 [/metrics] — 指标数据入库commitMetrics
[/metrics] — 指标数据入库commitMetrics
# 一、文章导读
你将获得
- commitMetrics 的完整入库路径与关键分支;
- Phoenix UPSERT 的占位符与字段一一对照表;
- calculateAggregates 的结果含义与实算示例;
- UUID(20B) 的来源与含义(含 host 维度);
- 批量提交、临时指标分流、常见异常与验证 SQL。
# 二、核心代码与上下文
public void commitMetrics(Collection<TimelineMetrics> timelineMetricsCollection) {
LOG.debug("Committing metrics to store");
Connection conn = null;
PreparedStatement metricRecordStmt = null;
List<TimelineMetric> transientMetrics = new ArrayList<>();
int rowCount = 0;
try {
conn = getConnection();
metricRecordStmt = conn.prepareStatement(String.format(
UPSERT_METRICS_SQL, METRICS_RECORD_TABLE_NAME));
for (TimelineMetrics timelineMetrics : timelineMetricsCollection) {
for (TimelineMetric metric : timelineMetrics.getMetrics()) {
if (metadataManagerInstance.isTransientMetric(metric.getMetricName(), metric.getAppId())) {
transientMetrics.add(metric);
continue;
}
metricRecordStmt.clearParameters();
if (LOG.isTraceEnabled()) {
LOG.trace("host: " + metric.getHostName() + ", " +
"metricName = " + metric.getMetricName() + ", " +
"values: " + metric.getMetricValues());
}
double[] aggregates = AggregatorUtils.calculateAggregates(
metric.getMetricValues());
if (aggregates[3] != 0.0) {
rowCount++;
byte[] uuid = metadataManagerInstance.getUuid(metric, true);
if (uuid == null) {
LOG.error("Error computing UUID for metric. Cannot write metrics : " + metric.toString());
continue;
}
metricRecordStmt.setBytes(1, uuid);
metricRecordStmt.setLong(2, metric.getStartTime());
metricRecordStmt.setDouble(3, aggregates[0]);
metricRecordStmt.setDouble(4, aggregates[1]);
metricRecordStmt.setDouble(5, aggregates[2]);
metricRecordStmt.setLong(6, (long) aggregates[3]);
String json = TimelineUtils.dumpTimelineRecordtoJSON(metric.getMetricValues());
metricRecordStmt.setString(7, json);
try {
int rows = metricRecordStmt.executeUpdate();
} catch (SQLException | NumberFormatException ex) {
LOG.warn("Failed on insert records to store : " + ex.getMessage());
LOG.warn("Metric that cannot be stored : [" + metric.getMetricName() + "," + metric.getAppId() + "]" +
metric.getMetricValues().toString());
continue;
}
if (rowCount >= PHOENIX_MAX_MUTATION_STATE_SIZE - 1) {
conn.commit();
rowCount = 0;
}
} else {
LOG.debug("Discarding empty metric record for : [" + metric.getMetricName() + "," +
metric.getAppId() + "," +
metric.getHostName() + "," +
metric.getInstanceId() + "]");
}
}
}
if (CollectionUtils.isNotEmpty(transientMetrics)) {
commitTransientMetrics(conn, transientMetrics);
}
// commit() blocked if HBase unavailable
conn.commit();
} catch (Exception exception){
exception.printStackTrace();
}
finally {
if (metricRecordStmt != null) {
try {
metricRecordStmt.close();
} catch (SQLException e) { }
}
if (conn != null) {
try {
conn.close();
} catch (SQLException sql) { }
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
UPSERT INTO METRIC_RECORD_UUID
(UUID, SERVER_TIME, METRIC_SUM, METRIC_MAX, METRIC_MIN, METRIC_COUNT, METRICS)
VALUES
(?, ?, ?, ?, ?, ?, ?);
1
2
3
4
2
3
4
{
"metrics": [
{
"instanceid": "",
"hostname": "dev1",
"metrics": {
"1758095682384": 7,
"1758095682484": 8,
"1758095682584": 9,
"1758095682684": 99,
"1758095682784": 10
},
"starttime": 1758095682384,
"appid": "amssmoketestfake",
"metricname": "ttbigdata.test"
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
// Make sure to add code blocks to your code group
语句构造入口(插入 SQL 的来源)
metricRecordStmt = conn.prepareStatement(String.format(
UPSERT_METRICS_SQL, METRICS_RECORD_TABLE_NAME));
1
2
2
其实为了构建插入 SQL,我们在下图已经标记了(往下看👇)。
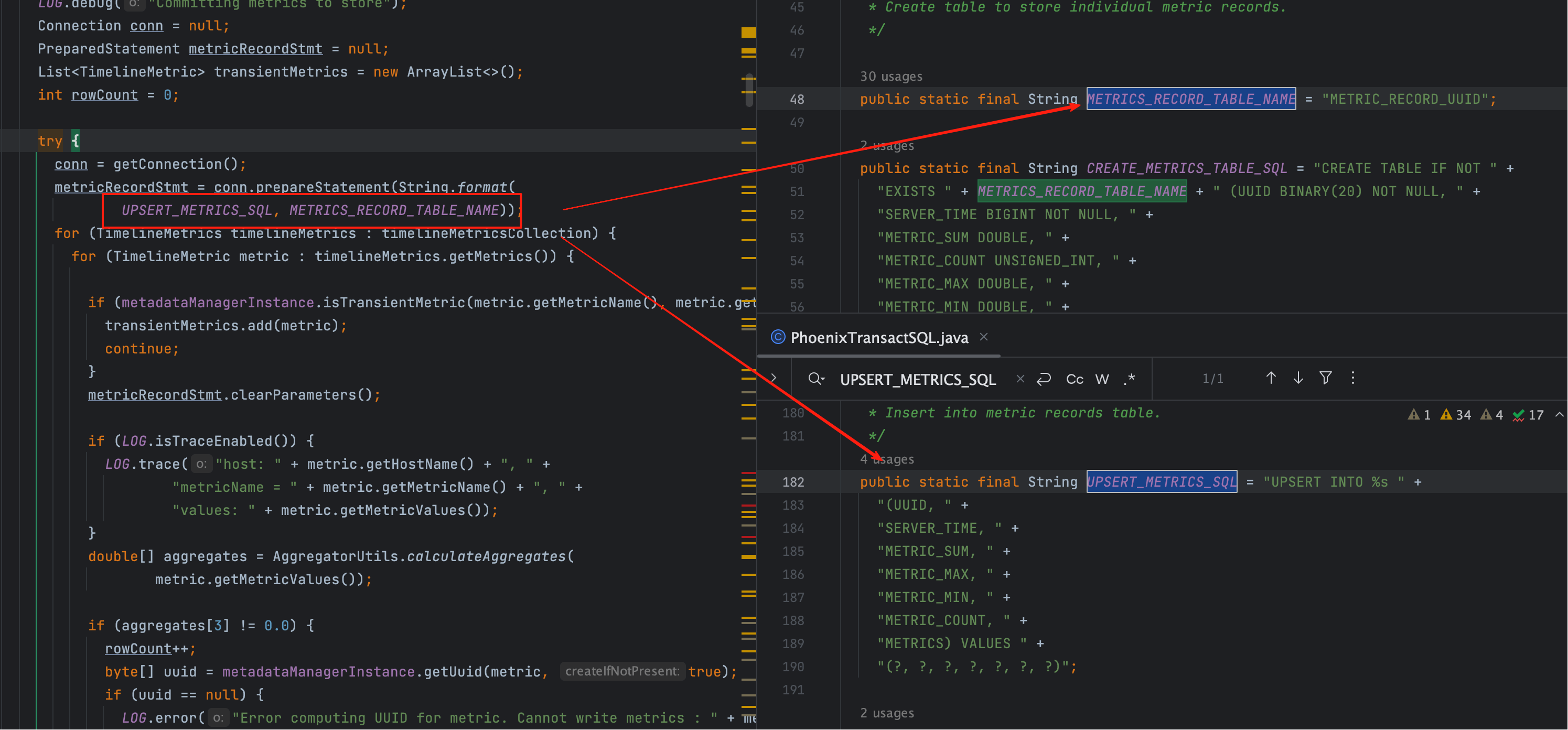
# 三、占位符与字段映射(对号入座)
| 占位符序号 | set 方法 | 映射字段 | 含义说明 |
|---|---|---|---|
| 1 | setBytes(1, uuid) | UUID | 20B 主键:metric 基础 UUID(16B)+ host 维度(4B) |
| 2 | setLong(2, startTime) | SERVER_TIME | 本批序列的起始时间(毫秒) |
| 3 | setDouble(3, aggregates[0]) | METRIC_SUM | 序列和(sum) |
| 4 | setDouble(4, aggregates[1]) | METRIC_MAX | 序列最大值(max) |
| 5 | setDouble(5, aggregates[2]) | METRIC_MIN | 序列最小值(min) |
| 6 | setLong(6, (long)aggregates[3]) | METRIC_COUNT | 参与统计的点位个数(count) |
| 7 | setString(7, json) | METRICS | 原始点位 JSON(时间戳 → 值) |
小结
7 个占位符与 7 个字段严格一一对应;写入前会按批量阈值进行 分段提交,避免 Phoenix mutation state 过大。
# 四、聚合计算 calculateAggregates(含实算)
public static double[] calculateAggregates(Map<Long, Double> metricValues) {
double[] values = new double[4];
double max = Double.MIN_VALUE;
double min = Double.MAX_VALUE;
double sum = 0.0;
int metricCount = 0;
if (metricValues != null && !metricValues.isEmpty()) {
for (Double value : metricValues.values()) {
if (value != null && !value.isNaN()) {
if (value > max) max = value;
if (value < min) min = value;
sum += value;
}
}
metricCount = metricValues.values().size();
}
values[0] = sum;
values[1] = max != Double.MIN_VALUE ? max : 0.0;
values[2] = min != Double.MAX_VALUE ? min : 0.0;
values[3] = metricCount;
return values;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
# 1、结果位含义
values[0]:sumvalues[1]:maxvalues[2]:minvalues[3]:count
# 2、基于示例 JSON 的实算
# 3、执行分支
if (aggregates[3] != 0.0) { /* 执行 UPSERT */ } else { /* 丢弃空记录 */ }
1
当 count 为 0 时,本条 metric 被丢弃,避免产生空数据行。
# 五、UUID 获取与 20B 结构
byte[] uuid = metadataManagerInstance.getUuid(metric, true);
1
# 1、为啥是 20B?
- 16B:metric 的基础 UUID(通常由 metricName/appId/instance 等维度哈希/映射而来);
- 4B:host 维度字节(开启
true即“带主机名”),用于区分同一指标在不同主机上的记录。
注意
- 若
uuid == null,当前 metric 直接跳过并打印错误日志; - 这一步依赖 Metadata 管理器(黑/白名单、Transient 标记等也在这一层生效)。
# 六、批量提交策略与异常处理
# 1、批量边界
if (rowCount >= PHOENIX_MAX_MUTATION_STATE_SIZE - 1) {
conn.commit();
rowCount = 0;
}
1
2
3
4
2
3
4
当单次事务内的 UPSERT 数量逼近 Phoenix mutation state 上限时,提前提交,避免内存暴涨与失败。
# 2、最终提交
conn.commit(); // 若 HBase 暂不可用,这里可能被阻塞
1
# 3、异常与重试
- 单条失败(
SQLException | NumberFormatException)→ WARN 并跳过,不影响后续写入; - finally 中关闭语句与连接,防止资源泄露。
# 七、Transient 指标分流(不走本表)
if (metadataManagerInstance.isTransientMetric(metric.getMetricName(), metric.getAppId())) {
transientMetrics.add(metric);
continue;
}
...
if (CollectionUtils.isNotEmpty(transientMetrics)) {
commitTransientMetrics(conn, transientMetrics);
}
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
# 1、含义
- Transient:瞬时/临时指标,默认不入
METRIC_RECORD_UUID; - 单独汇集后通过
commitTransientMetrics处理(实现由产品策略决定)。
# 2、与黑/白名单
提示
若开启白名单,仅匹配的指标允许持久化;黑名单可用于屏蔽噪声指标。这两者与 Transient 是互补策略:一个控制“是否允许入库”,一个控制“是否只做瞬时处理”。