 [/metrics] — condition生命周期
[/metrics] — condition生命周期
# 一、入口:Condition 的构建
在 metricNames 生命周期的文章中,我们已经提到会调用:
Condition condition = conditionBuilder.build();
1
# 一、为什么要关注 Condition(查询“意图”在这里定型)
在 /metrics 的整个调用链中,Condition 是查询意图的最终“固化形态”:它承载了 uuid 约束、metric
过滤、主机维度选择、时间窗口、精度、结果分组与上限、以及 TopN 配置等。Controller 侧前置的各种解析与校验,最后都会“落盘”到一个具体的
Condition 实例里,供后续 HBase/Phoenix 访问层据此拼装扫描范围与聚合策略。
提示
换句话说:你传了什么参数、想查什么粒度与范围、要不要做 TopN,最终都“写进了” Condition;后端只需读 Condition,就能确定使用哪张表、怎样扫、如何聚合。
# 二、入口回顾:三类 Condition 的构建分流
applyTopNCondition、parseMetricNamesToAggregationFunctions 等步骤完成后,构建在下列分支中收敛为三种 Condition:
public Condition build() {
if (topN == null) {
if (CollectionUtils.isEmpty(transientMetricNames)) {
return new DefaultCondition(
uuids, metricNames,
hostnames, appId, instanceId, startTime, endTime,
precision, limit, grouped);
} else {
return new TransientMetricCondition(
uuids, metricNames,
hostnames, appId, instanceId, startTime, endTime,
precision, limit, grouped, transientMetricNames);
}
} else {
return new TopNCondition(uuids, metricNames, hostnames, appId, instanceId,
startTime, endTime, precision, limit, grouped, topN, topNFunction, isBottomN);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
# 三、Condition 持有的关键字段(生命周期“装配清单”)
# 1、核心过滤与范围
uuids:基于 metricName/appId/instanceId(及 host 相关字节)映射得到的主键片段;metricNames、hostnames、appId、instanceId:语义过滤;startTime、endTime:时间窗口(毫秒级/秒级视实现);precision:精度(minute/hour/day…),影响 AGGREGATE 系列分表选择;grouped:是否对多序列进行分组聚合;limit:返回条数/点位上限(防止过量扫描);
# 2、TopN 扩展(仅 TopNCondition)
topN:N 的具体值;topNFunction:排序依据(如sum/avg/max/min等);isBottomN:是否反向(取最小 N)。
# 3、Transient 扩展(仅 TransientMetricCondition)
transientMetricNames:临时性指标集合,走瞬时路径。
提示
生命周期理解:Controller → 解析/校验 → 计算 uuids/函数映射 → build() 固化为 Condition → 传入访问层执行。
详解可参考
# 四、基于 hostnames 的“表级”分流(两条主干路径)
源码中的分流判断如下图所示(你的示意图):
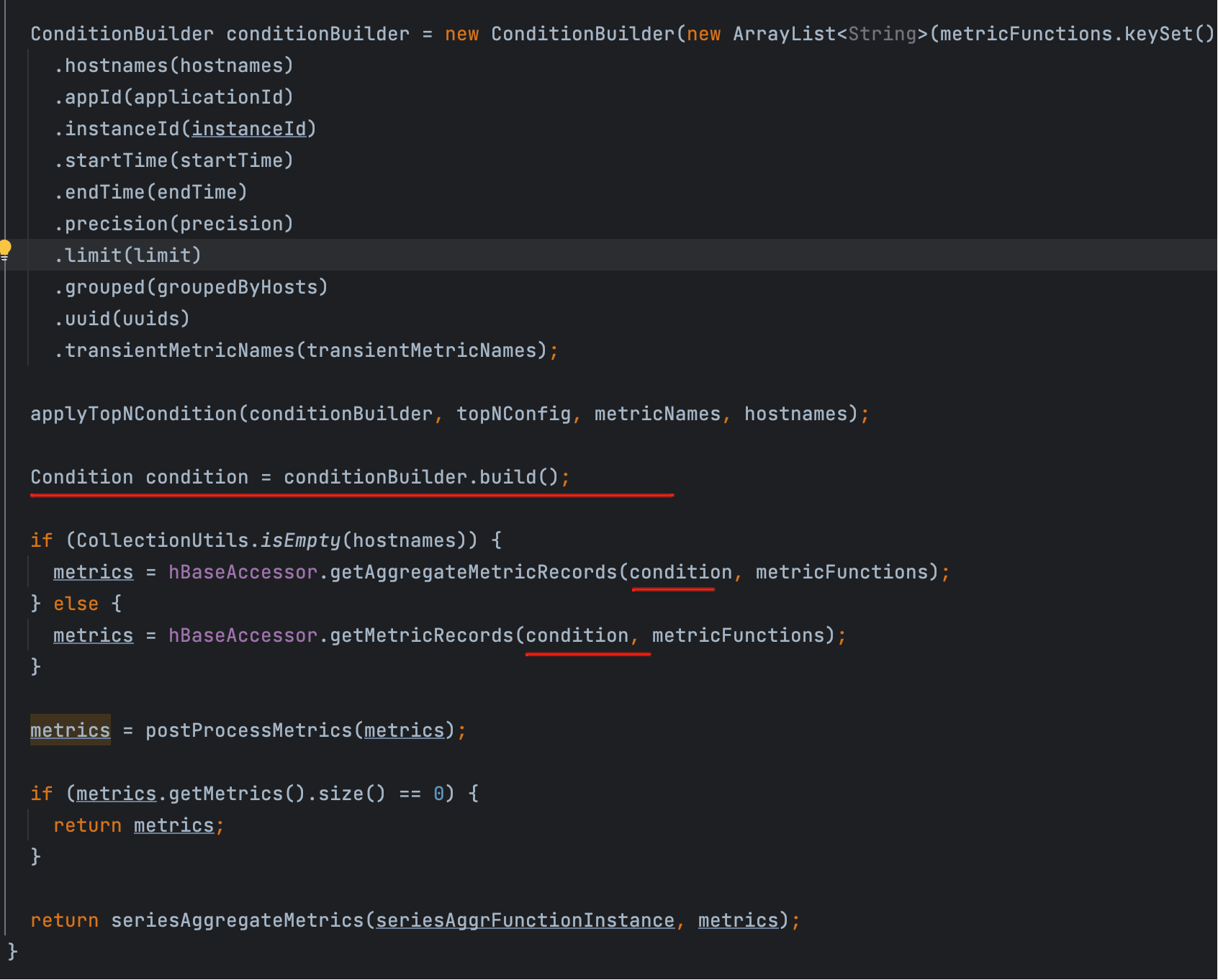
以及对应代码:
if (CollectionUtils.isEmpty(hostnames)) {
metrics = hBaseAccessor.getAggregateMetricRecords(condition, metricFunctions);
} else {
metrics = hBaseAccessor.getMetricRecords(condition, metricFunctions);
}
1
2
3
4
5
2
3
4
5
# 1、有 hostnames:走 METRIC_RECORD_* 系列
- 典型表:
METRIC_RECORD_UUID - RowKey 语义:在指标基础上增加主机 4B 维度字节(你的前文已有论证)
- 适合:主机维度的明细曲线、多主机并列对比、细粒度诊断
# 2、无 hostnames:走 METRIC_AGGREGATE_* 系列
- 典型表:
METRIC_AGGREGATE_UUID(以及 minute/hour/day 粒度分表) - 由
precision决定使用哪张聚合表 - 适合:跨主机/实例的汇总趋势、长时间窗口的轻量级查询