 [/metrics] — 请求参数概括及详解索引速查
[/metrics] — 请求参数概括及详解索引速查
# 一、代码职责梳理
# 1. TimelineWebServices 【Controller 层】
入口代码:
timelineMetricStore.getTimelineMetrics(
parseListStr(metricNames, ","), // 支持多 metric
parseListStr(hostname, ","), // 支持多 host
appId, parseStr(instanceId),
parseLongStr(startTime), parseLongStr(endTime),
Precision.getPrecision(precision), parseIntStr(limit),
parseBoolean(grouped), parseTopNConfig(topN, topNFunction, isBottomN),
seriesAggregateFunction);
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
这里的逻辑可以拆成两个步骤:
参数解析
parseListStr、parseLongStr、parseBoolean等工具方法把 HTTP GET 参数 转成 Java 类型。- 避免字符串直接拼 SQL/HBase 查询,保证安全性与类型正确性。
调用服务层
- 参数准备好后,调用
timelineMetricStore.getTimelineMetrics。 - 实际运行时,
timelineMetricStore的实现类就是 HBaseTimelineMetricsService。
- 参数准备好后,调用
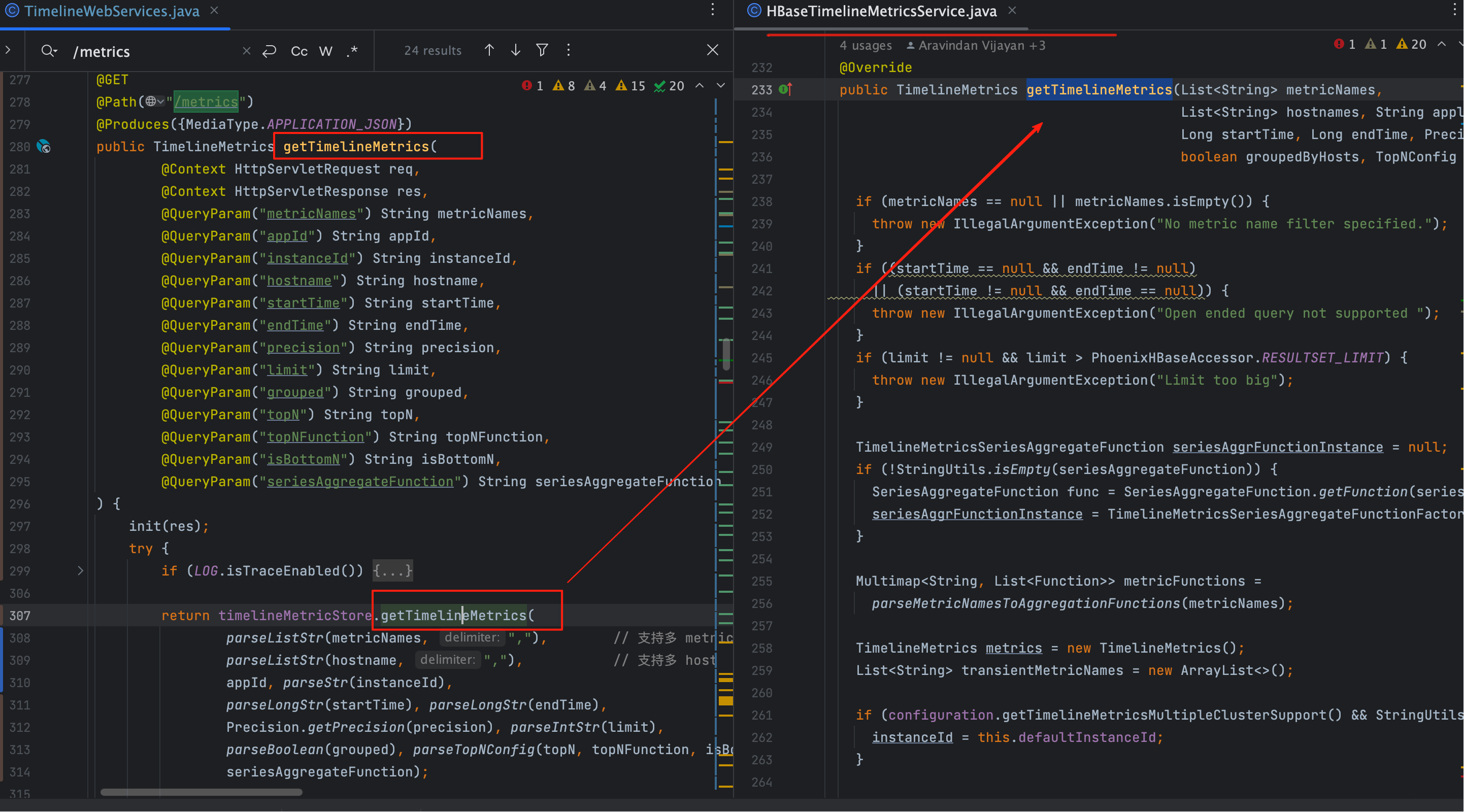
小结
上图对应了 Controller → Service 的调用关系:前者负责参数解析,后者负责查询与聚合。
# 二、参数详解索引
下面逐一对参数进行解读,配合源码和截图,帮助快速理解其作用。
# 1. metricNames
- 代码:
parseListStr(metricNames, ",") - 作用: 支持一次查询多个指标,参数之间用逗号分隔。
- 示例:
cpu_user,cpu_system。
详解可以参考这篇文章
# 2. hostname
- 代码:
parseListStr(hostname, ",") - 作用: 支持多个主机查询,用
,分隔。 - 示例:
host1,host2,host3。
详解可以参考这篇文章
# 3. appId
- 作用: 标识组件名称,例如
datanode、namenode、RESOURCEMANAGER。 - 理解: 其实就是主机上安装的组件 ID,Collector 通过它区分指标来源。
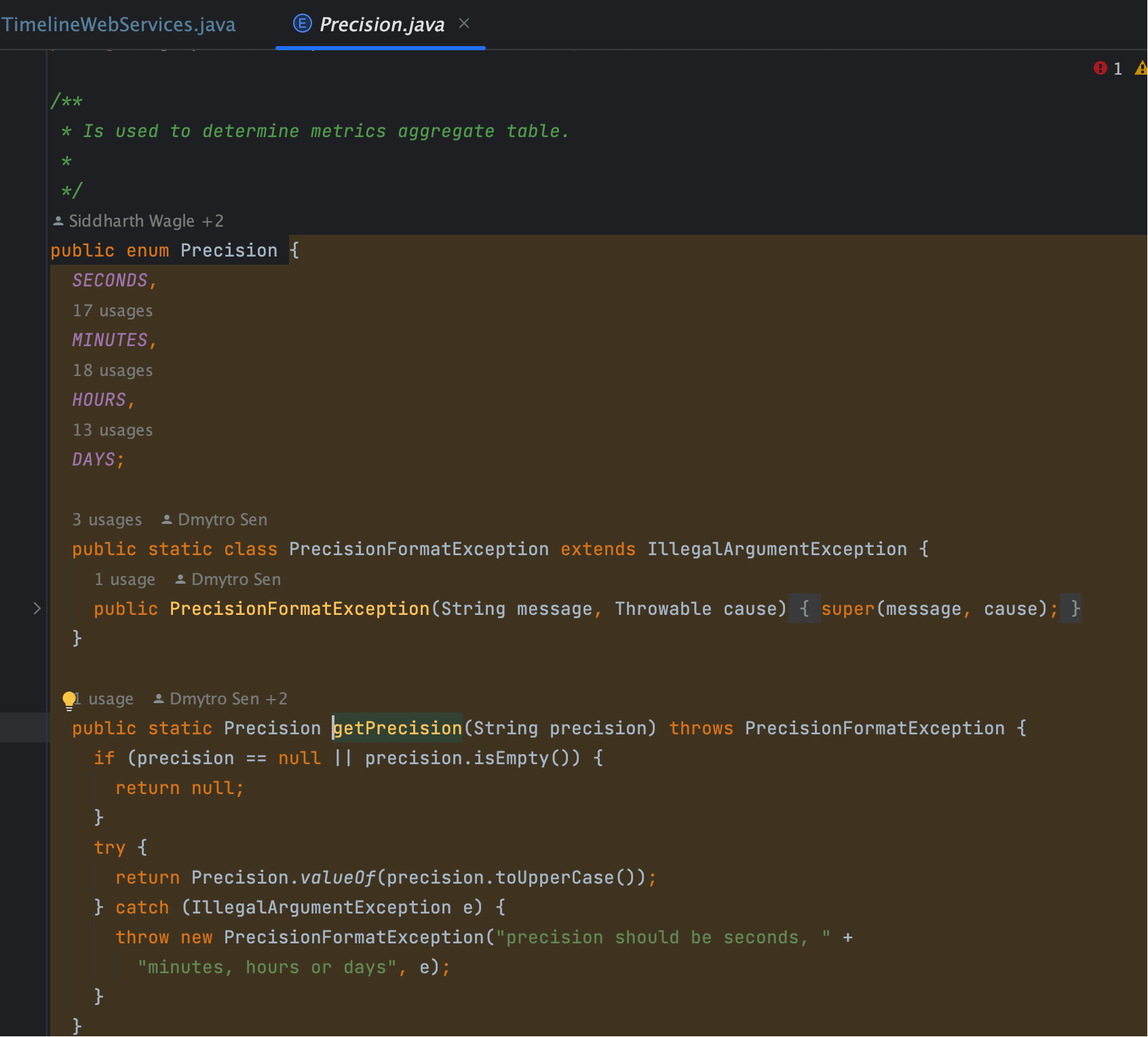
# 4. precision
- 代码:
Precision.getPrecision(precision) - 作用: 控制数据的粒度。
- 可选值: 秒 / 分钟 / 小时 / 天。
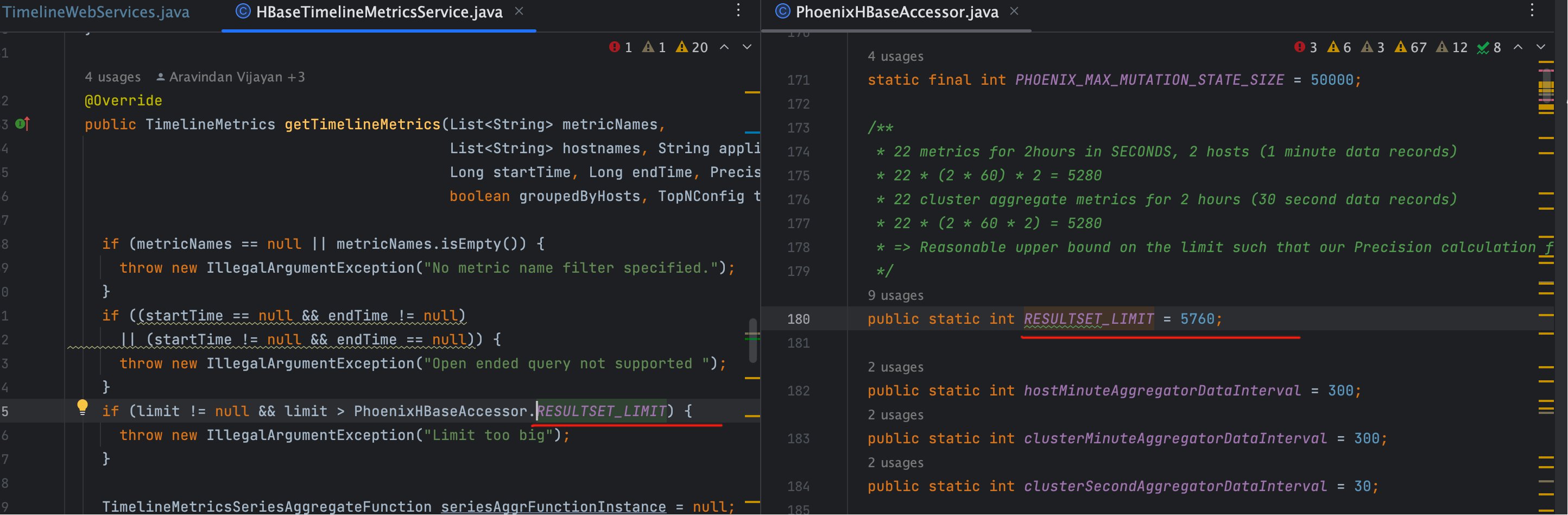
# 5. limit
- 作用: 限制返回的数据点数,避免接口返回过大结果集。
- 默认上限:
5760。
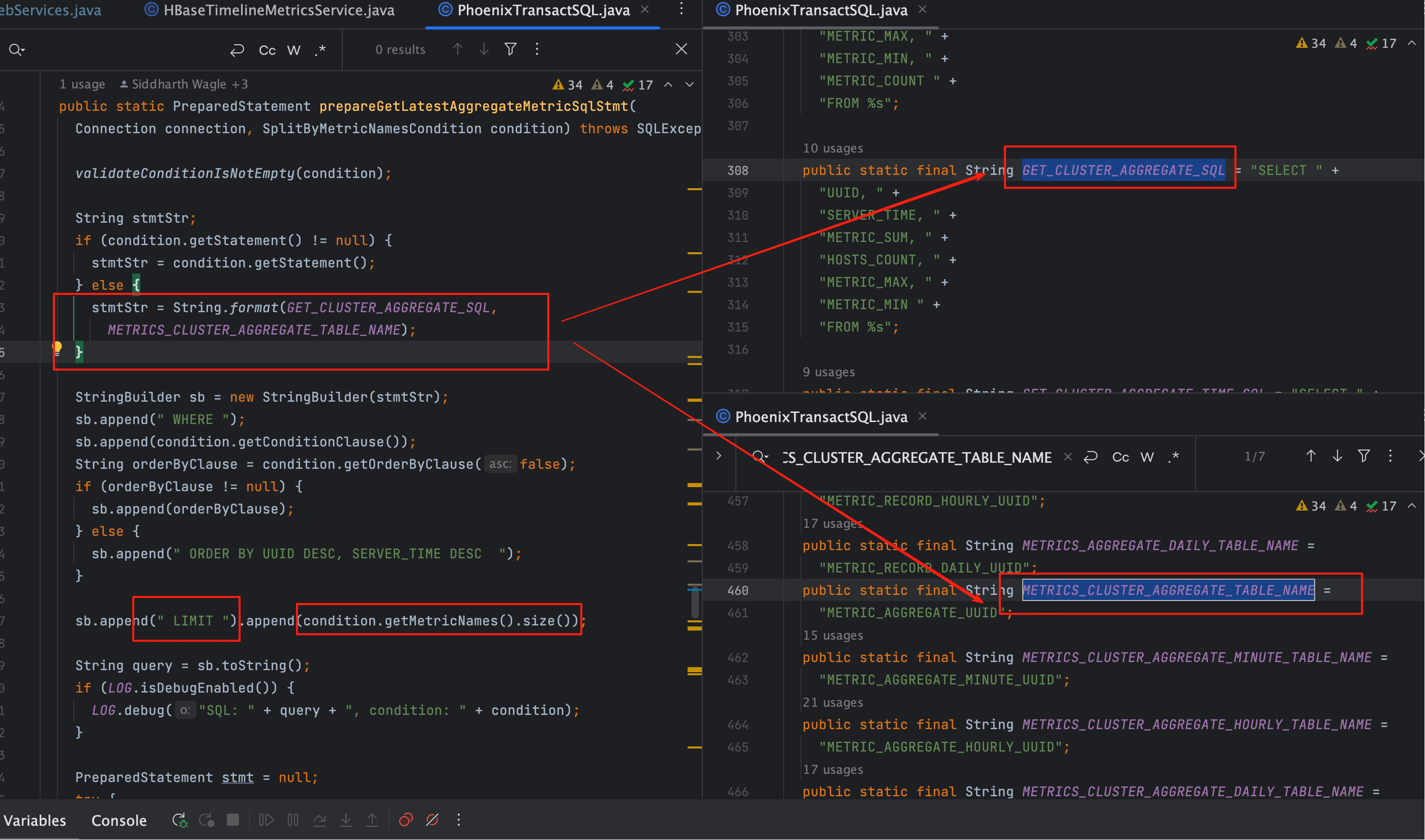
注意
若触发了 UUID 聚合表 查询,limit 参数会被忽略:
# 6. grouped
- 默认值:
true - 作用: 将多条结果合并成一条输出。
- 对比: 类似 SQL 中的
GROUP BY。
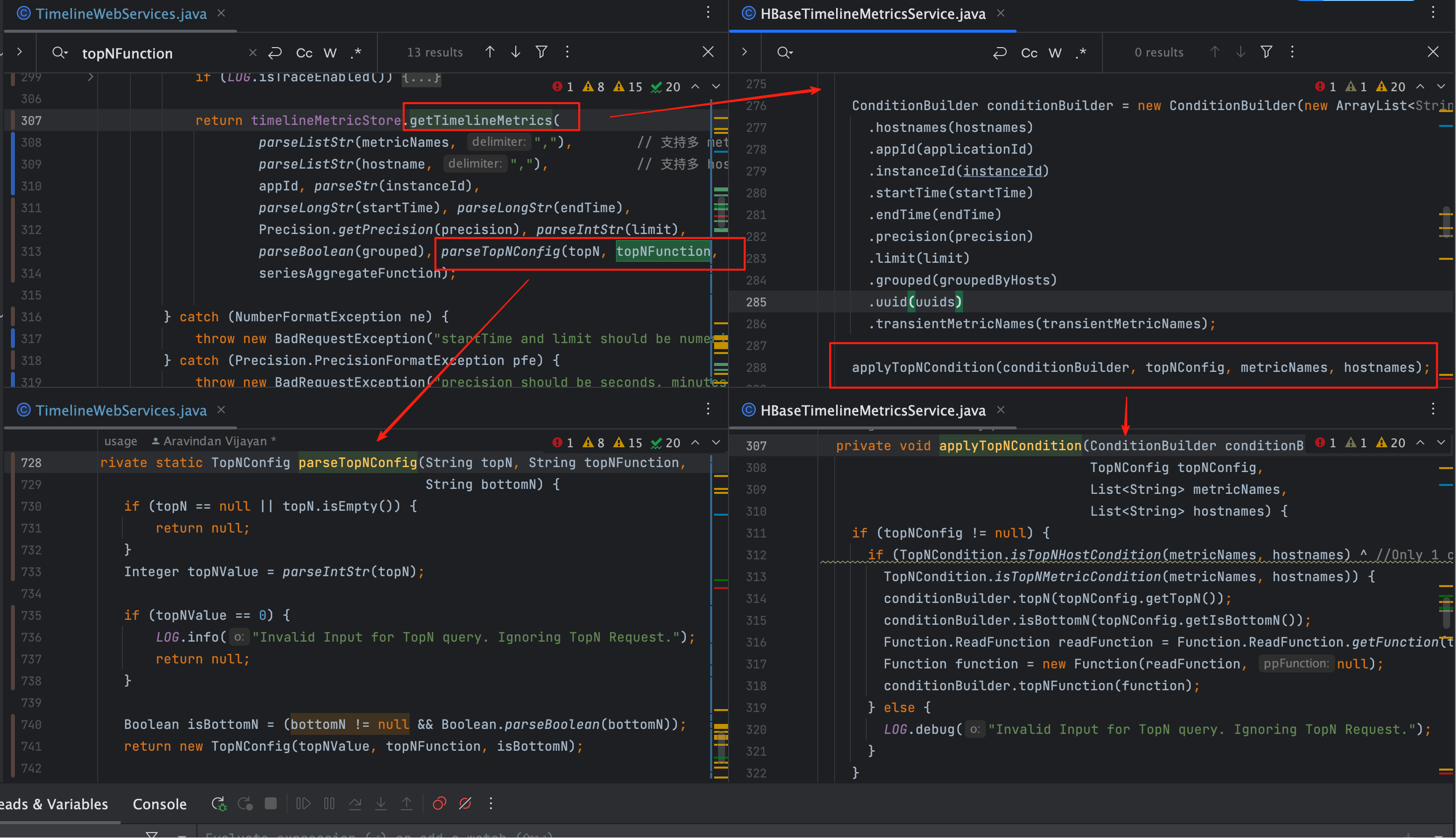
# 7. topN, topNFunction, isBottomN
- 作用: 触发 TopN 查询逻辑。
- 条件:
topN需要传入数字才生效。 - 实现: 在 Service 层拼接
applyTopNCondition。
# 8. seriesAggregateFunction
- 作用: 对结果集进行二次聚合。
- 支持函数:
avg、max、min、sum。 - 应用时机: 在结果返回之前。

详解可以参考这篇文章