 [/metrics/metadata] — 缓存数据装载Phoenix
[/metrics/metadata] — 缓存数据装载Phoenix
# 一、承接上节:缓存从哪来?
在上一节中,我们已经明确了:
请求 /metrics/metadata 时,数据是直接从 METADATA_CACHE 中返回的。
那么问题来了:METADATA_CACHE 又是何时、如何被填充的?
答案就在 TimelineMetricMetadataManager.initializeMetadata()。
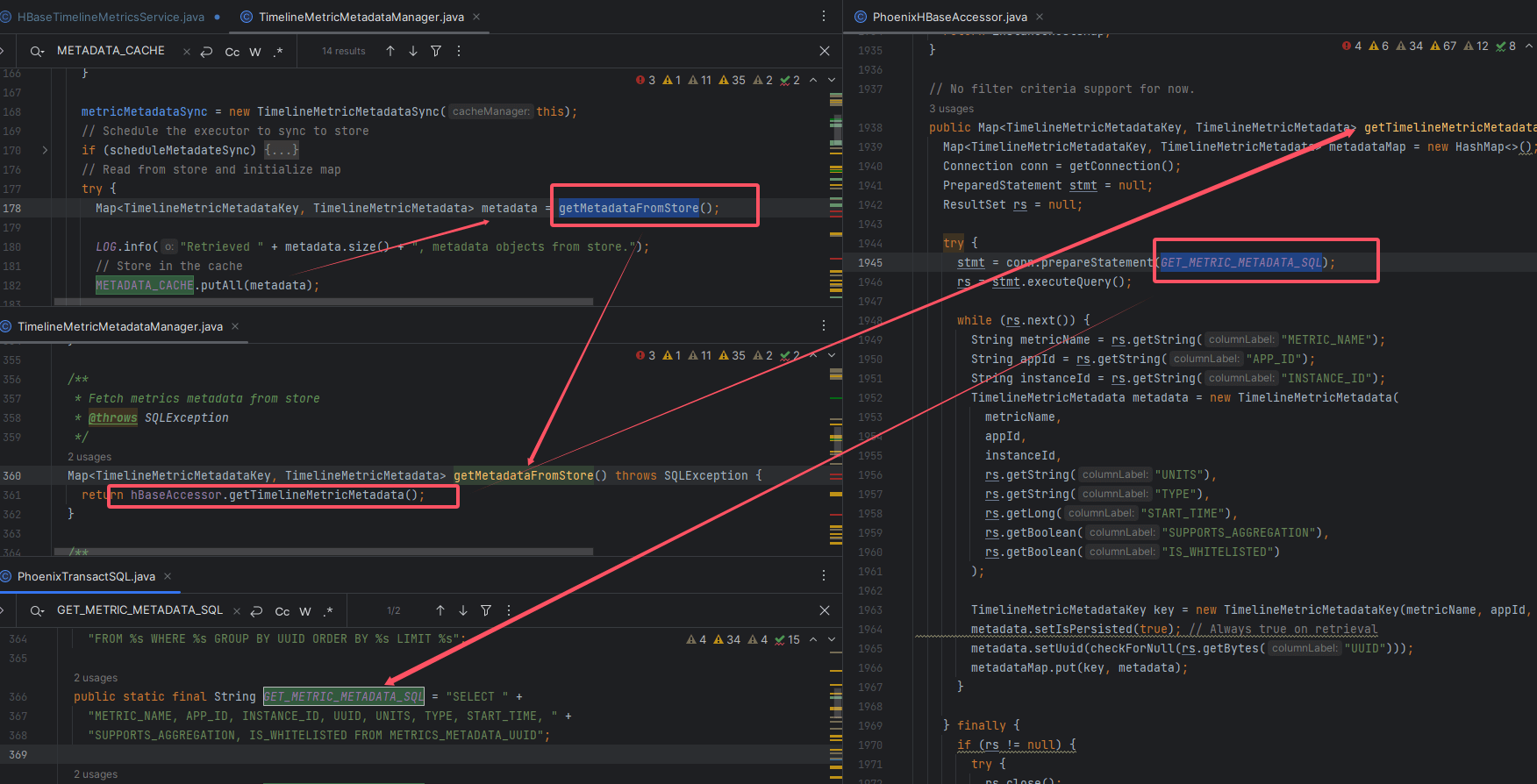
# 二、核心调用链
# 1、缓存初始化
Map<TimelineMetricMetadataKey, TimelineMetricMetadata> metadata = getMetadataFromStore();
METADATA_CACHE.putAll(metadata);
1
2
2
在 initializeMetadata 中,会调用 getMetadataFromStore(),将查询结果一次性 putAll 到缓存中。
# 2、数据来源:getMetadataFromStore
Map<TimelineMetricMetadataKey, TimelineMetricMetadata> getMetadataFromStore() throws SQLException {
return hbaseAccessor.getTimelineMetricMetadata();
}
1
2
3
2
3
可以看到,真正的查询交给了 PhoenixHBaseAccessor。
# 3、Phoenix 层查询
在 PhoenixHBaseAccessor 中,定义了完整的查询逻辑:
try (PreparedStatement stmt = conn.prepareStatement(GET_METRIC_METADATA_SQL);
ResultSet rs = stmt.executeQuery()) {
while (rs.next()) {
String metricName = rs.getString("METRIC_NAME");
String appId = rs.getString("APP_ID");
String instanceId = rs.getString("INSTANCE_ID");
TimelineMetricMetadata metadata =
new TimelineMetricMetadata(metricName, appId, instanceId);
metadata.setUuid(checkForNull(rs.getBytes("UUID")));
metadata.setUnits(rs.getString("UNITS"));
metadata.setType(rs.getString("TYPE"));
metadata.setStartTime(rs.getLong("START_TIME"));
metadata.setSupportsAggregates(rs.getBoolean("SUPPORTS_AGGREGATION"));
metadata.setWhitelisted(rs.getBoolean("IS_WHITELISTED"));
TimelineMetricMetadataKey key =
new TimelineMetricMetadataKey(metricName, appId, instanceId);
metadata.setPersisted(true);
metadataMap.put(key, metadata);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
这里的核心步骤:
- 执行 SQL
- 遍历 ResultSet
- 封装为
TimelineMetricMetadata - 与 Key 组装为 Map,最终返回
# 三、SQL 定义
查询所用的 SQL 定义在 PhoenixTransactSQL 中:
public static final String GET_METRIC_METADATA_SQL =
"SELECT METRIC_NAME, APP_ID, INSTANCE_ID, UUID, UNITS, TYPE, START_TIME, " +
"SUPPORTS_AGGREGATION, IS_WHITELISTED FROM METRICS_METADATA_UUID";
1
2
3
2
3
提示
数据源就是 METRICS_METADATA_UUID 表。 该表存储了 Collector 内所有监控指标的“元信息”,是 UI 与 API 查询的基础。
# 四、执行逻辑回顾
整个装载过程可归纳为以下四步:
| 步骤 | 方法/位置 | 作用 |
|---|---|---|
| 1️⃣ | initializeMetadata | 触发缓存加载逻辑 |
| 2️⃣ | getMetadataFromStore | 调用 PhoenixHBaseAccessor |
| 3️⃣ | GET_METRIC_METADATA_SQL | 查询 HBase 的 METRICS_METADATA_UUID 表 |
| 4️⃣ | putAll(metadata) | 写入 ConcurrentHashMap 缓存 |
- 01
- [/metrics/metadata] — 元数据查询和使用 GET09-12
- 02
- [/metrics/metadata] — 请求完整链路解读09-12
- 03
- [监控表] — Java代码验证表关系 代码可拷贝运行09-10