 [/metrics] — metricNames 生命周期
[/metrics] — metricNames 生命周期
# 一、入口:非空校验(拦截无效请求)
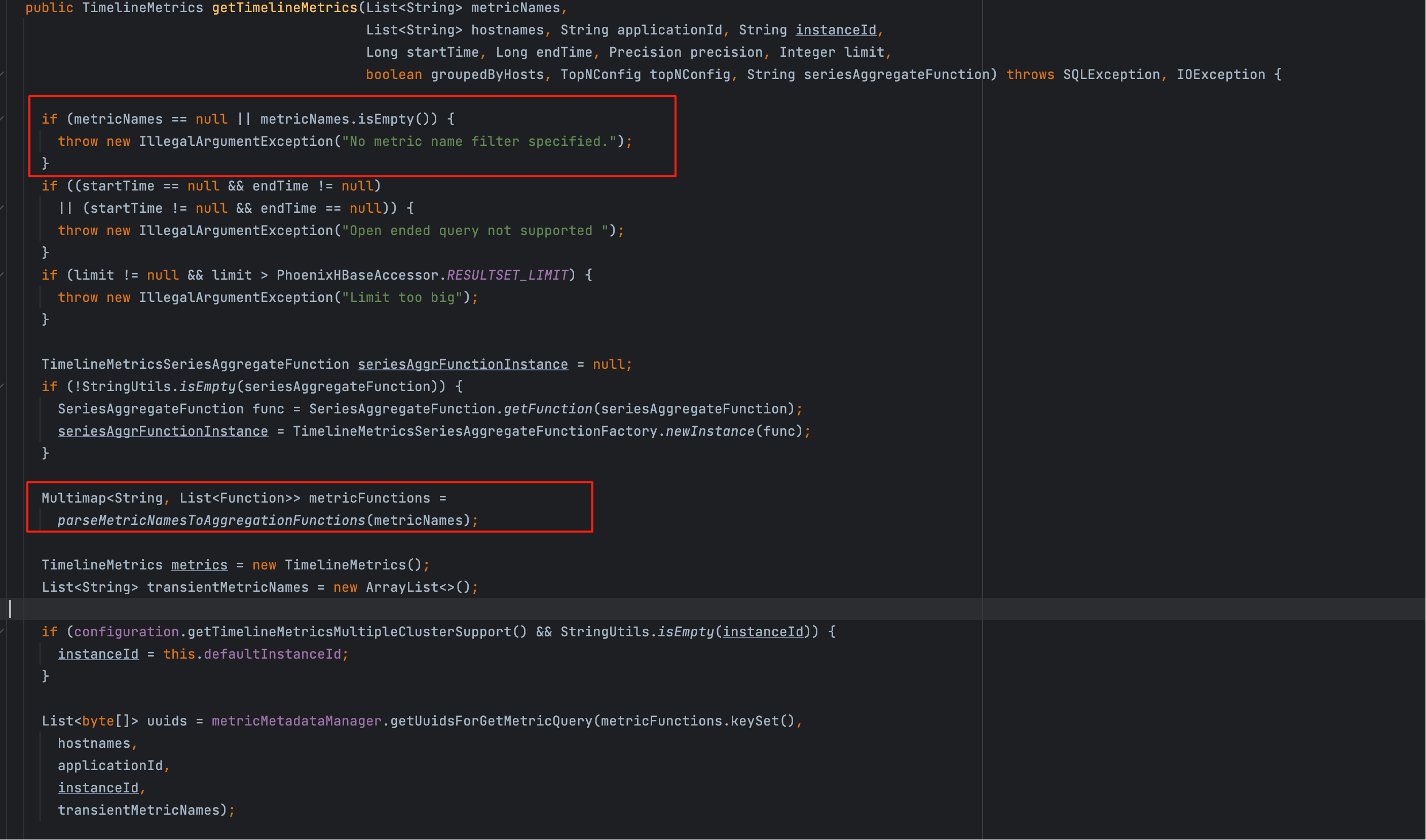
# 1、参数非空校验
if (metricNames == null || metricNames.isEmpty()) {
throw new IllegalArgumentException("No metric name filter specified.");
}
2
3
这一关是最前置的“硬闸”:
- 为什么要硬拦?
/metrics不带指标没有业务意义,继续执行只会浪费 HBase/Phoenix 的资源,还可能把 TopN、聚合等后续逻辑带偏。 - 常见触发场景:Grafana 变量未解析为空、拼装查询字符串丢参、Apifox 模板未填。
提示
/metrics 不带指标没有业务意义,这里直接抛错,能够尽早暴露请求问题。
排错清单(最常见三类)
1)metricNames= 后没有值 / 变量没展开;
2)多指标拼接时漏了逗号导致后端解析失败;
3)带了空白字符(如 metricNames= cpu.usage),被前端 trim 规则“照顾不到”。
# 二、解析:parseMetricNamesToAggregationFunctions(拆后缀、留“干净名”)
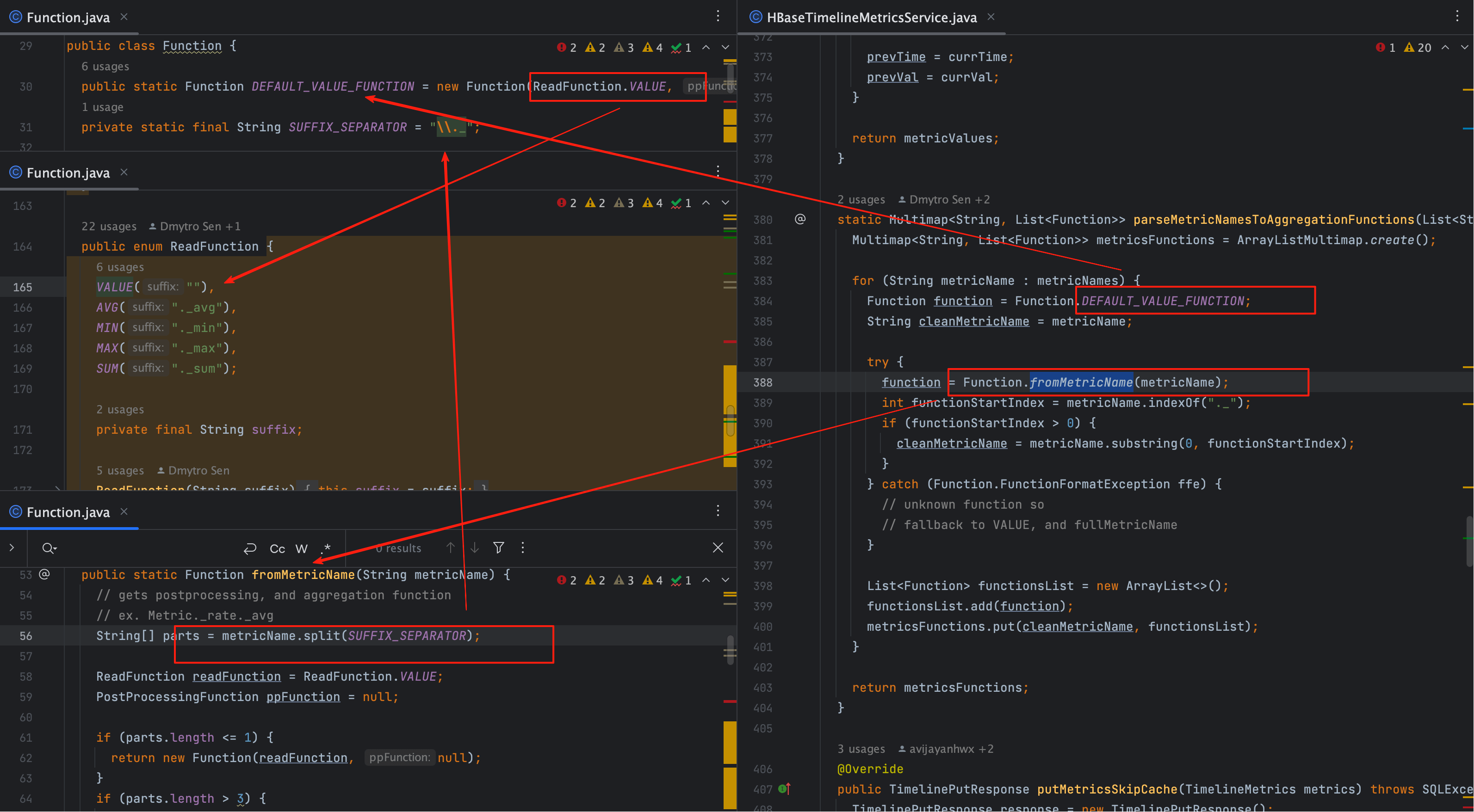
# 1、调用入口
Multimap<String, List<Function>> metricFunctions =
parseMetricNamesToAggregationFunctions(metricNames);
2
这一步把带函数后缀的指标(如 cpu.usage._avg、regionserver.Server.storeFileSize._sum)解析成两部分:
- 干净指标名:后续 UUID 匹配只看它;
- 函数列表:在读取层或内存后置处理阶段生效。
# 2、核心实现(保留原始代码)
static Multimap<String, List<Function>> parseMetricNamesToAggregationFunctions(List<String> metricNames) {
Multimap<String, List<Function>> metricsFunctions = ArrayListMultimap.create();
for (String metricName : metricNames) {
Function function = Function.DEFAULT_VALUE_FUNCTION;
String cleanMetricName = metricName;
try {
function = Function.fromMetricName(metricName);
int functionStartIndex = metricName.indexOf("._");
if (functionStartIndex > 0) {
cleanMetricName = metricName.substring(0, functionStartIndex);
}
} catch (Function.FunctionFormatException ffe) {
// unknown function so
// fallback to VALUE, and fullMetricName
}
List<Function> functionsList = new ArrayList<>();
functionsList.add(function);
metricsFunctions.put(cleanMetricName, functionsList);
}
return metricsFunctions;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
# 3、要点说明
后缀语法:以
._为分隔,metricName + "._" + 函数。函数分两层
- ReadFunction:
value/sum/avg/min/max(落到读取层;影响 SQL/聚合器取数与聚合方式)。 - PostProcessingFunction:
_rate/_diff(在内存对时间序列做派生变换)。
- ReadFunction:
干净名:只截第一次
._之前的部分;UUID 匹配只用干净名。降级策略:后缀非法 → 退回 VALUE(只取原值)+ 保留完整字符串,这意味着后续 UUID 解析可能查不到(因为带后缀的完整串不参与 UUID 生成)。
多后缀链:实现上只识别一类读函数 + 至多一类后置函数;额外或非法后缀被忽略/降级(避免过度堆叠带来不可预期)。
解析示例(更直观)
| 输入 metricName | 干净名 | 读函数(Read) | 后置(PP) | 说明 |
|---|---|---|---|---|
cpu.usage | cpu.usage | value | - | 无后缀 |
cpu.usage._avg | cpu.usage | avg | - | 平均聚合 |
regionserver.Server.storeFileSize._sum | regionserver.Server.storeFileSize | sum | - | 求和聚合 |
rpc.rpcdetailed.numOpen._diff._sum | rpc.rpcdetailed.numOpen | sum | diff | 先求差分,再按读函数聚合 |
hdfs.blocks_corrupt._rate | hdfs.blocks_corrupt | value | rate | 无显式读函数,退回 value |
cpu.usage._oops | cpu.usage._oops(退回原串)* | value | - | 非法后缀,读函数退回 value,且UUID 可能查不到 |
- 注意:非法后缀会保留完整串用于后续,但UUID 解析只看干净名,因此推荐统一写法(避免
_oops类后缀混入)。
# 三、示例与最小可复现请求(Grafana → API)
/ws/v1/timeline/metrics?metricNames=regionserver.Server.storeFileSize._sum&hostname=&appId=ams-hbase&instanceId=&startTime=1757893072&endTime=1757914672
将请求带入 Apifox(粒度 300 秒),时间跨度较大时返回点位会增多,这是预期行为(窗口聚合会让相邻时间戳“对齐成阶梯”)。
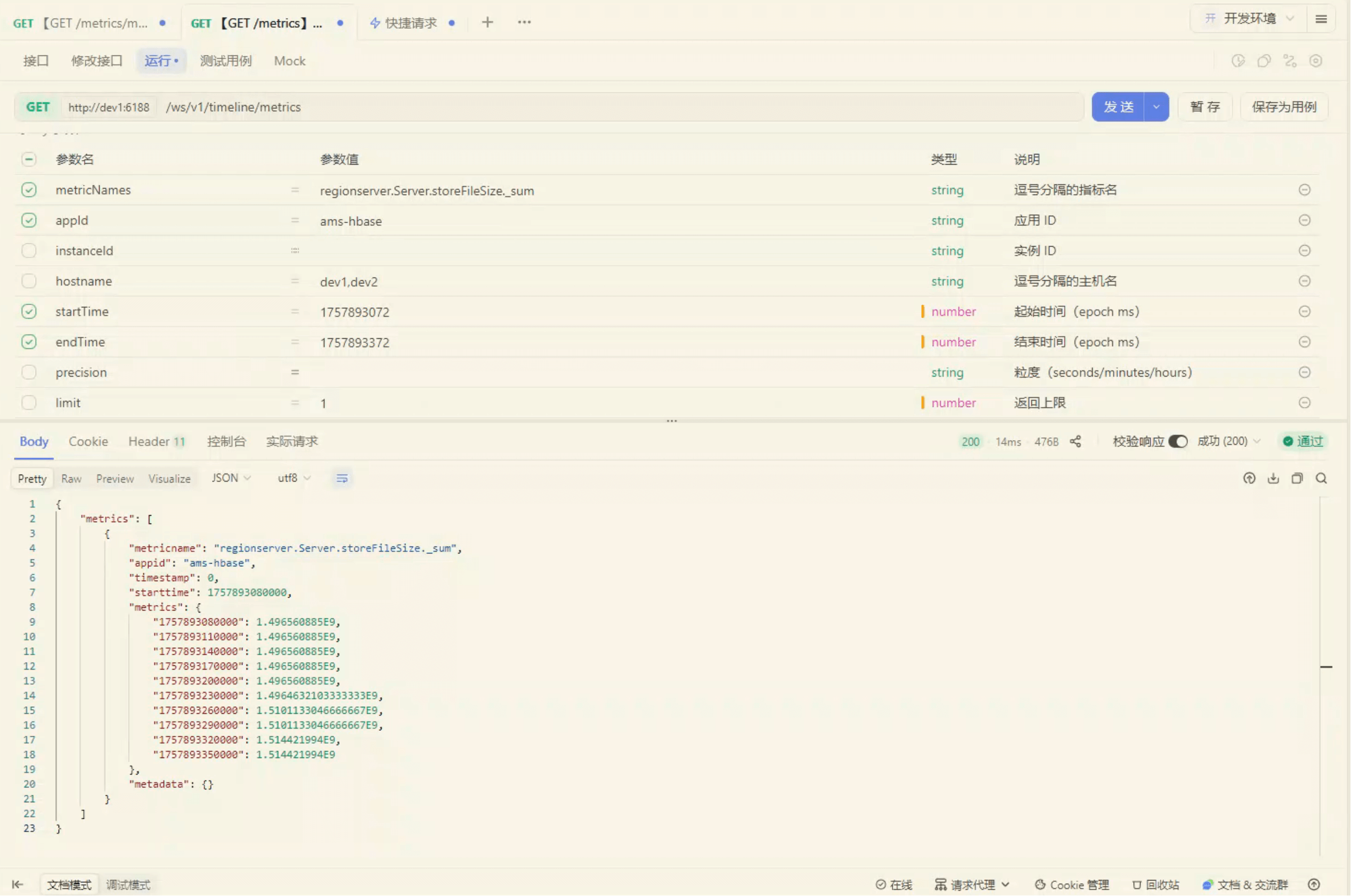
curl --location --request GET 'http://dev1:6188/ws/v1/timeline/metrics?metricNames=regionserver.Server.storeFileSize._sum&appId=ams-hbase&startTime=1757893072&endTime=1757893372' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Accept: */*' \
--header 'Host: dev1:6188' \
--header 'Connection: keep-alive'
2
3
4
5
建议的小步验证法
1)先用很短的时间窗(如 5~10 分钟)验证指标能否取到点;
2)再逐步放大时间窗,观察点位密度与聚合窗口是否与你在 Grafana 的步长一致;
3)读函数从 value 切到 sum/avg/min/max 前后,对比返回序列是否符合预期(特别是 _rate/_diff 的派生曲线)。
笔记
为了观察 5 分钟窗口的聚合效果,建议先缩短时间窗再放大查看。
常见坑位
hostname留空 → 可能返回多主机拼接的混合序列(取决于是否指定grouped/seriesAggregateFunction等);appId写错(如ams_hbasevsams-hbase)会导致UUID 命中率骤降;_sum等读函数只影响读层聚合,并不会改变UUID 匹配的维度键。
# 四、UUID:只用“干净指标名”参与匹配(函数不影响 UUID)
# 1、调用入口
List<byte[]> uuids = metricMetadataManager.getUuidsForGetMetricQuery(metricFunctions.keySet(),
hostnames,
applicationId,
instanceId,
transientMetricNames);
2
3
4
5
这里最关键:metricFunctions.keySet() 只包含“干净指标名”。也就是说,cpu.usage._avg、cpu.usage._max 都会在这里
统一成 cpu.usage 参与 UUID 匹配。
# 2、结构理解与示例
根据上一节的解析逻辑,可得到如下等价推导:
[
"cpu.usage",
"cpu.usage._avg",
"cpu.usage._max",
"rpc.rpcdetailed.numOpen._diff._sum"
]
2
3
4
5
6
解析后得到的 metricsFunctions:
key =
cpu.usage- value = [ (VALUE, NONE), (AVG, NONE), (MAX, NONE) ]
key =
rpc.rpcdetailed.numOpen- value = [ (SUM, DIFF) ]
因此:
metricsFunctions.keySet() = ["cpu.usage", "rpc.rpcdetailed.numOpen"]
说明:UUID 只看“干净指标名 + host/appId/instanceId”,后缀函数不参与 UUID 选择。
进一步说明(结合元数据缓存与通配)
- host 通配
%:不会参与 UUID 生成(UUID 的 host 维度需要具体值),通配会在后续 SQL 条件或内存过滤阶段处理。 - transientMetricNames:匹配配置中的瞬时指标模式时,可能绕过部分持久化路径(用于降低瞬时指标写入压力), 但干净名规则不变。
- 实例维度:
instanceId为空 vs. 非空,命中的是不同的 UUID 集合(同名指标在不同实例下是独立条目)。
排错口诀:命中先看四要素 cleanMetricName + hostName + appId + instanceId
后缀函数(._avg/_sum/_rate/_diff)在这里一律无关。
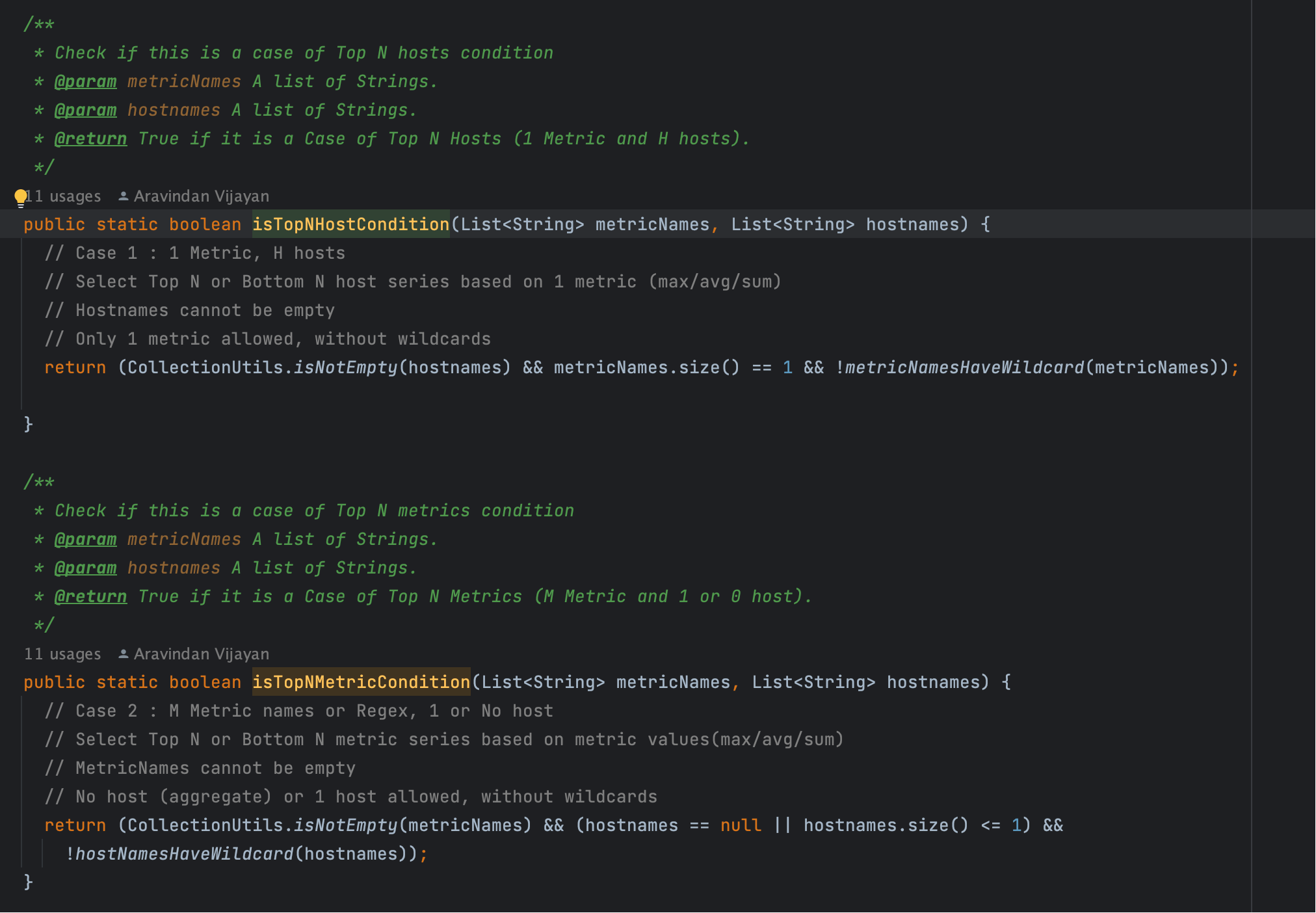
# 五、TopN:XOR 判定(Host / Metric 二选一)
最终会进入 TopN 的条件判定与应用逻辑(XOR 只允许二选一):
private void applyTopNCondition(ConditionBuilder conditionBuilder,
TopNConfig topNConfig,
List<String> metricNames,
List<String> hostnames) {
if (topNConfig != null) {
if (TopNCondition.isTopNHostCondition(metricNames, hostnames) ^ //Only 1 condition should be true.
TopNCondition.isTopNMetricCondition(metricNames, hostnames)) {
conditionBuilder.topN(topNConfig.getTopN());
conditionBuilder.isBottomN(topNConfig.getIsBottomN());
Function.ReadFunction readFunction = Function.ReadFunction.getFunction(topNConfig.getTopNFunction());
Function function = new Function(readFunction, null);
conditionBuilder.topNFunction(function);
} else {
LOG.debug("Invalid Input for TopN query. Ignoring TopN Request.");
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
# 1、TopN Host 模式
触发条件(全部满足):
- 指标数量 = 1 且不含
%; - 主机列表非空(可列表,或用
%通配)。
典型可触发参数:
metricNames = ["cpu.usage"]
hostnames = ["host1","host2","host3"] # 多主机
metricNames = ["cpu.usage"]
hostnames = ["host%"] # 主机名使用 %
2
3
4
语义:同一指标下,在主机维度做 TopN,找“表现最好/最差”的那些主机。
推荐 GET 示例
/ws/v1/timeline/metrics?metricNames=cpu.usage&hostname=host%&topN=5&topNFunction=avg&isBottomN=false
实施细节
topNFunction只接受读函数(sum/avg/min/max/value),用于比较值;isBottomN=true取“倒数 N 名”;- 若读函数非法,解析会抛异常/降级,建议只用上述白名单。
# 2、TopN Metric 模式
触发条件(全部满足):
- 指标数量 ≥ 1(可含
%); - 主机 ≤ 1(0 或 1 个),且不能含
%。
典型可触发参数:
metricNames = ["cpu.usage"] ; hostnames = []
metricNames = ["cpu.%"] ; hostnames = []
metricNames = ["cpu.usage","mem.free"] ; hostnames = []
metricNames = ["cpu.%"] ; hostnames = ["host1"]
metricNames = ["cpu.usage","mem.free"] ; hostnames = ["host1"]
2
3
4
5
语义:同一主机(或无主机聚合)下,在指标维度做 TopN,找出“数值最大/最小”的那些指标。
推荐 GET 示例
/ws/v1/timeline/metrics?metricNames=cpu.usage,mem.free&hostname=host1&topN=10&topNFunction=max&isBottomN=true
实践建议
metricNames支持%扩散,但扩散面过大时 SQL 会放大,请配合较短时间窗;- 对含
_rate/_diff的指标,不建议做 TopN(派生序列的统计意义要先确认)。
# 3、不会触发的典型情形
- 指标列表为空;
- 单指标无
%+ 单主机无%(两条件同时为真 → XOR 为假 → TopN 被忽略); - 多指标 + 多主机(两条件皆假)。
XOR 真值表(帮助快判)
| Host 条件为真 | Metric 条件为真 | XOR 结果 | 行为 |
|---|---|---|---|
| T | F | T | 触发 TopN Host |
| F | T | T | 触发 TopN Metric |
| T | T | F | 忽略 TopN(输入不合法) |
| F | F | F | 忽略 TopN(不满足任一条件) |