 [/metrics] — 拦截非法指标写入acceptMetric
[/metrics] — 拦截非法指标写入acceptMetric
# 一、为什么需要 acceptMetric?
在 Ambari-Metrics 的 Collector 中,数据写入 HBase 前必须经过 合法性校验。
这个校验的入口就是 acceptMetric 方法。
如果不加约束,Collector 会把 所有组件、所有主机、所有指标 都采集并存储。随着集群规模增长,这会导致:
- HBase 表中产生大量无价值数据,存储成本上升;
- Collector 写入压力骤增,影响整体监控性能;
- Grafana 等前端 展示混乱,用户难以聚焦真正关心的指标。
于是,Ambari 提供了一个灵活机制:黑白名单过滤,让用户决定哪些指标值得上报。
核心思想
不是所有数据都值得存,通过 acceptMetric 过滤掉冗余指标,可以让 Collector 更轻、更快、更可控。
# 二、结论先行:acceptMetric 的设计原则
- 黑名单优先级高:匹配黑名单即直接拦截。
- 白名单控制更细:允许用户指定精确指标或通配符。
- 特殊组件例外:
ams-hbase采用“只采集白名单”逻辑。 - 默认宽松策略:若未配置名单,大多数指标允许通过。
这种设计确保了 Collector 在 默认开箱可用 与 高度可定制化 之间取得平衡。
# 三、源码全景解读
核心方法 acceptMetric 的代码如下:
public static boolean acceptMetric(TimelineMetric metric) {
String appId = metric.getAppId();
String metricName = metric.getMetricName();
// 1. 应用黑名单
if (CollectionUtils.isNotEmpty(blacklistedApps) && blacklistedApps.contains(appId)) {
return false;
}
// 2. 指标黑名单(支持通配符)
if (CollectionUtils.isNotEmpty(blacklistedMetrics) || CollectionUtils.isNotEmpty(blacklistedPatterns)) {
if (blacklistedMetrics.contains(metricName)) {
return false;
}
for (Pattern p : blacklistedPatterns) {
Matcher m = p.matcher(metricName);
if (m.find()) {
blacklistedMetrics.add(metricName);
return false;
}
}
}
// 3. ams-hbase 特殊白名单
if ("ams-hbase".equals(appId) && CollectionUtils.isNotEmpty(amshbaseWhitelist)) {
return amshbaseWhitelist.contains(metric.getMetricName());
}
// 4. 应用白名单
if (CollectionUtils.isNotEmpty(whitelistedApps) && whitelistedApps.contains(appId)) {
return true;
}
// 5. 指标白名单(若为空,则默认放行)
if (CollectionUtils.isEmpty(whitelistedMetrics) && CollectionUtils.isEmpty(whitelistedMetricPatterns)) {
return true;
}
if (whitelistedMetrics.contains(metricName)) {
return true;
}
for (Pattern p : whitelistedMetricPatterns) {
Matcher m = p.matcher(metricName);
if (m.find()) {
whitelistedMetrics.add(metricName);
return true;
}
}
return false;
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
# 逻辑拆解
- 应用黑名单 → 全拦截 避免某些应用全量噪音指标(如 MR Job 临时任务)。
- 指标黑名单 → 精确 / 模糊匹配 即使某应用通过了,也能按指标粒度再拦截。
- ams-hbase 白名单 → 仅采集定义指标 避免 HBase 自身暴露过多无意义指标。
- 应用白名单 → 快速放行 应用级控制更高效,不必逐个指标过滤。
- 指标白名单 → 精确 / 正则放行
常用于只关注某一类指标(如
cpu.*)。 - 缺省策略 → 宽松 没有白名单时,默认允许写入,保证 Collector 能跑起来。
运行机制
黑名单 → ams-hbase → 白名单 → 缺省策略 形成了一条优先级清晰的校验链。
# 四、名单初始化:Collector 启动加载逻辑
acceptMetric 的名单集合并不是运行时生成的,而是在 Collector 启动时,通过 initializeMetricFilter 方法完成初始化:
public static void initializeMetricFilter(TimelineMetricConfiguration configuration) {
...
// 加载白名单
if (configuration.isWhitelistingEnabled()) {
String whitelistFile = metricsConf.get(
TimelineMetricConfiguration.TIMELINE_METRICS_WHITELIST_FILE,
TimelineMetricConfiguration.TIMELINE_METRICS_WHITELIST_FILE_LOCATION_DEFAULT);
readMetricWhitelistFromFile(whitelistedMetrics, whitelistedMetricPatterns, whitelistFile);
}
// 加载黑名单
String blacklistFile = metricsConf.get(TIMELINE_METRICS_BLACKLIST_FILE, "");
if (!StringUtils.isEmpty(blacklistFile)) {
readMetricWhitelistFromFile(blacklistedMetrics, blacklistedPatterns, blacklistFile);
}
// 应用级名单
String appsBlacklist = metricsConf.get(TimelineMetricConfiguration.TIMELINE_METRICS_APPS_BLACKLIST, "");
...
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20

Collector 会从 ams-site.xml 中读取文件路径与应用名单,完成内存初始化。
# 五、配置文件实战
在 ams-site.xml 中,可以配置三类清单:
# 1. 应用名单
<property>
<name>timeline.metrics.apps.whitelist</name>
<value>HDFS,HBASE</value>
</property>
<property>
<name>timeline.metrics.apps.blacklist</name>
<value>SPARK,MAPREDUCE</value>
</property>
2
3
4
5
6
7
8
9
10

# 2. 指标白名单
<property>
<name>timeline.metrics.whitelist.file</name>
<value>/etc/ambari-metrics-collector/conf/metrics_whitelist</value>
</property>
2
3
4
5
若未配置,默认路径为:
/etc/ambari-metrics-collector/conf/metrics_whitelist
# 3. 指标黑名单
<property>
<name>timeline.metrics.blacklist.file</name>
<value>/etc/ambari-metrics-collector/conf/metrics_blacklist</value>
</property>
2
3
4
5
黑名单没有默认值,必须显式配置。
# 4. ams-hbase 特殊清单

配置路径:amshbase_metrics_whitelist 文件。
写法:每行一个指标名。
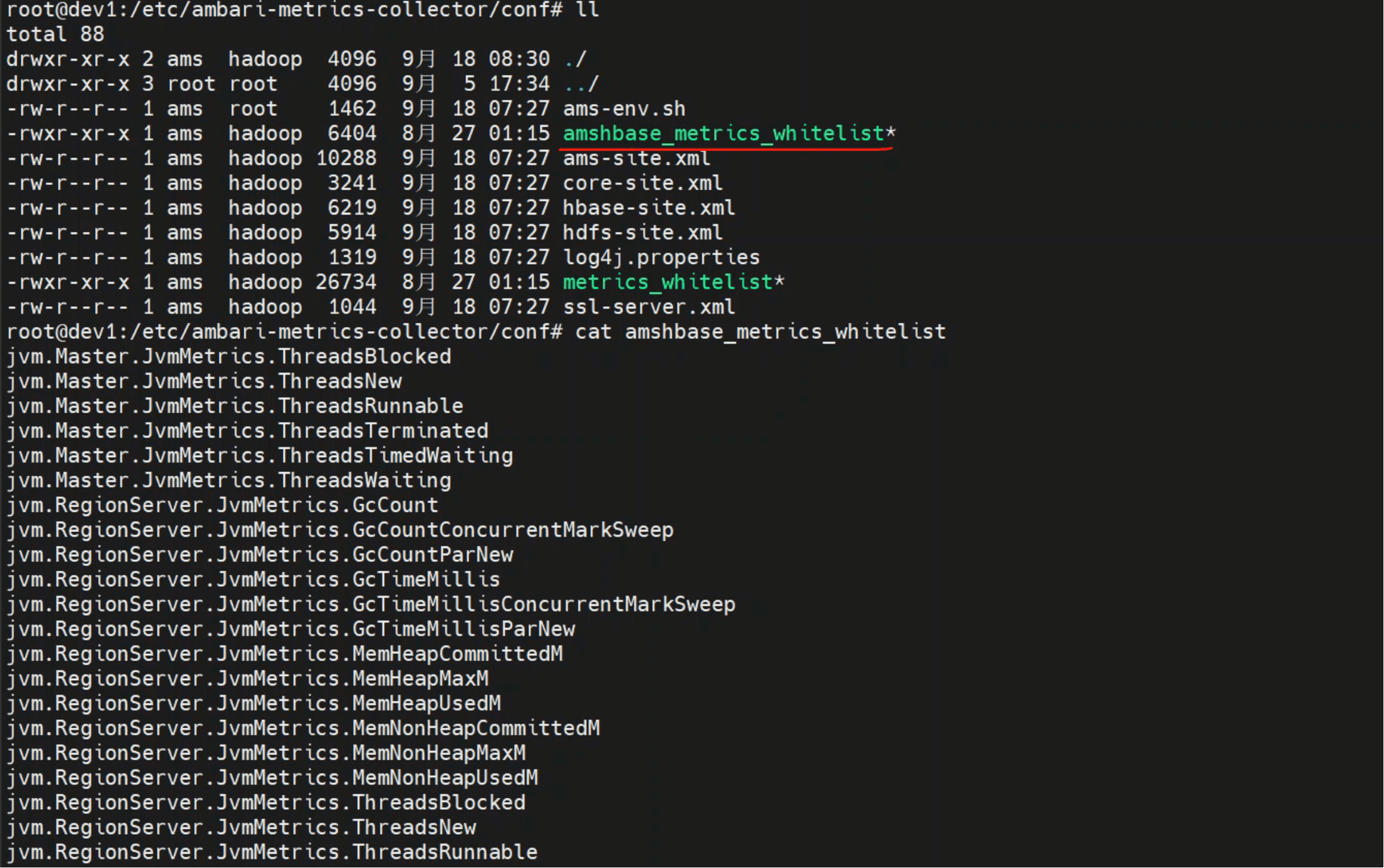
代码对应:
if ("ams-hbase".equals(appId) && CollectionUtils.isNotEmpty(amshbaseWhitelist)) {
return amshbaseWhitelist.contains(metric.getMetricName());
}
2
3
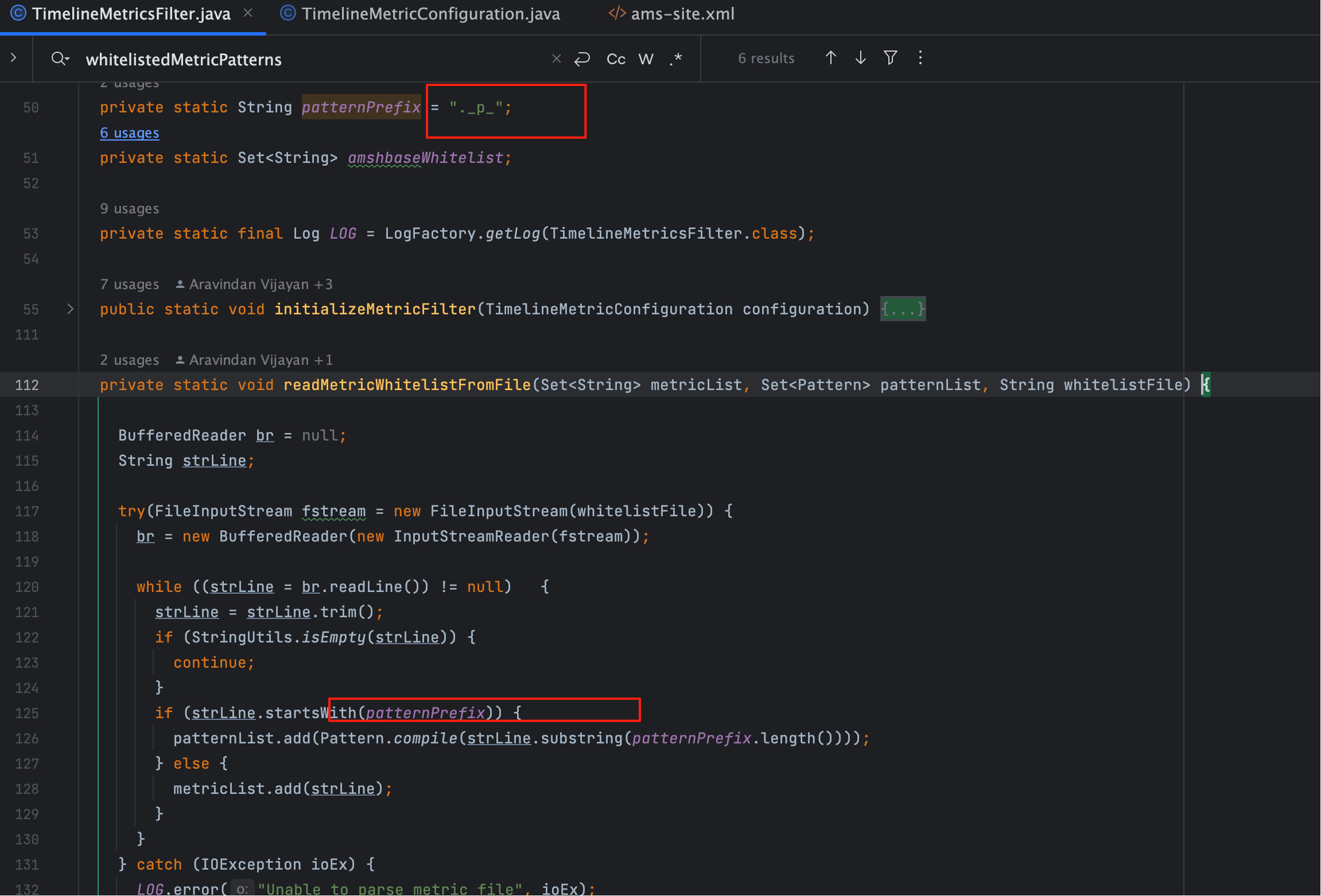
# 六、通配符机制
名单文件支持通配符,通过 ._p_ 前缀触发正则模式:
._p_kafka.log.Log.*
源码:
if (strLine.startsWith(patternPrefix)) {
patternList.add(Pattern.compile(strLine.substring(patternPrefix.length())));
} else {
metricList.add(strLine);
}
2
3
4
5
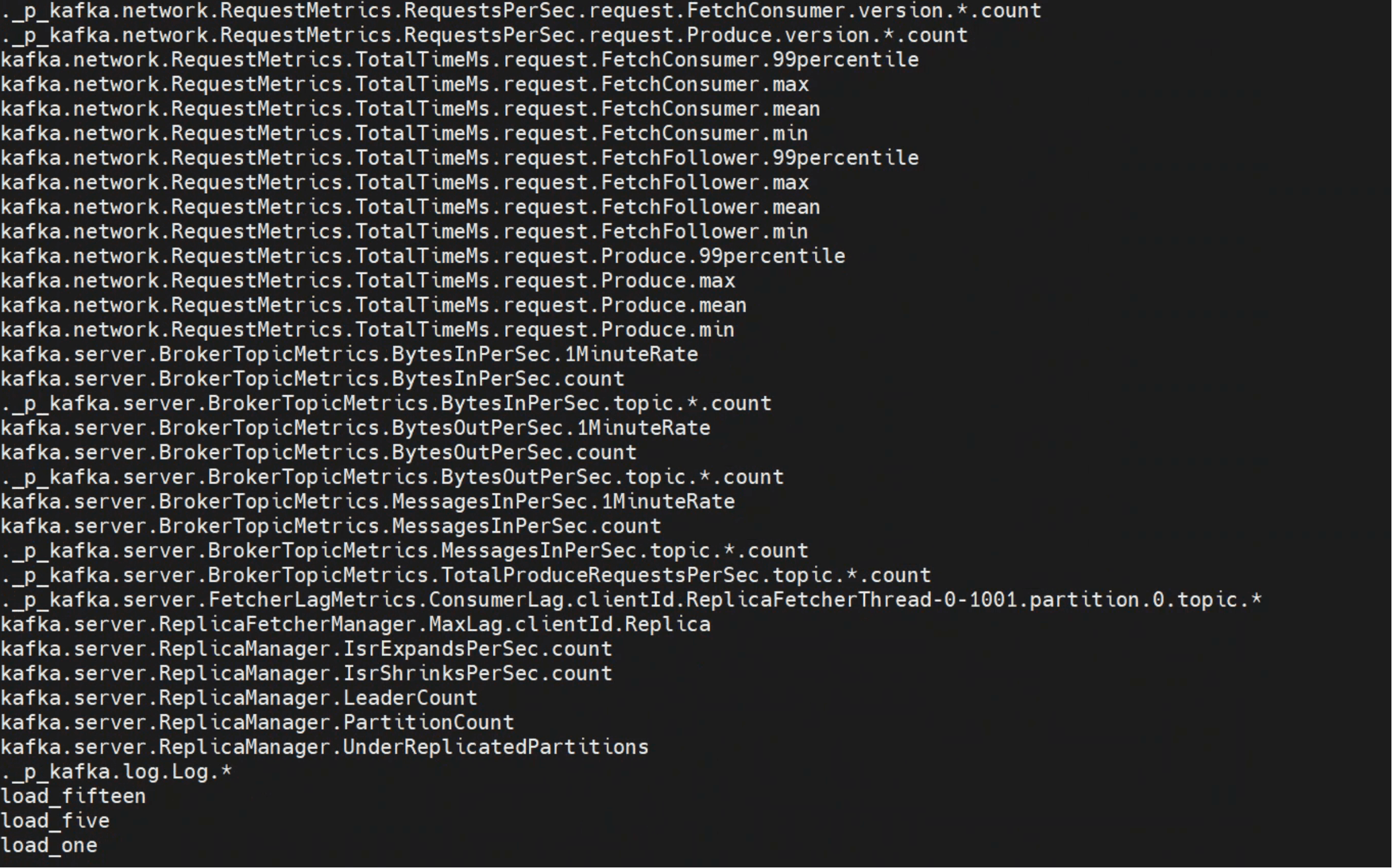
举例:
定义 ._p_kafka.log.Log.* 后,凡是匹配该正则的指标,都会动态补充到名单,并立即生效。
注意
通配符是 正则表达式,使用不当可能误拦截大量指标。 建议先在测试环境验证。
# 七、运行时动态效果
结合前文逻辑,当一个新指标进入 Collector 时:
- 先查应用黑名单 → 如果命中直接丢弃;
- 再查指标黑名单 → 若正则匹配上,立即加入黑名单缓存;
- ams-hbase 特例 → 只有白名单里的才能通过;
- 白名单判定 → 命中即放行,未配置白名单时默认全放行。
这个过程在高并发写入场景下执行非常快,因为:
- 名单在内存中维护
HashSet/Pattern; - 正则匹配命中后,会 缓存结果,避免下次重复计算。