 启动脚本链接Python&Java
启动脚本链接Python&Java
# 一、Collector 启动脚本的入口 📂
Ambari-Metrics Collector 的启动逻辑集中在以下文件:
ambari-metrics-timelineservice/conf/unix/ambari-metrics-collector
1
笔记
这个脚本通常由 ams 用户 执行,负责 Collector 的初始化逻辑。它不仅仅是调用 Java,而是包含了环境准备、依赖判断、参数拼接和后台进程守护。
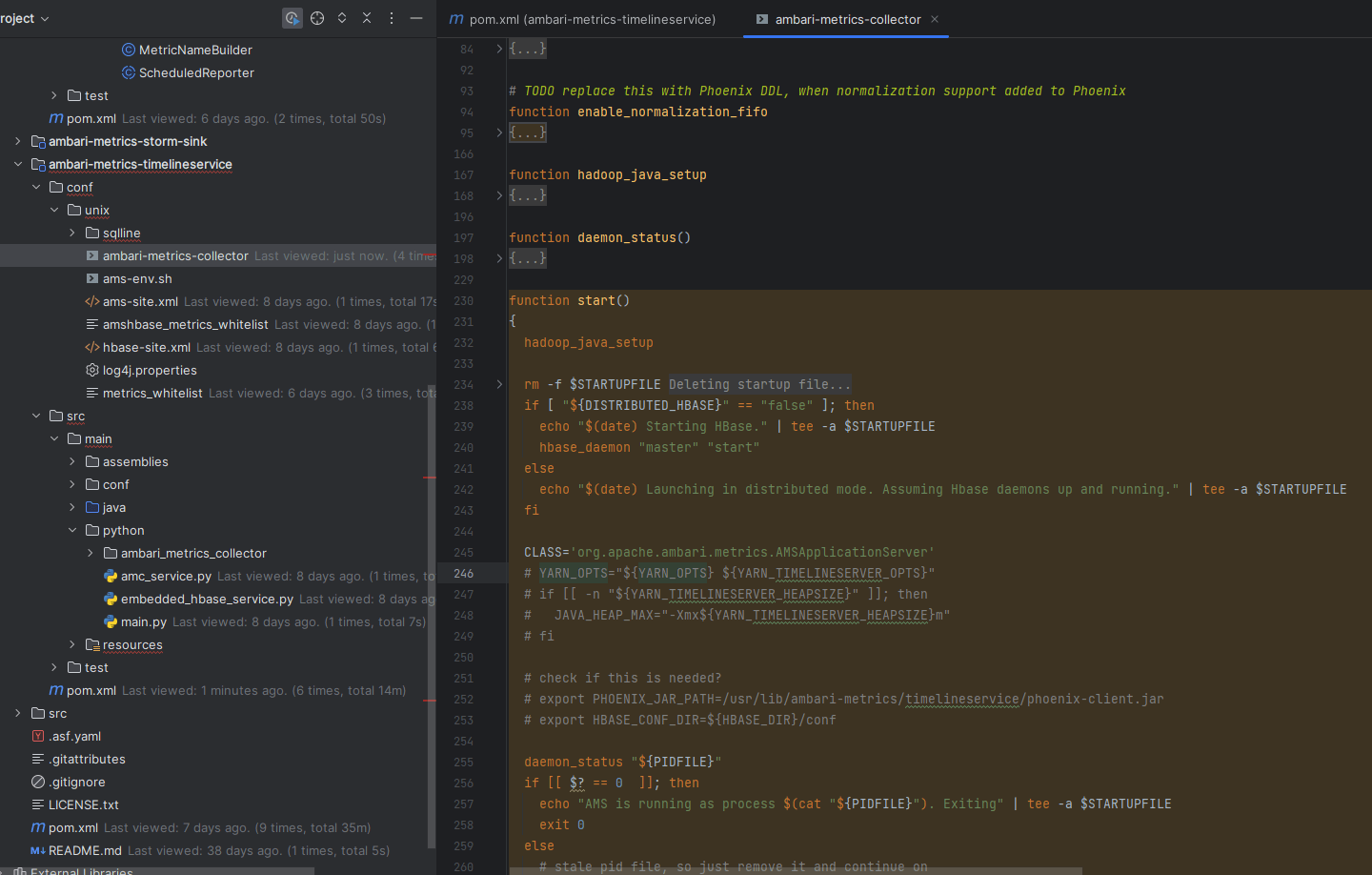
# 二、start() 函数的执行流程 🔍
脚本中 start() 方法的关键步骤如下:
| 步骤 | 动作 | 说明 |
|---|---|---|
| 1️⃣ | hadoop_java_setup | 初始化 Hadoop 与 JDK 环境变量,保证 Java 可用 |
| 2️⃣ | hbase_daemon | 根据模式决定是否启动本地 HBase,Collector 依赖存储层 |
| 3️⃣ | 设置 CLASS | 入口类 → AMSApplicationServer |
| 4️⃣ | daemon_status | 检查 PID 文件,防止 Collector 重复拉起 |
| 5️⃣ | nohup java ... & | 最终触发 Java 主类,Collector 真正被启动 |
提示
前 4 步主要是准备和检查,真正的“点火”动作在 nohup java ... 这一行。
此外,脚本中还包含一个初始化 HBase 表模型的循环检查,通过 hbase shell 验证 METRIC_* 表是否建好,避免 Collector 起不来但
UI 无法提示的尴尬场景。
注意
如果集群启用了 分布式 HBase,脚本不会帮你自动启动 HBase,需要保证外部 HBase 已经可用,否则 Collector 初始化时会失败。
# 三、点火命令的全貌 🚀
当执行 start() 时,脚本最终会拼接出一个庞大的 Java 启动命令。这正是 Collector 的真正入口:
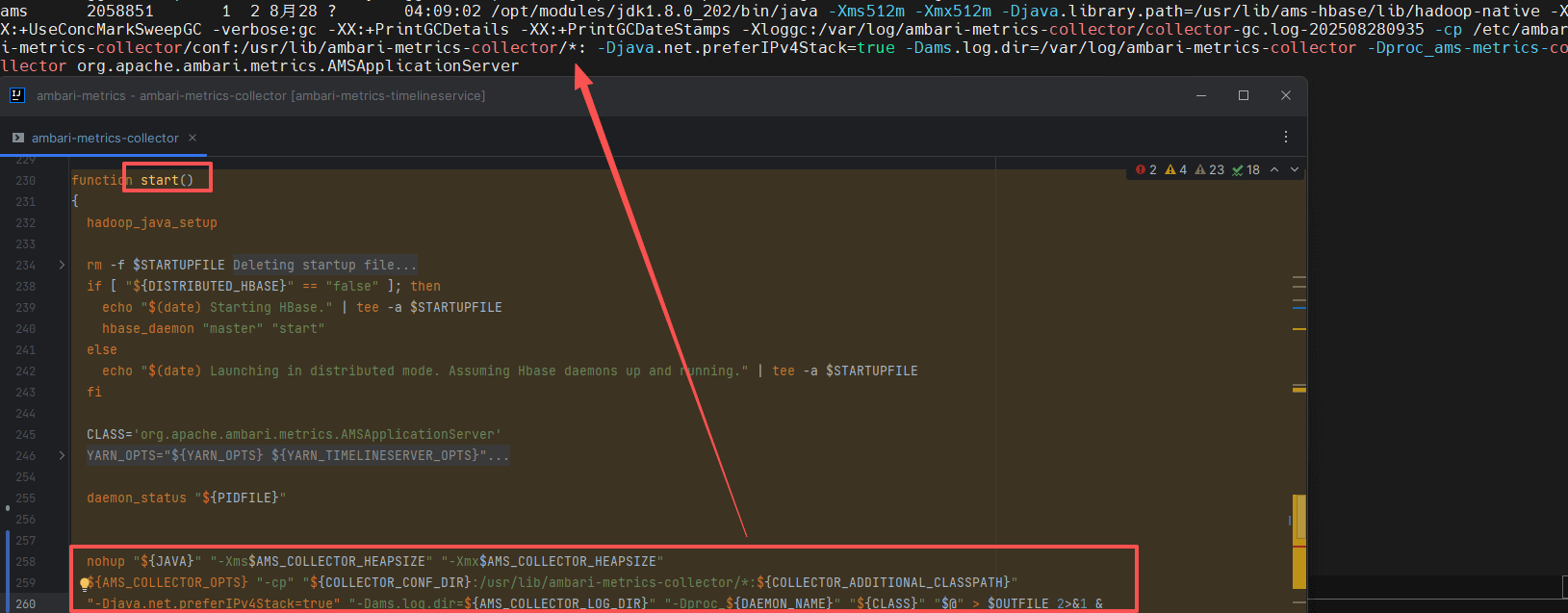
/opt/modules/jdk1.8.0_202/bin/java \
-Xms512m -Xmx512m \
-Djava.library.path=/usr/lib/ams-hbase/lib/hadoop-native \
-XX:+UseConcMarkSweepGC \
-verbose:gc -XX:+PrintGCDetails -XX:+PrintGCDateStamps \
-Xloggc:/var/log/ambari-metrics-collector/collector-gc.log-202508280935 \
-cp /etc/ambari-metrics-collector/conf:/usr/lib/ambari-metrics-collector/*: \
-Djava.net.preferIPv4Stack=true \
-Dams.log.dir=/var/log/ambari-metrics-collector \
-Dproc_ams-metrics-collector \
org.apache.ambari.metrics.AMSApplicationServer
1
2
3
4
5
6
7
8
9
10
11
2
3
4
5
6
7
8
9
10
11
# 参数逐项解读 🧩
| 参数 | 含义 |
|---|---|
-Xms/-Xmx | JVM 堆大小,取自 ${AMS_COLLECTOR_HEAPSIZE} |
-Djava.library.path | 指定 hadoop-native 的动态库路径,涉及 Snappy 等本地依赖 |
-XX:+UseConcMarkSweepGC | Collector 长期运行推荐的 GC 策略 |
-verbose:gc -XX:+PrintGC* | 输出 GC 日志,方便排查内存问题 |
-Xloggc | GC 日志文件路径 |
-cp | Classpath,覆盖配置目录与 Collector 所有 jar |
-Dams.log.dir | Collector 的日志路径 |
-Dproc_ams-metrics-collector | 给进程一个唯一标签,方便 jps 查询 |
| 主类 | AMSApplicationServer → Collector 核心 Java 入口 |
提示
-Dproc_ams-metrics-collector 的作用是让 jps 输出结果更清晰,方便运维快速识别 Collector 进程。
# 四、完整的 start() 脚本解析 📜
以下为完整的 start() 函数代码,可以对照逐段理解:
function start()
{
hadoop_java_setup
rm -f $STARTUPFILE #Deleting startup file
# hbase_daemon "zookeeper" "start"
# hbase_daemon "master" "start"
# hbase_daemon "regionserver" "start"
if [ "${DISTRIBUTED_HBASE}" == "false" ]; then
echo "$(date) Starting HBase." | tee -a $STARTUPFILE
hbase_daemon "master" "start"
else
echo "$(date) Launching in distributed mode. Assuming Hbase daemons up and running." | tee -a $STARTUPFILE
fi
CLASS='org.apache.ambari.metrics.AMSApplicationServer'
# YARN_OPTS="${YARN_OPTS} ${YARN_TIMELINESERVER_OPTS}"
# if [[ -n "${YARN_TIMELINESERVER_HEAPSIZE}" ]]; then
# JAVA_HEAP_MAX="-Xmx${YARN_TIMELINESERVER_HEAPSIZE}m"
# fi
# check if this is needed?
# export PHOENIX_JAR_PATH=/usr/lib/ambari-metrics/timelineservice/phoenix-client.jar
# export HBASE_CONF_DIR=${HBASE_DIR}/conf
daemon_status "${PIDFILE}"
if [[ $? == 0 ]]; then
echo "AMS is running as process $(cat "${PIDFILE}"). Exiting" | tee -a $STARTUPFILE
exit 0
else
# stale pid file, so just remove it and continue on
rm -f "${PIDFILE}" >/dev/null 2>&1
fi
nohup "${JAVA}" "-Xms$AMS_COLLECTOR_HEAPSIZE" "-Xmx$AMS_COLLECTOR_HEAPSIZE" ${AMS_COLLECTOR_OPTS} "-cp" "${COLLECTOR_CONF_DIR}:/usr/lib/ambari-metrics-collector/*:${COLLECTOR_ADDITIONAL_CLASSPATH}" "-Djava.net.preferIPv4Stack=true" "-Dams.log.dir=${AMS_COLLECTOR_LOG_DIR}" "-Dproc_${DAEMON_NAME}" "${CLASS}" "$@" > $OUTFILE 2>&1 &
PID=$!
write_pidfile "${PIDFILE}"
sleep 2
echo "Verifying ${METRIC_COLLECTOR} process status..." | tee -a $STARTUPFILE
if [ -z "`ps ax | grep -w ${PID} | grep AMSApplicationServer`" ]; then
if [ -s ${OUTFILE} ]; then
echo "ERROR: ${METRIC_COLLECTOR} start failed. For more details, see ${OUTFILE}:" | tee -a $STARTUPFILE
echo "===================="
tail -n 10 ${OUTFILE}
echo "===================="
else
echo "ERROR: ${METRIC_COLLECTOR} start failed" | tee -a $STARTUPFILE
rm -f ${PIDFILE}
fi
echo "Collector out at: ${OUTFILE}" | tee -a $STARTUPFILE
exit -1
fi
echo "$(date) Collector successfully started." | tee -a $STARTUPFILE
if [[ "${AMS_HBASE_INIT_CHECK_ENABLED}" == "true" || "${AMS_HBASE_INIT_CHECK_ENABLED}" == "True" ]]
then
echo "$(date) Initializing Ambari Metrics data model" | tee -a $STARTUPFILE
start=$SECONDS
# Wait until METRIC_* tables created
# Wait for 10 tries or 5 minutes whichever comes first
for retry in {1..10}
do
echo 'list' | ${HBASE_CMD} --config ${HBASE_CONF_DIR} shell 2> /dev/null | grep ^${METRIC_TABLES[0]} > /dev/null 2>&1
if [ $? -eq 0 ]; then
echo "$(date) Ambari Metrics data model initialization completed." | tee -a $STARTUPFILE
break
fi
echo "$(date) Ambari Metrics data model initialization check $retry" | tee -a $STARTUPFILE
duration=$(( SECONDS - start ))
if [ $duration -gt 300 ]; then
echo "$(date) Ambari Metrics data model initialization timed out" | tee -a $STARTUPFILE
break
fi
sleep 5
done
if [ $? -ne 0 ]; then
echo "WARNING: Ambari Metrics data model initialization failed."
>&2 echo "WARNING: Ambari Metrics data model initialization failed."
fi
else
echo "$(date) Skipping Ambari Metrics data model initialization" | tee -a $STARTUPFILE
fi
}
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
# 脚本亮点
- PID 文件治理:避免“僵尸 pid”导致误判运行状态
- 后台守护:通过
nohup+&保证进程与终端解耦 - 自恢复检查:Collector 起不来时,脚本会直接 tail 最后 10 行日志给出错误提示
笔记
AMS_HBASE_INIT_CHECK_ENABLED=true 时,脚本会主动检查并等待 HBase 表初始化完成,最长约 5 分钟。
警告
常见错误场景:
- PID 文件未清理 → 导致“已运行”误报;
- 日志/目录权限不足 → 启动直接失败;
- Classpath 缺失 jar →
ClassNotFoundException; - 本地库冲突 →
UnsatisfiedLinkError;
# 五、Shell 与 Java 的衔接关系 🪢
提示
如果需要进一步排查 Collector 运行情况,可以使用:
ps -ef | grep AMSApplicationServer查看进程lsof -p <pid>确认依赖 jar 是否加载完整tail -f /var/log/ambari-metrics-collector/ambari-metrics-collector.log观察启动过程
整个链路可以总结为:
flowchart TD
A[start() Shell 函数] --> B[环境初始化]
B --> C[拼装 CLASS=AMSApplicationServer]
C --> D[PID 检查与清理]
D --> E[nohup java ...]
E --> F[AMSApplicationServer.main()]
1
2
3
4
5
6
2
3
4
5
6
- Shell:主要负责环境准备、参数拼接和后台守护
- Java:主类
AMSApplicationServer才是真正执行 Collector 初始化、表结构检查和服务启动的载体
下一节预告
Java 进程已经被拉起,但你是否好奇 —— 它是如何一步步进入主类并启动的呢?
下一篇我们就来深挖这个过程。