newversion, oldversion, log, jira_info)
+ os.makedirs(target_dir, exist_ok=True)
+ with open(os.path.join(target_dir, "sqoop-" + newversion + ".releasenotes.html"), "w", encoding="utf-8") as handle:
+ handle.write(html)
+ return 0
if __name__ == "__main__":
- sys.exit(main(sys.argv))
-
-
+ sys.exit(main(sys.argv))
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
292
293
294
295
296
297
298
299
300
301
302
303
304
305
306
307
308
309
310
311
312
313
314
315
316
317
318
319
320
321
322
323
324
325
326
327
328
329
330
331
332
333
334
335
336
337
338
339
340
341
342
343
344
345
346
347
348
349
350
351
352
353
354
355
356
357
358
359
360
361
362
363
364
365
366
367
368
369
370
371
372
373
374
375
376
377
378
379
380
381
382
383
384
提示
实际迁移重点总结如下:
- shebang 必须用
#!/usr/bin/env python3,否则新环境找不到 python 解释器。 - 所有 print 语法批量替换为 print()。
- os.popen 全部迁移为 subprocess.check_output,更好支持异常处理和编码。
- 文件读写建议加 encoding="utf-8",兼容中文及特殊字符。
- 其余如 try-except 异常捕获也建议覆盖到关键外部命令,提升鲁棒性。