[监控表] — 业务表结构梳理
[监控表] — 业务表结构梳理
# 一、初始化入口
Collector 在启动阶段会调用:
hBaseAccessor.initMetricSchema();
1
这里集中执行所有建表语句,并结合
TimelineMetricSplitPointComputer 生成 Split Points。
# 二、业务表族分类
Collector 初始化时,最核心的就是创建承载时序数据的业务表。
整体上分为 Host Level 与 Cluster Level 两大类,二者的区别在于 是否携带主机维度:
- Host Level 表:携带主机信息,UUID 长度为 20B(指标 16B + 主机 4B),用于存储单机级别的明细和聚合;
- Cluster Level 表:聚合到集群层面,UUID 长度为 16B(仅指标 16B),主要存放全局聚合结果。
此外,还有两张 辅助表,分别用于短期指标存储和容器级监控。
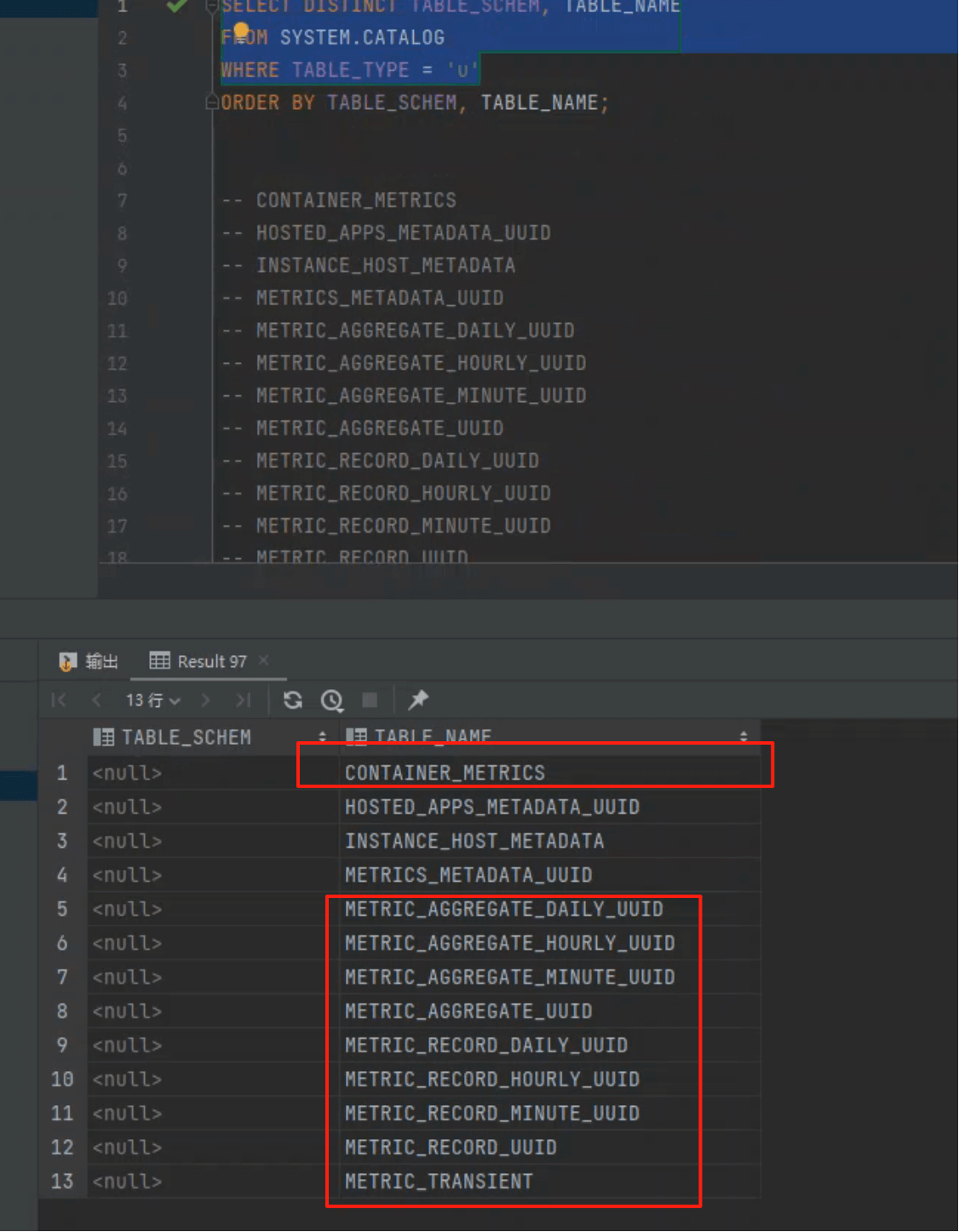
# 1.表族一览
| 分层 | 表名 | 粒度 / 用途 | UUID 设计 |
|---|---|---|---|
| Host Level | METRIC_RECORD_UUID | 秒级原始明细,Collector 写入最繁忙,带 Split | BINARY(20) = 指标16B + 主机4B |
METRIC_RECORD_MINUTE_UUID | 主机维度分钟聚合,带 Split | BINARY(20) | |
METRIC_RECORD_HOURLY_UUID | 主机维度小时聚合 | BINARY(20) | |
METRIC_RECORD_DAILY_UUID | 主机维度天聚合 | BINARY(20) | |
| Cluster Level | METRIC_AGGREGATE_UUID | 秒级全局聚合(含 HOSTS_COUNT 字段),带 Split | BINARY(16)(仅指标维度) |
METRIC_AGGREGATE_MINUTE_UUID | 分钟全局聚合(含 METRIC_COUNT 字段) | BINARY(16) | |
METRIC_AGGREGATE_HOURLY_UUID | 小时全局聚合 | BINARY(16) | |
METRIC_AGGREGATE_DAILY_UUID | 天全局聚合 | BINARY(16) | |
| 辅助 | METRIC_TRANSIENT | 瞬时 / 实验性指标(按需创建,不做长期存储) | 无 UUID(直接用原始维度作主键) |
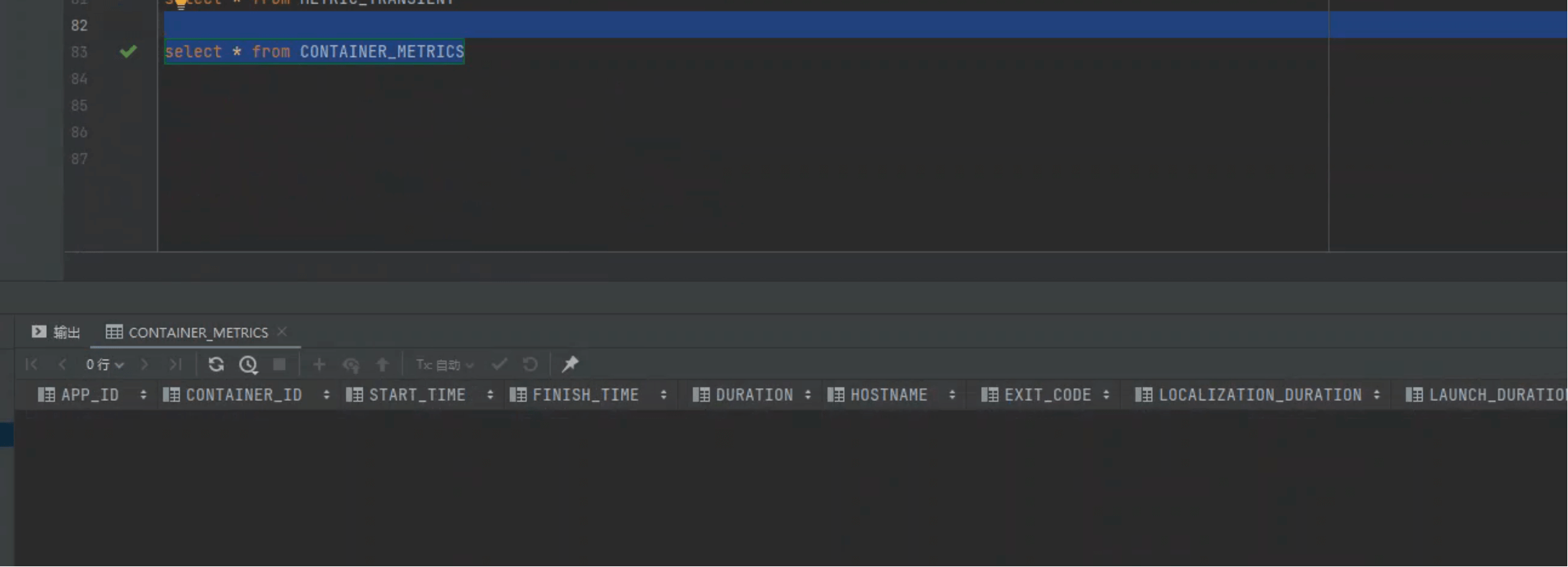
| 辅助 | CONTAINER_METRICS | 容器级指标(生命周期 / 资源消耗追踪) | 主键 APP_ID + CONTAINER_ID |
# 2.补充说明
Host Level 表
- 面向单机维度,数据量巨大。
- 秒级明细表写入量最高,必须依赖 Split 分区;
- 分钟/小时/天聚合表则逐级降低数据量,用于查询趋势和可视化。
Cluster Level 表
- 面向集群维度,去掉主机位,UUID 长度缩减为 16B。
- 秒级表包含
HOSTS_COUNT字段,用于统计参与聚合的主机数; - 分/时/天聚合表则使用
METRIC_COUNT,表示样本数量。
辅助表
- Transient 表:仅在配置了 transient.patterns 时才会创建,不走 UUID,适合存放心跳或实验性数据,TTL 很短;
- Container 表:专门用于记录 YARN 容器的生命周期与资源使用情况,例如启动耗时、退出状态、内存申请与实际使用。
# 三、核心表结构
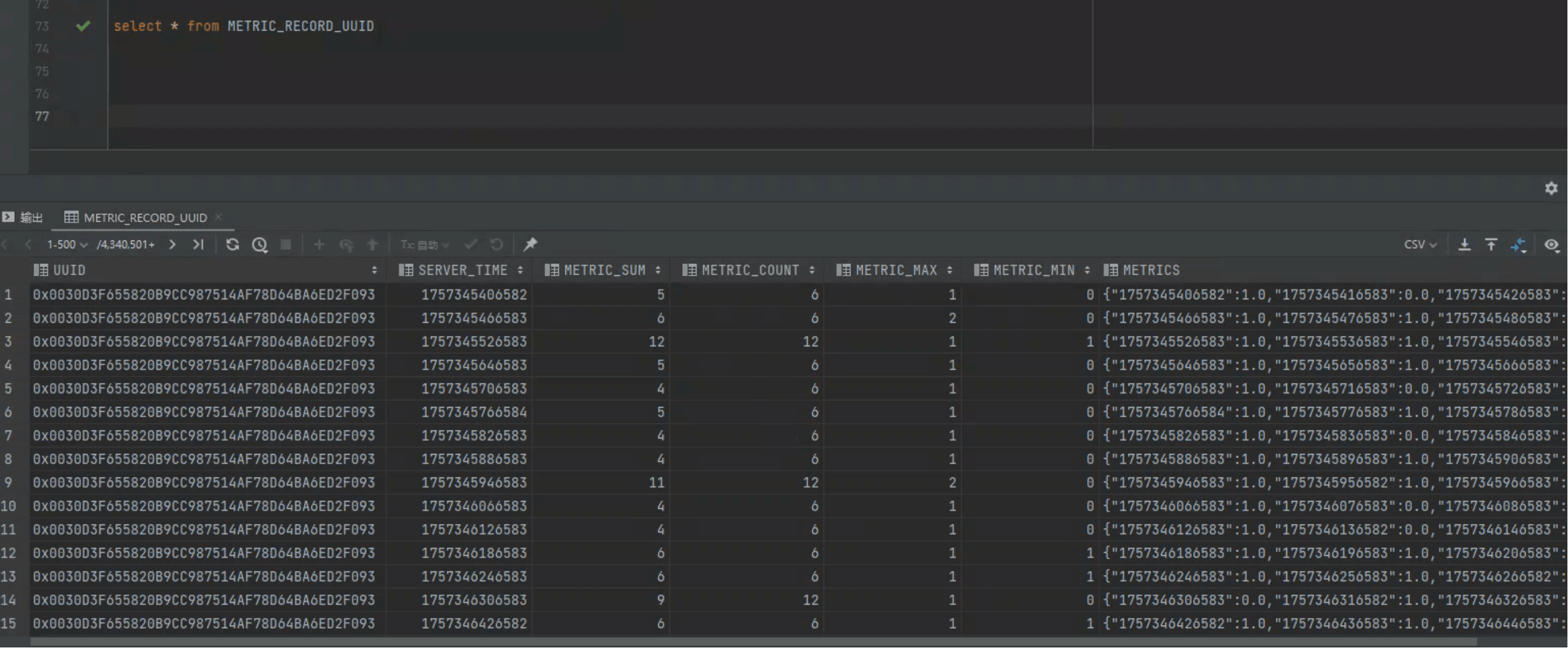
# 1. Host Level — 原始明细表
CREATE TABLE IF NOT EXISTS METRIC_RECORD_UUID (
UUID BINARY(20) NOT NULL,
SERVER_TIME BIGINT NOT NULL,
METRIC_SUM DOUBLE,
METRIC_COUNT UNSIGNED_INT,
METRIC_MAX DOUBLE,
METRIC_MIN DOUBLE,
METRICS VARCHAR,
CONSTRAINT pk PRIMARY KEY (UUID, SERVER_TIME ROW_TIMESTAMP)
) DATA_BLOCK_ENCODING='FAST_DIFF',
IMMUTABLE_ROWS=true, TTL=..., COMPRESSION='SNAPPY';
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
- UUID 20B = 指标 16B + 主机 4B
- SERVER_TIME:行键二级维度,范围查询高效
- METRICS:样本值(秒级还原曲线)
# 2. Host Level — 聚合表
CREATE TABLE IF NOT EXISTS METRIC_RECORD_MINUTE_UUID (
UUID BINARY(20) NOT NULL,
SERVER_TIME BIGINT NOT NULL,
METRIC_SUM DOUBLE,
METRIC_COUNT UNSIGNED_INT,
METRIC_MAX DOUBLE,
METRIC_MIN DOUBLE,
CONSTRAINT pk PRIMARY KEY (UUID, SERVER_TIME ROW_TIMESTAMP)
) DATA_BLOCK_ENCODING='FAST_DIFF',
IMMUTABLE_ROWS=true, TTL=..., COMPRESSION='SNAPPY';
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
同类还有:
METRIC_RECORD_HOURLY_UUIDMETRIC_RECORD_DAILY_UUID
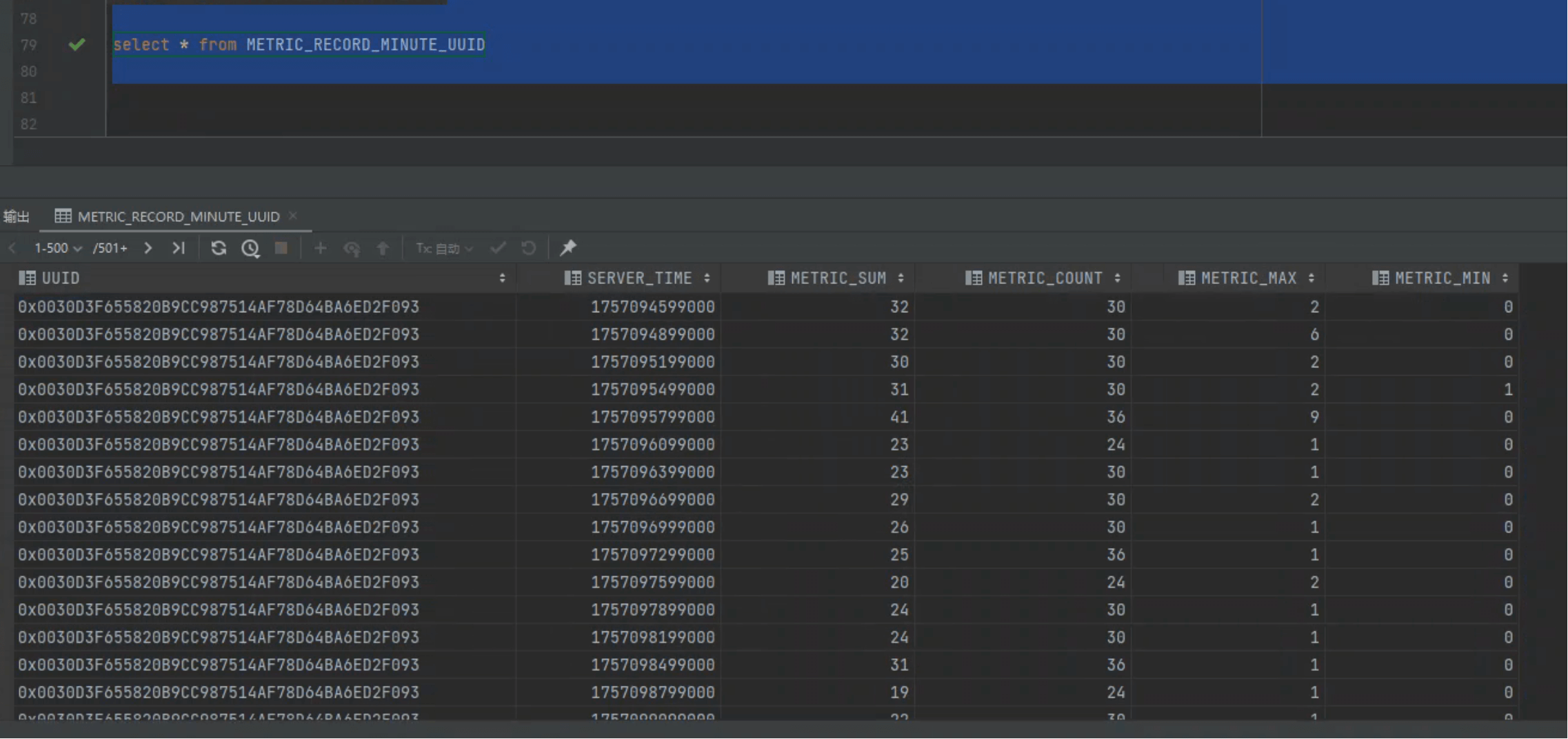
查询建议
分钟表 → 高频查询 & 可视化 小时/天表 → 长期趋势对比
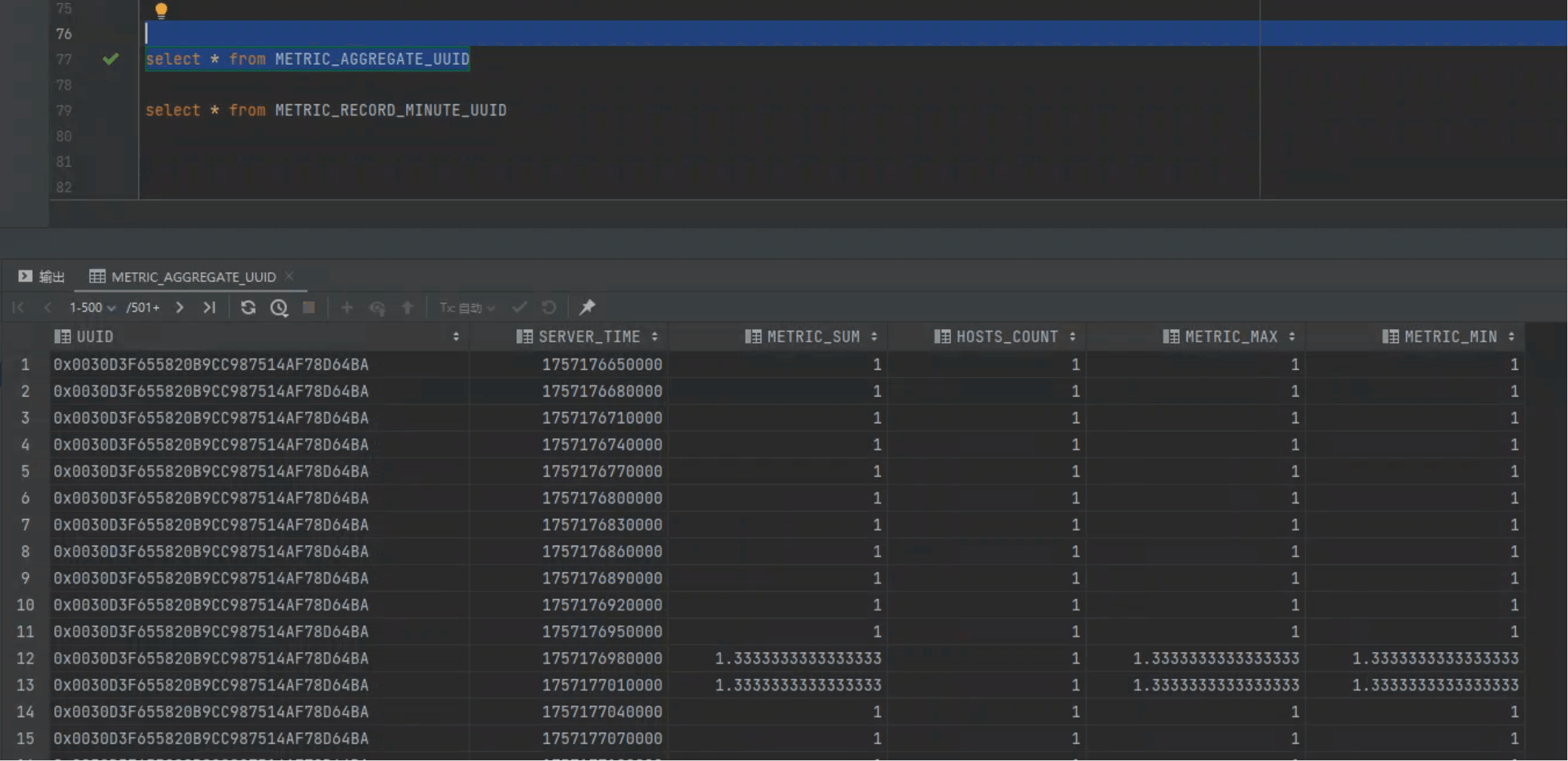
# 3. Cluster Level — 秒级全局聚合
CREATE TABLE IF NOT EXISTS METRIC_AGGREGATE_UUID (
UUID BINARY(16) NOT NULL,
SERVER_TIME BIGINT NOT NULL,
METRIC_SUM DOUBLE,
HOSTS_COUNT UNSIGNED_INT,
METRIC_MAX DOUBLE,
METRIC_MIN DOUBLE,
CONSTRAINT pk PRIMARY KEY (UUID, SERVER_TIME ROW_TIMESTAMP)
) DATA_BLOCK_ENCODING='FAST_DIFF',
IMMUTABLE_ROWS=true, TTL=..., COMPRESSION='SNAPPY';
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
- UUID 16B:不含主机位
- HOSTS_COUNT:参与聚合的主机数
常用于:全局秒级波动 → 快速监控集群负载
# 4. Cluster Level — 分/时/天聚合
CREATE TABLE IF NOT EXISTS METRIC_AGGREGATE_MINUTE_UUID (
UUID BINARY(16) NOT NULL,
SERVER_TIME BIGINT NOT NULL,
METRIC_SUM DOUBLE,
METRIC_COUNT UNSIGNED_INT,
METRIC_MAX DOUBLE,
METRIC_MIN DOUBLE,
CONSTRAINT pk PRIMARY KEY (UUID, SERVER_TIME ROW_TIMESTAMP)
) DATA_BLOCK_ENCODING='FAST_DIFF',
IMMUTABLE_ROWS=true, TTL=..., COMPRESSION='SNAPPY';
1
2
3
4
5
6
7
8
9
10
2
3
4
5
6
7
8
9
10
同类还有:
METRIC_AGGREGATE_HOURLY_UUIDMETRIC_AGGREGATE_DAILY_UUID
字段差异
- 秒级表:
HOSTS_COUNT - 分/时/天:
METRIC_COUNT
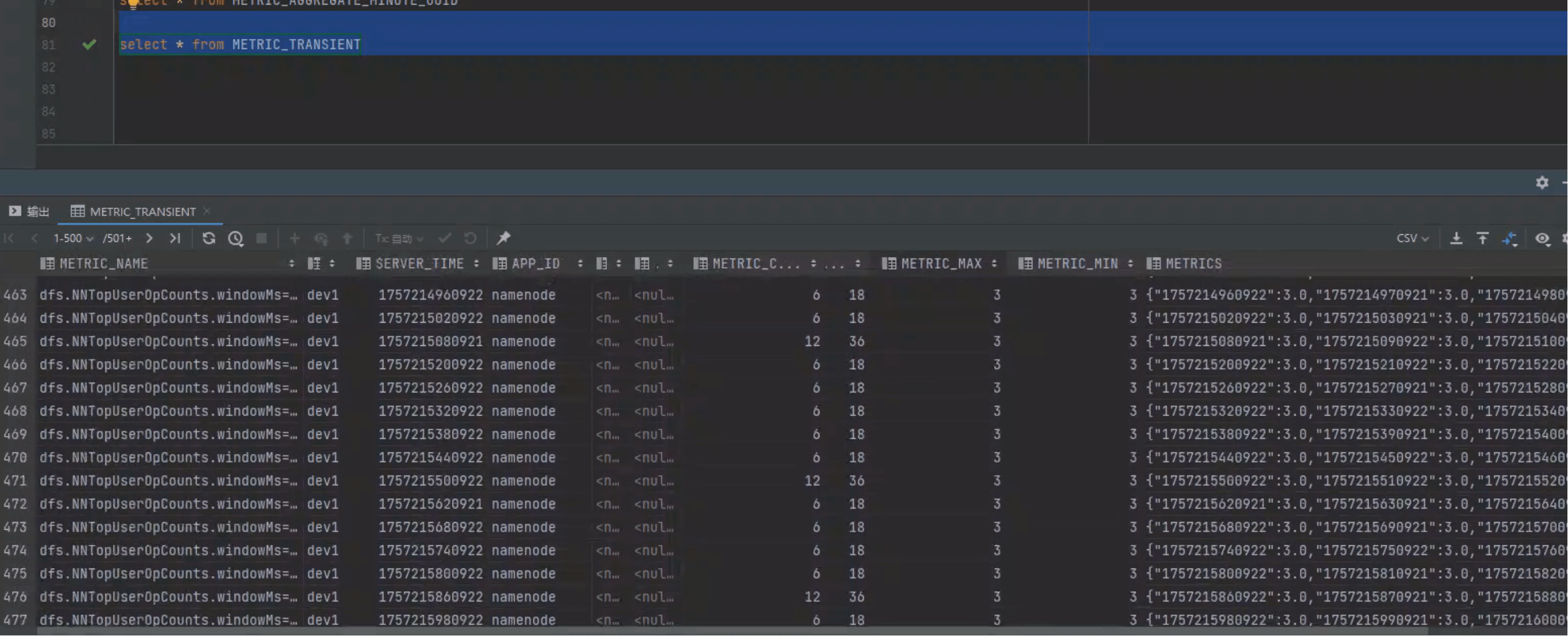
# 5. Transient — 瞬时指标
CREATE TABLE IF NOT EXISTS METRIC_TRANSIENT (
METRIC_NAME VARCHAR,
HOSTNAME VARCHAR,
SERVER_TIME BIGINT NOT NULL,
APP_ID VARCHAR,
INSTANCE_ID VARCHAR,
UNITS CHAR(20),
METRIC_SUM DOUBLE,
METRIC_COUNT UNSIGNED_INT,
METRIC_MAX DOUBLE,
METRIC_MIN DOUBLE,
METRICS VARCHAR,
CONSTRAINT pk PRIMARY KEY (METRIC_NAME, HOSTNAME, SERVER_TIME ROW_TIMESTAMP, APP_ID, INSTANCE_ID)
) DATA_BLOCK_ENCODING='FAST_DIFF',
IMMUTABLE_ROWS=true, TTL=..., COMPRESSION='SNAPPY';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
2
3
4
5
6
7
8
9
10
11
12
13
14
15
- 不分配 UUID,用原始维度做主键
- TTL 短,适合心跳/实验性指标
# 6. Container — 容器指标表
CREATE TABLE IF NOT EXISTS CONTAINER_METRICS (
APP_ID VARCHAR,
CONTAINER_ID VARCHAR,
START_TIME TIMESTAMP,
FINISH_TIME TIMESTAMP,
DURATION BIGINT,
HOSTNAME VARCHAR,
EXIT_CODE INTEGER,
LOCALIZATION_DURATION BIGINT,
LAUNCH_DURATION BIGINT,
MEM_REQUESTED_GB DOUBLE,
MEM_REQUESTED_GB_MILLIS DOUBLE,
MEM_VIRTUAL_GB DOUBLE,
MEM_USED_GB_MIN DOUBLE,
MEM_USED_GB_MAX DOUBLE,
MEM_USED_GB_AVG DOUBLE,
MEM_USED_GB_50_PCT DOUBLE,
MEM_USED_GB_75_PCT DOUBLE,
MEM_USED_GB_90_PCT DOUBLE,
MEM_USED_GB_95_PCT DOUBLE,
MEM_USED_GB_99_PCT DOUBLE,
MEM_UNUSED_GB DOUBLE,
MEM_UNUSED_GB_MILLIS DOUBLE,
CONSTRAINT pk PRIMARY KEY(APP_ID, CONTAINER_ID)
) DATA_BLOCK_ENCODING='FAST_DIFF',
IMMUTABLE_ROWS=true, TTL=..., COMPRESSION='SNAPPY';
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- 记录容器生命周期(启动/结束/耗时)
- 跟踪内存请求 vs 实际使用
- 常与 Spark/Flink 作业诊断联动