 [/metrics/metadata] — 请求完整链路解读
[/metrics/metadata] — 请求完整链路解读
# 一、背景与目标
为什么要关注 Metadata 请求?
在 Ambari-Metrics Collector 的众多接口中,TimelineMetricMetadata 请求属于高频调用。
它的职责是返回某个组件(appid)下的全部监控指标定义,常用于 UI 查询、指标下拉框、黑白名单过滤。
我们需要回答三个核心问题:
- 请求链路是什么? —— 从 REST API 到缓存返回的完整调用过程。
- 过滤逻辑怎么实现? ——
appId、metricPattern、黑名单参数如何影响结果。 - 缓存数据从何而来? —— 系统何时初始化这些元数据?如何保证缓存一致性?
# 二、整体链路回顾
调用链路如图所示:
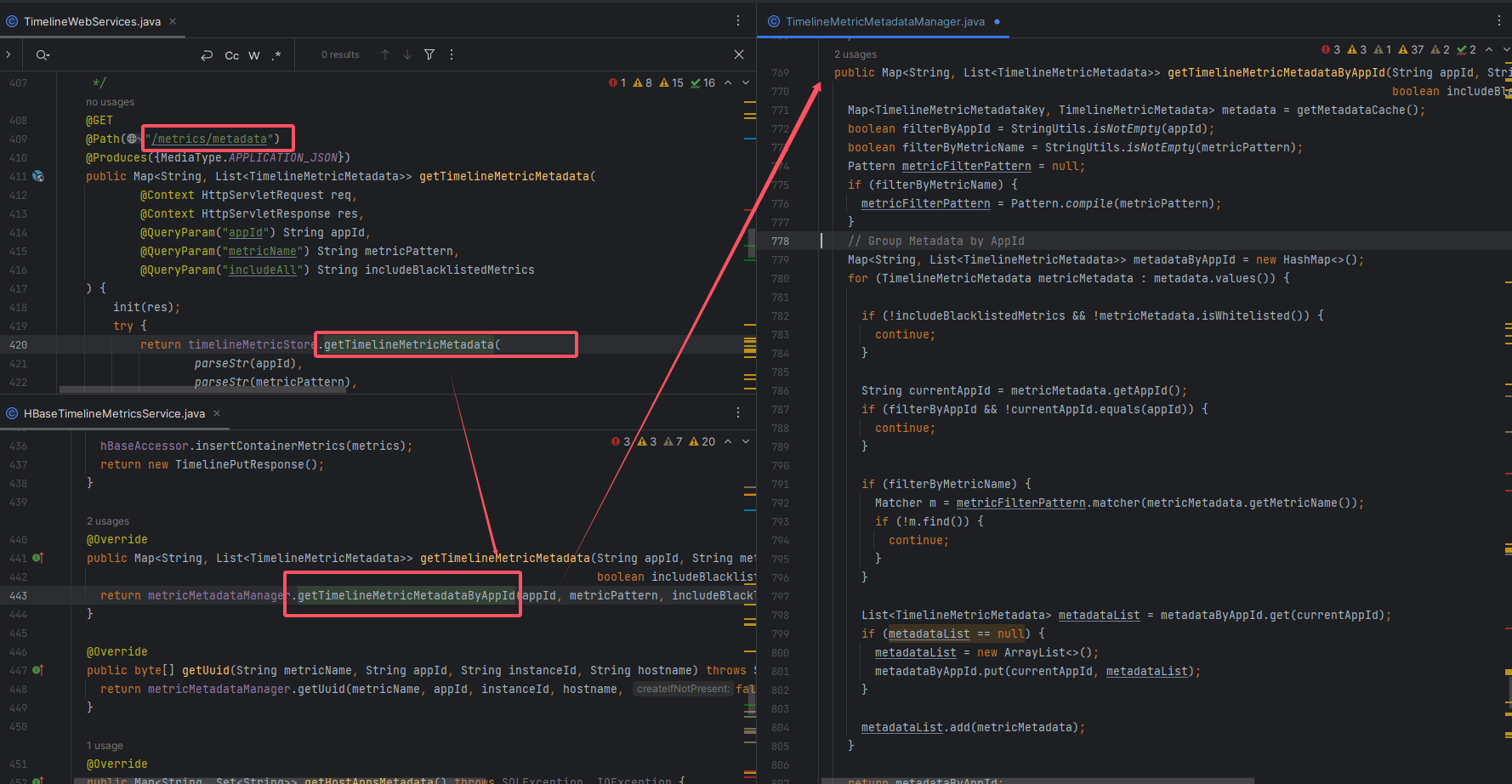
TimelineWebServices.getTimelineMetricMetadata
↓
HBaseTimelineMetricsService.getTimelineMetricMetadata
↓
TimelineMetricMetadataManager.getTimelineMetricMetadataByAppId
2
3
4
5
6
7
设计哲学
这是一条典型的 三层架构链路:
- 控制层(Controller) → 接收 REST 请求
- 服务层(Service) → 负责业务逻辑与存储交互
- 缓存层(Manager) → 从内存缓存中返回结果
# 三、API 层:请求入口
# 1、REST 请求
接口入口在 TimelineWebServices,对外暴露 HTTP 请求路径:
/ws/v1/timeline/metrics/metadata
它的职责很单一:接收参数并下发到服务层。
# 2、关键参数表
| 参数名 | 类型 | 说明 |
|---|---|---|
appId | String | 应用标识,例如 HDFS、YARN、HBASE;为空则查询全量 |
metricPattern | String(正则) | 指标名过滤条件,可匹配如 cpu.* |
includeBlacklistedMetrics | Boolean | 是否包含黑名单指标,默认 false 表示只返回白名单 |
提示
这三个参数组合,可以灵活支持 全量查询 / 模糊匹配 / 精确过滤。
# 四、服务层:业务转发
当请求进入 TimelineWebServices 后,会调用:
HBaseTimelineMetricsService.getTimelineMetricMetadata(appId, metricPattern, includeBlacklistedMetrics);
# 设计思路
笔记
- HBaseTimelineMetricsService 不直接查 HBase,而是进一步委托给 TimelineMetricMetadataManager。
- 这种分层结构保证了:服务类关注流程,管理器关注数据。
# 五、缓存层:元数据管理器
核心逻辑在 TimelineMetricMetadataManager.getTimelineMetricMetadataByAppId:
Map<TimelineMetricMetadataKey, TimelineMetricMetadata> metadata = getMetadataCache();
// 参数过滤逻辑
boolean filterByAppId = StringUtils.isNotEmpty(appId);
boolean filterByMetricName = StringUtils.isNotEmpty(metricPattern);
Pattern metricFilterPattern = null;
if (filterByMetricName) {
metricFilterPattern = Pattern.compile(metricPattern);
}
// 遍历缓存,逐层过滤
Map<String, List<TimelineMetricMetadata>> metadataByAppId = new HashMap<>();
for (TimelineMetricMetadata metricMetadata : metadata.values()) {
if (!includeBlacklistedMetrics && !metricMetadata.isWhitelisted()) {
continue;
}
String currentAppId = metricMetadata.getAppId();
if (filterByAppId && !currentAppId.equals(appId)) {
continue;
}
if (filterByMetricName) {
Matcher m = metricFilterPattern.matcher(metricMetadata.getMetricName());
if (!m.find()) {
continue;
}
}
metadataByAppId.computeIfAbsent(currentAppId, k -> new ArrayList<>())
.add(metricMetadata);
}
return metadataByAppId;
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
# 过滤逻辑一览
| 条件 | 判断点 | 说明 |
|---|---|---|
| 黑名单过滤 | !metricMetadata.isWhitelisted() | 默认跳过黑名单指标 |
| AppId 过滤 | currentAppId.equals(appId) | 精确匹配指定组件 |
| 正则过滤 | Pattern.compile(metricPattern) | 支持模糊匹配指标名 |
# 六、缓存结构详解
# 1、Key 设计
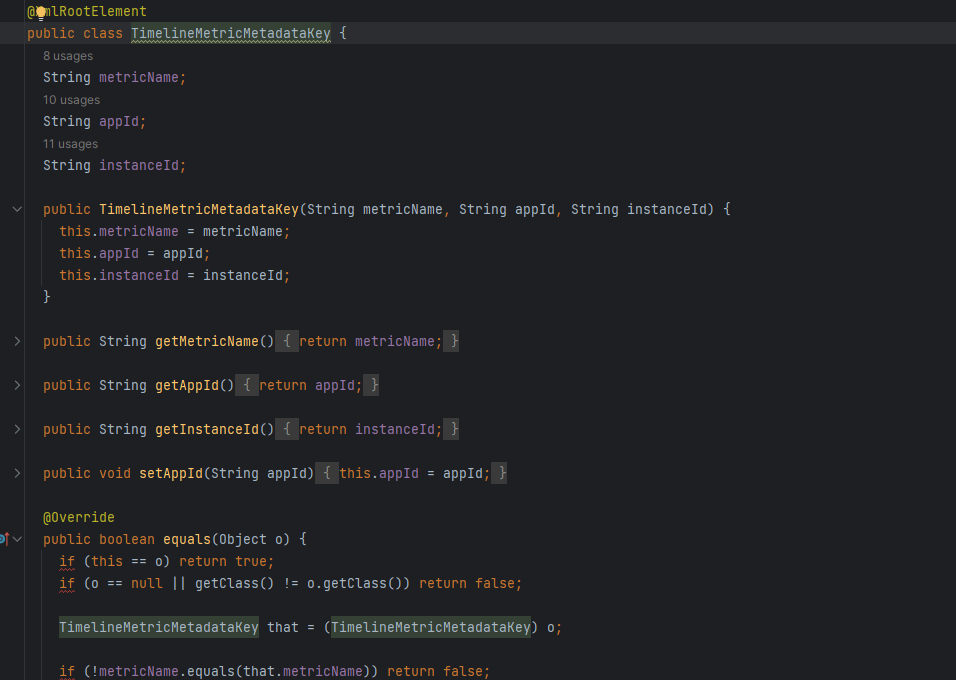
class TimelineMetricMetadataKey {
String metricName;
String appId;
String instanceId;
}
2
3
4
5
提示
三者组合保证唯一性,避免不同组件/实例下的指标冲突。
# 2、Value 内容
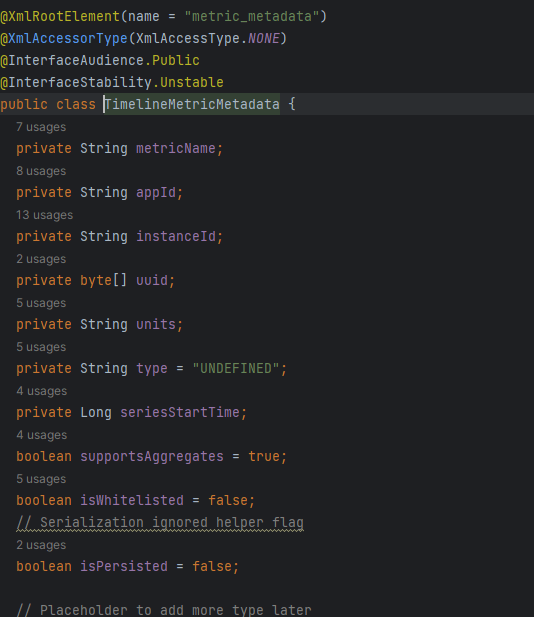
TimelineMetricMetadata 对象包含:
- 采集频率
- 数据类型(long/double)
- 聚合方式(sum/avg/max)
- 白名单属性
它就像是每个指标的 身份证信息。
# 七、执行逻辑串联
整个请求的 四步走:
- 获取缓存 → 从
ConcurrentHashMap拉取全量数据 - 参数过滤 → 黑名单 / appId / metricPattern
- 结果分组 → 按
appId组织成Map - 返回结果 → 给上层调用返回 JSON
性能要点
由于全程依赖缓存(ConcurrentHashMap),避免了实时访问 HBase 的开销,保证了接口的高性能。
# 八、缓存初始化来源
# 1、反向追踪
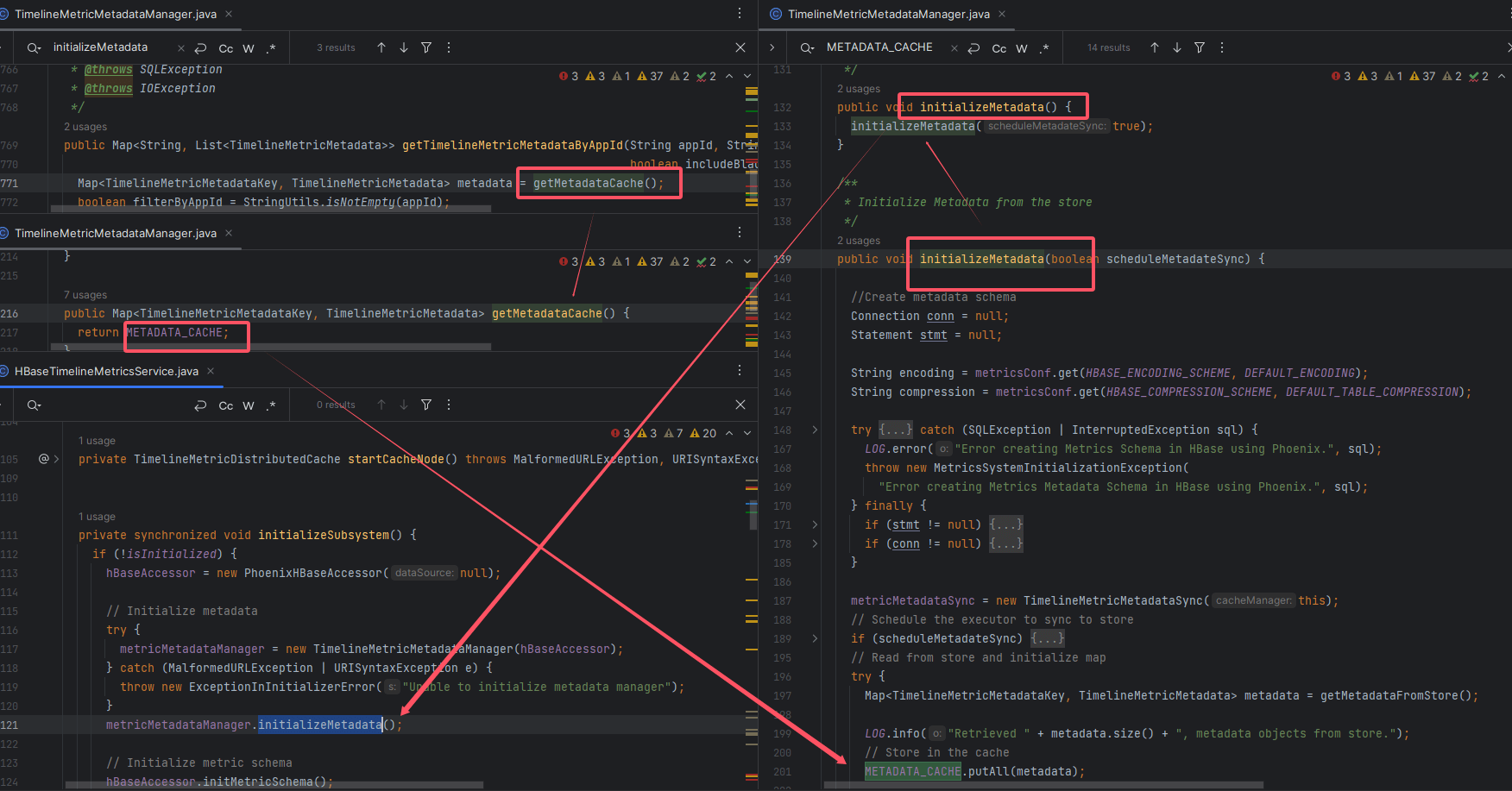
private final Map<TimelineMetricMetadataKey, TimelineMetricMetadata> METADATA_CACHE = new ConcurrentHashMap<>();
填充过程发生在 initializeMetadata:
public void initializeMetadata(...) {
METADATA_CACHE.putAll(loadFromHBaseOrConfig());
}
2
3
# 2、初始化链路
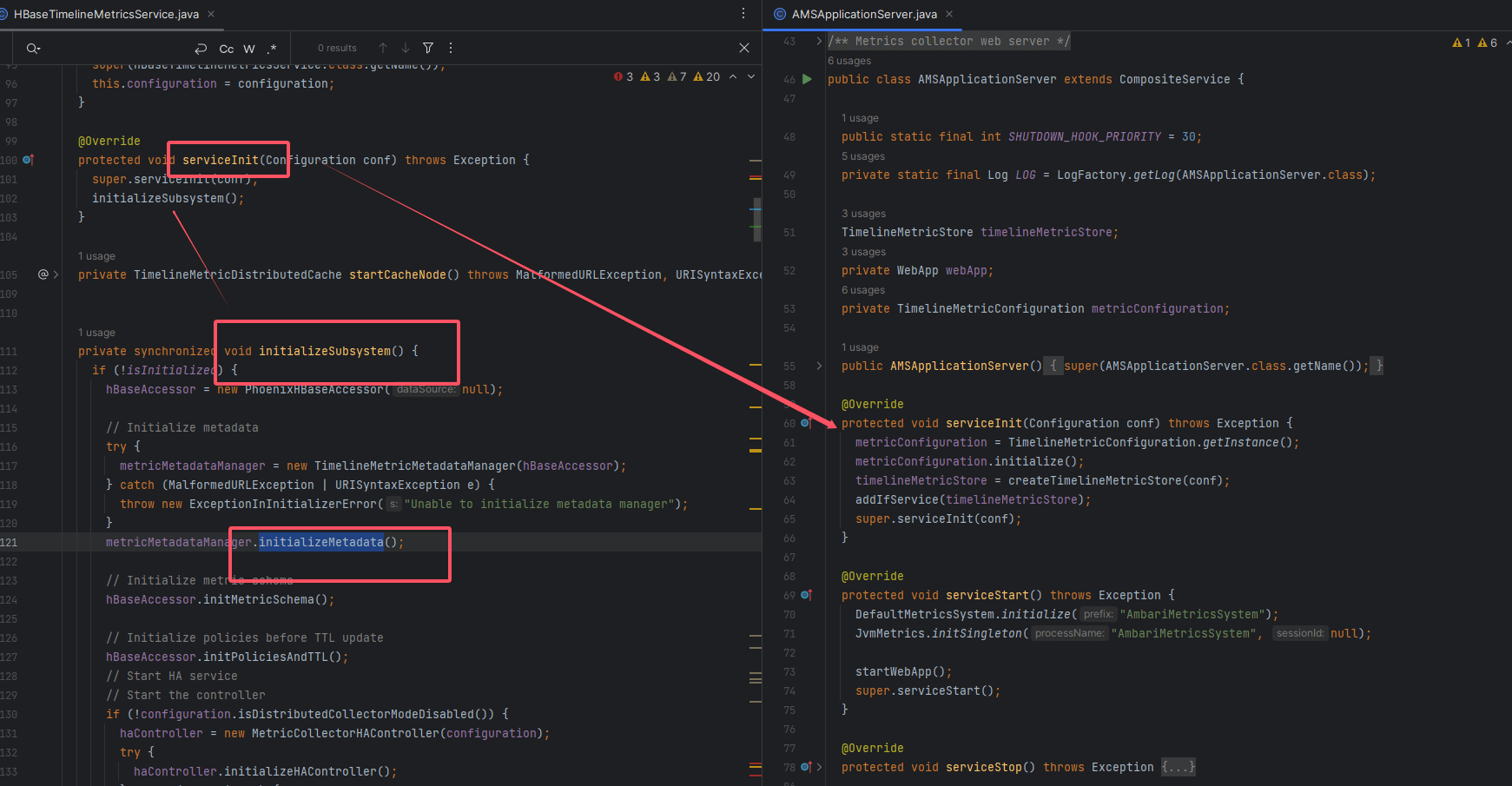
| 阶段 | 方法 | 职责 |
|---|---|---|
| 启动入口 | AMSApplicationServer.main | 触发 init() |
| 服务初始化 | HBaseTimelineMetricsService.serviceInit | 初始化存储子系统 |
| 子系统初始化 | initializeSubsystem | 执行元数据加载 |
| 缓存填充 | TimelineMetricMetadataManager.initializeMetadata | putAll 元数据 |
注意
如果初始化阶段 HBase 不可用,缓存将为空,导致接口无法返回有效结果。
# 九、全景流程总结
flowchart TD
A[REST 请求 /metadata] --> B[TimelineWebServices Controller]
B --> C[HBaseTimelineMetricsService]
C --> D[TimelineMetricMetadataManager]
D --> E[ConcurrentHashMap 缓存]
E --> F[返回分组结果]
2
3
4
5
6
闭环逻辑:
- 入口:REST API 收参
- 转发:服务类传递参数
- 命中:缓存层执行过滤
- 初始化:启动时加载全量元数据
- 返回:最终结果交给 UI 或调用方
思考
讲到这里,请求链路已经梳理清楚:
从 Controller → Service → Manager → Cache,逻辑上形成了完整闭环。
但是,问题随之而来:
缓存数据并不是凭空出现的,它第一次写入时是否需要从外部存储查询?
那它究竟是从哪里查的呢?
👉 带着这个问题,我们将在下一节详细解析 元数据的加载来源与 HBase 查询逻辑。