 Ambari启动视角剖析执行逻辑
Ambari启动视角剖析执行逻辑
# 一、模块定位
TimelineService(Collector)
TimelineService 是 Ambari-Metrics 的核心模块,在架构中承担三大职能:
- 指标接收:对接 Host-Monitor 与 Hadoop Sink 上报的监控数据;
- 数据存储:落盘到 HBase,形成时序数据库;
- API 提供:通过 REST / WebSocket 接口对外提供查询和聚合能力。
⚡️ 特别说明:Collector 虽然是一个 Java 进程,但在 Ambari 的世界里,它必须遵循统一的链路:
Server → Agent → Python 脚本 → Java 命令
# 二、执行链路总览
# 2.1 三层分工
执行逻辑可分为三层:
- Server 层:生成 Command JSON,下发启动动作;
- Agent 层:解析 JSON,调用对应 Python 脚本(
metrics_collector.py); - 脚本层:渲染参数,拼接并调用最终 Java 命令。
图 1 从“启动动作”到“Java 命令”的链路演进 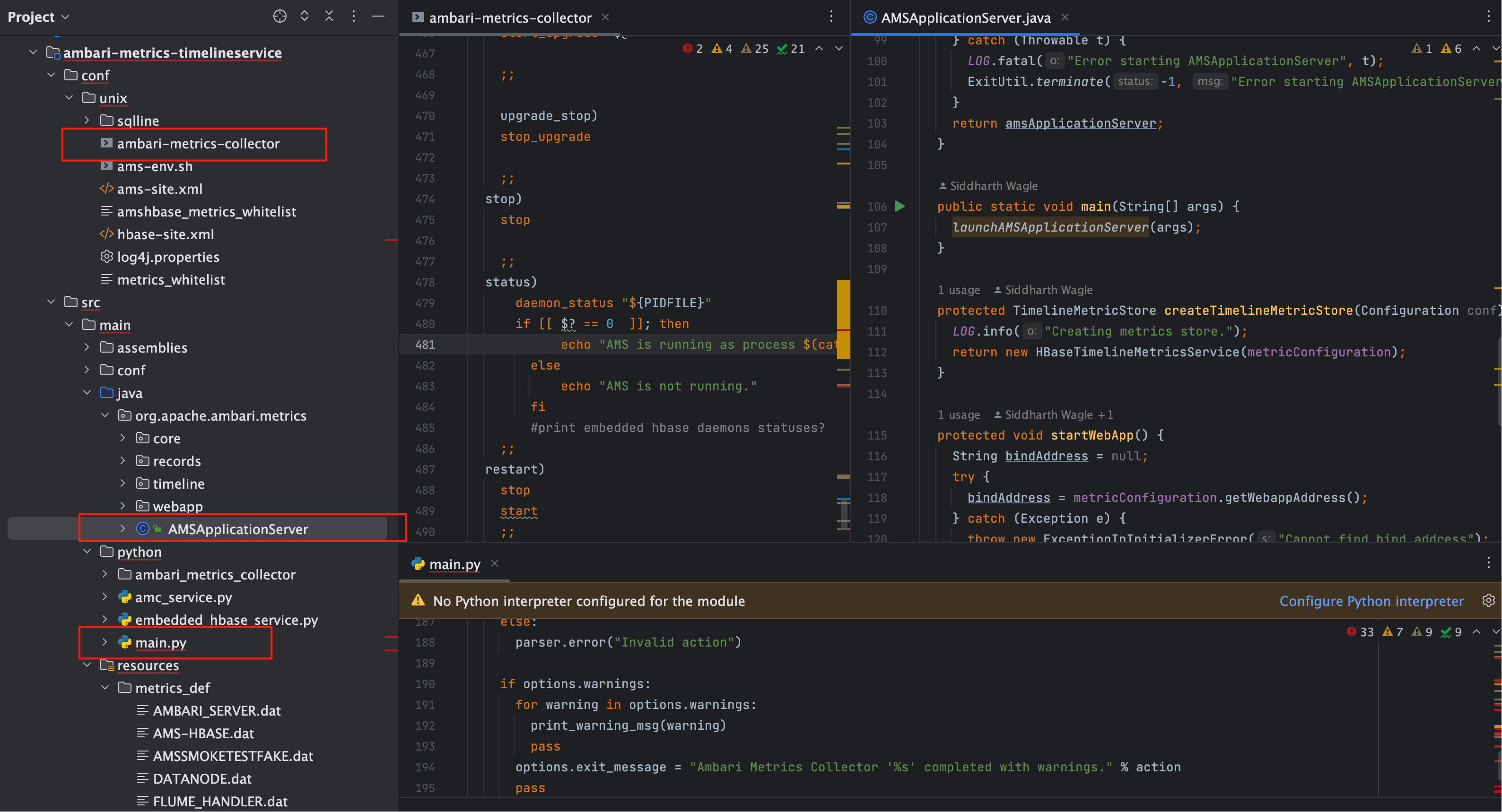
# 2.2 设计思路
- 解耦:Server 不直接运行命令,只传递“意图”;
- 灵活:Agent 脚本二次解析,兼容跨平台与版本差异;
- 健壮:命令由脚本动态拼接,避免硬编码带来的兼容问题。
👉 想进一步理解,可阅读 Ambari成神之路 章节,掌握 Server / Agent / Provider 的整体设计哲学。
# 三、服务定义与脚本入口
# 3.1 服务目录
Ambari-Metrics 的服务定义不在 bigtop stacks,而在 Ambari 的 common-services 目录:
- 定义文件:
common-services/AMBARI_METRICS/<ver>/metainfo.xml - 脚本目录:
.../package/scripts/metrics_collector.py、ams_service.py - 配置模板:
.../configuration/*
图 2 服务目录与脚本入口(metainfo.xml → metrics_collector.py) 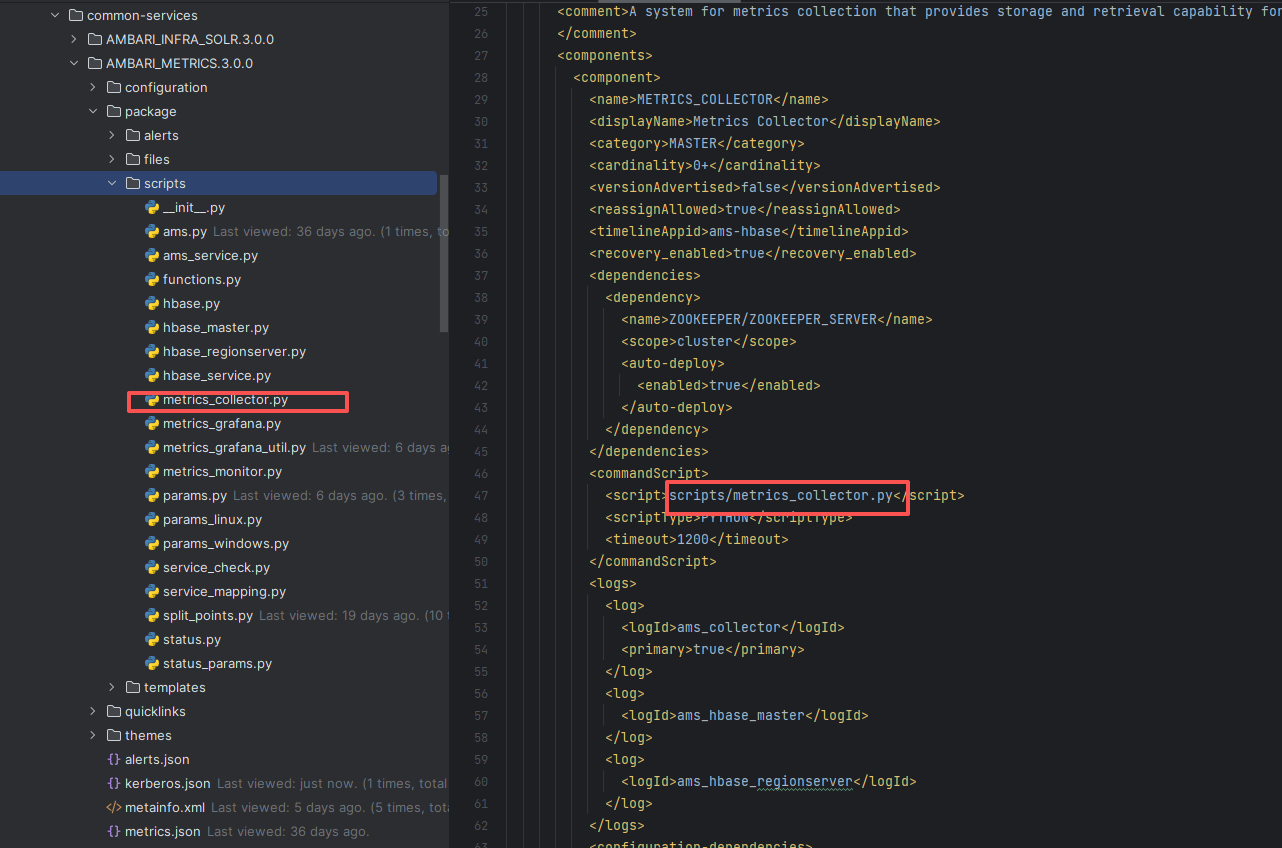
# 3.2 metainfo 的作用
metainfo.xml 是服务的“蓝图”,定义了:
- 服务名、版本号、依赖关系;
- 启动 / 停止 / 重启动作的脚本路径;
- 关键配置文件与环境变量。
依赖它,Ambari 能保证 Collector 在不同系统和环境下,都能按统一逻辑被启动。
# 四、“启动动作 → Java 命令”的四步链路
# 4.1 四步拆解
- 入口:
metrics_collector.py的start()方法接收 Agent 指令; - 分发:进入
ams_service.py的 collector 分支; - 渲染:参数由
params渲染为命令行片段,如--config、--distributed; - 执行:拼接成最终启动命令,并由
Execute()调用:
/usr/sbin/ambari-metrics-collector \
--config /etc/ambari-metrics-collector/conf \
--distributed start
1
2
3
2
3
# 4.2 职责表
| 层级/文件 | 关键点 | 作用说明 |
|---|---|---|
metrics_collector.py | start() | 接收 Agent 指令,进入启动链路 |
ams_service.py | collector | 调度 Collector 与 Monitor 分支 |
| 参数体系(params) | 渲染参数 | 将 metainfo/配置文件映射为命令行 |
| 最终命令 | Execute | 执行 Java 进程 |
图 3 四步链路示意(从 Python 脚本到 Java 进程) 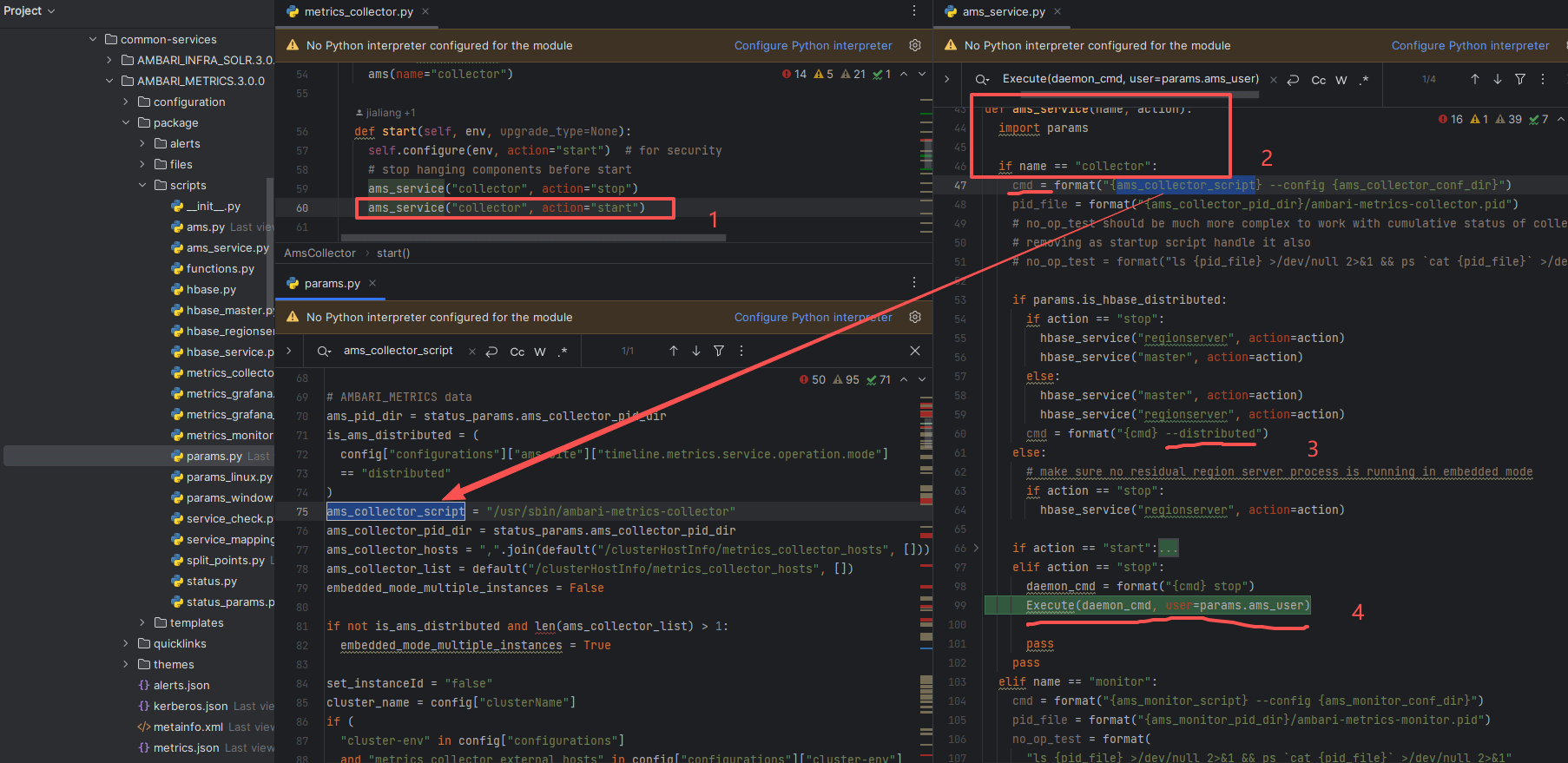
# 五、执行日志与权限
# 5.1 日志回溯
在 Agent 日志中可以清晰看到 Collector 的执行记录:
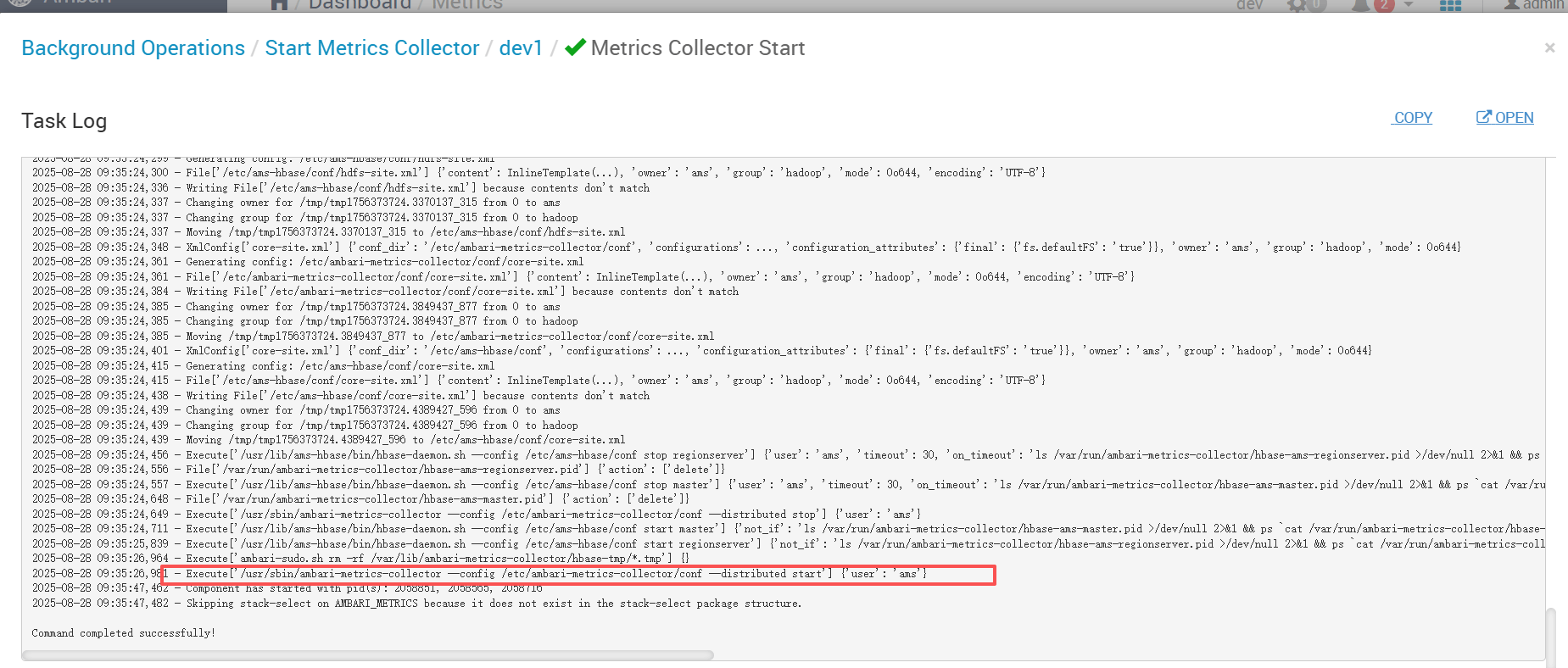
Execute['/usr/sbin/ambari-metrics-collector --config /etc/ambari-metrics-collector/conf --distributed start'] {'user': 'ams'}
1
# 5.2 权限说明
Collector 进程由
ams用户 启动;ams属于 hadoop 组,可访问 HDFS、HBase 路径;这样实现了:
- 服务级安全隔离(不同服务对应不同用户);
- 统一权限治理(保证 Hadoop 生态间访问顺畅)。
下一节预告
Collector 已经顺利启动,但问题来了:
这个 Java 进程究竟是在哪里被拉起来的? 别急,我们会在下一节为你详细剖析!