 [监控表] — Master组件和Slave组件判别
[监控表] — Master组件和Slave组件判别
# 一、前序章节回忆 铺垫
还记得上一讲我们提到的 masterComponents 和 slaveComponents 吗? 在监控表的存储设计中,split on 切分是否均匀、Region 是否热点、扩容后负载是否重新均衡,都与 appId 属于 Master 还是 Slave 组件密切相关。 本章就沿着“谁来判别 → 如何落地 → 为什么影响切分”这条线,把机制讲透、把验证方法给全、把坑点列清。
读前导览
- 先看“源码溯源”,搞清 分类结果从何而来;
- 再看“落地配置”,知道 它被写到哪里;
# 二、源码溯源:参数从哪里来? 链路定位
# 1、入口代码截图
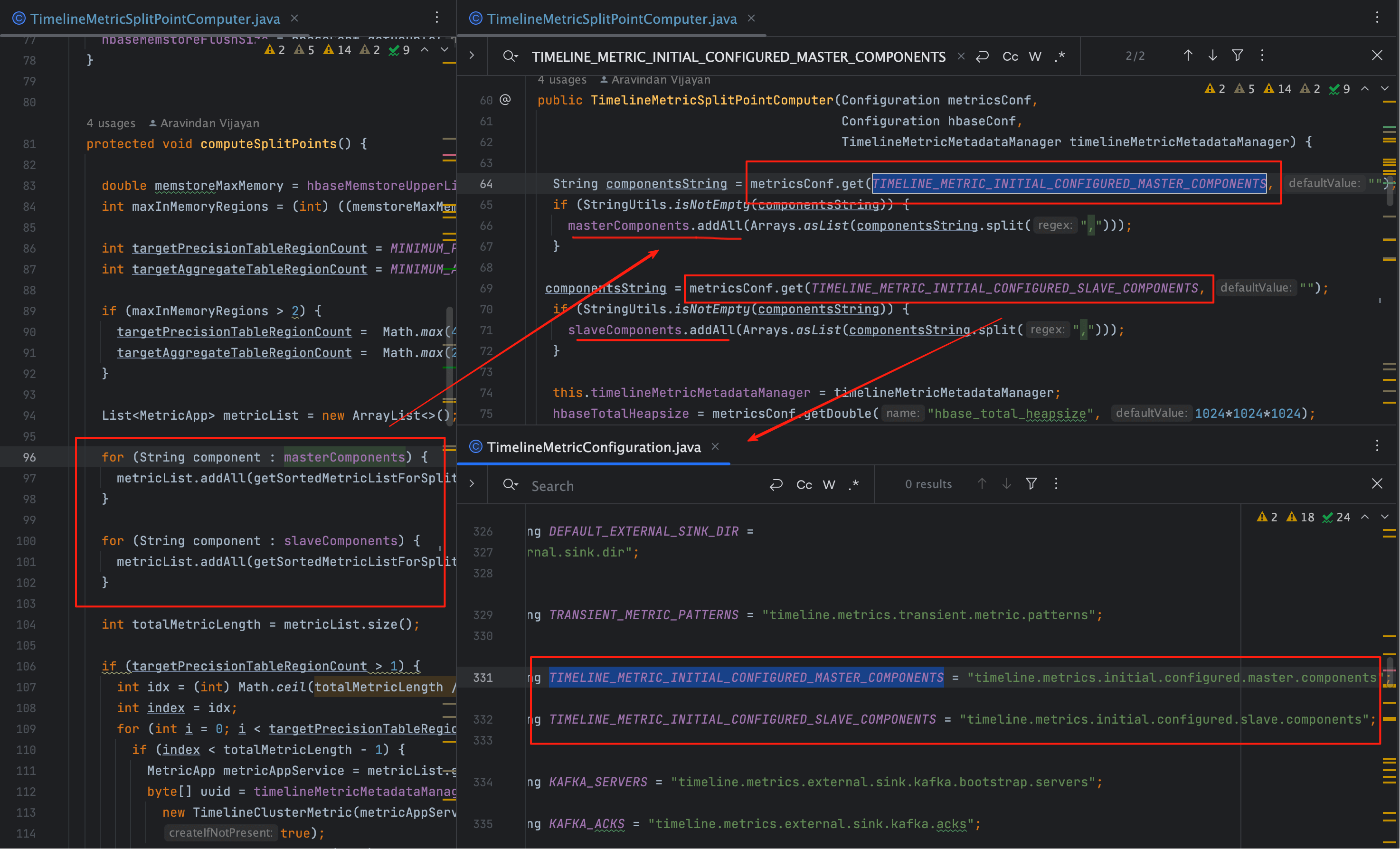
这张图展示了我们在 ambari-metrics 代码里定位 masterComponents / slaveComponents 的过程:
它们不是 Collector 内部计算出来的,而是 通过 properties 注入 的。
提示很明确——真正的来源在 Ambari Server 下发的配置。
# 2、Ambari 侧分类逻辑长什么样?
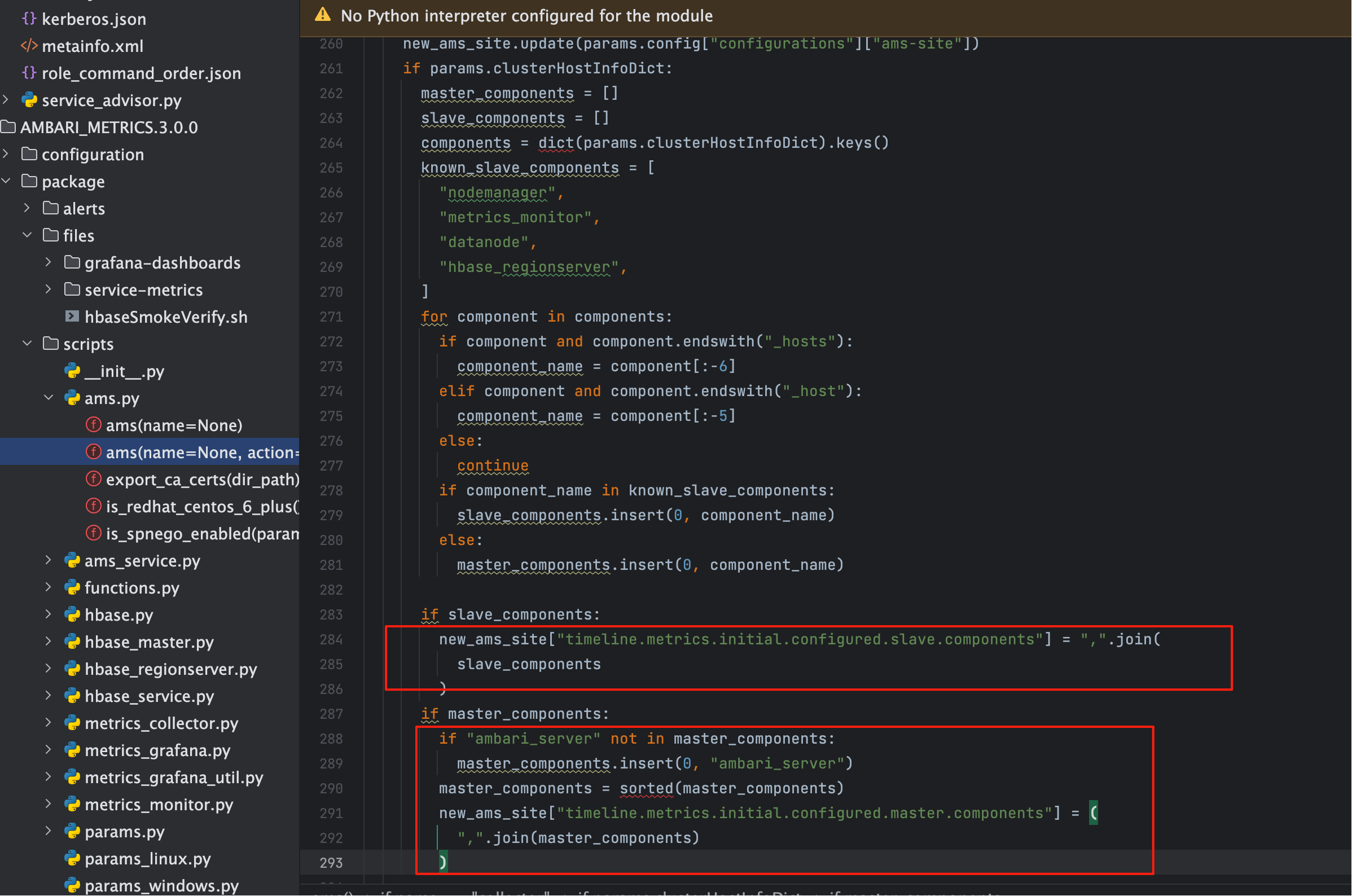
在 ams 的 Python 脚本中,会遍历 clusterHostInfoDict,根据 known_slave_components 白名单 把组件拆成 Master 与
Slave,最后写回 ams-site.xml。这一步决定了 初始分类结果。
# 3、关键代码片段(节选)
if params.clusterHostInfoDict:
master_components = []
slave_components = []
components = dict(params.clusterHostInfoDict).keys()
known_slave_components = [
"nodemanager", "metrics_monitor", "datanode", "hbase_regionserver",
]
for component in components:
if component and component.endswith("_hosts"):
component_name = component[:-6]
elif component and component.endswith("_host"):
component_name = component[:-5]
else:
continue
if component_name in known_slave_components:
slave_components.insert(0, component_name)
else:
master_components.insert(0, component_name)
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
判别规则小结
- Key 名识别:以
_hosts/_host结尾的 key,去后缀即组件名; - 白名单归类:命中
known_slave_components→ Slave; - 兜底策略:其余默认 Master;
- 附加处理:
ambari_server会被插入 Master,并在入库前统一排序。
# 4、常见 key 与组件名对照
| clusterHostInfo 的 key | 解析后的组件名 | 默认归类 |
|---|---|---|
namenode_hosts | namenode | Master |
resourcemanager_hosts | resourcemanager | Master |
zookeeper_server_hosts | zookeeper_server | Master |
datanode_hosts | datanode | Slave |
nodemanager_hosts | nodemanager | Slave |
hbase_master_hosts | hbasemaster | Master |
hbase_regionserver_hosts | hbase_regionserver | Slave |
metrics_monitor_hosts | metrics_monitor | Slave |
易混点
自定义服务有时会出现 xxx_host 单数;解析时同样会去掉 _host。命名不规范(大小写、下划线)会导致分类异常,后文给出校验方法。
# 三、clusterHostInfo 的来源与现场定位 命令快照
# 1、它就藏在 command-*.json
如下图所示,config['clusterHostInfo'] 就是组件分布快照的载体:
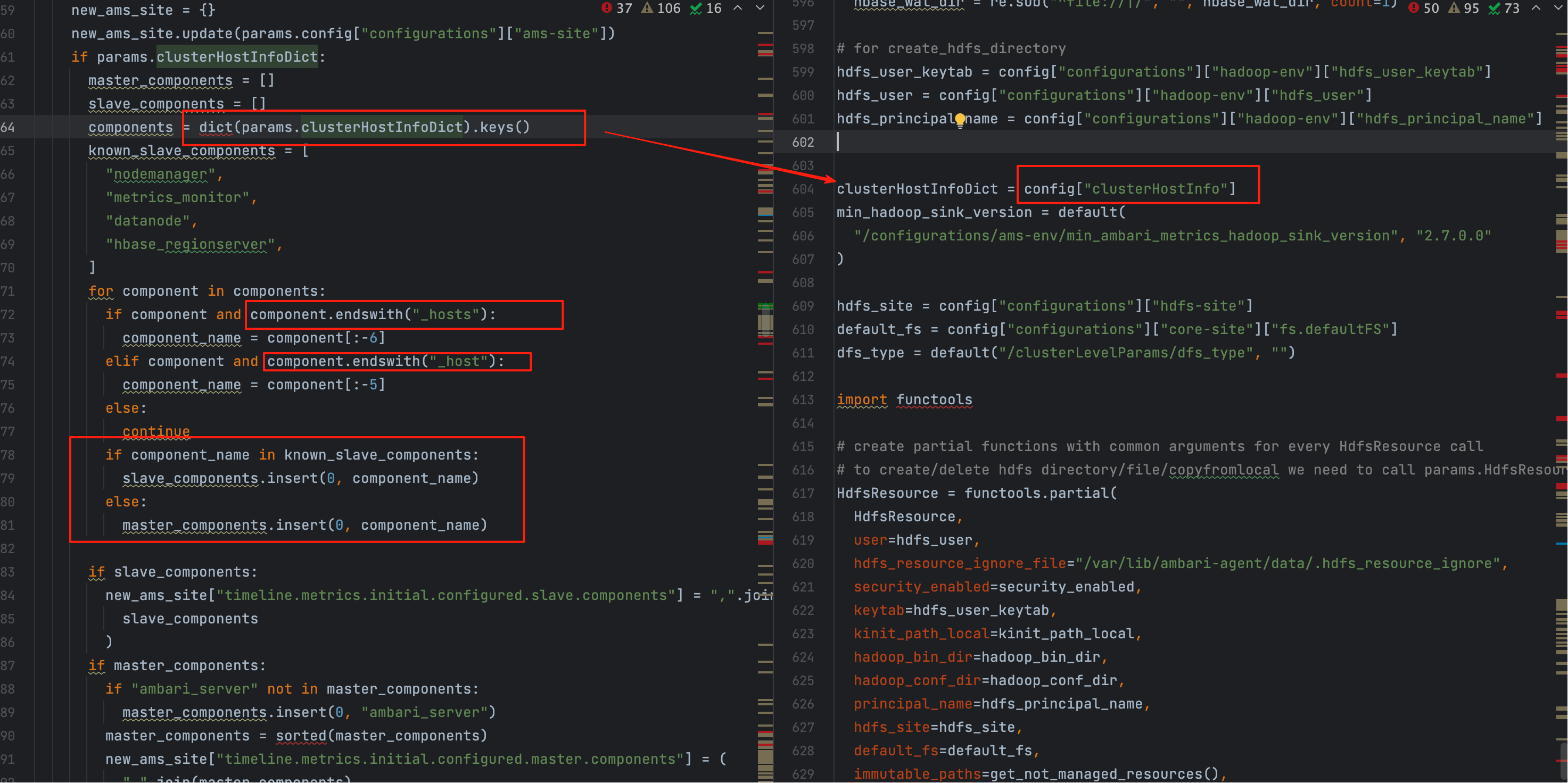
Ambari Agent 会把 Server 下发的命令(含配置、主机映射等)保存为
command-*.json。
温馨提醒
command-*.json为什么是Server下发,我们在Ambari成神之路讲过。他的执行逻辑以及参数绑定,请自行查阅
在 Agent 机器上可直接定位(路径视安装而定):
# 常见路径
ls -ltr /var/lib/ambari-agent/data/ | tail -n 3
2
# 2、命令文件里的典型示例

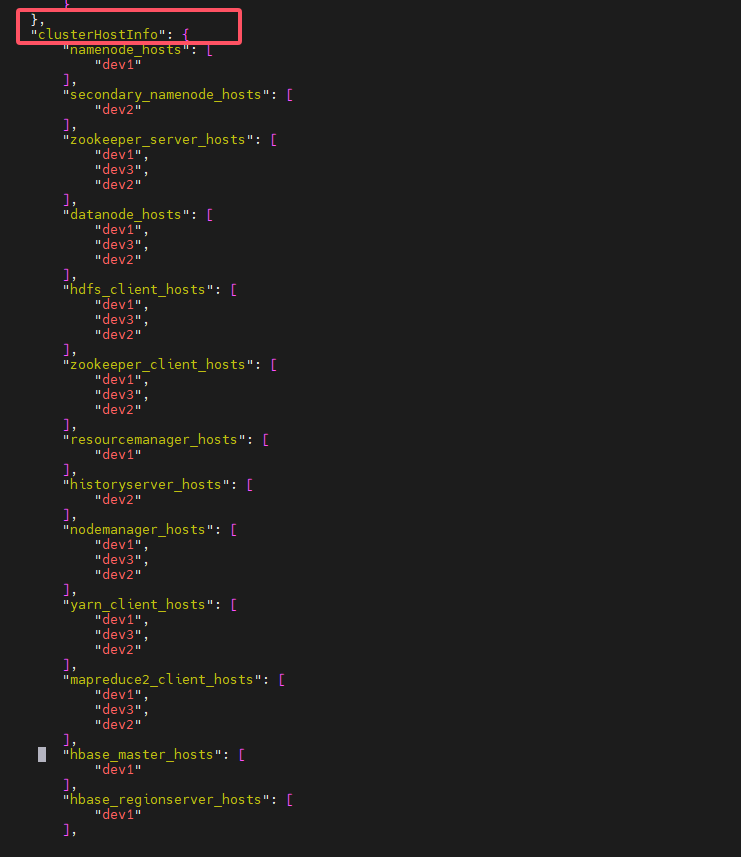
"clusterHostInfo": {
"namenode_hosts": ["dev1"],
"secondary_namenode_hosts": ["dev2"],
"zookeeper_server_hosts": ["dev1", "dev3", "dev2"],
"datanode_hosts": ["dev1", "dev3", "dev2"],
"hbase_master_hosts": ["dev1"],
"hbase_regionserver_hosts": ["dev1"]
}
2
3
4
5
6
7
8
# 四、写入 ams-site.xml:分类结果如何落地? 配置注入
分类完成后,结果会被更新到 Collector 的配置文件:
/etc/ambari-metrics-collector/conf/ams-site.xml
# 1、配置文件截图
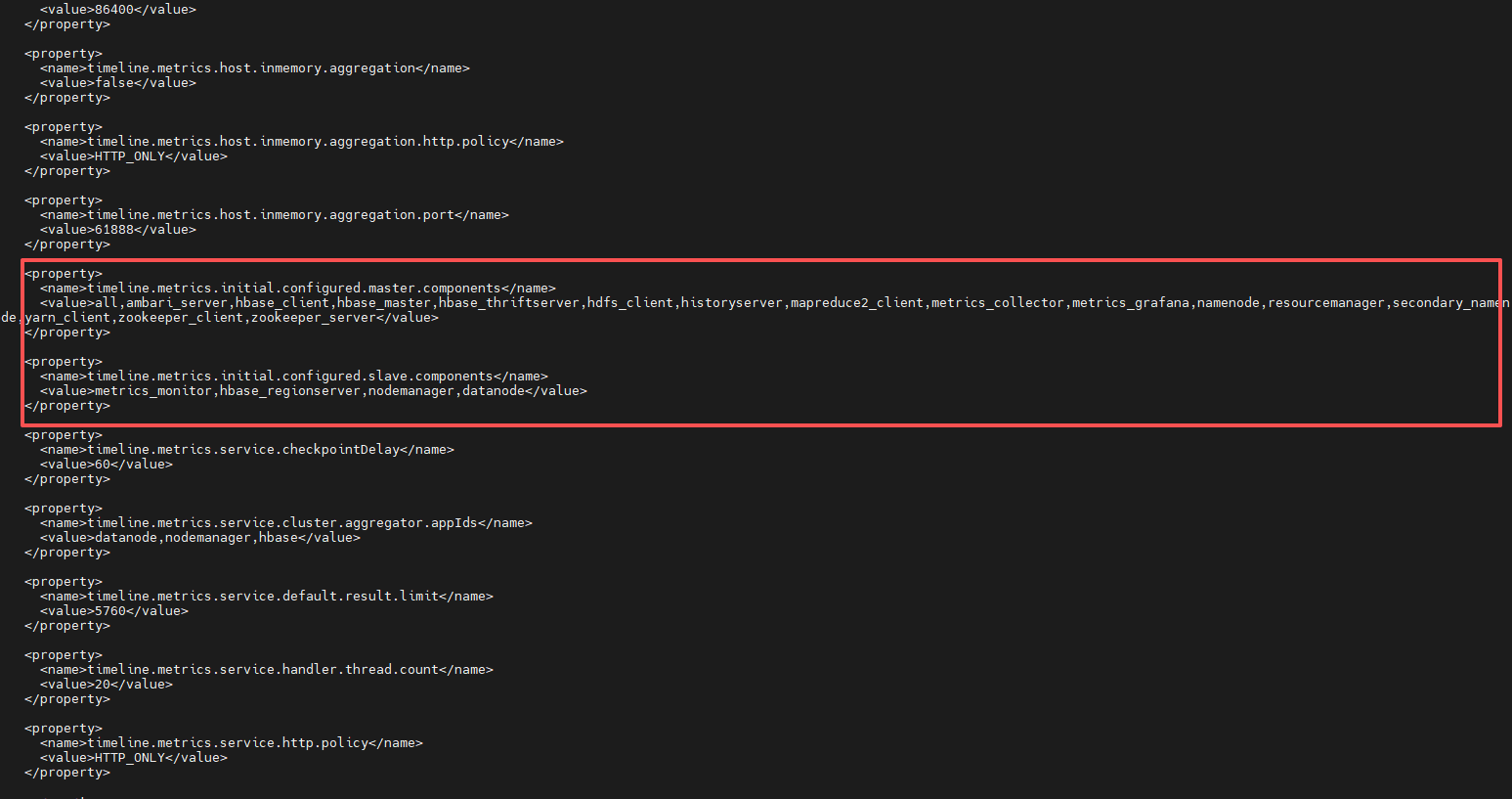
可见两个关键属性:
timeline.metrics.initial.configured.master.componentstimeline.metrics.initial.configured.slave.components
# 2、典型落地片段
<property>
<name>timeline.metrics.initial.configured.master.components</name>
<value>ambari_server,hbasemaster,historyserver,namenode,resourcemanager,zookeeper_server</value>
</property>
<property>
<name>timeline.metrics.initial.configured.slave.components</name>
<value>datanode,hbase_regionserver,nodemanager,metrics_monitor</value>
</property>
2
3
4
5
6
7
8
9
这些值会被何时读取?
Collector 初始化(init())阶段会加载 ams-site.xml,把上述组件集合作为 初始分类 进入内存;
后续扩容/缩容如有变化,建议 重新部署配置 + 重启 AMS,以确保内存视图与磁盘配置一致。