 [监控表] — Uuid 16 位构成全解析murmur3
[监控表] — Uuid 16 位构成全解析murmur3
# 一、背景与问题提出
在 Ambari-Metrics 中,所有监控指标最终都会存储在 HBase 表中,而 RowKey 的设计直接决定了性能与可扩展性。
这里的关键就是 Metric UUID —— 一个固定长度的 16 字节哈希值。
Metric UUID 的作用:
- 确保 全局唯一性,避免指标冲突;
- 作为 Phoenix RowKey,影响 Region 切分和查询效率;
- 提供 稳定标识,即便 metricName 较长或存在相似性,也能快速区分。
因此,理解 UUID 的生成机制,是掌握 Ambari-Metrics 数据模型的第一步。
# 二、调用链回溯
Collector 在初始化阶段,会调用 computeSplitPoints,从而触发 UUID 的生成逻辑。
timelineMetricMetadataManager.getUuid(
new TimelineClusterMetric(metricAppService.metricName,
metricAppService.appId,
null, -1),
true);
2
3
4
5
这里传入的对象是 TimelineClusterMetric,包含三个关键字段:
| 字段 | 作用说明 |
|---|---|
| metricName | 指标名,如 cpu_user |
| appId | 应用 ID,如 datanode |
| instanceId | 实例 ID(可选,当前为 null) |
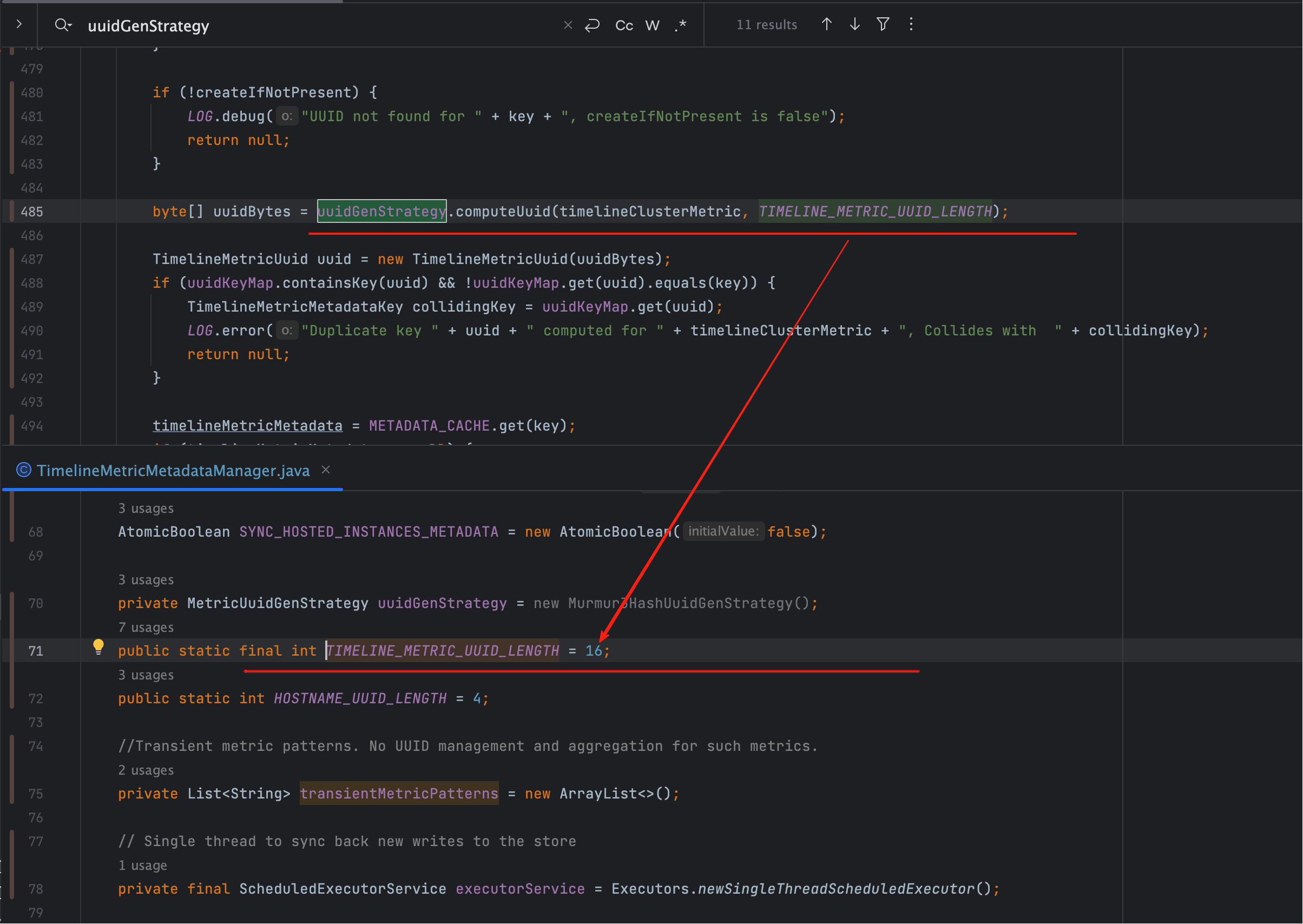
接下来进入 uuidGenStrategy.computeUuid():
uuidGenStrategy.computeUuid(timelineClusterMetric, TIMELINE_METRIC_UUID_LENGTH);
笔记
这里的 TIMELINE_METRIC_UUID_LENGTH = 16,意味着 UUID 始终是 16 字节。
# 三、UUID 策略模式
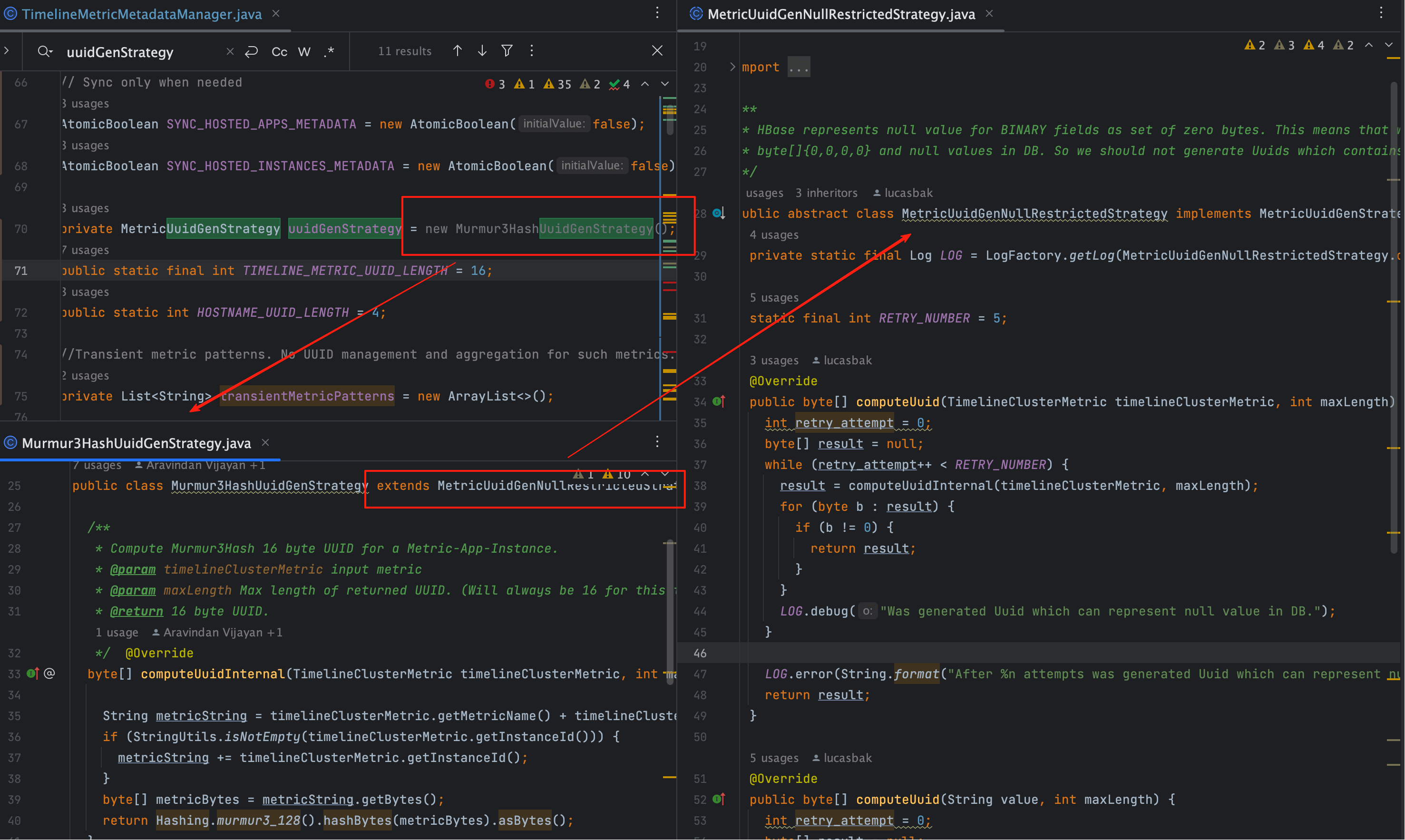
在 Ambari-Metrics 源码中,uuidGenStrategy 实际上是 Murmur3HashUuidGenStrategy 的实例:
new Murmur3HashUuidGenStrategy();
其继承关系如下:
- 父类:
MetricUuidGenNullRestrictedStrategy负责通用逻辑与“全零校验” - 子类:
Murmur3HashUuidGenStrategy实现具体的computeUuidInternal
调用顺序:
computeUuid() → 父类逻辑 → 子类 computeUuidInternal()
# 四、NullRestricted 策略设计
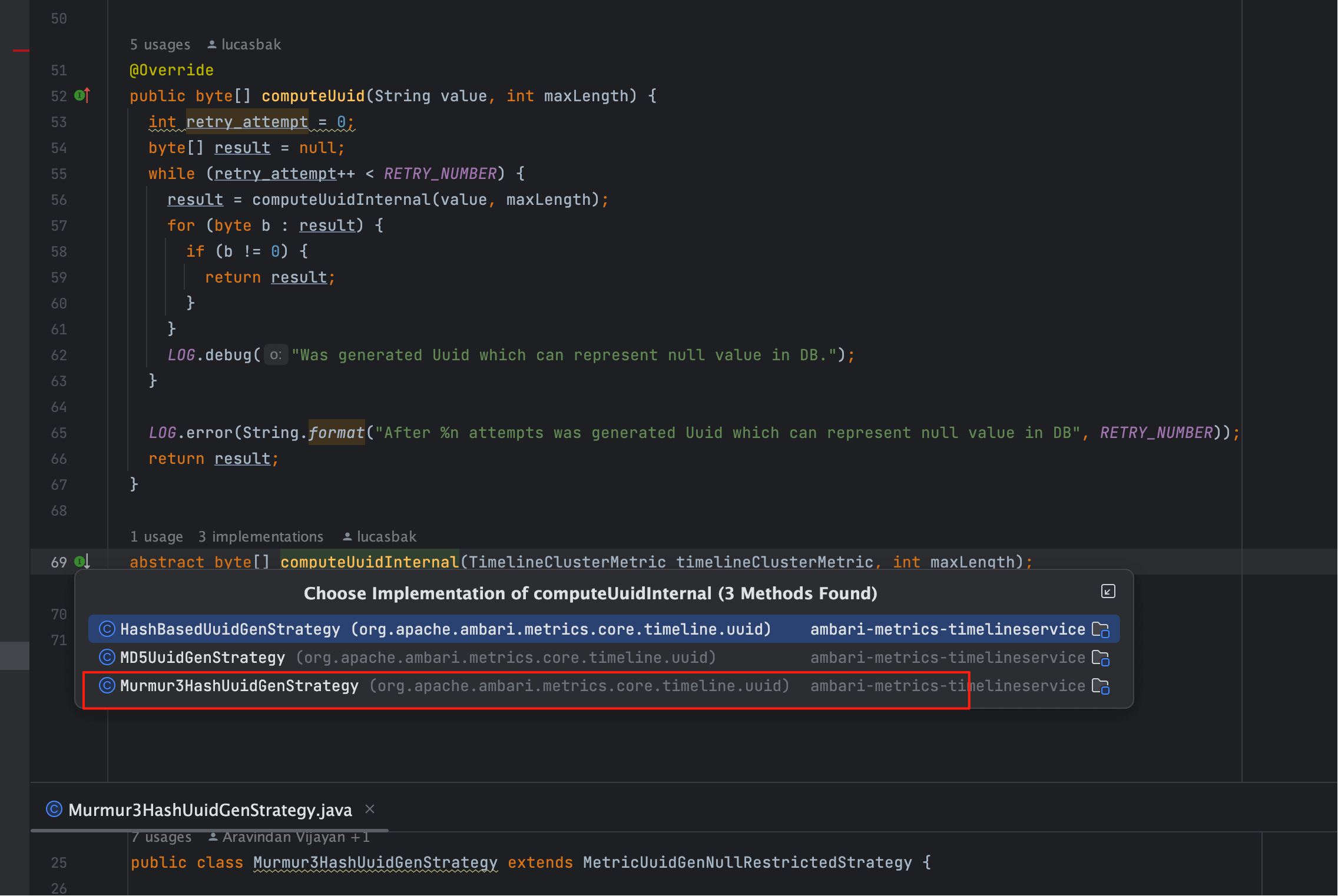
父类 MetricUuidGenNullRestrictedStrategy 的职责:
- 多次尝试生成(默认 5 次),避免出现全 0 UUID;
- 规避 HBase 陷阱:HBase 将全 0 视作 null,可能导致查询异常;
- 返回有效值:只要生成结果包含非零字节,即认为合法。
提示
这一步保证了 UUID 的可用性与稳定性,相当于给 Murmur3 的输出加了保险。
# 五、Murmur3_128 实现细节
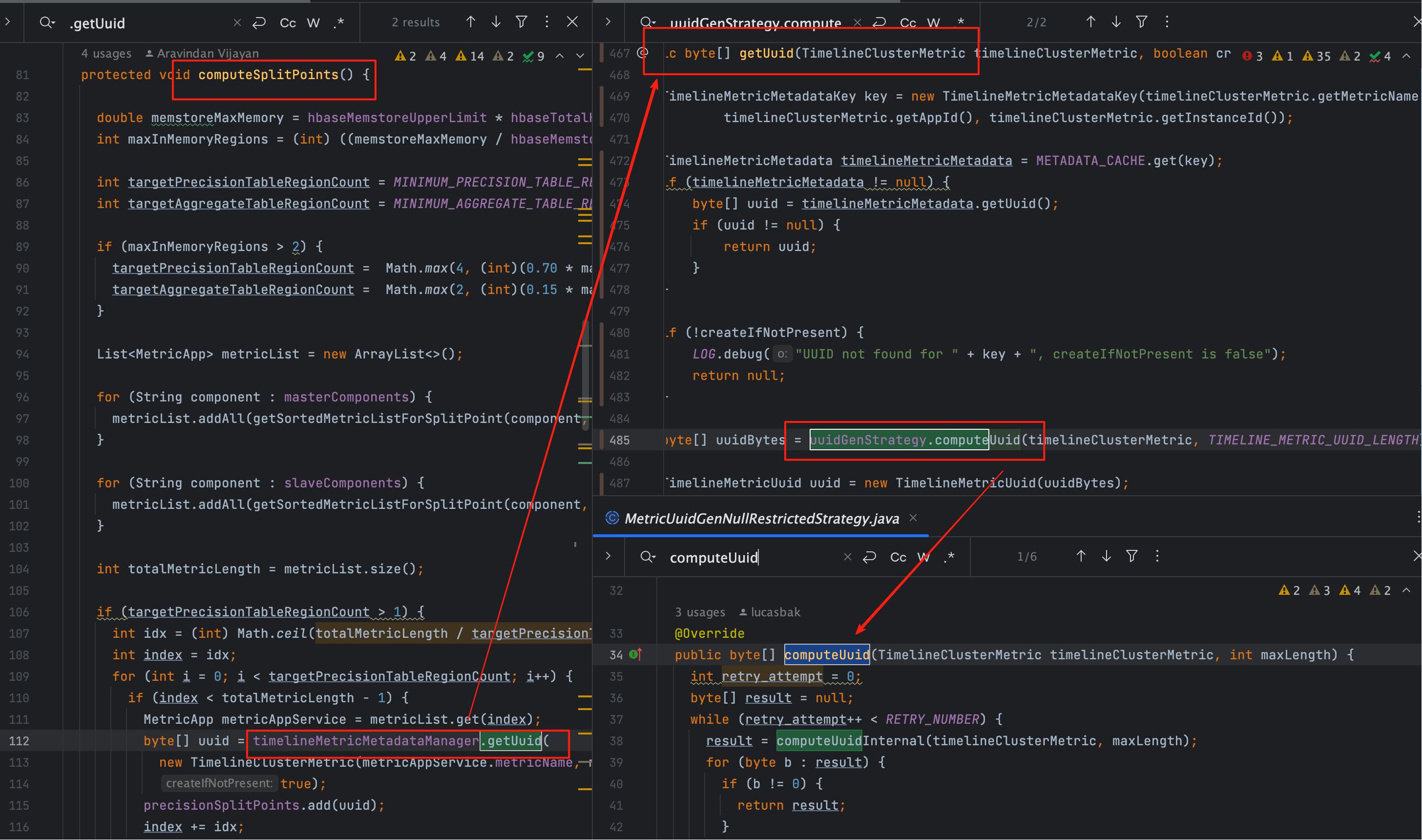
子类 Murmur3HashUuidGenStrategy 的核心逻辑如下:
String metricString = timelineClusterMetric.getMetricName()
+ timelineClusterMetric.getAppId();
if (StringUtils.isNotEmpty(timelineClusterMetric.getInstanceId())) {
metricString += timelineClusterMetric.getInstanceId();
}
byte[] metricBytes = metricString.getBytes();
return Hashing.murmur3_128().hashBytes(metricBytes).asBytes();
2
3
4
5
6
7
关键点总结:
| 步骤 | 说明 |
|---|---|
| 字符串拼接 | 按顺序拼接 metricName + appId + instanceId(可选) |
| 字节转换 | 将拼接后的字符串转为字节数组 |
| 哈希计算 | 调用 Murmur3_128,输出 16 字节结果 |
| 返回结果 | 最终作为 Phoenix RowKey 存入 HBase |
# Demo 示例
我们以一个实际的指标作为例子:
- metricName =
cpu_user - appId =
datanode - instanceId =
dn1.example.com
拼接后的字符串为:
cpu_userdatanodedn1.example.com
调用 Murmur3_128 计算后,得到一个 16 字节 UUID:
import com.google.common.hash.Hashing;
public class MetricUuidDemo {
public static void main(String[] args) {
String metricString = "cpu_user" + "datanode" + "dn1.example.com";
byte[] uuidBytes = Hashing.murmur3_128().hashBytes(metricString.getBytes()).asBytes();
// 输出为十六进制字符串
StringBuilder sb = new StringBuilder();
for (byte b : uuidBytes) {
sb.append(String.format("%02x", b));
}
System.out.println("Metric UUID (hex) = " + sb.toString());
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
运行结果示例:
Metric UUID (hex) = 9f7a1c2b6e084d5a9b27f8c8c97d6a42
提示
这个 32 位十六进制字符串(16 字节)就是 最终的 Metric UUID, 它会被直接作为 Phoenix RowKey 写入 HBase 表中。
# 六、结构解读与意义
最终生成的 16 字节 UUID 可以抽象为:
[Murmur3_128 hash(metricName + appId + instanceId)]
这种设计带来的好处:
- 紧凑:统一长度 16 字节,节省存储空间;
- 高效:哈希均匀分布,避免热点 Region;
- 灵活:通过 instanceId 进一步细分相同 metricName 的不同实例。
| 维度 | 示例值 | 在 UUID 中的作用 |
|---|---|---|
| metricName | cpu_user | 指标维度,保证指标级别唯一性 |
| appId | datanode | 应用维度,区分不同组件 |
| instanceId | dn1.example.com | 实例维度,区分同类应用下的不同节点 |
# 七、实践意义
为什么要花这么大力气来理解这 16 个字节?
- 表设计优化:Region 切分策略往往依赖 UUID 分布,理解其规律可指导 split key 的选取;
- 查询性能调优:Phoenix 二级索引构建时,RowKey 的哈希均匀性直接决定 scan 的代价;
- 扩展与排错:当出现 UUID 冲突或全零异常时,能快速定位到 MetricUuidGen 策略类。