 Spark 安装1.0.0+
Spark 安装1.0.0+
# 基于 Ambari 安装 Spark 服务
在本篇文章中,我们将带领大家通过 Ambari 来安装和配置 Spark 服务。Ambari 提供了一个简洁的界面来管理 Spark 服务的安装、配置和监控,使用它来进行 Spark 安装将大大简化复杂的操作。以下是详细步骤。
# 1. 进入首页
首先,我们需要登录到 Ambari 的管理界面。进入 Ambari 后,点击左侧导航栏中的三个点,弹出菜单中选择 Add Service 按钮。
提示
此时你可以看到各个服务的安装选项,在这里我们选择 Spark 来开始安装。点击 Next 继续。

# 2. 选择 Spark 服务
在弹出的窗口中,我们需要选择 Spark 服务,点击选择后,点击 Next 继续。
注意
确保选择了 Spark 服务,并注意选择与其他服务的兼容性。例如,Spark 依赖于 YARN 和 HDFS 服务,因此需要确保这些服务已安装并正常运行。

# 3. 配置 Spark History Server
在此步骤中,系统将提示你配置 Spark History Server。我们建议将 Spark History Server 部署在单一节点上,以便集中管理日志信息。这里我们选择了 hadoop1,也可以根据需要选择其他节点。
提示
下方的加号可以选择多个节点部署多个 History Server,但在大多数情况下,部署一个即可满足需求。多个 History Server 部署通常没有太大意义。

# 4. 配置 Spark 客户端
为了确保集群中每个节点都能够访问 Spark 服务,建议每个节点都勾选 Spark Thrift Server 和 Client。
注意
确保 Spark Thrift Server 和 Client 被选择,避免在使用过程中其他节点无法访问 Spark 服务。这样可以确保所有节点都能够与 Spark 服务进行交互。

# 5. 配置页面
接下来,我们进入了 Spark 的配置页面。您可以根据实际需求调整相关配置。常见的配置包括 Spark Eventlog Directory 和 Spark History FS Log Directory,您可以选择使用 HDFS 来存储日志数据。点击 Next 继续。
提示
这里推荐将 Spark Eventlog Directory 设置为 hdfs:///spark-history/,以便于集中管理所有 Spark 作业的日志。

# 6. 预览安装
在预览页面,我们可以看到 Spark 服务的安装配置。确认无误后,点击 Deploy 按钮开始部署。
警告
在点击 Deploy 前,请确保所有节点的配置已经正确填写,特别是服务分配和存储路径等。错误的配置可能导致 Spark 服务无法正常启动。

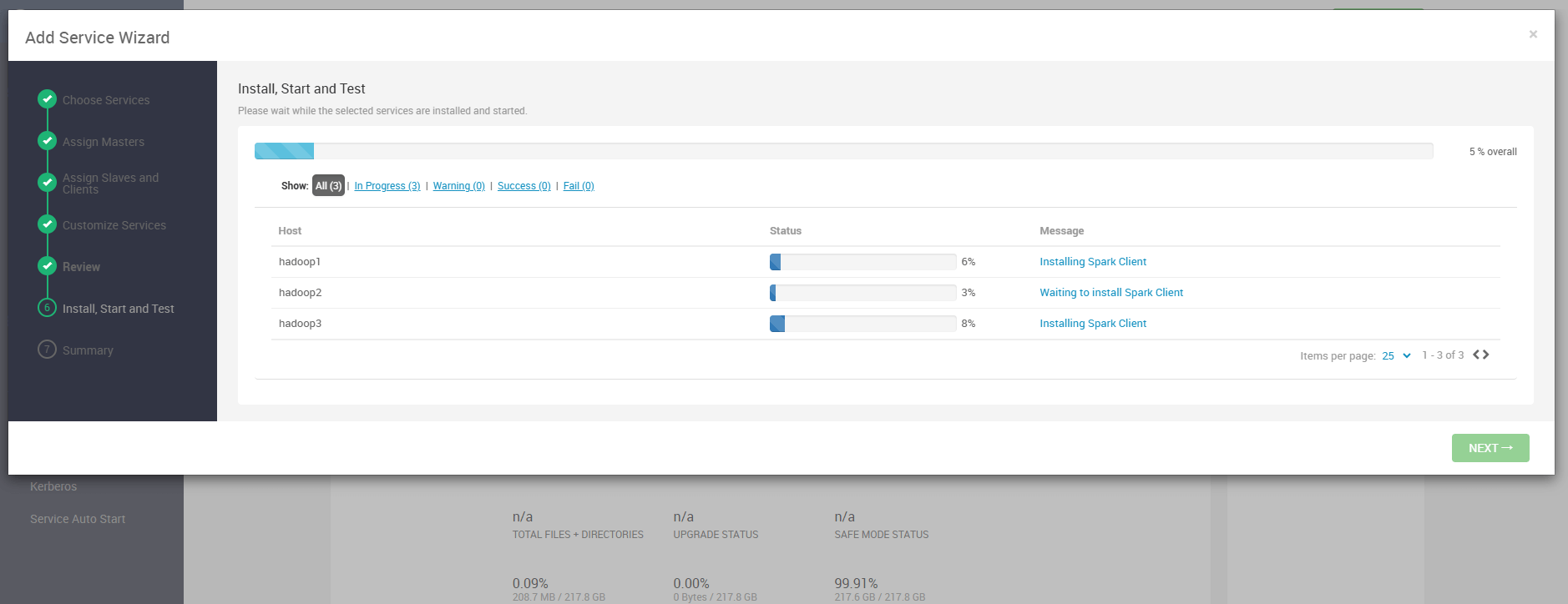
# 7. 部署过程
此时,系统开始安装和启动 Spark 服务。安装过程可能需要一些时间,视集群规模而定。请耐心等待,并在过程中观察各个节点的安装状态。
提示
如果遇到问题,可以检查日志,或者回到 Ambari 管理页面查看详细的错误信息,确保安装过程顺利进行。
# 8. 安装完成
当所有服务安装并启动完毕后,你会看到安装成功的页面,表示 Spark 服务已成功部署并可以开始使用。
笔记
安装完成后,您可以在 Ambari 管理界面中查看 Spark 服务的状态。如果服务显示为 Started,则表示安装成功。

# 9. 访问 Spark 服务
安装完成后,你可以返回到 Ambari 首页,看到 Spark 服务已经被成功安装和启动。你还可以点击右侧的超链接,直接访问 Spark History Server 的 Web UI。
提示
你可以通过以下链接访问 Spark History Server UI:http://<your-ambari-server>:18081/?showIncomplete=true。

# 10. 验证 Spark 服务
你可以通过访问以下 URL 或者点击右侧的链接来验证 Spark 服务是否安装成功:
http://192.168.3.1:18081/?showIncomplete=true
提示
确保 Spark 作业和历史日志能够正常显示。如果你看到作业历史页面和执行日志,表示安装成功。
