 [/metrics/aggregated] — 聚合指标触发逻辑溯源
[/metrics/aggregated] — 聚合指标触发逻辑溯源
# 一、起点:saveHostAggregateRecords 的战略意义
在 Ambari Metrics 系统中,数据分为两大类:
- 原始指标:最基础的点状数据,例如某台主机某时刻的 CPU 使用率。
- 聚合指标:对一段时间或某个范围内的指标数据进行统计后的结果,例如一分钟内的平均 CPU 使用率。
提示
聚合指标的重要性不止于数据缩减,它直接关系到 可视化展现效率 和 告警策略触发。 换句话说,如果没有合理的聚合,整个监控系统会陷入原始数据过载的泥沼。
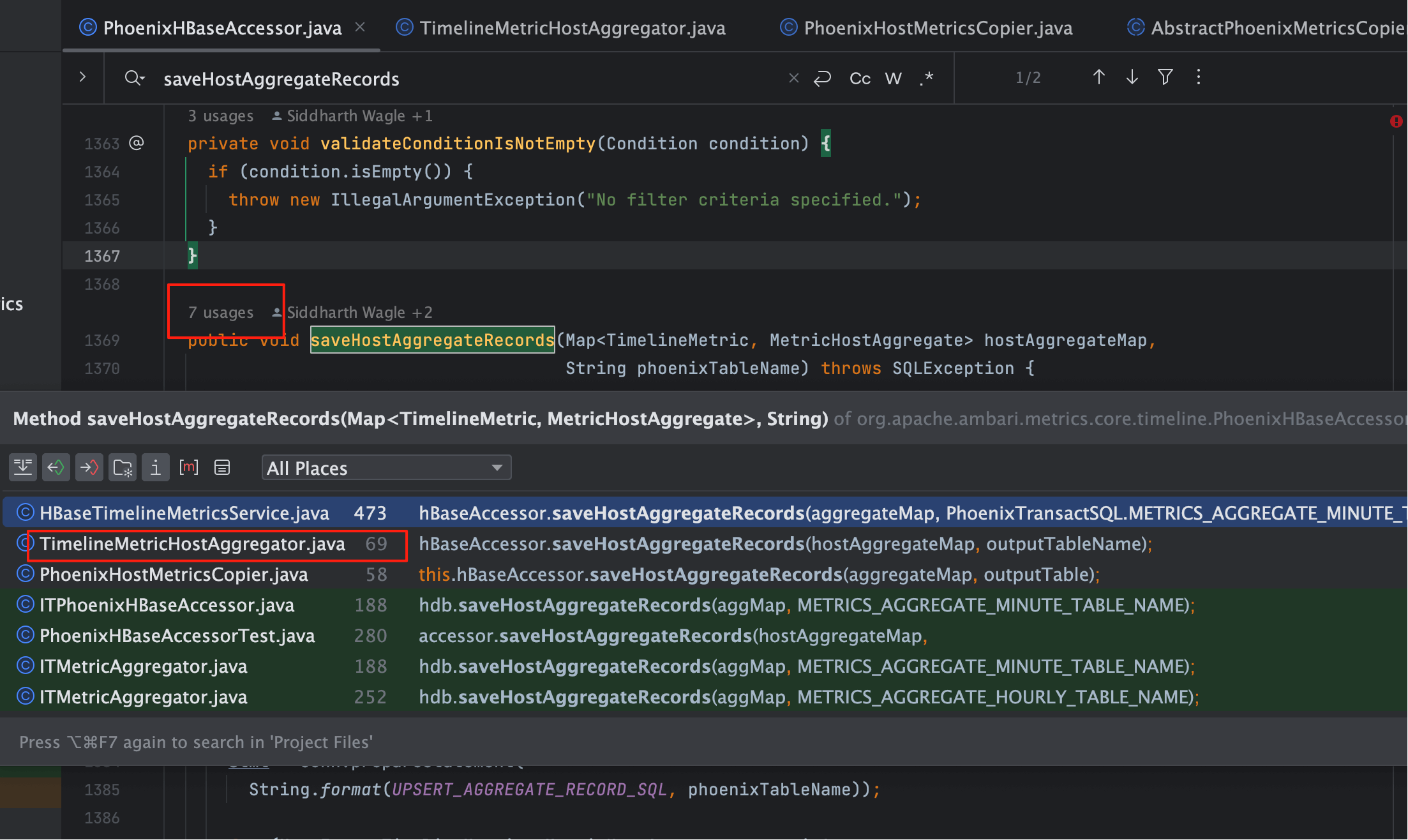
而 saveHostAggregateRecords 就是承载这个过程的“出口”。通过全局搜索可见,它被调用 7 次,这些调用点正是理解整个聚合触发链路的入口。
# 二、TimelineMetricHostAggregator:第一个落点
在调用链中,第一个出现的是 TimelineMetricHostAggregator。
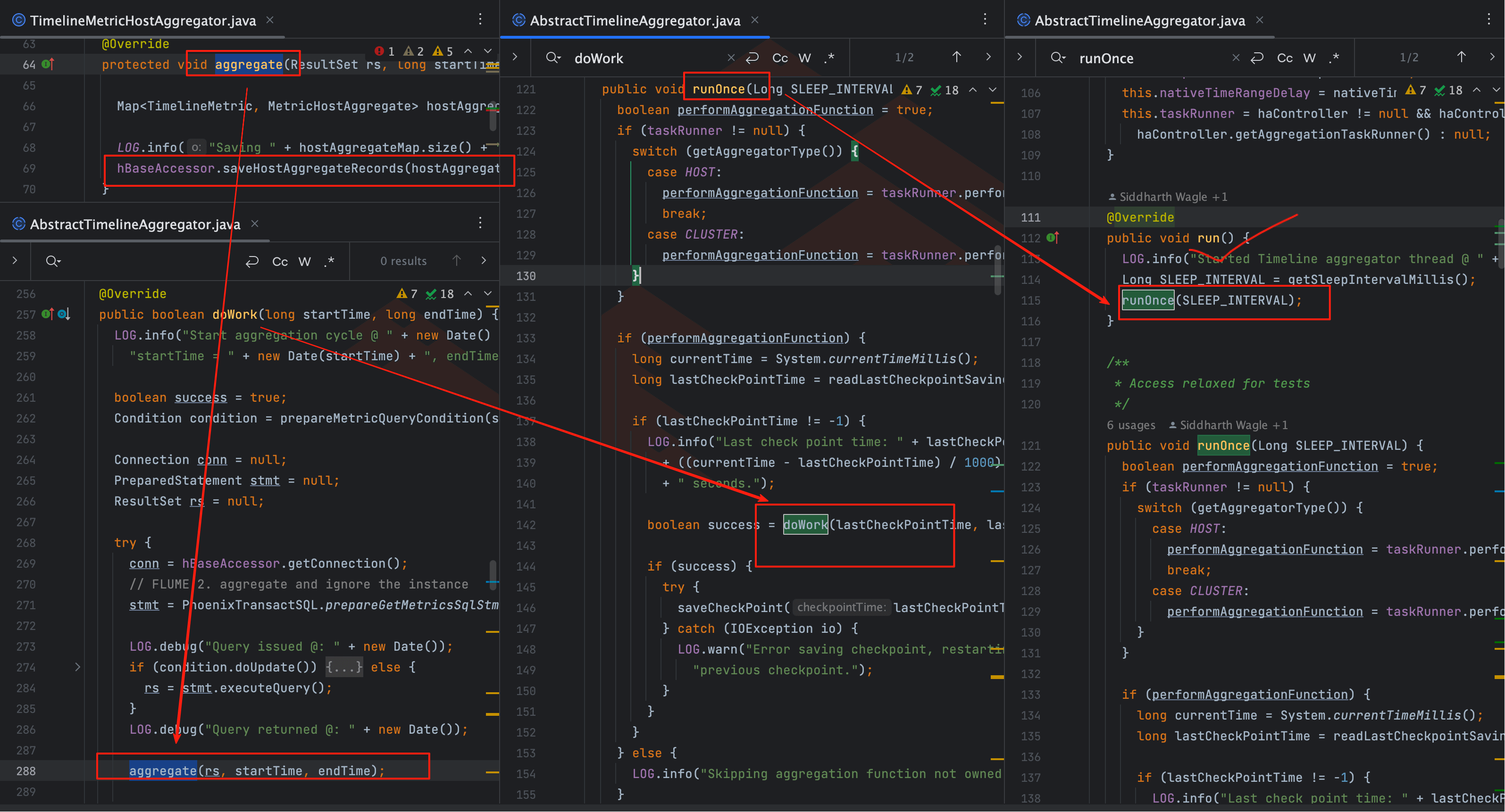
TimelineMetricHostAggregator extends AbstractTimelineAggregator
1
# 1、调用关系
- saveHostAggregateRecords → 在
aggregate()中被调用 - aggregate() → 来自
AbstractTimelineAggregator.doWork() - doWork() → 由
runOnce()调用 - runOnce() → 最终落在
run()
# 2、设计思想
这种模式体现了典型的 模板方法模式:
- 抽象类 (
AbstractTimelineAggregator) 提供统一调度框架 - 子类 (
TimelineMetricHostAggregator) 实现具体逻辑
注意
如果你要自定义聚合逻辑,切记要遵守这个继承体系,否则无法被调度线程正确识别。
# 三、run 方法与多线程调度
关键代码如下:
@Override
public void run() {
LOG.info("Started Timeline aggregator thread @ " + new Date());
Long SLEEP_INTERVAL = getSleepIntervalMillis();
runOnce(SLEEP_INTERVAL);
}
1
2
3
4
5
6
2
3
4
5
6
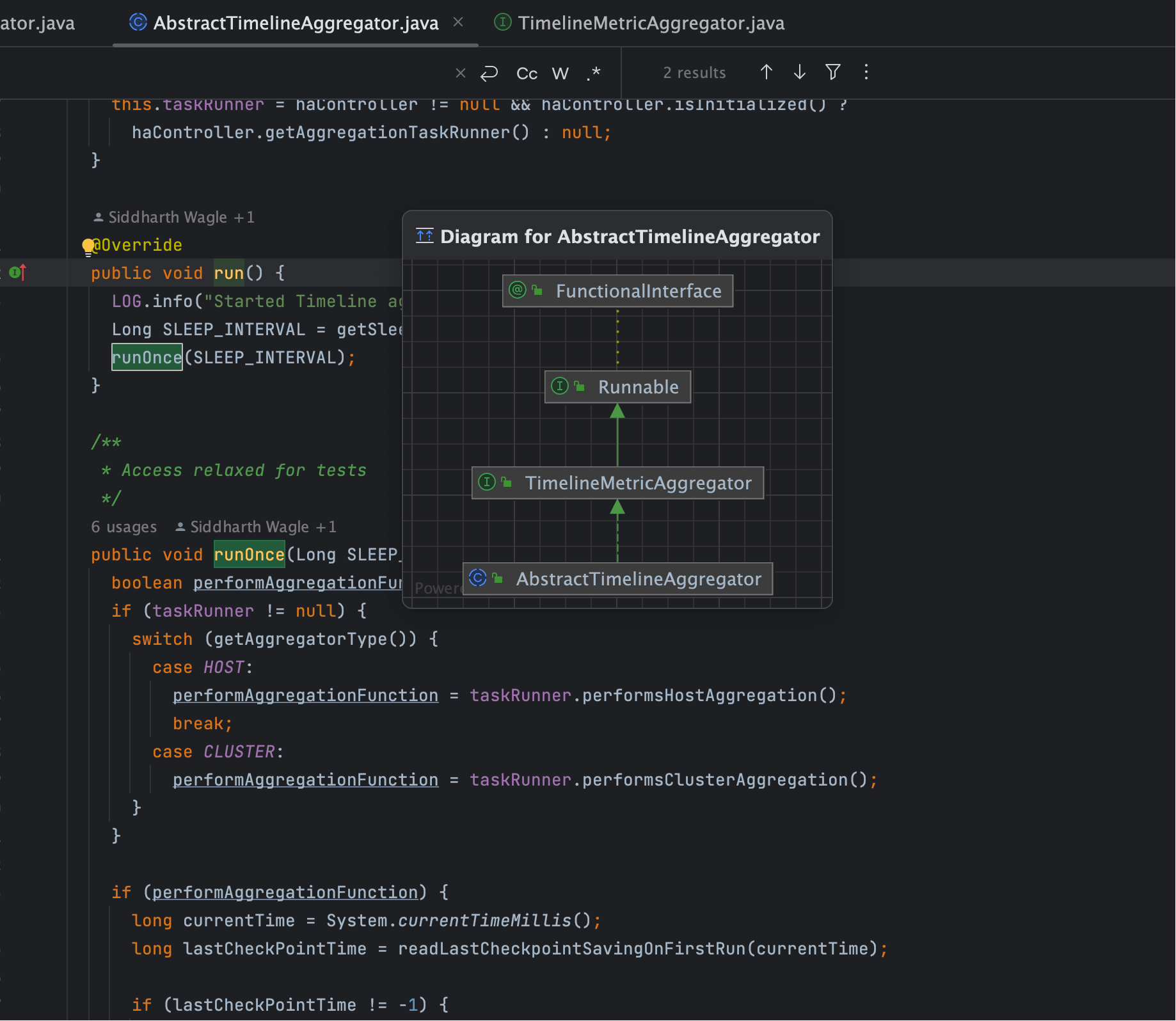
这里有两个重要信号:
- Runnable 接口:run 方法表明它是一个 Runnable 任务,能被线程池调度。
- 定时触发:内部调用
runOnce,意味着周期性任务由外部调度器控制。
日志截图也佐证了这一点:
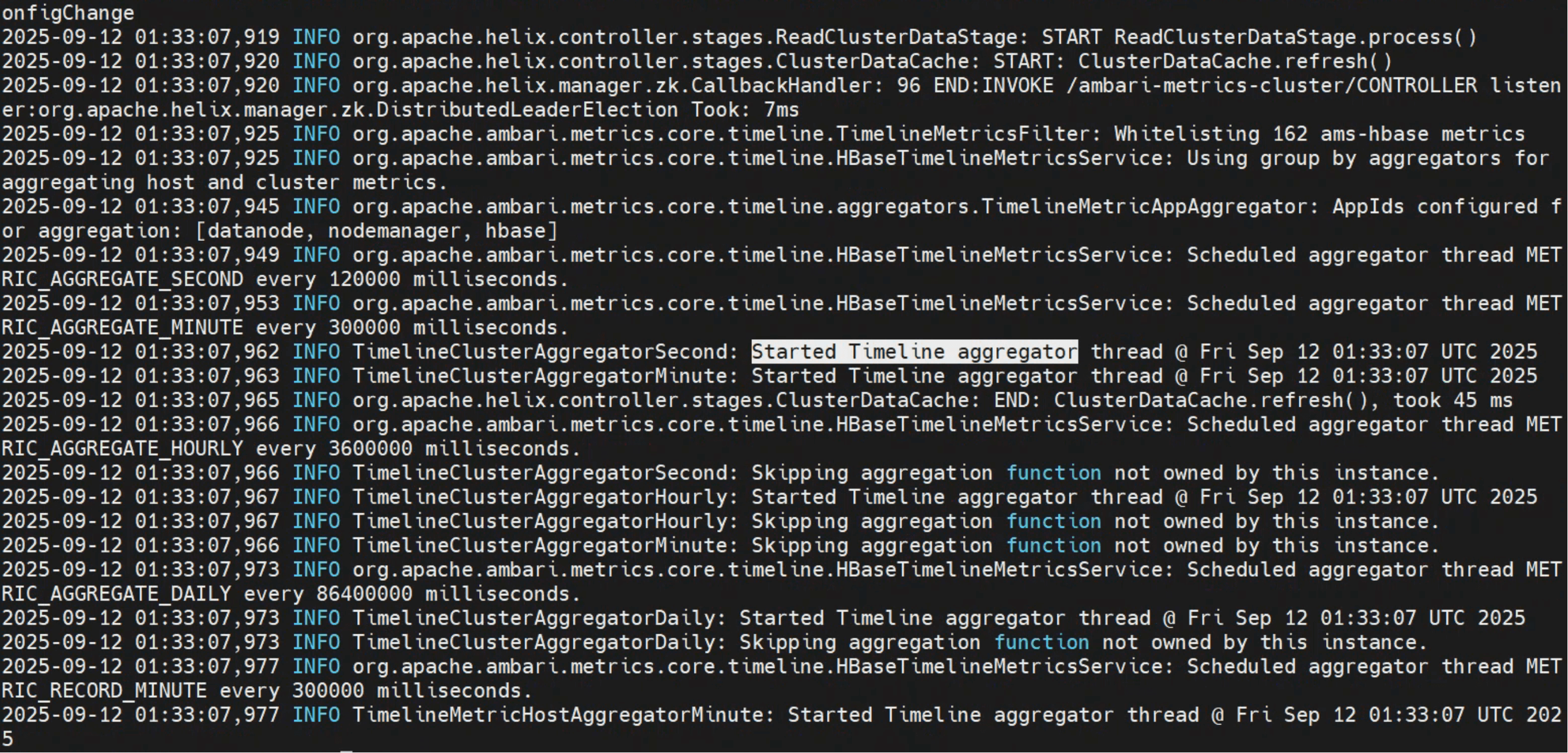
小结
每一次日志打印背后,代表的是一次完整的 聚合执行周期。
# 四、聚合器家族谱系
我们先来看一下 AbstractTimelineAggregator 的子类全景:

提示
从图中可以看到子类数量不少,看似涵盖了多种聚合维度。 但结合之前的探究,由于我们当前使用的都是 v2 表结构,真正能够投入使用的类其实有限。
我们再来看下图,我已经在其中做了标记:
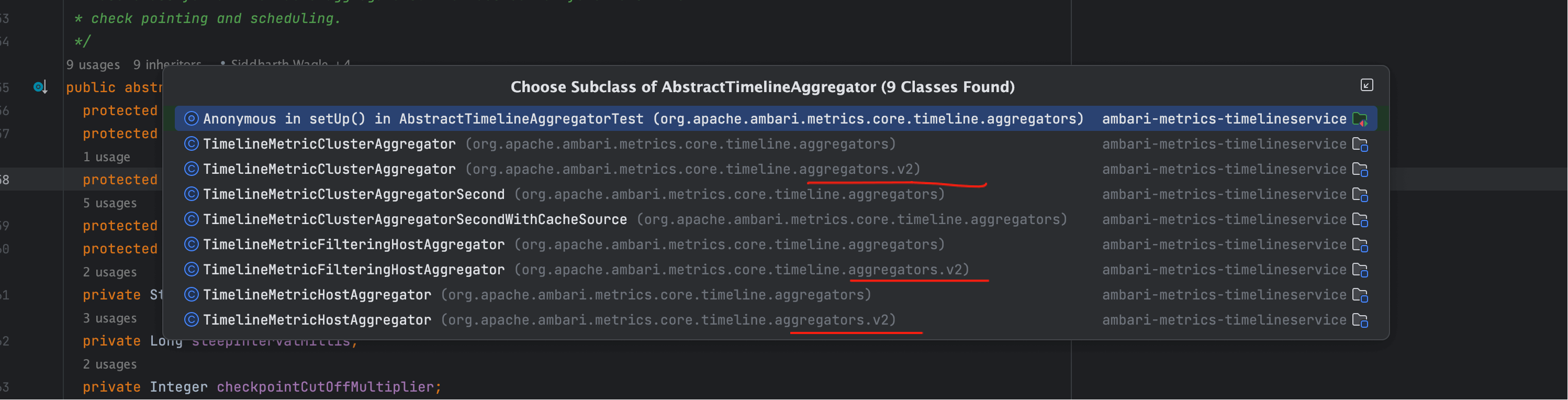
注意
- 类清单 ≠ 实际运行;
- v2 环境下只有少数几个类会被真正调度。
# 五、initializeSubsystem:一切的起点
我们回到初始化入口 initializeSubsystem。
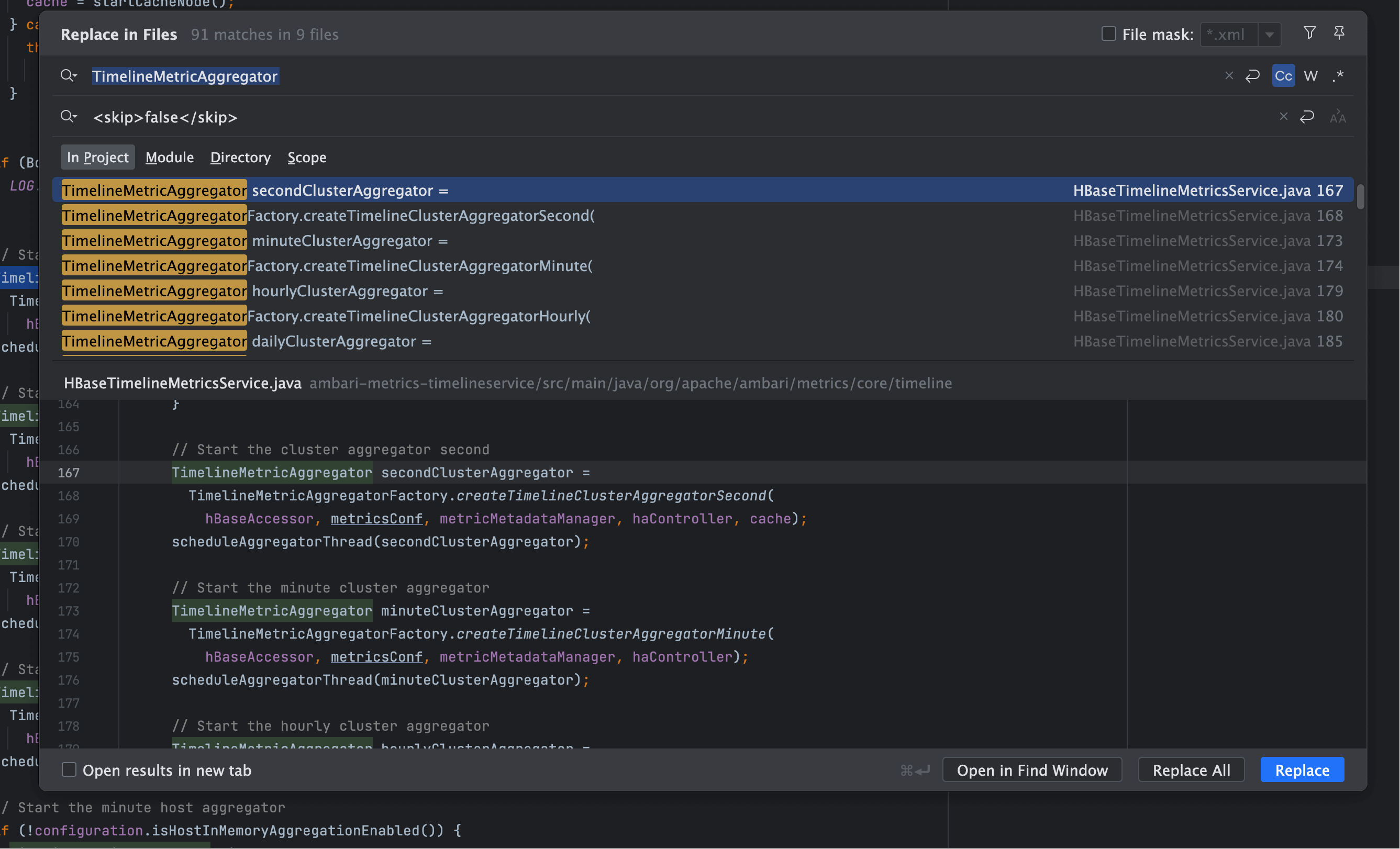
这里完成了以下步骤:
- 初始化 HBase 存储访问层 (
PhoenixHBaseAccessor) - 加载和校验 Metric Metadata
- 初始化聚合器工厂
TimelineMetricAggregatorFactory - 使用
scheduleAggregatorThread将各个聚合器纳入调度
初始化片段
TimelineMetricAggregator hourlyHostAggregator =
TimelineMetricAggregatorFactory.createTimelineMetricAggregatorHourly(
hBaseAccessor, metricsConf, metricMetadataManager, haController);
scheduleAggregatorThread(hourlyHostAggregator);
1
2
3
4
2
3
4
提示
注意配置项中存在聚合开关,例如 isHostInMemoryAggregationEnabled,在某些模式下会跳过 Host 聚合器。
# 六、scheduleAggregatorThread:核心逻辑
private void scheduleAggregatorThread(final TimelineMetricAggregator aggregator) {
if (!aggregator.isDisabled()) {
ScheduledExecutorService executorService =
Executors.newSingleThreadScheduledExecutor(
r -> new Thread(r, ACTUAL_AGGREGATOR_NAMES.get(aggregator.getName()))
);
executorService.scheduleAtFixedRate(
aggregator,
0L,
aggregator.getSleepIntervalMillis(),
TimeUnit.MILLISECONDS
);
LOG.info("Scheduled aggregator thread " + aggregator.getName() +
" every " + aggregator.getSleepIntervalMillis() + " milliseconds.");
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
# 核心要点
- 单线程调度:每个聚合器独立线程,避免相互干扰
- 固定周期执行:
scheduleAtFixedRate保证调度稳定 - 可配置的间隔:间隔由
getSleepIntervalMillis()决定 - 日志可观测性:清晰标明每个聚合器的执行频率
注意
若某个聚合器执行过慢,可能导致线程阻塞,影响后续调度周期。建议在性能调优时重点关注 minute 粒度的执行耗时。
# 七、调用链可视化
flowchart TD
A[initializeSubsystem] --> B[Factory 创建 Aggregator]
B --> C[scheduleAggregatorThread]
C --> D[ScheduledExecutorService]
D --> E[run()]
E --> F[runOnce]
F --> G[doWork]
G --> H[aggregate]
H --> I[saveHostAggregateRecords → HBase]
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
从反向出发,正向总结
最终落点是 HBase,调度逻辑则完全交由 JVM 线程池。