 [主启动类] — HBaseTimeline初始化职责
[主启动类] — HBaseTimeline初始化职责
# 一、上节回忆
关键结论
init 阶段的执行实质落在 AbstractService → serviceInit 的两个子类上:
AMSApplicationServer 负责加载配置(hbase-site.xml / ams-site.xml),
HBaseTimelineMetricsService 负责基于配置 初始化 Collector 的存储体系(Phoenix/HBase 表结构、聚合器、HA 等)。
我们上一节已讲完 AMSApplicationServer 的配置初始化职责。本节专注拆解 HBaseTimelineMetricsService。
# 二、初始化入口:二次 serviceInit
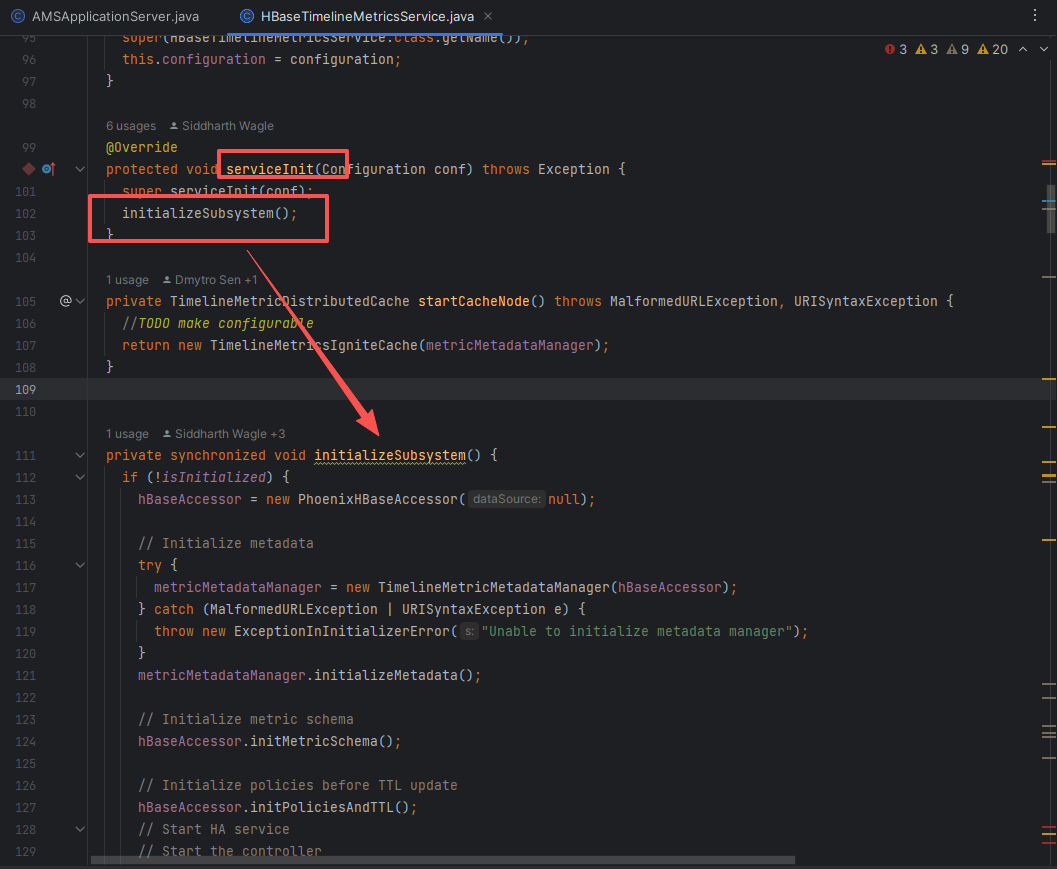
# 1、调用链定位
@Override
protected void serviceInit(Configuration conf) throws Exception {
metricConfiguration = TimelineMetricConfiguration.getInstance();
metricConfiguration.initialize();
timelineMetricStore = createTimelineMetricStore(conf);
addIfService(timelineMetricStore);
super.serviceInit(conf);
}
protected TimelineMetricStore createTimelineMetricStore(Configuration conf) {
LOG.info("Creating metrics store.");
return new HBaseTimelineMetricsService(metricConfiguration);
}
2
3
4
5
6
7
8
9
10
11
12
13
super.serviceInit(conf)会递归把所有的Service初始化
# 2、图示定位
笔记
这里等价于在 init 阶段再次进入一个“子系统初始化入口”,完成从 配置 → 存储 → 聚合 → 监控 的整套构建。
# 三、核心初始化流程:initializeSubsystem()
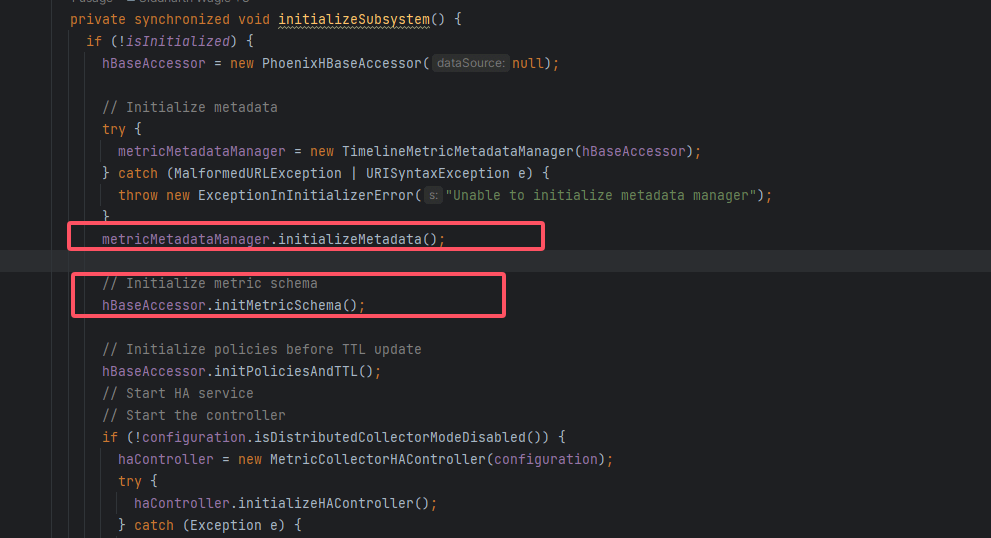
private synchronized void initializeSubsystem() {
if (!isInitialized) {
hBaseAccessor = new PhoenixHBaseAccessor(null);
// 1) Metadata 管理器与缓存
try {
metricMetadataManager = new TimelineMetricMetadataManager(hBaseAccessor);
} catch (MalformedURLException | URISyntaxException e) {
throw new ExceptionInInitializerError("Unable to initialize metadata manager");
}
metricMetadataManager.initializeMetadata();
// 2) Metric Schema(业务数据表)
hBaseAccessor.initMetricSchema();
// 3) 策略/TTL
hBaseAccessor.initPoliciesAndTTL();
// 4) 分布式 Collector 的 HA 控制器
if (!configuration.isDistributedCollectorModeDisabled()) {
haController = new MetricCollectorHAController(configuration);
try {
haController.initializeHAController();
} catch (Exception e) {
LOG.error(e);
throw new MetricsSystemInitializationException("Unable to initialize HA controller", e);
}
} else {
LOG.info("Distributed collector mode disabled");
}
// 5) 过滤器(白/黑名单)
TimelineMetricsFilter.initializeMetricFilter(configuration);
// 6) 读取 ams-site 配置
Configuration metricsConf = configuration.getMetricsConf();
// 7) Collector 侧内存聚合缓存(可选)
if (configuration.isCollectorInMemoryAggregationEnabled()) {
cache = startCacheNode();
}
// 8) 聚合器(Host/Cluster,秒/分/小时/天)
// …… 创建与调度各类聚合器(见下节)
// 9) Watcher(健康监控)
if (!configuration.isTimelineMetricsServiceWatcherDisabled()) {
int initDelay = configuration.getTimelineMetricsServiceWatcherInitDelay();
int delay = configuration.getTimelineMetricsServiceWatcherDelay();
watchdogExecutorService.scheduleWithFixedDelay(
new TimelineMetricStoreWatcher(this, configuration), initDelay, delay, TimeUnit.SECONDS);
}
containerMetricsDisabled = configuration.isContainerMetricsDisabled();
defaultInstanceId = configuration.getDefaultInstanceId();
isInitialized = true;
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
流程要点
1)Metadata:注册指标元数据与主机-实例映射; 2)Metric Schema:创建时序数据表与多粒度聚合表; 3)策略/TTL:设置数据留存策略; 4)HA 控制器:分布式 Collector 环境下的主备协同; 5)过滤器:白/黑名单控制指标入库; 6)内存聚合:Collector 端的 Cache 节点; 7)聚合器:Host/Cluster 多粒度定时汇总; 8)Watcher:周期性健康检查。
# 四、元数据层:Metadata 三张表
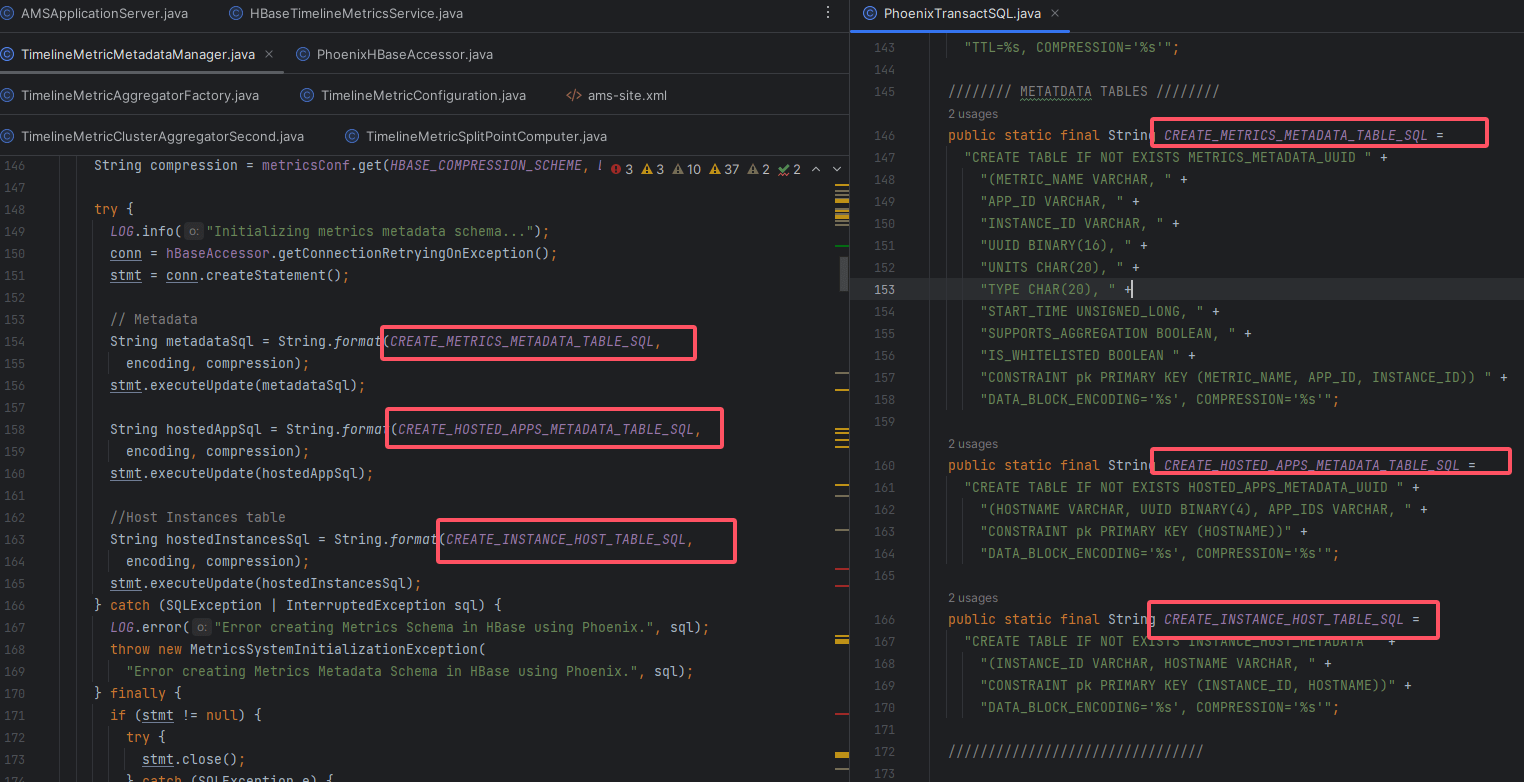
# 1、initializeMetadata()
metricMetadataManager.initializeMetadata();
源码位置:
ambari-metrics-timelineservice/src/main/java/org/apache/ambari/metrics/core/timeline/discovery/TimelineMetricMetadataManager.java
作用:创建并维护 指标字典与索引,提升查询效率、减少写入体积(UUID 化)并为路由/聚合提供附加信息。
# 2、建表 SQL
public static final String CREATE_METRICS_METADATA_TABLE_SQL =
"CREATE TABLE IF NOT EXISTS METRICS_METADATA_UUID " +
"(METRIC_NAME VARCHAR, " +
"APP_ID VARCHAR, " +
"INSTANCE_ID VARCHAR, " +
"UUID BINARY(16), " +
"UNITS CHAR(20), " +
"TYPE CHAR(20), " +
"START_TIME UNSIGNED_LONG, " +
"SUPPORTS_AGGREGATION BOOLEAN, " +
"IS_WHITELISTED BOOLEAN " +
"CONSTRAINT pk PRIMARY KEY (METRIC_NAME, APP_ID, INSTANCE_ID)) " +
"DATA_BLOCK_ENCODING='%s', COMPRESSION='%s'";
public static final String CREATE_HOSTED_APPS_METADATA_TABLE_SQL =
"CREATE TABLE IF NOT EXISTS HOSTED_APPS_METADATA_UUID " +
"(HOSTNAME VARCHAR, UUID BINARY(4), APP_IDS VARCHAR, " +
"CONSTRAINT pk PRIMARY KEY (HOSTNAME))" +
"DATA_BLOCK_ENCODING='%s', COMPRESSION='%s'";
public static final String CREATE_INSTANCE_HOST_TABLE_SQL =
"CREATE TABLE IF NOT EXISTS INSTANCE_HOST_METADATA " +
"(INSTANCE_ID VARCHAR, HOSTNAME VARCHAR, " +
"CONSTRAINT pk PRIMARY KEY (INSTANCE_ID, HOSTNAME))" +
"DATA_BLOCK_ENCODING='%s', COMPRESSION='%s'";
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 3、编码与压缩策略来源
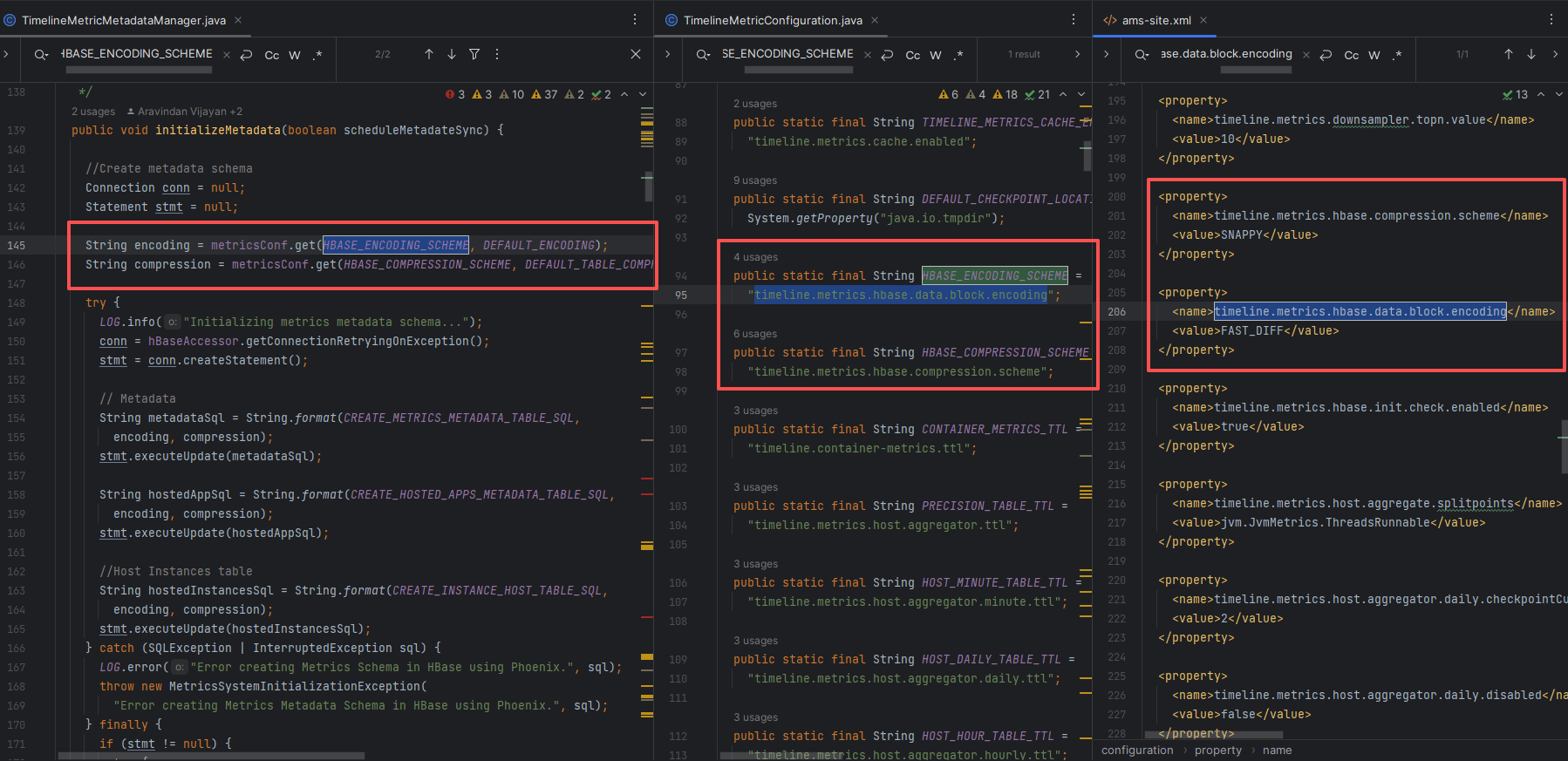
AMS 在建表时统一读取 ams-site.xml:
timeline.metrics.hbase.data.block.encoding→ 典型:FAST_DIFFtimeline.metrics.hbase.compression.scheme→ 典型:SNAPPY
常见坑位
- 未安装 native snappy:压缩失效或 CPU 飙高;
- 编码与旧 RegionServer 不兼容:表创建失败;
- TTL 设置不当:查询“有面板无数据”或磁盘爆量。
# 4、示意(固定策略)
CREATE TABLE IF NOT EXISTS METRICS_METADATA_UUID (...)
DATA_BLOCK_ENCODING='FAST_DIFF', COMPRESSION='SNAPPY';
CREATE TABLE IF NOT EXISTS HOSTED_APPS_METADATA_UUID (...)
DATA_BLOCK_ENCODING='FAST_DIFF', COMPRESSION='SNAPPY';
CREATE TABLE IF NOT EXISTS INSTANCE_HOST_METADATA (...)
DATA_BLOCK_ENCODING='FAST_DIFF', COMPRESSION='SNAPPY';
2
3
4
5
6
7
8
实战建议
- 元数据三表写入频次低、读取频次高,FAST_DIFF + SNAPPY 在读放大与磁盘占用之间较平衡;
- 若使用 HDD 存储,SNAPPY 压缩能显著降低 IO 压力;NVMe 环境下可视场景考虑 ZSTD。
# 五、业务数据层:Metric Schema(时序与聚合)
# 1、初始化入口
// Initialize metric schema
hBaseAccessor.initMetricSchema();
2
# 2、核心源码(摘录)
protected void initMetricSchema() {
Connection conn = null;
Statement stmt = null;
PreparedStatement pStmt = null;
TimelineMetricSplitPointComputer splitPointComputer =
new TimelineMetricSplitPointComputer(metricsConf, hbaseConf, metadataManagerInstance);
splitPointComputer.computeSplitPoints();
String encoding = metricsConf.get(HBASE_ENCODING_SCHEME, DEFAULT_ENCODING);
String compression = metricsConf.get(HBASE_COMPRESSION_SCHEME, DEFAULT_TABLE_COMPRESSION);
try {
conn = getConnectionRetryingOnException();
stmt = conn.createStatement();
// 1) Container Metrics
stmt.executeUpdate(String.format(CREATE_CONTAINER_METRICS_TABLE_SQL,
encoding, tableTTL.get(CONTAINER_METRICS_TABLE_NAME), compression));
// 2) Host 粒度:原始时序 + 分钟/小时/天聚合
String precisionSql = String.format(CREATE_METRICS_TABLE_SQL,
encoding, tableTTL.get(METRICS_RECORD_TABLE_NAME), compression);
pStmt = prepareCreateMetricsTableStatement(conn, precisionSql, splitPointComputer.getPrecisionSplitPoints());
pStmt.executeUpdate();
String hostMinuteAggSql = String.format(CREATE_METRICS_AGGREGATE_TABLE_SQL,
METRICS_AGGREGATE_MINUTE_TABLE_NAME, encoding,
tableTTL.get(METRICS_AGGREGATE_MINUTE_TABLE_NAME), compression);
pStmt = prepareCreateMetricsTableStatement(conn, hostMinuteAggSql, splitPointComputer.getHostAggregateSplitPoints());
pStmt.executeUpdate();
stmt.executeUpdate(String.format(CREATE_METRICS_AGGREGATE_TABLE_SQL,
METRICS_AGGREGATE_HOURLY_TABLE_NAME, encoding,
tableTTL.get(METRICS_AGGREGATE_HOURLY_TABLE_NAME), compression));
stmt.executeUpdate(String.format(CREATE_METRICS_AGGREGATE_TABLE_SQL,
METRICS_AGGREGATE_DAILY_TABLE_NAME, encoding,
tableTTL.get(METRICS_AGGREGATE_DAILY_TABLE_NAME), compression));
// 3) Cluster 粒度:秒/分/时/天聚合与分组聚合
String aggregateSql = String.format(CREATE_METRICS_CLUSTER_AGGREGATE_TABLE_SQL,
METRICS_CLUSTER_AGGREGATE_TABLE_NAME, encoding,
tableTTL.get(METRICS_CLUSTER_AGGREGATE_TABLE_NAME), compression);
pStmt = prepareCreateMetricsTableStatement(conn, aggregateSql, splitPointComputer.getClusterAggregateSplitPoints());
pStmt.executeUpdate();
stmt.executeUpdate(String.format(CREATE_METRICS_CLUSTER_AGGREGATE_GROUPED_TABLE_SQL,
METRICS_CLUSTER_AGGREGATE_MINUTE_TABLE_NAME, encoding,
tableTTL.get(METRICS_CLUSTER_AGGREGATE_MINUTE_TABLE_NAME), compression));
stmt.executeUpdate(String.format(CREATE_METRICS_CLUSTER_AGGREGATE_GROUPED_TABLE_SQL,
METRICS_CLUSTER_AGGREGATE_HOURLY_TABLE_NAME, encoding,
tableTTL.get(METRICS_CLUSTER_AGGREGATE_HOURLY_TABLE_NAME), compression));
stmt.executeUpdate(String.format(CREATE_METRICS_CLUSTER_AGGREGATE_GROUPED_TABLE_SQL,
METRICS_CLUSTER_AGGREGATE_DAILY_TABLE_NAME, encoding,
tableTTL.get(METRICS_CLUSTER_AGGREGATE_DAILY_TABLE_NAME), compression));
// 4) 瞬时表(可选):短期指标临时存储
String transientMetricPatterns = metricsConf.get(TRANSIENT_METRIC_PATTERNS, StringUtils.EMPTY);
if (StringUtils.isNotEmpty(transientMetricPatterns)) {
String transientSql = String.format(CREATE_TRANSIENT_METRICS_TABLE_SQL,
encoding, tableTTL.get(METRIC_TRANSIENT_TABLE_NAME), compression);
stmt.executeUpdate(transientSql);
}
conn.commit();
} catch (SQLException | InterruptedException sql) {
throw new MetricsSystemInitializationException("Error creating Metrics Schema in HBase using Phoenix.", sql);
} finally {
// 资源释放...
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
# 3、在hbase web ui 上看到的效果
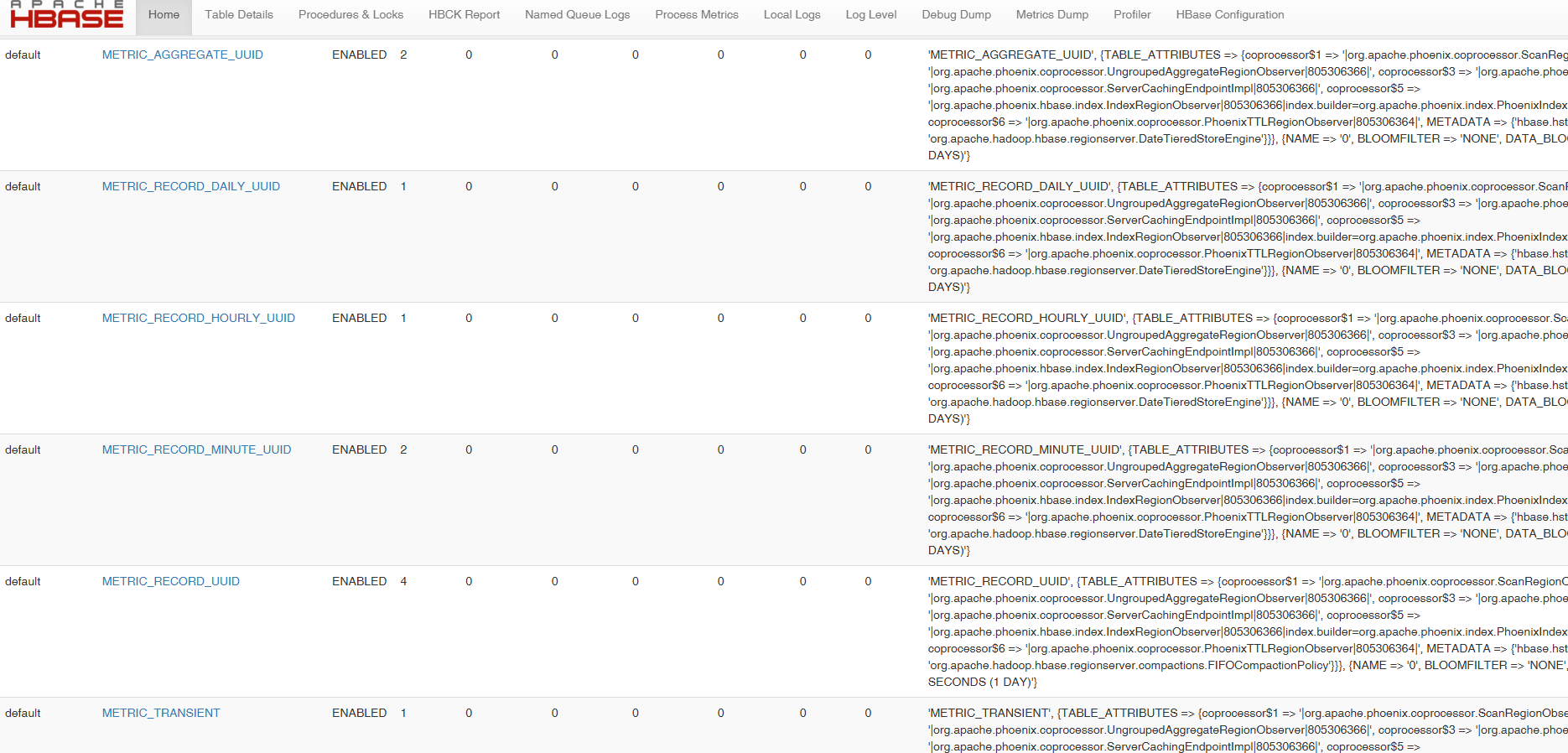
下一节预告
至于创建哪些表,以及表的解读,我们将在后续章节给大家补充! 下节我们将给大家拆解 AMSApplicationServer start() 过程。