 [/metrics] — Service 代码整体逻辑概览
[/metrics] — Service 代码整体逻辑概览
# 一、Service 代码逻辑总览
Ambari-Metrics 的 Service 层主要由 HBaseTimelineMetricsService 承担,它是 Collector 的核心服务类。 源码路径:
ambari-metrics-timelineservice/src/main/java/org/apache/ambari/metrics/core/timeline/HBaseTimelineMetricsService.java
核心方法为:
@Override
public TimelineMetrics getTimelineMetrics(List<String> metricNames,
List<String> hostnames, String applicationId, String instanceId,
Long startTime, Long endTime, Precision precision, Integer limit,
boolean groupedByHosts, TopNConfig topNConfig, String seriesAggregateFunction)
throws SQLException, IOException {
...
}
1
2
3
4
5
6
7
8
2
3
4
5
6
7
8
其逻辑可拆解为 九大步骤:
参数校验 → 聚合函数解析 → metrics 聚合逻辑 → 多实例管理 → UUID 获取 → 查询条件构造 → TopN 筛选 → 结果清洗 → 二次聚合返回
# 二、逐步剖析代码逻辑
# 1. 参数校验
if (metricNames == null || metricNames.isEmpty()) {
throw new IllegalArgumentException("No metric name filter specified.");
}
if ((startTime == null && endTime != null)
|| (startTime != null && endTime == null)) {
throw new IllegalArgumentException("Open ended query not supported ");
}
if (limit != null && limit > PhoenixHBaseAccessor.RESULTSET_LIMIT) {
throw new IllegalArgumentException("Limit too big");
}
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
metricNames必填。startTime和endTime必须成对出现。limit不能超过 Phoenix 允许的上限。
总结
这一层保证 输入参数合法性,防止对 HBase/Phoenix 发起无效或危险的查询。
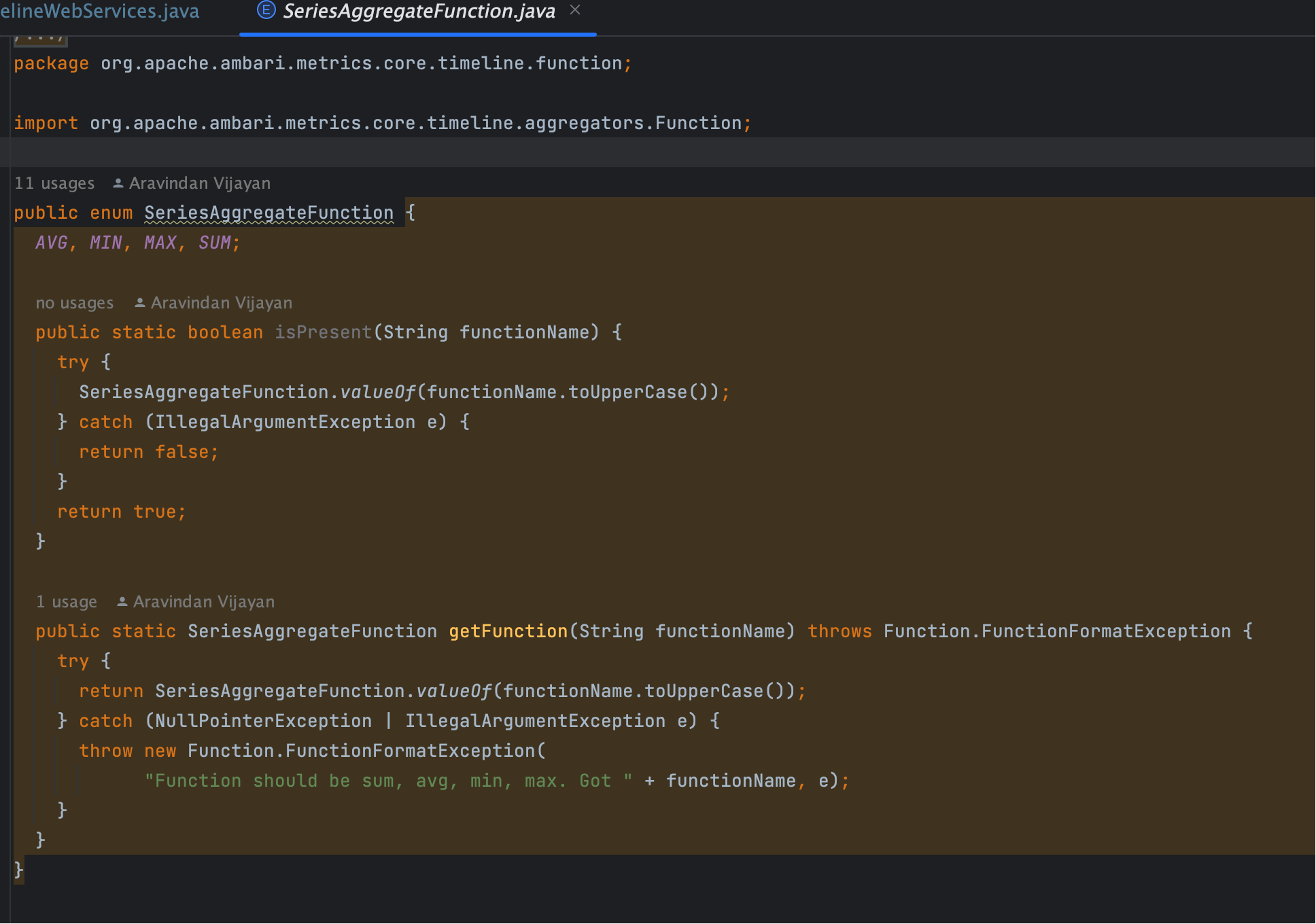
# 2. 聚合函数解析
TimelineMetricsSeriesAggregateFunction seriesAggrFunctionInstance = null;
if (!StringUtils.isEmpty(seriesAggregateFunction)) {
SeriesAggregateFunction func = SeriesAggregateFunction.getFunction(seriesAggregateFunction);
seriesAggrFunctionInstance = TimelineMetricsSeriesAggregateFunctionFactory.newInstance(func);
}
1
2
3
4
5
2
3
4
5
seriesAggregateFunction可选,例如avg、min、max、sum。- 转换成内部聚合函数对象,供后续二次处理。
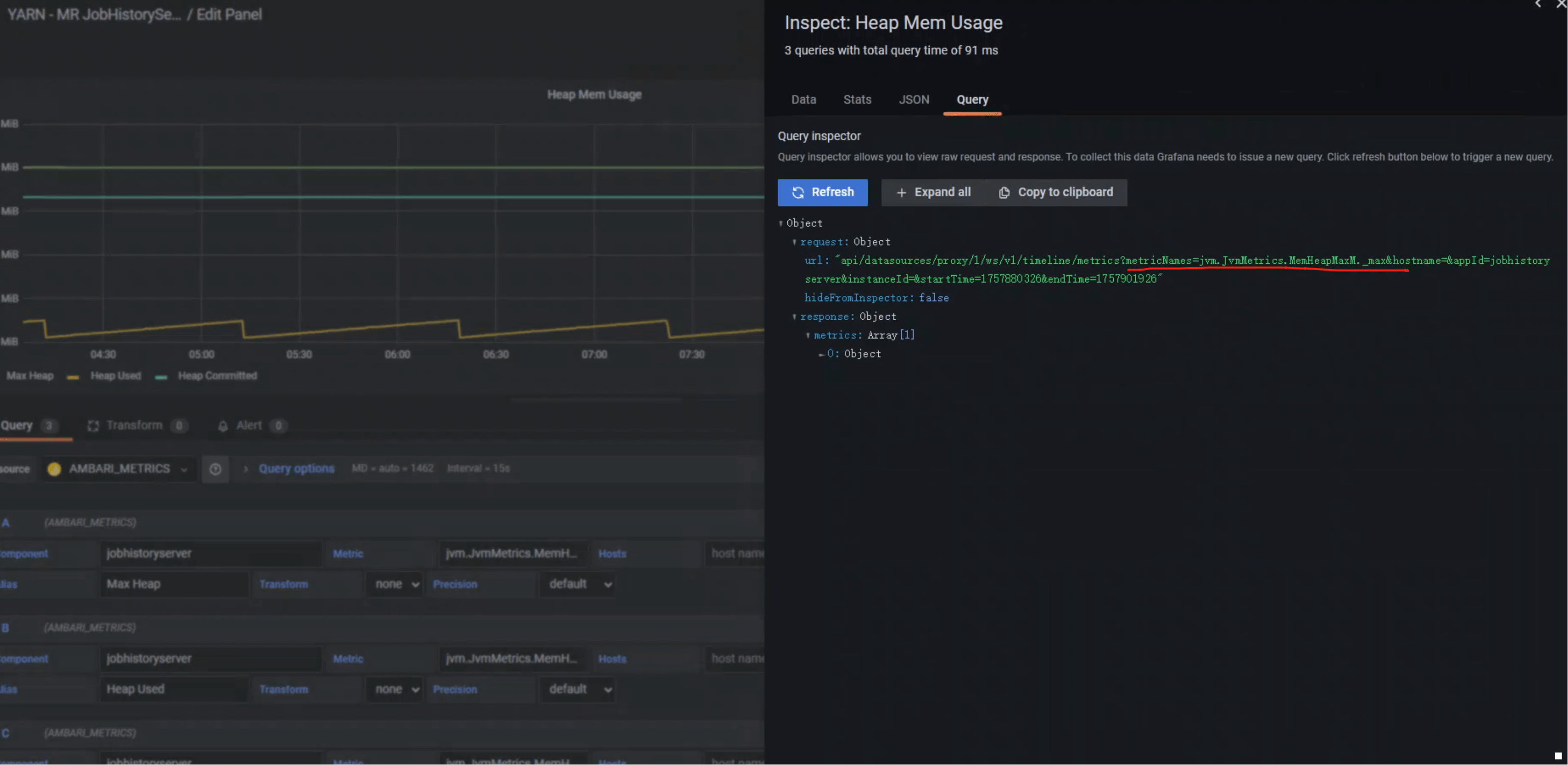
# 3. metrics 聚合逻辑
Multimap<String, List<Function>> metricFunctions =
parseMetricNamesToAggregationFunctions(metricNames);
1
2
2
示例:
/ws/v1/timeline/metrics?metricNames=jvm.JvmMetrics.MemHeapMaxM._max
1
这里的 _max 会自动解析成函数逻辑。
# 4. 多实例管理
提醒
我们部署的Ambari一般情况下没有部署多实例,所以下面一般都是空
if (configuration.getTimelineMetricsMultipleClusterSupport() && StringUtils.isEmpty(instanceId)) {
instanceId = this.defaultInstanceId;
}
1
2
3
2
3
- 单集群:
instanceId通常为空。 - 多集群:会自动填充默认
instanceId。
# 5. 获取指标 UUID
List<byte[]> uuids = metricMetadataManager.getUuidsForGetMetricQuery(
metricFunctions.keySet(), hostnames, applicationId, instanceId, transientMetricNames);
1
2
2
作用:将 逻辑指标名 转化为 物理存储主键(uuid)。
注意
若 uuids 与 transientMetricNames 都为空,直接返回空结果。
# 6. 构造查询条件并查询
ConditionBuilder conditionBuilder = new ConditionBuilder(new ArrayList<String>(metricFunctions.keySet()))
.hostnames(hostnames)
.appId(applicationId)
.instanceId(instanceId)
.startTime(startTime)
.endTime(endTime)
.precision(precision)
.limit(limit)
.grouped(groupedByHosts)
.uuid(uuids)
.transientMetricNames(transientMetricNames);
1
2
3
4
5
6
7
8
9
10
11
12
2
3
4
5
6
7
8
9
10
11
12
核心逻辑:
- 未传 host → 聚合查询(Cluster 级)。
- 传入 host → 按 Host 维度查询。
# 7. TopN 条件处理
applyTopNCondition(conditionBuilder, topNConfig, metricNames, hostnames);
1
TopNConfig用于 取前 N 名。- 可按 host 或 metric 排序。
常见需求:CPU 使用率 Top5 主机。
# 8. 查询结果后处理
metrics = postProcessMetrics(metrics);
1
- 处理
_rate、_diff派生指标。 - 数据清洗,确保接口输出一致。
# 9. 二次聚合并返回
return seriesAggregateMetrics(seriesAggrFunctionInstance, metrics);
1
- 如果用户指定了全局聚合函数(如
avg),这里会再执行一次。 - 典型场景:跨 host、跨时间段的统计。
# 三、逻辑链路
我们可以把整个方法归纳为下表:
| 步骤 | 关键逻辑 | 作用说明 |
|---|---|---|
| 1 | 参数校验 | 确保查询合法性,避免错误请求 |
| 2 | 聚合函数解析 | 转换为内部函数对象,支持二次聚合 |
| 3 | metrics 聚合逻辑 | 支持在 metricName 中直接定义函数 |
| 4 | 多实例管理 | 支持多集群扩展 |
| 5 | 获取 UUID | 将逻辑指标映射到存储层主键 |
| 6 | 构造查询条件 | 生成 Condition,面向 HBase/Phoenix 查询 |
| 7 | TopN 条件处理 | 结果过滤,返回 TopN 数据 |
| 8 | 查询结果后处理 | 清洗数据,保证输出一致 |
| 9 | 二次聚合返回 | 最终包装,确保符合用户请求期望 |