 源码下载及环境初始化
源码下载及环境初始化
# 背景说明
在前文中我们已经提到,从 2.8.0 版本开始,ambari-metrics 从 Ambari 主项目中拆分,成为独立子项目。
这种演进方式不仅减轻了 Ambari 本体的负担,也让 Metrics 组件可以更灵活地适配不同的环境和依赖。
- 官方 GitHub 仓库地址:
https://github.com/apache/ambari-metrics (opens new window)
为什么要独立?
独立出来的 Ambari-Metrics 可以:
- 更快迭代:解耦 Ambari 本体后,Metrics 不受版本周期限制;
- 跨环境兼容:能独立适配 JDK/Python 的不同组合;
- 专注扩展:更好地支持 Grafana、Hadoop Sink 等下游生态。
# 一、源码获取与工具准备
要进入源码解读阶段,第一步是把代码下载到本地,并通过 IDEA 工具进行打开。
本次我们选择的分支是:
dependabot/maven/ambari-metrics-common/com.google.guava-guava-32.0.0-jre
1
为什么是这个分支?
- 依赖更新:集成了较新的 Guava 依赖,避免低版本 Bug。
- 兼容友好:能在 Python3 环境中正常工作,同时对 Python2 无缝集成。
- 生产验证:经验证该分支在实际环境中指标采集更稳定,不易出现采集失败的情况。
# 二、分支选择的缘由
归纳起来,分支选择主要基于两点考虑:
兼容性 Python2/3 新旧系统并存时,既要照顾 Python3 主环境,也要让 Python2 老环境无痛运行。
稳定性 监控指标 该分支对核心指标采集支持完善,不会出现部分组件“有监控、有插件,但就是没数据”的情况。
# 三、环境准备
在源码分析前,环境准备是关键一步。
| 组件 | 推荐版本 | 用途说明 |
|---|---|---|
| JDK | 1.8 | 本次解析以 Python2 + JDK8 组合为主 |
| Maven | 3.6+ | 构建与依赖管理,IDEA 会自动调用 |
| Python | 2.x/3.x | 支撑脚本运行,分支已兼容两套环境 |
| IDEA | 2022+ | 便于调试与模块级源码阅读 |
注意
Ambari 3.0 需要 JDK17,但 Ambari-Metrics 本体解读更适合在 JDK8 下进行,避免额外的兼容性干扰。 因此建议安装双版本 JDK(8 与 17),并在源码阅读时明确指定环境。
这里安装 JDK 的过程不再赘述,可参考本站其他章节
# 四、IDEA 打开与构建验证
源码下载完成后,用 IDEA 打开项目:
- 打开右侧 Maven 面板;
- 点击 Load 重新加载依赖;
- 等待依赖下载完成。
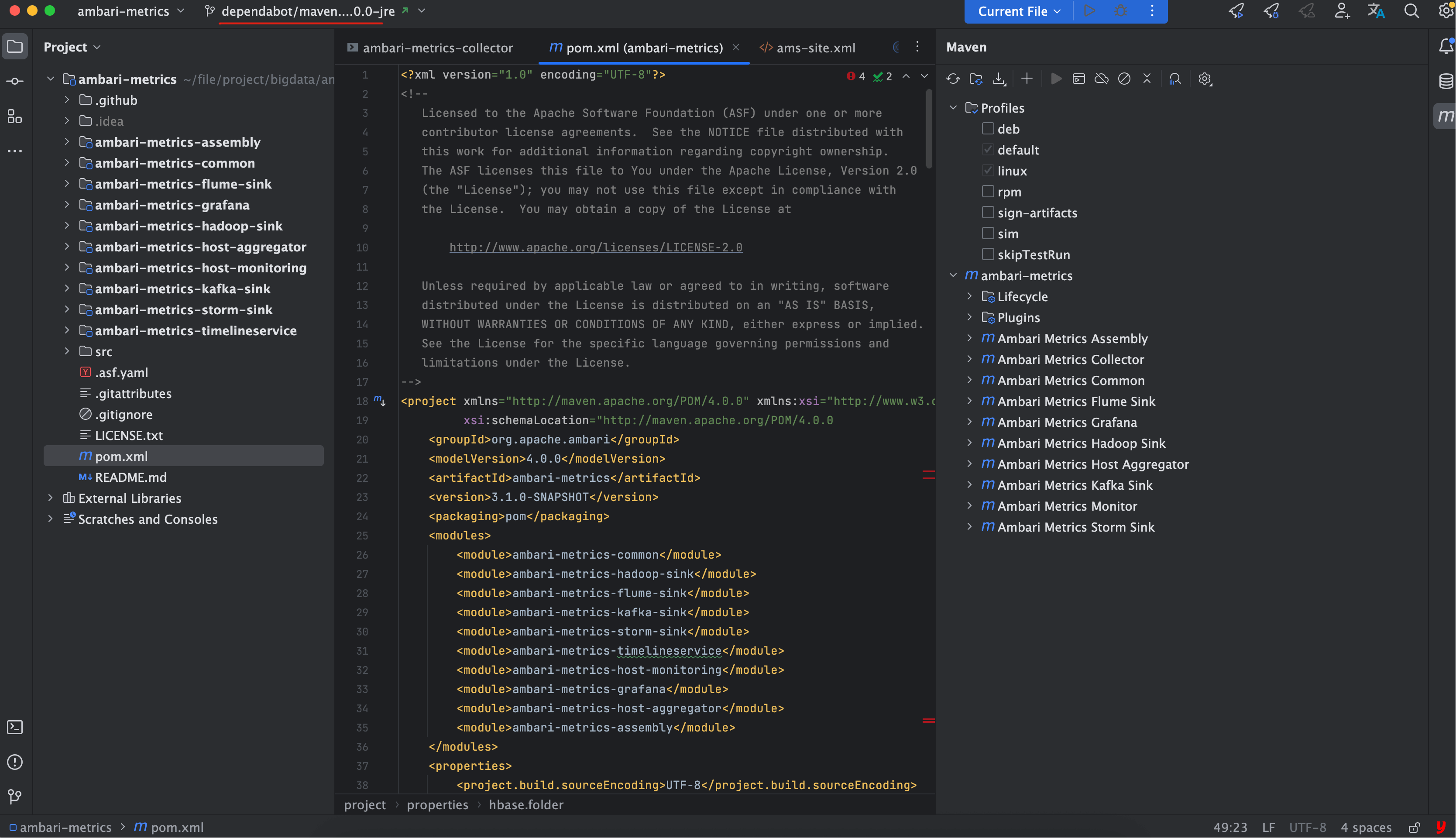
验证方式
如果项目中没有出现大面积爆红,说明 Maven 依赖解析正确,环境初始化成功。