 [/metrics/metadata] — 元数据查询和使用GET
[/metrics/metadata] — 元数据查询和使用GET
# 一、接口定位与使用场景
我们在查什么
/ws/v1/timeline/metrics/metadata 用来“拿目录”,而不是“拿数据点”。
它回答两个问题:这个组件有哪些指标?这些指标的元属性(类型、是否支持聚合、UUID)是什么?
- 常见场景:自动补全指标、图表配置面板拉取可选指标、联调时校验指标是否被 Collector 识别并入库。
- 与数据查询接口的关系:先用本接口拿 清单,再用
/metrics或聚合接口拿 时序数据。
# 二、接口参数解析(从源码出发)
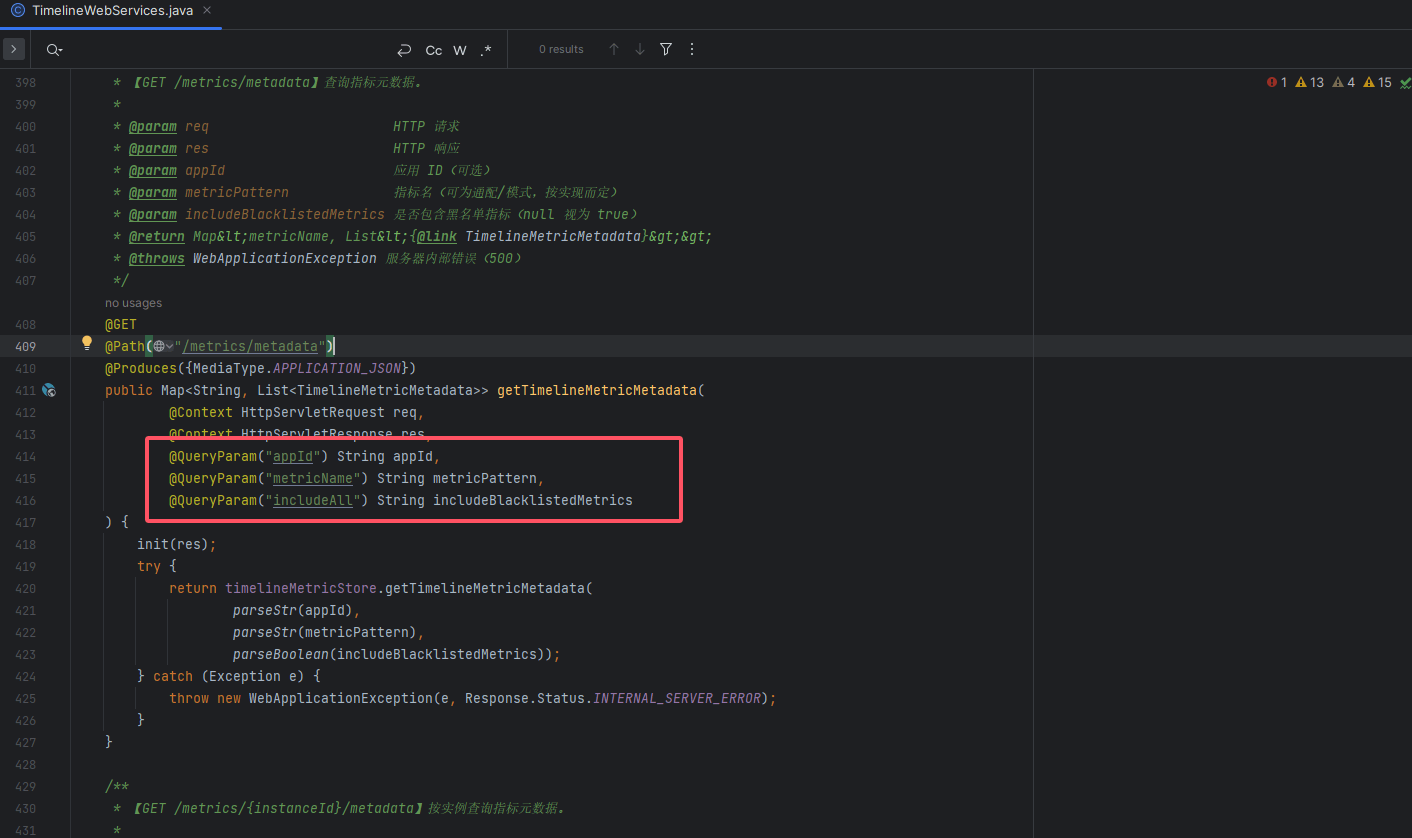
# 1. 入口方法与 QueryParam
源码位置(示意):
// TimelineWebServices.java
@GET
@Path("/metrics/metadata")
@Produces({MediaType.APPLICATION_JSON})
public Map<String, List<TimelineMetricMetadata>> getTimelineMetricMetadata(
@QueryParam("appId") String appId,
@QueryParam("metricName") String metricPattern,
@QueryParam("includeALL") String includeBlacklistedMetrics // 有些分支命名为 includeALL
) {
init(res);
try {
return timelineMetricStore.getTimelineMetricMetadata(
parseStr(appId),
parseStr(metricPattern),
parseBoolean(includeBlacklistedMetrics)
);
} catch (Exception e) {
throw new WebApplicationException(e, Response.Status.INTERNAL_SERVER_ERROR);
}
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
命名细节
部分版本/分支里参数注解为 includeALL(全大写),也常见到文档/调用中使用 includeAll。两者在实际解析层通常等价,请以你环境控制台展示为准。
# 2. 三个入参的职责
| 参数名 | 类型 | 作用与取值建议 |
|---|---|---|
appId | string | 组件名过滤。建议填具体组件(如 datanode、namenode),减少返回体体积。 |
metricName | string | 指标名过滤,支持通配(如 jvm*、dfs.namenode.*)。用于聚焦某一类指标。 |
includeALL | string/bool | 是否包含被黑名单屏蔽的指标。为空时通常等价于 true。联调阶段建议显式传入 true。 |
# 三、参数语义细化
# 1. appId 的含义(组件维度)
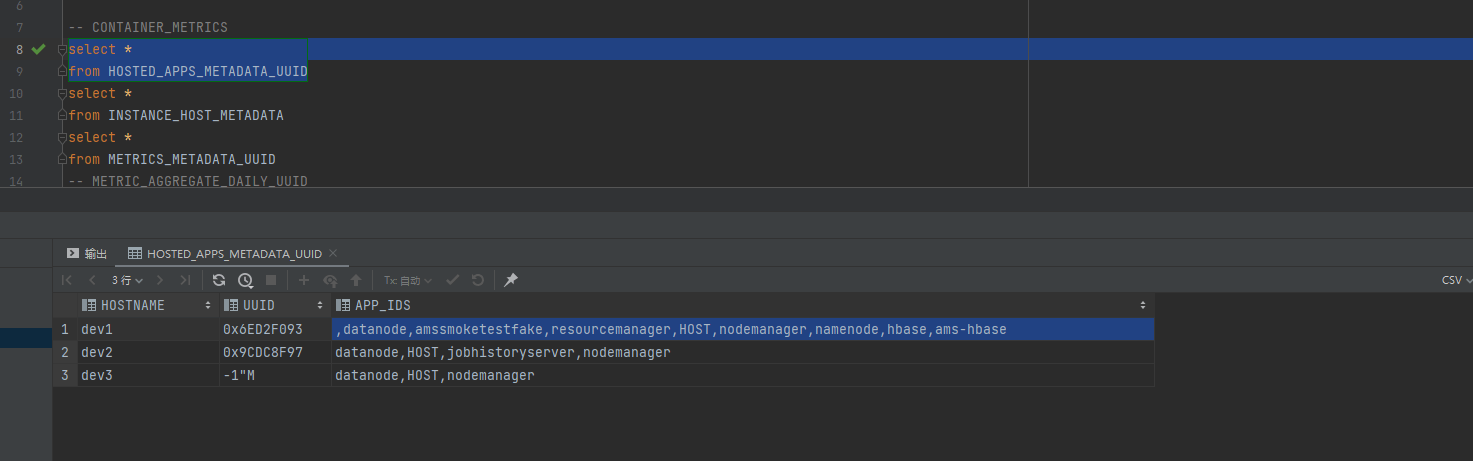
appId对应“这台主机安装了哪些组件”中的某一个组件名。- 可以把结构理解为:主机 → 组件(appId) → 指标(metricName) 的树。
# 2. metricName 的含义(指标维度)
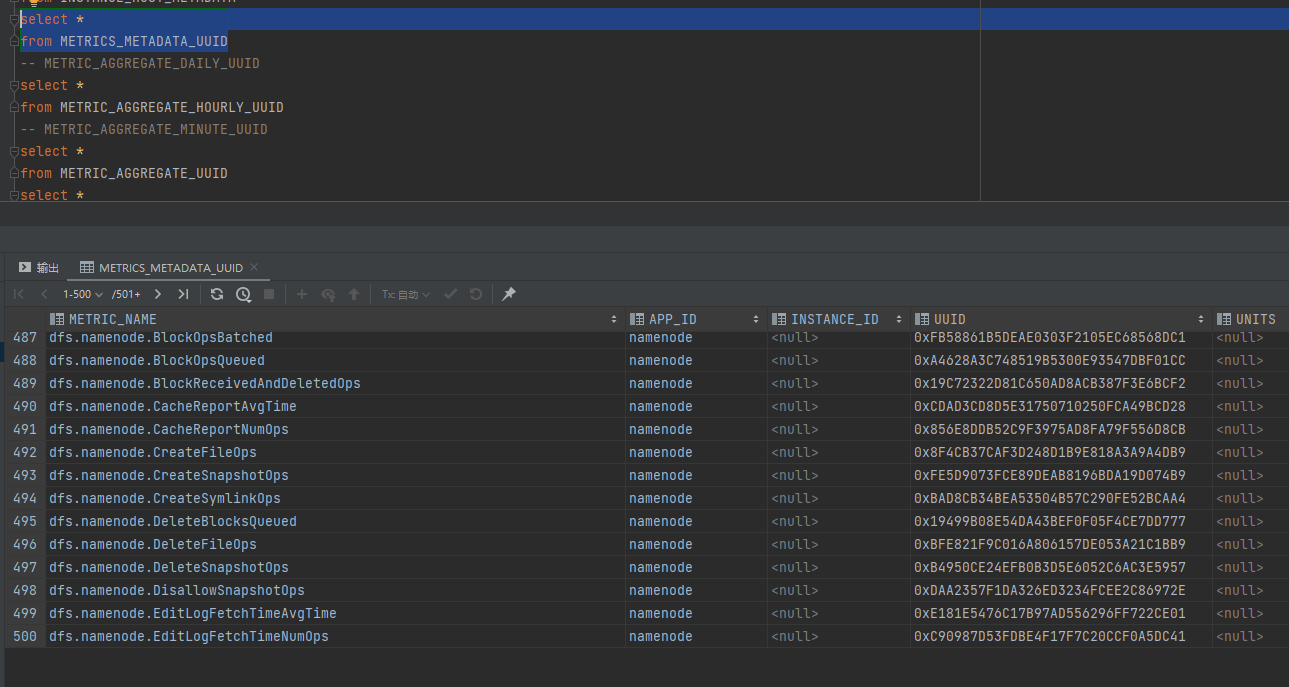
- 一般形如
模块.类别.指标,例如jvm.JvmMetrics.ThreadsTimedWaiting。 - 支持前缀/通配过滤,便于一次性抓取同类指标。
# 3. includeALL 的含义(过滤维度)
- 控制是否返回被列入黑名单的指标元数据。
- 联调/排障阶段建议传
true,可确认“因黑名单而不可见”的情况;生产环境面向前端通常保留默认行为。
# 四、一步步做:查询示例与可复制流程
# 1. 前置检查
- Collector 端口:确认
http://<collector-host>:6188可达。 - 组件存在:目标主机上确实安装并上报了
appId对应组件(如datanode)。 - 监控已上报:组件启动后等待 1~2 分钟,让元数据落库。
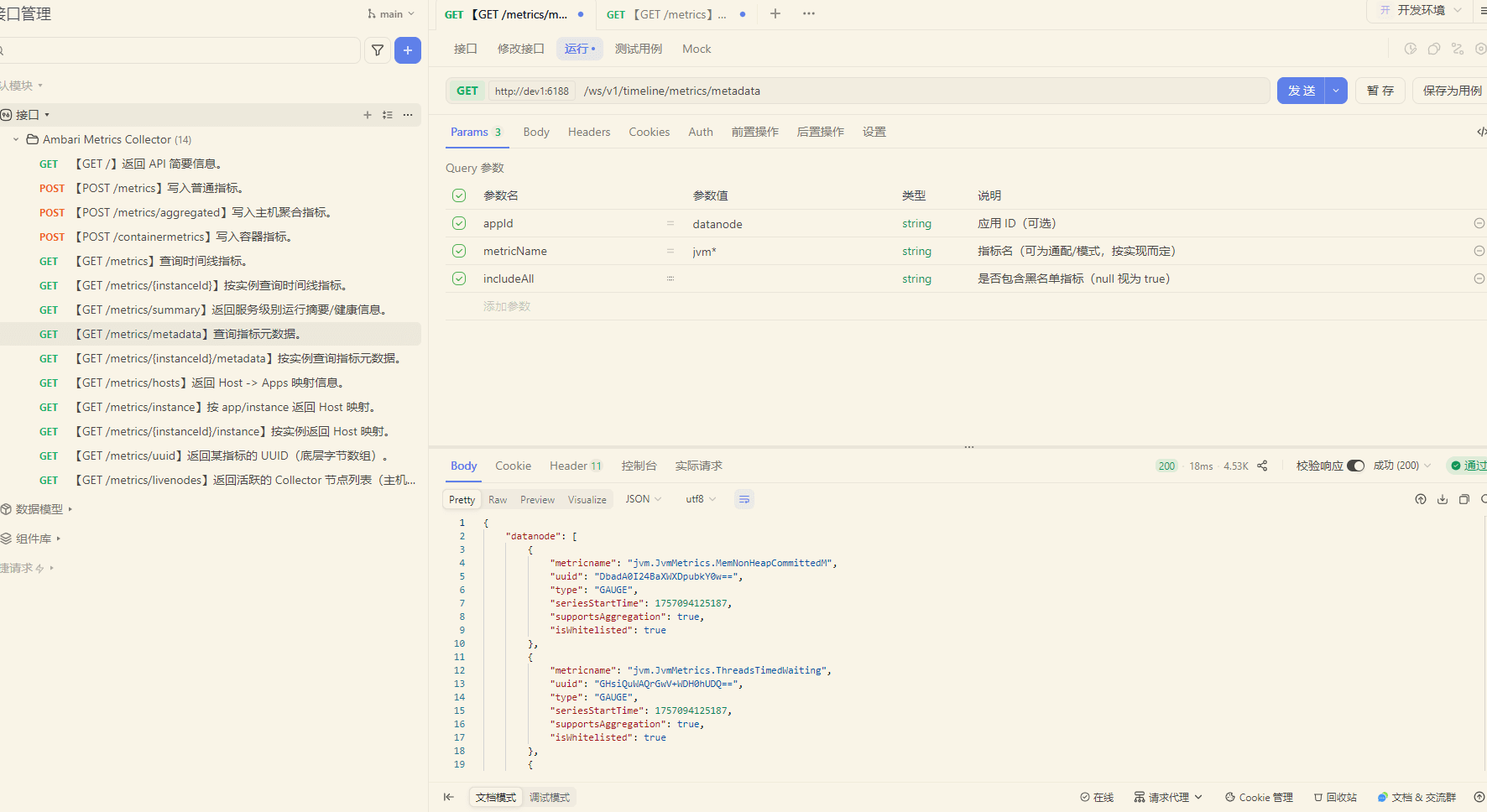
# 2. 发起请求(cURL 可直接复制)
curl --location --request GET 'http://dev1:6188/ws/v1/timeline/metrics/metadata?appId=datanode&metricName=jvm%2A&includeAll' \
--header 'User-Agent: Apifox/1.0.0 (https://apifox.com)' \
--header 'Accept: */*' \
--header 'Host: dev1:6188' \
--header 'Connection: keep-alive'
1
2
3
4
5
2
3
4
5
# 3. 期望返回与字段含义
{
"datanode": [
{
"metricname": "jvm.JvmMetrics.MemNonHeapCommittedM",
"uuid": "DbadA0I24BaXWXDpubkY0w==",
"type": "GAUGE",
"seriesStartTime": 1757094125187,
"supportsAggregation": true,
"isWhitelisted": true
},
{
"metricname": "jvm.JvmMetrics.ThreadsTimedWaiting",
"uuid": "GHsiQuWAQrGwV+WDH0hUDQ==",
"type": "GAUGE",
"seriesStartTime": 1757094125187,
"supportsAggregation": true,
"isWhitelisted": true
},
{
"metricname": "jvm.JvmMetrics.GcCountPS Scavenge",
"uuid": "4i4HdTIM/ybwM6piz34mUg==",
"type": "COUNTER",
"seriesStartTime": 1757094125187,
"supportsAggregation": true,
"isWhitelisted": true
}
]
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
| 字段 | 含义 | 备注 |
|---|---|---|
metricname | 指标名 | 建议用于界面展示与后续查询拼装 |
uuid | 指标唯一标识 | 后续写入/聚合表使用该键做主键片段 |
type | 指标类型 | GAUGE 或 COUNTER |
seriesStartTime | 首次出现时间 | 做数据窗口/补数判断 |
supportsAggregation | 是否支持聚合 | 指示能否参与分钟/小时/天级聚合 |
isWhitelisted | 是否白名单 | 配合 includeALL 理解过滤结果 |
# 4. 结果为空时怎么查
排障清单
appId是否拼写正确(大小写、下划线)。metricName过滤是否过于严格(先去掉通配再逐步收紧)。- 组件是否真的在这台主机上(可以查
HOSTED_APPS_METADATA_UUID)。 - Collector 与 HBase 是否健康(日志与端到端连通性)。
# 五、返回结构与实体映射
方法签名返回:
Map<String, List<TimelineMetricMetadata>>- Key:
appId(如datanode) - Value:该组件下的
TimelineMetricMetadata列表
- Key:
实体类位置(示意):
ambari-metrics-common/src/main/java/org/apache/hadoop/metrics2/sink/timeline/TimelineMetricMetadata.java
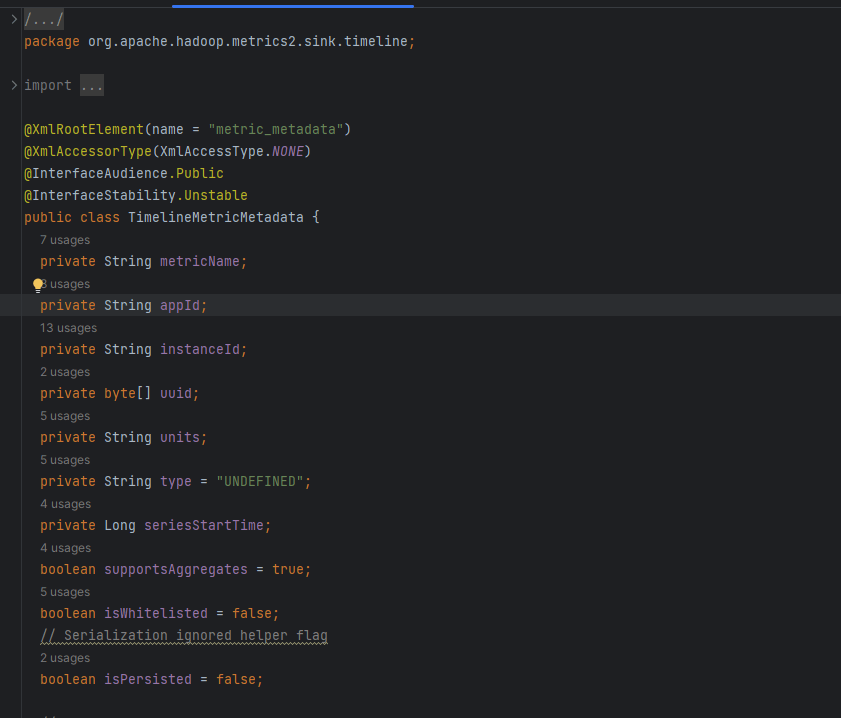
# 1. 关键字段对照
| 实体字段 | 类型 | 说明 |
|---|---|---|
metricName | String | 指标名 |
appId | String | 组件名 |
instanceId | String | 实例维度(可为空) |
uuid | byte[] | 指标的 16 字节 UUID |
units | String | 单位(可选) |
type | String | GAUGE/COUNTER |
seriesStartTime | Long | 指标出现的起点时间 |
supportsAggregates | boolean | 是否参与聚合 |
isWhitelisted | boolean | 白名单状态 |
isPersisted | boolean | 是否已持久化 |
一致性
接口 JSON、实体类字段与底层表列保持一致,便于从界面追到表、从表回看界面。
下一节介绍
我们将围绕接口,探究他的整个查询过程