 快速创建一个简单demo
快速创建一个简单demo
# 一、背景说明
在大数据集群中,Ambari-Metrics Service (AMS) 提供了集群运行时的指标采集功能。
然而 Ambari 自带的 ambari-metrics-datasource 插件在 Grafana 9.x 之后已经不再适配,这时我们通常会使用 Infinity 插件
作为替代。
本文目标
通过 Infinity 插件构建一个最简单的 CPU 核数监控 Demo:
- 调用 AMS 的 REST API;
- 使用 Infinity 插件解析 JSON 数据;
- 在 Grafana 面板中绘制时序曲线。
# 二、配置 Data Source URL
进入 Grafana → Configuration → Data Sources → Add data source,选择 Infinity 插件。
在配置页面中,我们需要填写 AMS 提供的 REST URL。
通常 AMS Collector 默认运行在 http://<hostname>:6188 上,后面拼接 /ws/v1/timeline/metrics 路径即可。
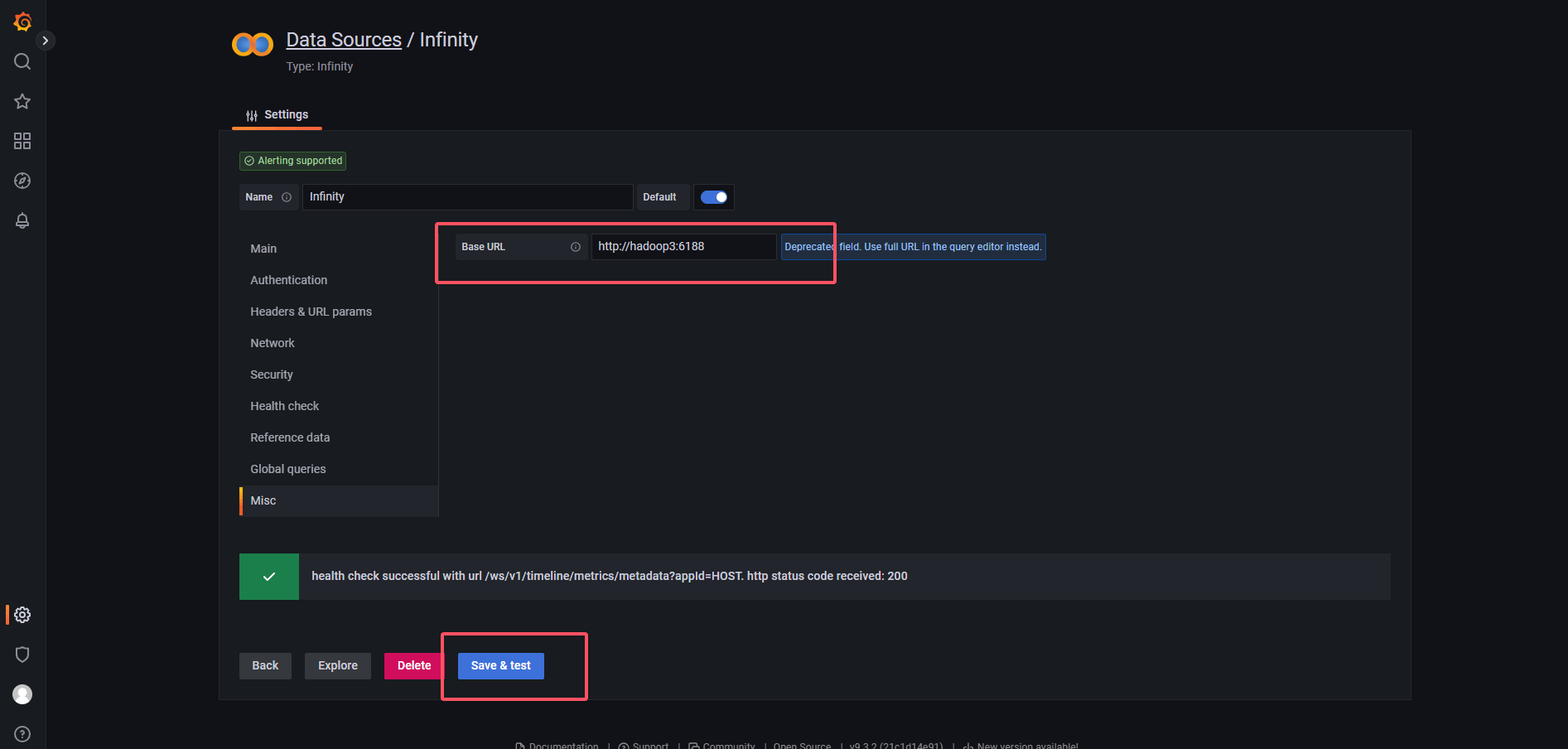
图:在 Infinity Data Source 中填写 Ambari-Metrics API URL
说明
如果不确定 Collector 的 IP,可以:
- 在 Ambari WebUI 中查看 Metrics Collector 服务所在节点;
- 登录该节点,确认 6188 端口是否监听。
# 三、新建 Dashboard 与 Panel
在配置好 Data Source 之后,我们需要新建一个 Dashboard,并在其中添加一个 Panel,用来展示 CPU 核数指标。
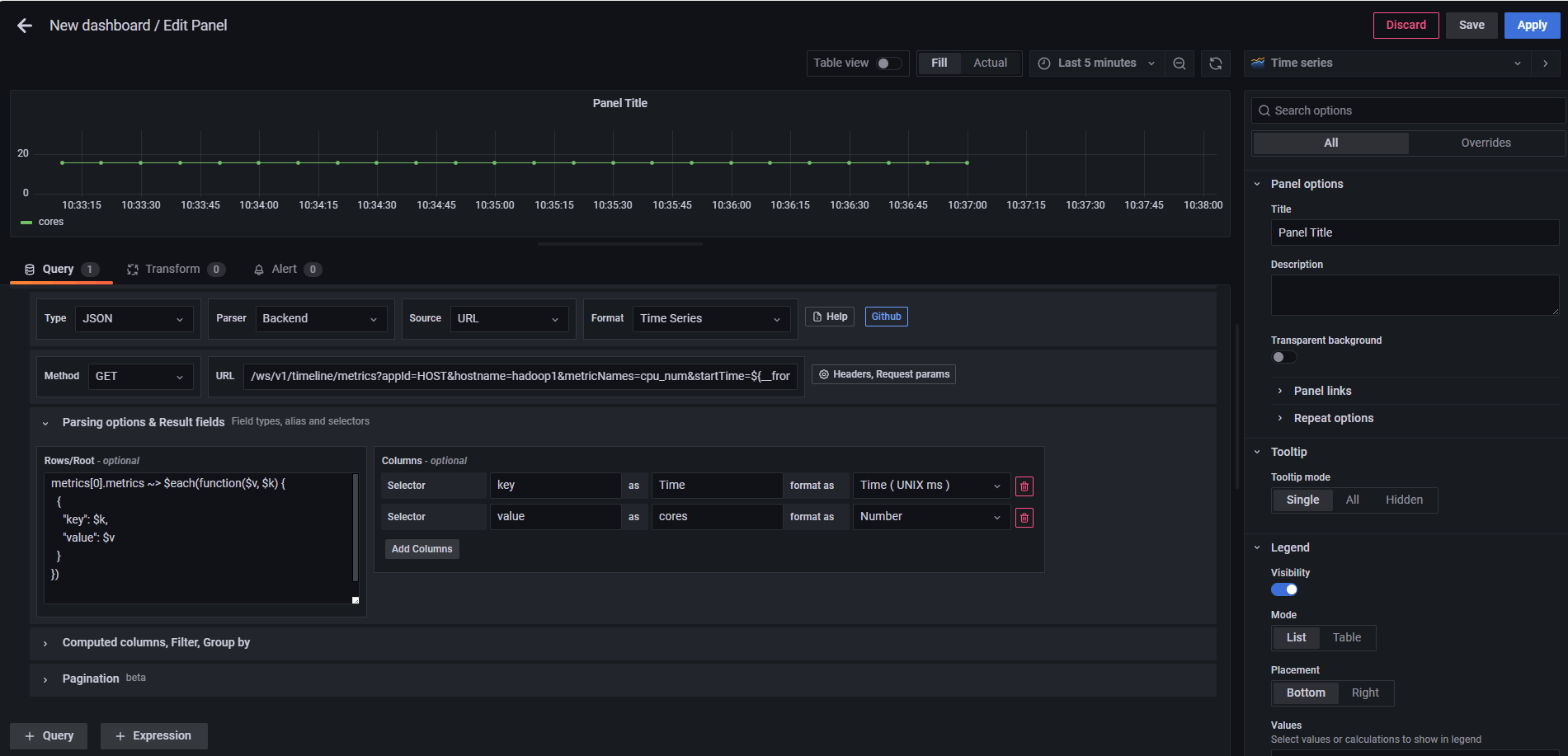 图:在 Dashboard 中创建 Panel,并选择 Infinity 数据源
图:在 Dashboard 中创建 Panel,并选择 Infinity 数据源
Step 1
进入 Dashboard 页面,点击 Add panel,并在 Data Source 中选择 Infinity。
Step 2
在 Panel 编辑界面:
- 设置 Type →
JSON - 选择 Parser →
Backend(推荐使用后端解析,能够减少前端处理 JSON 的压力,更适合大规模数据场景)
Step 3
继续配置:
- Source →
URL(通过 HTTP API 获取数据) - Format →
Time Series(将结果解析为时序数据,才能在 Grafana 中绘制曲线图)
Step 4
最后填写 URL 示例:
/ws/v1/timeline/metrics?appId=HOST&hostname=hadoop1&metricNames=cpu_num&startTime=${__from}&endTime=${__to}
这里的 ${__from} 和 ${__to} 是 Grafana 内置的时间变量,会在运行时自动替换成查询时间范围的开始和结束时间。
# 四、配置数据解析规则
Infinity 插件需要通过 Rows + Columns 把 JSON 转换成 Grafana 能理解的结构。
# 1. Rows 配置
metrics[0].metrics ~> $each(function($v, $k) {
{
"key": $k,
"value": $v
}
})
2
3
4
5
6
- 作用:将
metrics[0].metrics对象展开为[{key: 时间戳, value: 数值}, ...]。 $each函数把 JSON 对象的键值对转为数组,便于后续映射。
# 2. Columns 配置
- key → time(类型:timestamp_epoch)
- value → 指标值(类型:number)
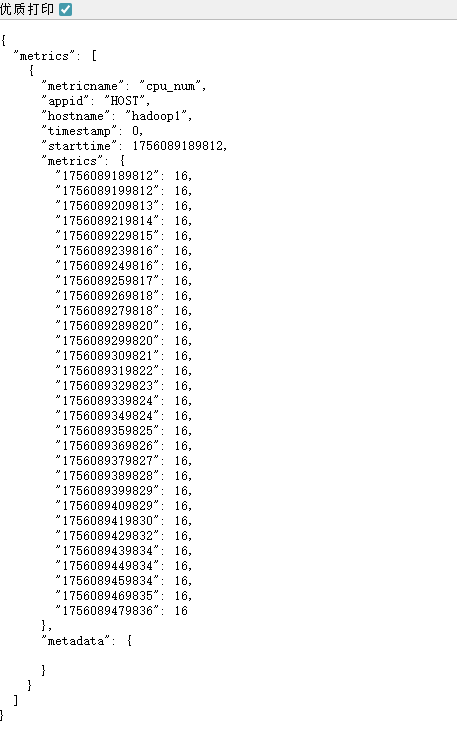
图:接口返回的 JSON 数据通过 Rows 与 Columns 配置转为时序指标
# 五、验证 API 数据
在浏览器或命令行直接访问 API,确保数据能正常返回:
http://hadoop1:6188/ws/v1/timeline/metrics?appId=HOST&endTime=1756089483234&hostname=hadoop1&metricNames=cpu_num&startTime=1756089183234
返回结果类似:
{
"metrics": [
{
"metricname": "cpu_num",
"hostname": "hadoop1",
"metrics": {
"1756089183234": 8,
"1756089283234": 8,
"1756089383234": 8
}
}
]
}
2
3
4
5
6
7
8
9
10
11
12
13
注意
- 返回值中的时间戳是 毫秒级 Unix 时间戳,必须用
timestamp_epoch格式解析; - 如果返回为空,需检查
appId、metricNames和hostname是否正确。
# 六、展示单一指标效果
完成配置后,就能在 Grafana 面板中看到一条 CPU 核数 曲线。
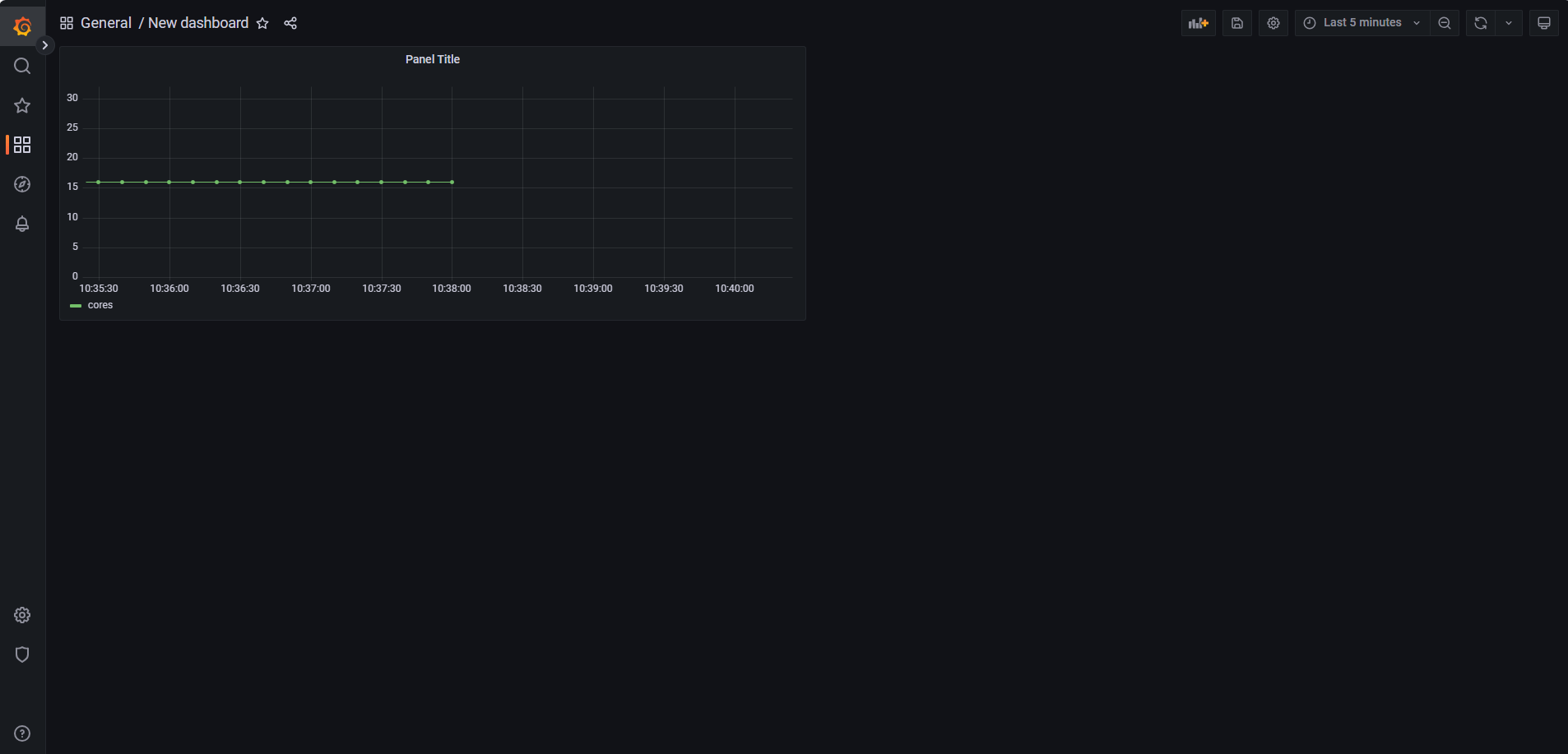 图:最终的展示效果,CPU 核数指标曲线
图:最终的展示效果,CPU 核数指标曲线
思考
虽然这里只是一个简单的 CPU 数量指标,但通过相同方法可以扩展到 内存、磁盘 IO、HDFS、YARN 等所有 AMS 指标。
# 七、完整 Panel JSON 配置
完整的配置请浏览