 Step15-Scripts-执行逻辑
Step15-Scripts-执行逻辑
# 1. 结构理念与自动化运行策略
Redis 集群集成方案强调三层分工:主节点、从节点、客户端。通过自动化脚本,批量实现服务分层管理、反亲和主从调度与集群自愈。
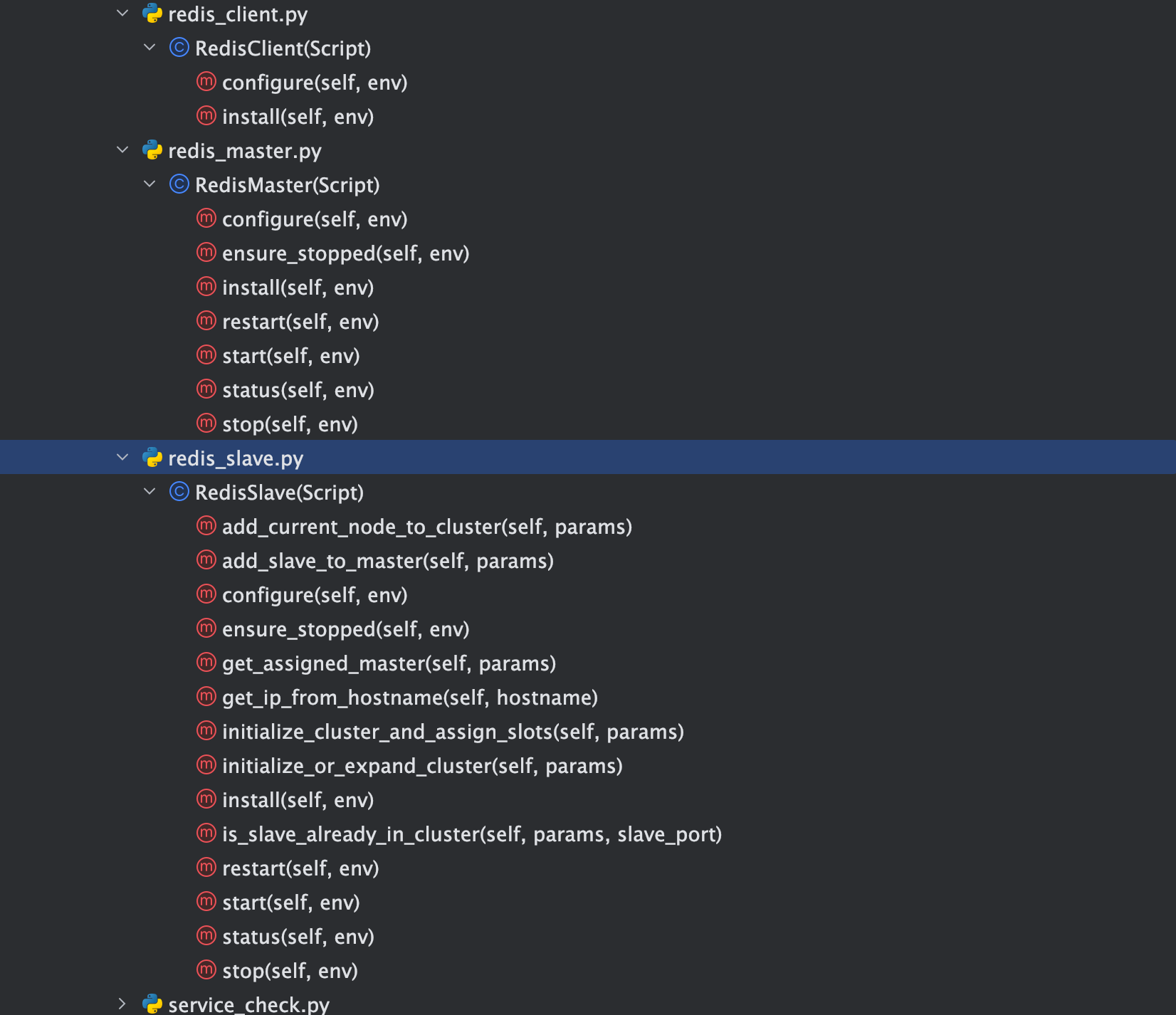
# 2. redis_client.py:客户端脚本
# 2.1 设计目标与核心实现
客户端角色以极简无状态为原则,只负责部署 redis-cli 工具等依赖包,无需守护进程、启动、停止或配置管理。这样做最大程度减少了运维复杂度,并支持大规模批量推送。
# 主要方法
class RedisClient(Script):
def install(self, env):
Logger.info("Installing Redis Client...")
self.install_packages(env)
Logger.info("Redis Client installation completed.")
def configure(self, env):
Logger.info("Redis Client does not require configuration.")
# start/stop/status 均为空实现
1
2
3
4
5
6
7
8
9
2
3
4
5
6
7
8
9
- install 负责调用环境自带的依赖包安装函数,保障 cli 工具包随需分发。
- configure/start/stop/status 均为“占位符”,仅记录日志说明客户端本身不涉及服务进程与配置,避免复杂性。
- 这样,客户端既不产生多余资源消耗,也不会和服务端逻辑耦合,非常适合各种调试、监控和工具化场景。
# 2.2 完整代码
# coding=utf-8
# redis_client.py manages the Redis Client component in Ambari.
from resource_management.core.logger import Logger
from resource_management.libraries.script.script import Script
class RedisClient(Script):
def install(self, env):
"""
安装 Redis 客户端包
"""
Logger.info("Installing Redis Client...")
self.install_packages(env)
Logger.info("Redis Client installation completed.")
def configure(self, env):
"""
Redis 客户端不需要特定的配置。
"""
Logger.info("Redis Client does not require configuration.")
#
# def start(self, env):
# """
# Redis 客户端不需要启动命令。
# """
# Logger.info("Redis Client does not have a start command, as it is only a client.")
#
# def stop(self, env):
# """
# Redis 客户端不需要停止命令。
# """
# Logger.info("Redis Client does not have a stop command, as it is only a client.")
#
# def status(self, env):
# """
# Redis 客户端没有状态检查。
# """
# Logger.info("Redis Client does not have a status check, as it is only a client.")
if __name__ == "__main__":
RedisClient().execute()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
# 3. redis_master.py:主节点脚本
# 3.1 设计目标
主节点的定位很明确:专注本地 Redis 服务进程的全生命周期管理。所有参数都由 Ambari 配置中心自动注入,所有操作均和本地 Redis 服务进程绑定。
# 3.2 关键方法分解
# 安装与配置
def install(self, env):
self.install_packages(env)
self.configure(env)
def configure(self, env):
import params
env.set_params(params)
Directory([params.redis_log_dir, params.redis_data_dir, params.redis_pid_dir],
owner=params.redis_user,
group=params.user_group,
mode=0o755,
create_parents=True)
File(
os.path.join(params.redis_conf_parent, "redis.conf"),
content=Template("redis.conf.j2"),
owner=params.redis_user,
group=params.user_group,
mode=0o644)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
- 安装阶段自动调用系统包管理、拉取依赖。
- 配置阶段按参数生成所有目录(日志/数据/PID),并渲染下发 redis.conf 配置文件,确保多节点多实例安全隔离。
# 启动、停止、重启与状态检测
def start(self, env):
self.configure(env)
Execute(format(
"{client_bin}/redis-server /etc/redis/redis.conf --cluster-config-file /etc/redis/cluster_master.conf --pidfile {master_redis_pid_file}"),
user=params.redis_user)
def stop(self, env):
self.configure(env)
try:
Execute(format("kill -9 `cat {master_redis_pid_file}`"),
user=params.redis_user)
except:
Logger.warning("Failed to stop Redis Master using the PID file.")
self.ensure_stopped(env)
def ensure_stopped(self, env):
# 多轮检测进程是否完全关闭,提升健壮性
def restart(self, env):
self.stop(env)
time.sleep(5)
self.start(env)
def status(self, env):
import params
check_process_status(params.master_redis_pid_file)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
- 启动流程明确指定配置、PID、集群文件,避免进程互相干扰。
- 停止流程通过 kill -9 强制杀死进程,再通过 PID 文件轮询保证彻底清理。
- restart 方法封装了完整生命周期闭环。
- 所有主节点只专注本地服务,不参与集群初始化和 slot 分配,职责高度聚焦,方便批量管理和滚动升级。
# 3.3 完整的代码
# coding=utf-8
import os
import time
from resource_management import Template
from resource_management.core.logger import Logger
from resource_management.core.resources.system import Execute, File, Directory
from resource_management.libraries.functions.check_process_status import check_process_status
from resource_management.libraries.functions.format import format
from resource_management.libraries.script.script import Script
class RedisMaster(Script):
def install(self, env):
# 安装 Redis 包
self.install_packages(env)
self.configure(env)
def configure(self, env):
import params
env.set_params(params)
# 创建日志、数据和 PID 目录,并设置适当的权限
Directory([params.redis_log_dir, params.redis_data_dir, params.redis_pid_dir],
owner=params.redis_user,
group=params.user_group,
mode=0o755,
create_parents=True)
# 生成 redis.conf 配置文件
File(
os.path.join(params.redis_conf_parent, "redis.conf"),
content=Template("redis.conf.j2"),
owner=params.redis_user,
group=params.user_group,
mode=0o644)
def start(self, env):
import params
self.configure(env)
Logger.info(format("Starting Redis Master on port {redis_port}"))
# 启动 Redis Master,不处理集群逻辑
Execute(format(
"{client_bin}/redis-server /etc/redis/redis.conf --cluster-config-file /etc/redis/cluster_master.conf --pidfile {master_redis_pid_file}"),
user=params.redis_user)
def stop(self, env):
import params
self.configure(env)
Logger.info("Stopping Redis Master using its PID file...")
# 使用 PID 文件来停止 Redis Master 进程
try:
Execute(format("kill -9 `cat {master_redis_pid_file}`"),
user=params.redis_user)
Logger.info("Redis Master stopped successfully.")
except:
Logger.warning("Failed to stop Redis Master using the PID file.")
# 确保 Redis Master 完全停止
self.ensure_stopped(env)
def ensure_stopped(self, env):
"""
确保 Redis Master 服务已完全停止。如果 Redis 进程还在运行,等待它完全关闭。
"""
Logger.info("Checking if Redis Master is fully stopped...")
retries = 5
retry_delay = 2 # 每隔2秒检查一次
for attempt in range(retries):
try:
check_process_status("{master_redis_pid_file}")
Logger.info("Redis Master is still running (attempt {}/{}). Waiting...".format(attempt + 1, retries))
time.sleep(retry_delay)
except:
Logger.info("Redis Master has been successfully stopped.")
return
Logger.error("Redis Master failed to stop after retries.")
raise Exception("Redis Master process could not be stopped.")
def restart(self, env):
"""
重新启动 Redis Master 服务。先调用 stop 方法停止服务,然后调用 start 方法重新启动服务。
增加等待时间和进程状态检查,确保服务能够正确停止和重启。
"""
Logger.info("Restarting Redis Master...")
# 先停止服务
self.stop(env)
# 等待几秒钟,确保 Redis 进程已经彻底关闭
time.sleep(5)
# 再启动服务
self.start(env)
Logger.info("Redis Master restarted successfully.")
def status(self, env):
import params
check_process_status(params.master_redis_pid_file)
if __name__ == "__main__":
RedisMaster().execute()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
# 4. redis_slave.py:从节点+集群编排核心
# 4.1 设计目标
从节点既是 Redis 本地服务的守护者,更是整个集群自动化编排的核心枢纽。它不仅要完成自身进程的标准运维,还要负责整个 Redis 集群的初始化、slot 分配、主从动态绑定和反亲和分布。
# 4.2 关键方法分解
# 安装与配置
def install(self, env):
self.install_packages(env)
self.configure(env)
def configure(self, env):
import params
env.set_params(params)
Directory([params.redis_log_dir, params.redis_data_dir, params.redis_pid_dir],
owner=params.redis_user,
group=params.user_group,
mode=0o755,
create_parents=True)
File("/etc/redis/redis.conf",
content=Template("redis.conf.j2"),
owner=params.redis_user,
group=params.user_group,
mode=0o644)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
- 和 master 一致,标准的目录、权限和配置文件生成。
# 启动与集群智能编排
def start(self, env):
self.configure(env)
slave_port = int(params.redis_port) + 1
Execute(format(
"{client_bin}/redis-server /etc/redis/redis.conf --port {slave_port} --cluster-config-file /etc/redis/cluster_slave.conf --pidfile {slave_redis_pid_file} --masterauth {redis_password}"),
user=params.redis_user)
self.initialize_or_expand_cluster(params)
1
2
3
4
5
6
7
2
3
4
5
6
7
- 启动 Slave 时会自动使用独立端口、PID、配置,保证与 Master 并存。
- 启动后立即进入
initialize_or_expand_cluster,自动判断当前集群状态并做初始化/扩容。
# 集群初始化与主从自动挂载
def initialize_or_expand_cluster(self, params):
code, output = shell.call(
format("{client_bin}/redis-cli -p {params.redis_port} -a {redis_password} cluster nodes"),
user=params.redis_user)
filtered_output = [line for line in output.splitlines() if "Warning" not in line]
if code == 0 and len(filtered_output) > 1:
self.add_slave_to_master(params)
elif len(filtered_output) == 1:
self.initialize_cluster_and_assign_slots(params)
self.add_current_node_to_cluster(params)
else:
Logger.warning("Cluster is not initialized (attempt {}/{}).".format(attempt + 1, retries))
time.sleep(retry_delay)
1
2
3
4
5
6
7
8
9
10
11
12
13
2
3
4
5
6
7
8
9
10
11
12
13
- 检查当前集群节点数量,自动区分“已初始化”或“需初始化”状态。
- 已初始化:自动将本节点作为新 Slave 挂到合适 Master 下。
- 未初始化:直接发起主节点集群组建、slot 分配,然后将本 Slave 节点自动加入。
# 自动反亲和、动态分布算法
def get_assigned_master(self, params):
master_hosts = params.redis_master_hosts
current_slave_index = int(params.redis_port) % len(master_hosts)
assigned_master_index = (current_slave_index + 1) % len(master_hosts)
assigned_master = master_hosts[assigned_master_index]
return assigned_master
1
2
3
4
5
6
2
3
4
5
6
- 动态分配算法,根据当前集群全局状态和端口号,将新 Slave 挂载到不同 Master,最大化主从分布打散,防止主从同机。
- 新节点扩容时也自动适配,不需人肉干预。
# 停止、重启与状态检测
def stop(self, env):
self.configure(env)
try:
Execute(format("kill -9 `cat {slave_redis_pid_file}`"),
user=params.redis_user)
except:
Logger.warning("Failed to stop Redis Slave using the PID file.")
self.ensure_stopped(env)
def ensure_stopped(self, env):
# 检查进程彻底关闭
def restart(self, env):
self.stop(env)
time.sleep(5)
self.start(env)
def status(self, env):
import params
check_process_status(params.slave_redis_pid_file)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
- 标准的生命周期管理,流程与主节点一致。
# 4.3 完整代码
# coding=utf-8
import socket
import subprocess
import time
from resource_management import Template
from resource_management.core import shell
from resource_management.core.logger import Logger
from resource_management.core.resources.system import Execute, File, Directory
from resource_management.libraries.functions.check_process_status import check_process_status
from resource_management.libraries.functions.format import format
from resource_management.libraries.script.script import Script
class RedisSlave(Script):
def install(self, env):
# 安装 Redis 包
self.install_packages(env)
self.configure(env)
def configure(self, env):
import params
env.set_params(params)
# 创建日志、数据和 PID 目录,并设置适当的权限
Directory([params.redis_log_dir, params.redis_data_dir, params.redis_pid_dir],
owner=params.redis_user,
group=params.user_group,
mode=0o755,
create_parents=True)
# 生成 redis.conf 配置文件
File("/etc/redis/redis.conf",
content=Template("redis.conf.j2"),
owner=params.redis_user,
group=params.user_group,
mode=0o644)
def start(self, env):
import params
self.configure(env)
slave_port = int(params.redis_port) + 1
Logger.info(format("Starting Redis Slave on port {slave_port}"))
# 启动 Redis Slave,并显式指定 pidfile
Execute(format(
"{client_bin}/redis-server /etc/redis/redis.conf --port {slave_port} --cluster-config-file /etc/redis/cluster_slave.conf --pidfile {slave_redis_pid_file} --masterauth {redis_password}"),
user=params.redis_user)
# 检查并处理集群逻辑,包括初始化集群和扩展
self.initialize_or_expand_cluster(params)
def stop(self, env):
import params
self.configure(env)
Logger.info("Stopping Redis Slave using its PID file...")
# 使用 PID 文件来停止 Redis Slave 进程,而不是直接通过 redis-cli shutdown
try:
Execute(format("kill -9 `cat {slave_redis_pid_file}`"),
user=params.redis_user)
Logger.info("Redis Slave stopped successfully.")
except:
Logger.warning("Failed to stop Redis Slave using the PID file.")
# 确保 Redis Slave 完全停止
self.ensure_stopped(env)
def ensure_stopped(self, env):
"""
确保 Redis Slave 服务已完全停止。如果 Redis 进程还在运行,等待它完全关闭。
"""
Logger.info("Checking if Redis Slave is fully stopped...")
retries = 5
retry_delay = 2 # 每隔2秒检查一次
for attempt in range(retries):
try:
check_process_status("{slave_redis_pid_file}")
Logger.info("Redis Slave is still running (attempt {}/{}). Waiting...".format(attempt + 1, retries))
time.sleep(retry_delay)
except:
Logger.info("Redis Slave has been successfully stopped.")
return
Logger.error("Redis Slave failed to stop after retries.")
raise Exception("Redis process could not be stopped.")
def restart(self, env):
"""
重新启动 Redis Slave 服务。先调用 stop 方法停止服务,然后调用 start 方法重新启动服务。
增加等待时间和进程状态检查,确保服务能够正确停止和重启。
"""
Logger.info("Restarting Redis Slave...")
# 先停止服务
self.stop(env)
# 等待几秒钟,确保 Redis 进程已经彻底关闭
time.sleep(5)
# 再启动服务
self.start(env)
Logger.info("Redis Slave restarted successfully.")
def status(self, env):
import params
check_process_status(params.slave_redis_pid_file)
def initialize_or_expand_cluster(self, params):
"""
在 Slave 启动时检查 Master 节点是否已经组成集群,如果没有则进行集群初始化。如果已经有集群,处理扩展。
"""
retries = 5
retry_delay = 10 # 秒
Logger.info("Checking cluster status to determine if initialization or expansion is needed.")
for attempt in range(retries):
code, output = shell.call(
format("{client_bin}/redis-cli -p {params.redis_port} -a {redis_password} cluster nodes"),
user=params.redis_user)
# 构建一个新数组,过滤掉包含 "Warning" 的行
filtered_output = [line for line in output.splitlines() if "Warning" not in line]
# 如果集群已经初始化,继续添加从节点
if code == 0 and len(filtered_output) > 1:
Logger.info("Cluster is already initialized. Proceeding with slave addition.")
self.add_slave_to_master(params)
return
# 如果集群只有一个节点,执行集群初始化并将当前节点加入
elif len(filtered_output) == 1:
Logger.info(
"Cluster is not initialized. Initializing Redis Cluster with master nodes and assigning slots.")
self.initialize_cluster_and_assign_slots(params)
# 初始化集群后,将当前节点也作为集群的一部分加入
Logger.info("Adding current node to the newly initialized cluster.")
self.add_current_node_to_cluster(params)
return
else:
Logger.warning("Cluster is not initialized (attempt {}/{}).".format(attempt + 1, retries))
time.sleep(retry_delay)
Logger.error("Cluster could not be initialized after retries.")
raise Exception("Cluster in an inconsistent state.")
def initialize_cluster_and_assign_slots(self, params):
"""
初始化集群,组建 Master 节点之间的集群,并分配槽位(仅限首次初始化时)。
"""
redis_port = int(params.redis_port) if isinstance(params.redis_port, str) else params.redis_port
# 使用 Ambari 提供的 format 方法来格式化字符串
master_hosts = [format("{host}:{redis_port}", host=host, redis_port=redis_port) for host in
params.redis_master_hosts]
master_nodes_str = " ".join(master_hosts)
Logger.info(format("Initializing Redis Cluster with master nodes: {master_nodes_str}"))
# 使用 --cluster-replicas 0 来创建只有主节点的集群
create_cluster_command = format(
"{client_bin}/redis-cli --cluster create {master_nodes_str} --cluster-replicas 0 -a {redis_password} --cluster-yes")
# 打印生成的集群创建命令
Logger.info(format("Generated create_cluster_command: {create_cluster_command}"))
try:
# 使用 subprocess 来执行命令,捕获 stdout 和 stderr
process = subprocess.Popen(create_cluster_command, shell=True, stdout=subprocess.PIPE,
stderr=subprocess.STDOUT)
stdout, _ = process.communicate()
# 过滤掉警告信息,仅保留核心输出
filtered_output = [line for line in stdout.decode('utf-8').splitlines() if "Warning" not in line]
if process.returncode != 0 or not filtered_output:
Logger.error("Failed to initialize Redis cluster. Error: {0}".format(filtered_output))
raise Exception("Cluster initialization failed")
Logger.info("Cluster initialized successfully.")
except Exception as e:
Logger.error("Failed to initialize Redis cluster: {0}".format(str(e)))
raise
def add_slave_to_master(self, params):
"""
将新的 Slave 节点加入到集群,并明确指定它作为某个 Master 节点的从节点,确保反亲和性。
之前添加前检查该从节点是否已经是集群的一部分。
"""
slave_port = int(params.redis_port) + 1
master_host = self.get_assigned_master(params) # 获取合适的主节点,确保反亲和性
# 先检查从节点是否已经在集群中
if self.is_slave_already_in_cluster(params, slave_port):
Logger.info(
format("Redis Slave {params.hostname}:{slave_port} is already part of the cluster, skipping addition."))
return
Logger.info(format("Adding Redis Slave on port {slave_port} to master at {master_host}"))
# 使用 -a 参数传递密码,明确指定将从节点加入到某个主节点下
Execute(format(
"{client_bin}/redis-cli --cluster add-node {params.hostname}:{slave_port} {master_host}:{params.redis_port} --cluster-slave -a {redis_password}"),
user=params.redis_user)
Logger.info("Slave node added to the cluster as a replica of master {master_host}. No need to rebalance slots.")
def add_current_node_to_cluster(self, params):
"""
将当前节点加入到集群中,确保当前节点成为集群的一部分。
"""
slave_port = int(params.redis_port) + 1
master_host = self.get_assigned_master(params) # 获取合适的主节点
Logger.info(format("Adding current Redis node on port {slave_port} to the newly initialized cluster."))
Execute(format(
"{client_bin}/redis-cli --cluster add-node {params.hostname}:{slave_port} {master_host}:{params.redis_port} --cluster-slave -a {redis_password}"),
user=params.redis_user)
Logger.info("Current node added to the cluster successfully.")
def is_slave_already_in_cluster(self, params, slave_port):
"""
检查 Redis 节点是否已经是集群的一部分,确保通过 IP 地址而非主机名进行匹配。
"""
Logger.info(format("Checking if Redis Slave {params.hostname}:{slave_port} is already part of the cluster..."))
# 将主机名解析为 IP 地址
slave_ip = self.get_ip_from_hostname(params.hostname)
if slave_ip is None:
Logger.error("Failed to resolve hostname to IP for: {0}".format(params.hostname))
return False
# 使用 redis-cli 查询集群的所有节点
code, output = shell.call(
format("{client_bin}/redis-cli -p {params.redis_port} -a {redis_password} cluster nodes"),
user=params.redis_user)
if code != 0:
Logger.warning("Failed to retrieve cluster nodes information.")
return False
# 检查输出,查看该从节点的 IP 地址是否已经在集群中
for line in output.splitlines():
if slave_ip in line and str(slave_port) in line:
Logger.info("Redis Slave with IP {0} is already in the cluster: {1}".format(slave_ip, line))
return True
return False
def get_assigned_master(self, params):
"""
动态分配 Master 节点,确保新 Slave 节点配对到正确的 Master 节点,且遵循反亲和性原则。
"""
master_hosts = params.redis_master_hosts
Logger.info("Available Master nodes: {0}".format(master_hosts))
# 获取当前主节点的索引
current_slave_index = int(params.redis_port) % len(master_hosts)
# 计算该从节点应当挂载的主节点
assigned_master_index = (current_slave_index + 1) % len(master_hosts)
assigned_master = master_hosts[assigned_master_index]
Logger.info(format("Assigning Slave on port {params.redis_port} to Master {assigned_master}"))
return assigned_master
def get_ip_from_hostname(self, hostname):
"""
使用 socket 库获取主机名对应的 IP 地址
"""
try:
ip_address = socket.gethostbyname(hostname)
return ip_address
except socket.error as e:
Logger.error("Failed to resolve hostname {0}: {1}".format(hostname, str(e)))
return None
if __name__ == "__main__":
RedisSlave().execute()
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113
114
115
116
117
118
119
120
121
122
123
124
125
126
127
128
129
130
131
132
133
134
135
136
137
138
139
140
141
142
143
144
145
146
147
148
149
150
151
152
153
154
155
156
157
158
159
160
161
162
163
164
165
166
167
168
169
170
171
172
173
174
175
176
177
178
179
180
181
182
183
184
185
186
187
188
189
190
191
192
193
194
195
196
197
198
199
200
201
202
203
204
205
206
207
208
209
210
211
212
213
214
215
216
217
218
219
220
221
222
223
224
225
226
227
228
229
230
231
232
233
234
235
236
237
238
239
240
241
242
243
244
245
246
247
248
249
250
251
252
253
254
255
256
257
258
259
260
261
262
263
264
265
266
267
268
269
270
271
272
273
274
275
276
277
278
279
280
281
282
283
284
285
286
287
288
289
290
291