 [/metrics] — getMetricRecords精讲
[/metrics] — getMetricRecords精讲
# 一、方法入口与执行框架
源码如下:
public TimelineMetrics getMetricRecords(
final Condition condition, Multimap<String, List<Function>> metricFunctions)
throws SQLException, IOException {
validateConditionIsNotEmpty(condition);
Connection conn = getConnection();
PreparedStatement stmt = null;
ResultSet rs = null;
TimelineMetrics metrics = new TimelineMetrics();
try {
// get latest
if (condition.isPointInTime()){
getLatestMetricRecords(condition, conn, metrics);
} else {
if (condition.getEndTime() >= condition.getStartTime()) {
if (CollectionUtils.isNotEmpty(condition.getUuids())) {
stmt = PhoenixTransactSQL.prepareGetMetricsSqlStmt(conn, condition);
rs = stmt.executeQuery();
while (rs.next()) {
appendMetricFromResultSet(metrics, condition, metricFunctions, rs);
}
}
if (CollectionUtils.isNotEmpty(condition.getTransientMetricNames())) {
stmt = PhoenixTransactSQL.prepareTransientMetricsSqlStmt(conn, condition);
if (stmt != null) {
rs = stmt.executeQuery();
while (rs.next()) {
TransientMetricReadHelper.appendMetricFromResultSet(metrics, condition, metricFunctions, rs);
}
}
}
} else {
LOG.warn("Skipping metrics query because endTime < startTime");
}
}
} catch (PhoenixIOException pioe) {
// 针对 hash join cache 过期的 fallback
} catch (RuntimeException ex) {
// 针对 TimeRange 异常的兜底
} finally {
closeQuietly(rs, stmt, conn);
}
LOG.debug("Metrics records size: " + metrics.getMetrics().size());
return metrics;
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
执行分支:
condition.isPointInTime()→ 走getLatestMetricRecords(但实际不会触发,因为时间必须带上)否则进入常规 SQL 路径:
- UUID 非空 →
prepareGetMetricsSqlStmt - transient 指标 →
prepareTransientMetricsSqlStmt
- UUID 非空 →
# 二、getLatestMetricRecords:点查询逻辑
尽管不会在 REST 请求中触发,这里依然保留逻辑,方便内部调用。
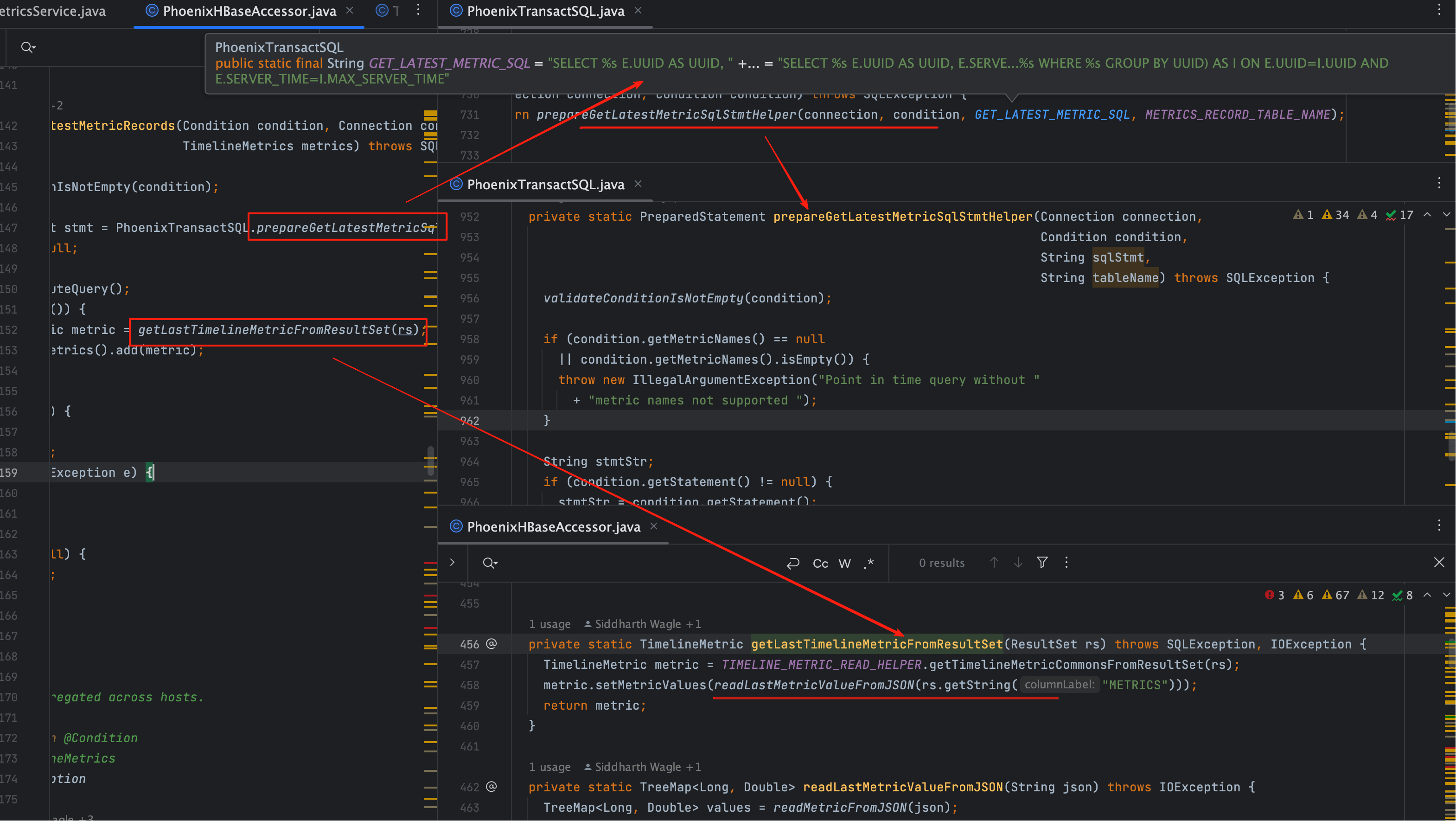
对应 SQL:
SELECT E.UUID, E.SERVER_TIME, E.METRIC_SUM, E.METRIC_MAX, E.METRIC_MIN,
E.METRIC_COUNT, E.METRICS
FROM METRIC_RECORD_UUID E
INNER JOIN (
SELECT UUID, MAX(SERVER_TIME) AS MAX_SERVER_TIME
FROM METRIC_RECORD_UUID
GROUP BY UUID
) I
ON E.UUID = I.UUID
AND E.SERVER_TIME = I.MAX_SERVER_TIME;
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
它的作用是:为每个 UUID 取出 最新一条监控数据。
由于 UUID 是二进制字段,在外部 SQL 工具里很难直接传参:
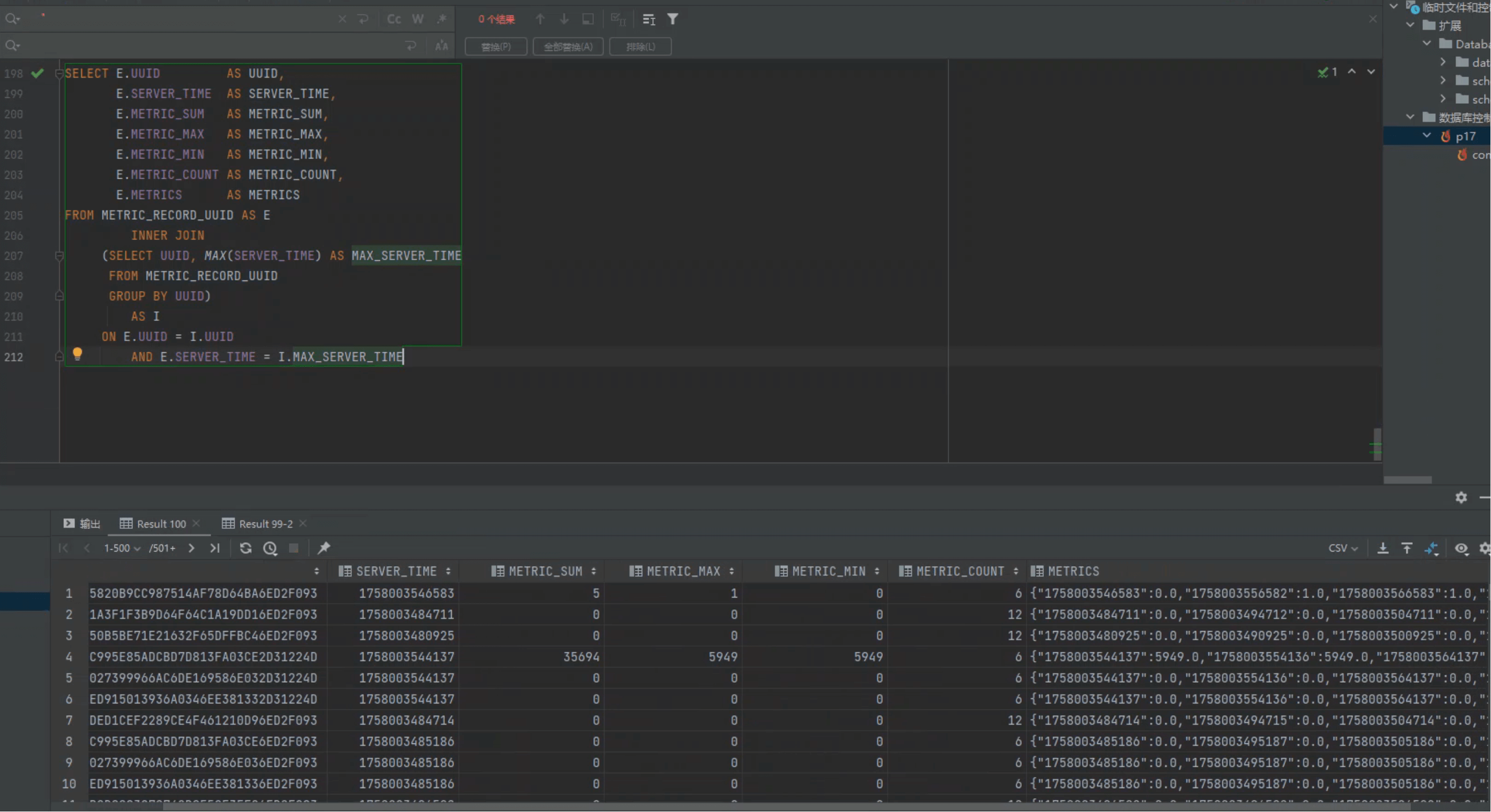
返回值示例:
{
"1758003546583": 0.0,
"1758003556582": 1.0,
"1758003566583": 1.0,
"1758003576582": 1.0
}
1
2
3
4
5
6
2
3
4
5
6
# 三、prepareGetMetricsSqlStmt:SQL 拼装逻辑
常规查询走 PhoenixTransactSQL.prepareGetMetricsSqlStmt。
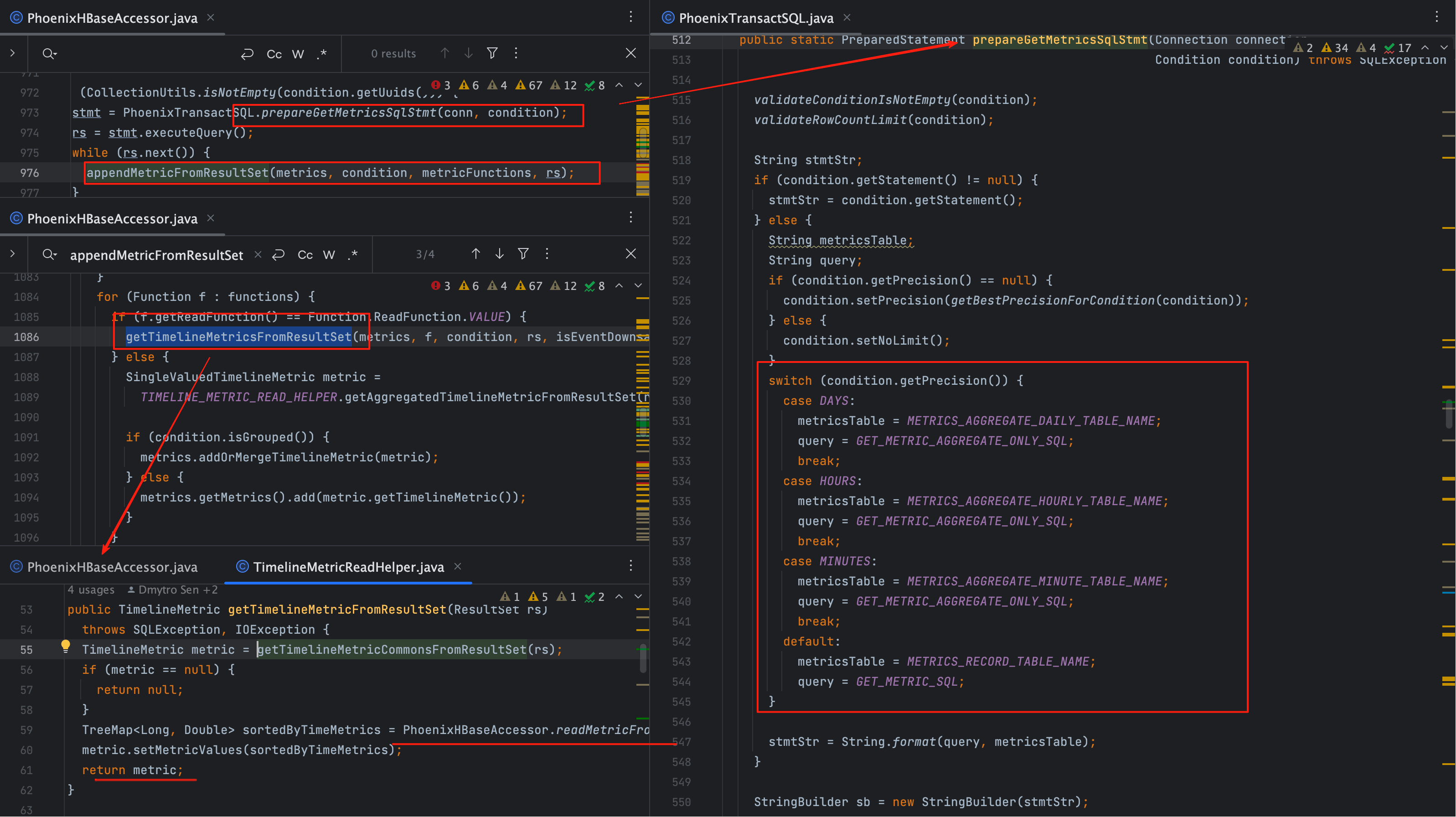
这里根据请求中的精度(precision)决定查询表:
| 精度 | 表名 | 特殊字段 |
|---|---|---|
| 秒级 | METRIC_RECORD_UUID | METRICS JSON |
| 分级 | METRIC_RECORD_MINUTE_UUID | 聚合值列 |
| 时级 | METRIC_RECORD_HOURLY_UUID | 聚合值列 |
| 天级 | METRIC_RECORD_DAILY_UUID | 聚合值列 |
差异点
秒表多了一个 METRICS JSON 字段,用于保存原始时序。
分钟、小时、天表只保存聚合值(SUM、AVG、MAX、MIN、COUNT)。
# 四、appendMetricFromResultSet:结果拼装
根据 function 的不同,分为两条路径:
if (f.getReadFunction() == Function.ReadFunction.VALUE) {
getTimelineMetricsFromResultSet(metrics, f, condition, rs, isEventDownsampledMetric(metricName));
} else {
SingleValuedTimelineMetric metric =
TIMELINE_METRIC_READ_HELPER.getAggregatedTimelineMetricFromResultSet(rs, f, isEventDownsampledMetric(metricName));
if (condition.isGrouped()) {
metrics.addOrMergeTimelineMetric(metric);
} else {
metrics.getMetrics().add(metric.getTimelineMetric());
}
}
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
- VALUE → 原始值查询,走
getTimelineMetricsFromResultSet,从秒表 JSON 中还原时序 - AVG/SUM/MIN/MAX → 聚合值查询,走
getAggregatedTimelineMetricFromResultSet
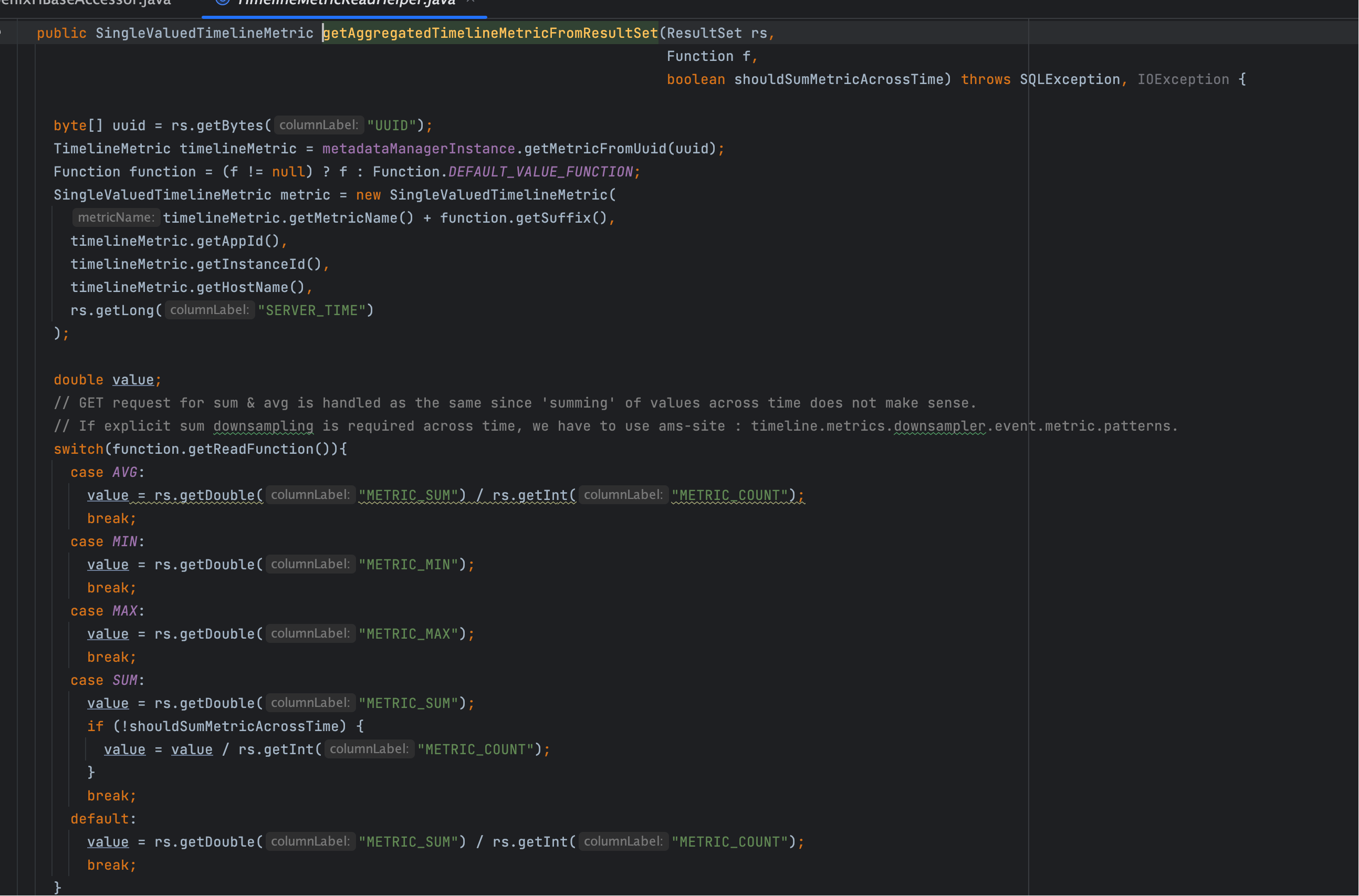
# 五、getTimelineMetricsFromResultSet:秒表特殊逻辑
private void getTimelineMetricsFromResultSet(TimelineMetrics metrics, Function f,
Condition condition, ResultSet rs, boolean shouldSumAcrossTime)
throws SQLException, IOException {
if (condition.getPrecision().equals(Precision.SECONDS)) {
TimelineMetric metric = TIMELINE_METRIC_READ_HELPER.getTimelineMetricFromResultSet(rs);
if (metric == null) return;
if (f != null && f.getSuffix() != null) {
metric.setMetricName(metric.getMetricName() + f.getSuffix());
}
if (condition.isGrouped()) {
metrics.addOrMergeTimelineMetric(metric);
} else {
metrics.getMetrics().add(metric);
}
} else {
SingleValuedTimelineMetric metric =
TIMELINE_METRIC_READ_HELPER.getAggregatedTimelineMetricFromResultSet(rs, f, shouldSumAcrossTime);
if (condition.isGrouped()) {
metrics.addOrMergeTimelineMetric(metric);
} else {
metrics.getMetrics().add(metric.getTimelineMetric());
}
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
- 秒表精度:直接取
METRICSJSON 展开为时间序列 - 非秒表精度:取聚合值列,返回单点数据
# 六、秒表 vs 聚合表差异
| 表名 | 字段 | 说明 |
|---|---|---|
| METRIC_RECORD_UUID | SERVER_TIME, METRICS(JSON) | 保存完整时序数据,含所有采样点 |
| METRIC_RECORD_MINUTE_UUID | METRIC_SUM, METRIC_MAX... | 每分钟聚合值 |
| METRIC_RECORD_HOURLY_UUID | 同上 | 每小时聚合值 |
| METRIC_RECORD_DAILY_UUID | 同上 | 每天聚合值 |
秒表查询结果(取自 JSON):
非秒表查询结果(取自聚合列):直接返回单值或少量聚合点。
# 七、调用链路梳理
/metrics
→ HBaseAccessor.getMetricRecords
→ PhoenixTransactSQL.prepareGetMetricsSqlStmt
→ METRIC_RECORD_* 表
→ appendMetricFromResultSet
├─ getTimelineMetricsFromResultSet (秒表 JSON)
└─ getAggregatedTimelineMetricFromResultSet (聚合表)
1
2
3
4
5
6
7
2
3
4
5
6
7