 Cloudbeaver 安装1.0.5+
Cloudbeaver 安装1.0.5+
# 基于 Ambari 安装 Cloudbeaver 可视化服务 🖥️
Cloudbeaver 是一款轻量级、开源的 Web 数据库管理平台,具备跨平台、易用、支持多种数据库(如 PostgreSQL、MySQL、MariaDB、Oracle
等)等特点,适合在大数据集群中部署用于图形化管理数据库。我们将通过 Ambari 一步到位 的方式,将
Cloudbeaver 集成部署到 Hadoop 集群中。
提示
Cloudbeaver 本身依赖 JDK 17 和一个元数据数据库(推荐使用 PostgreSQL),请确认这些环境已准备好。同时,大数据平台基础服务如 Hadoop、ZooKeeper 也应在 Ambari 中成功部署,以便服务组件能统一管理。
# 1. 安装背景说明
在大数据集群中,常常会面临多个组件、多个数据库的管理任务。相比命令行操作,Cloudbeaver 提供了可视化 Web UI 管理 PostgreSQL、MySQL、Oracle 等数据库的能力,是一个适合与 Ambari 搭配使用的轻量数据库管理工具。
跨平台数据库可视化 Cloudbeaver 基于 DBeaver,支持 JDBC 驱动,可通过 Ambari 集成部署,实现统一管理。# 2. 服务选择界面
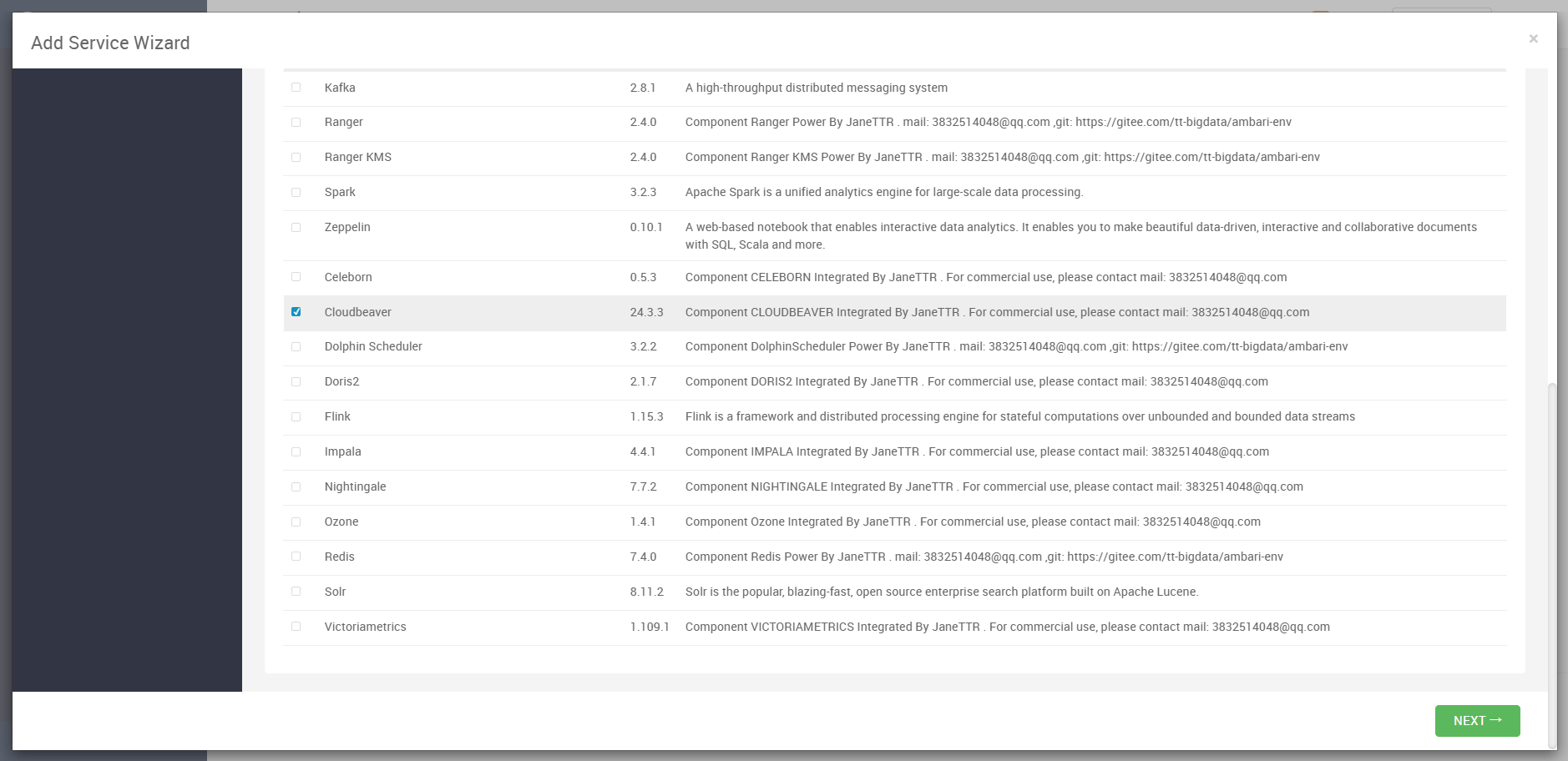
进入 Ambari 控制台后,在左侧服务面板点击 Add Service,系统将弹出可选服务列表。我们在其中找到 Cloudbeaver,勾选后点击 *
Next* 继续。
提示
该服务由本站适配并集成,确保与 Ambari Stack 完美兼容,版本为 24.3.3。
# 3. 分配安装主机
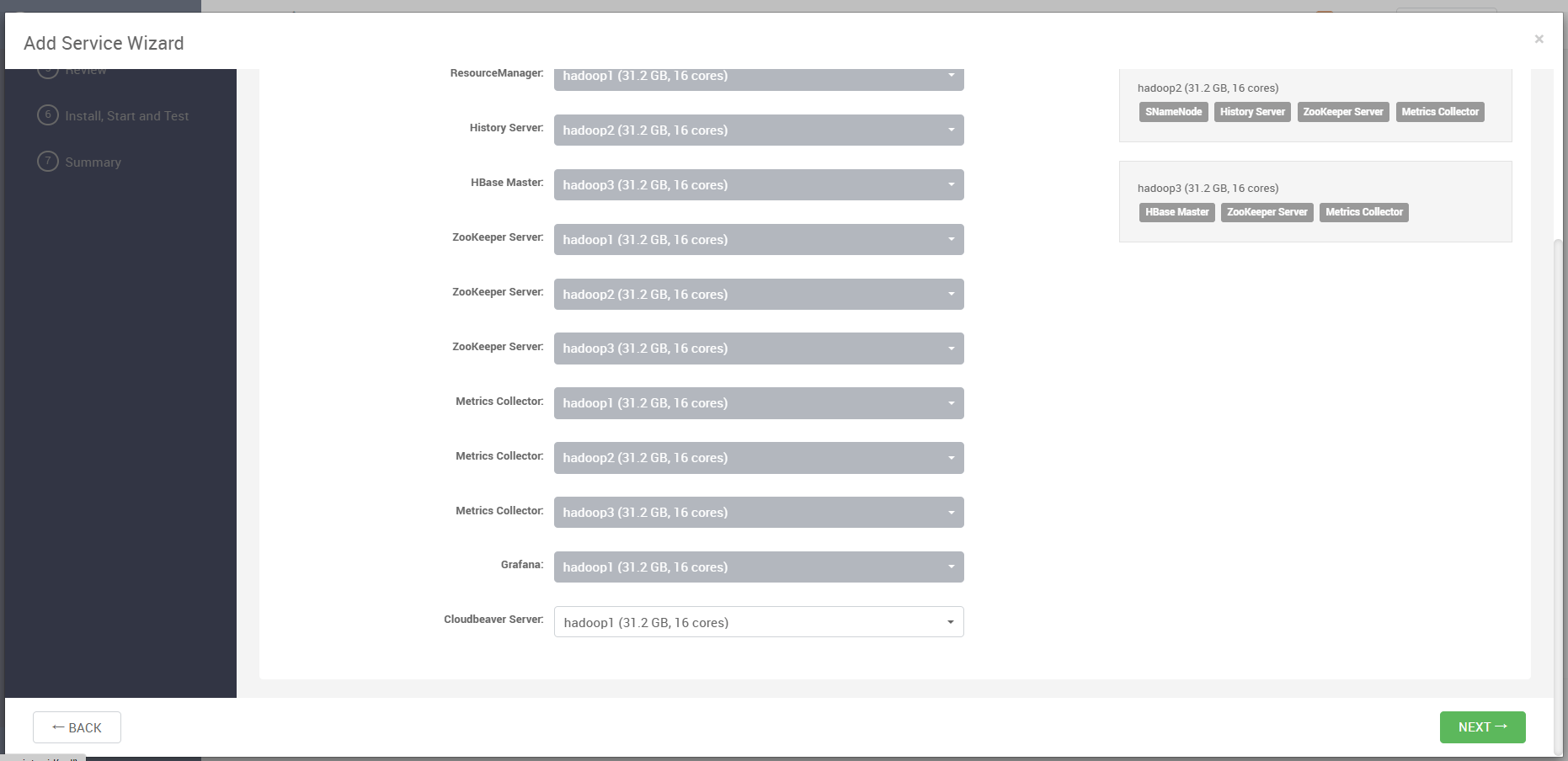
在组件分配界面,由于 Cloudbeaver 是 Web 服务,推荐仅部署在一台机器上即可。在本例中,我们选择部署在 hadoop1 节点。
笔记
不建议多节点部署,Cloudbeaver 不支持高可用,只需一台主机负责运行服务端即可。
# 4. 配置数据库参数(PostgreSQL)
Cloudbeaver 启动后需要使用数据库来保存连接配置、用户会话信息等。我们选择使用 PostgreSQL 作为元数据库,并填写对应参数:
server.database.user: postgresserver.database.password: postgres_pwdserver.database.url: jdbc:postgresql://hadoop2:5432/postgres
提示
关于 PostgreSQL 的安装方法,请参考本站文档:如何快速安装 pgsql
。该文中不仅包含安装步骤,还提供一键安装脚本,设置密码为 postgres_pwd,用户名和库名均为 postgres。
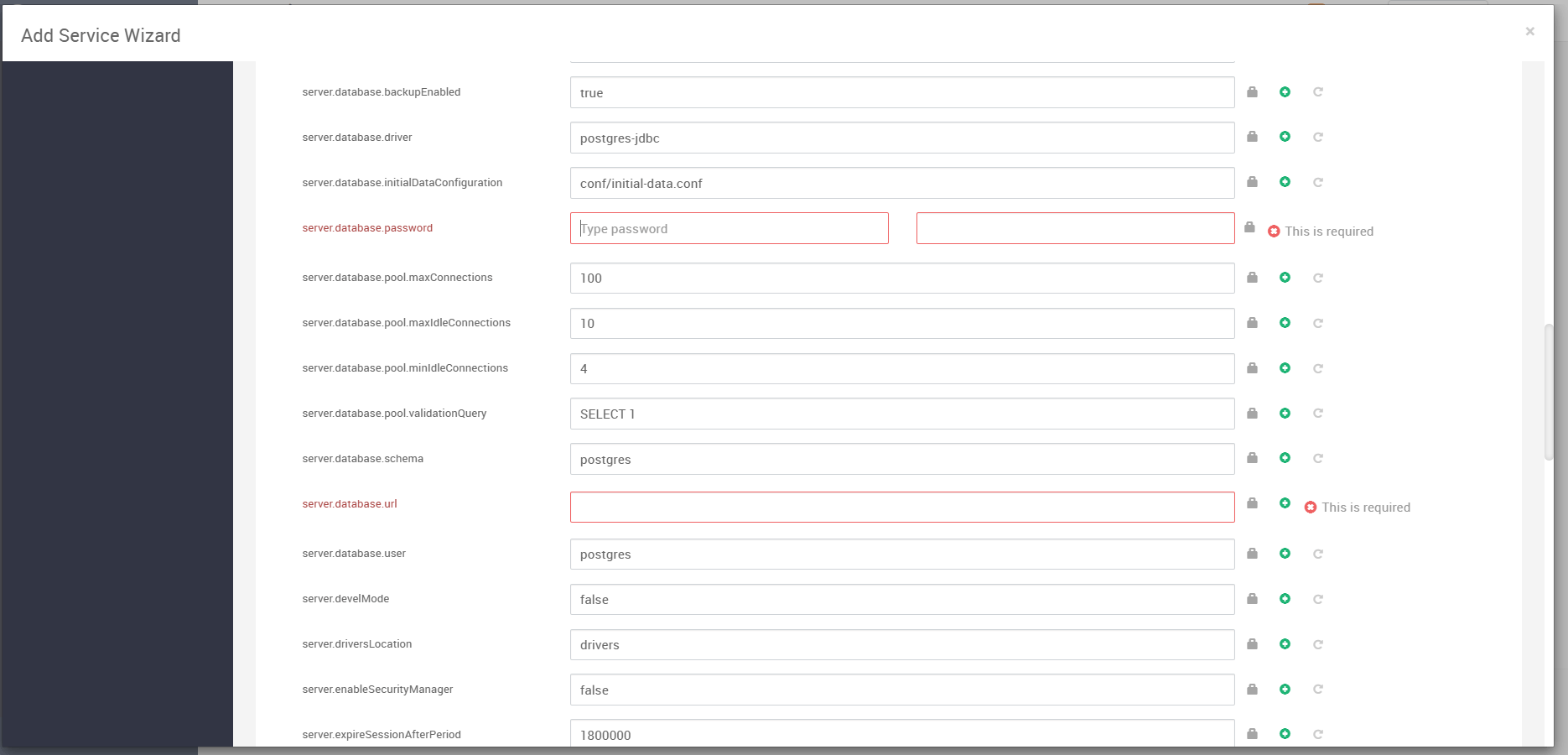
如图所示,右侧红框位置即为我们填写的 password 和 JDBC url。
# 5. 配置 JDK 环境路径(JDK 17)
Cloudbeaver 要求 Java 运行环境为 JDK 17。我们可以将自己准备好的 OpenJDK17 解压后,填入如下路径:
/opt/enhance_env/miniconda2/envs/cloudbeaver_env/lib/jvm
警告
Cloudbeaver 当前版本不兼容 JDK 8 或 JDK 11,请务必使用 JDK 17!
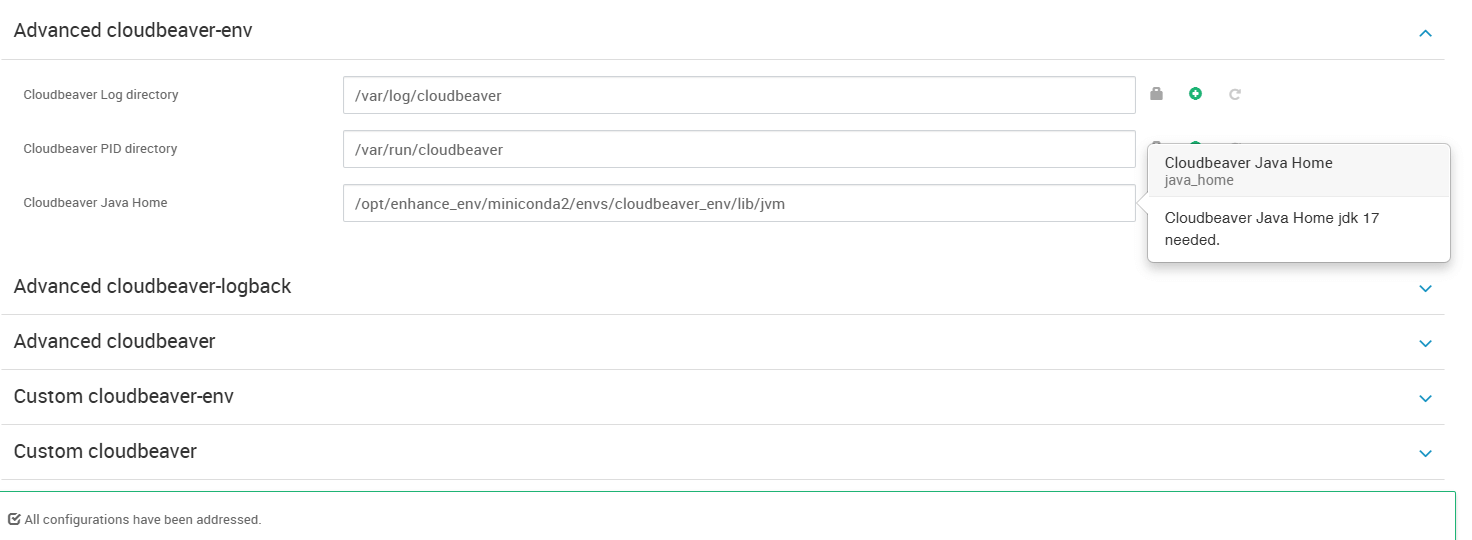
如果你使用的是 Conda 虚拟环境,也可以像上图这样将 JDK 17 安装在虚拟环境下,并使用该路径。
# 6. 开始安装并查看进度
一切参数设置完成后,点击 Next 进入部署阶段。Ambari 会自动下载、安装并启动 Cloudbeaver 服务。
如下图,hadoop1 节点正在进行安装,其他节点等待即可。
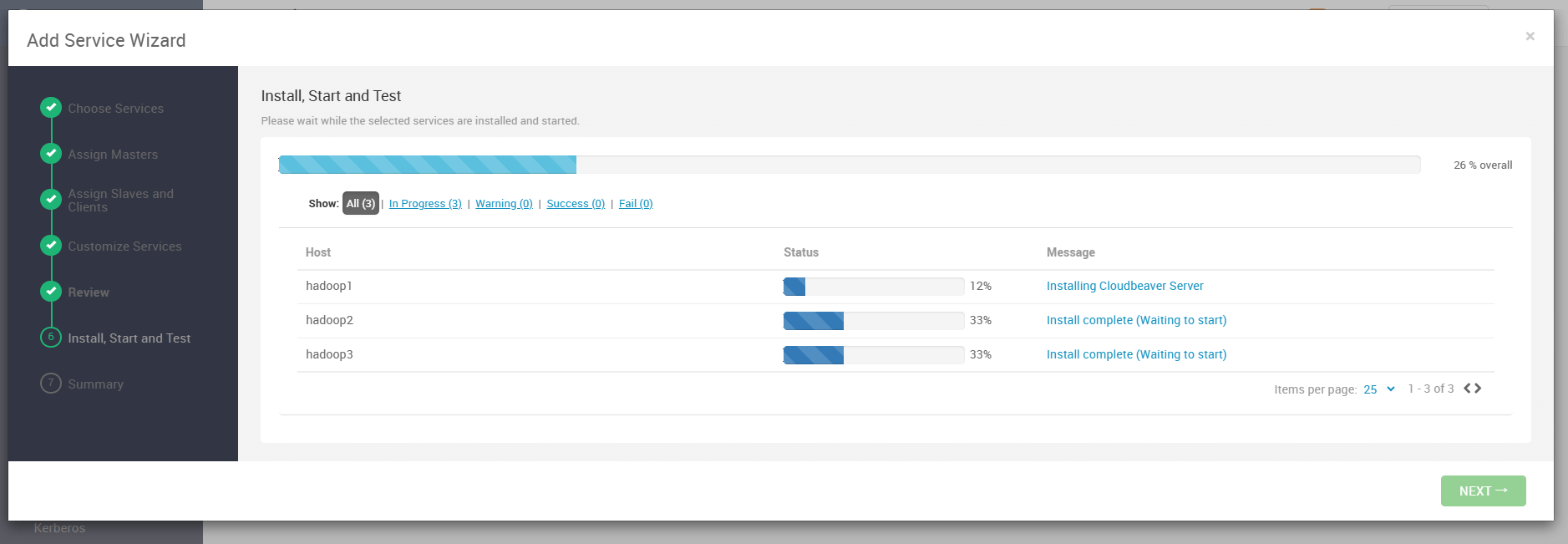
安装时间取决于网络环境和机器配置,建议耐心等待。
# 7. 安装成功并启动
当安装进度条达到 100% 时,系统会提示所有操作成功。表示服务已启动完毕。
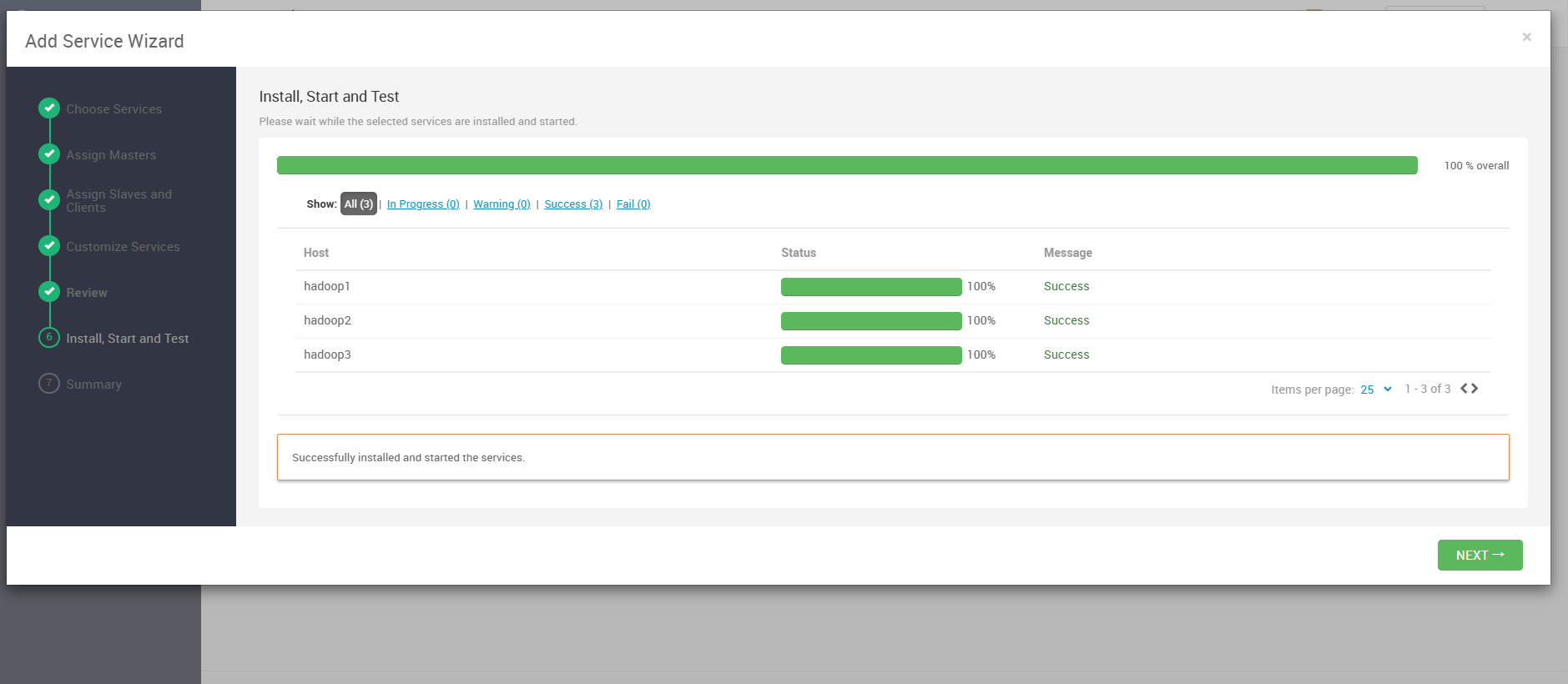
此时,返回 Ambari 控制台首页,可以看到 Cloudbeaver 服务状态为 Started,右侧提供了 Web UI 快捷访问链接:

# 8. 初次登录及管理账号配置
点击右侧链接,访问地址为:
http://hadoop2:8978/
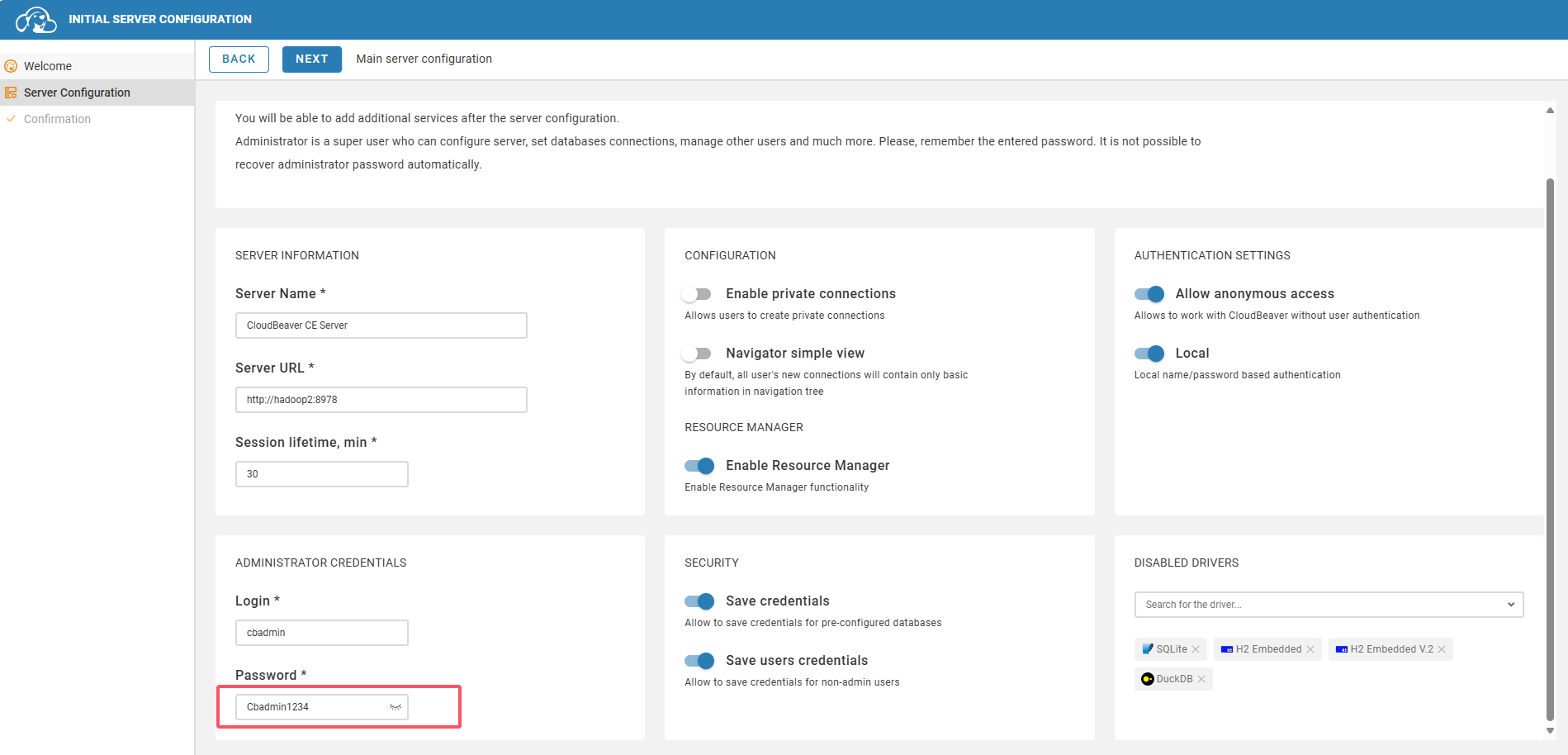
进入 Cloudbeaver 的初始化页面,配置管理员账号信息:
- 用户名:cbadmin
- 密码:Cbadmin1234
注意
请牢记此管理员密码,后续可登录 Web 控制台对数据库连接、权限策略进行管理。
点击 Finish 完成初始化:
# 9. 创建 PostgreSQL 连接
初始化完毕后,我们可以点击左上角的 ➕ 按钮,新增数据库连接:
填写如下参数:
| 字段 | 值 |
|---|---|
| Driver | PostgreSQL |
| Host | hadoop2 |
| Port | 5432 |
| Database | postgres |
| Username | postgres |
| Password | postgres_sql |
| Connection name | PostgreSQL@hadoop2 |
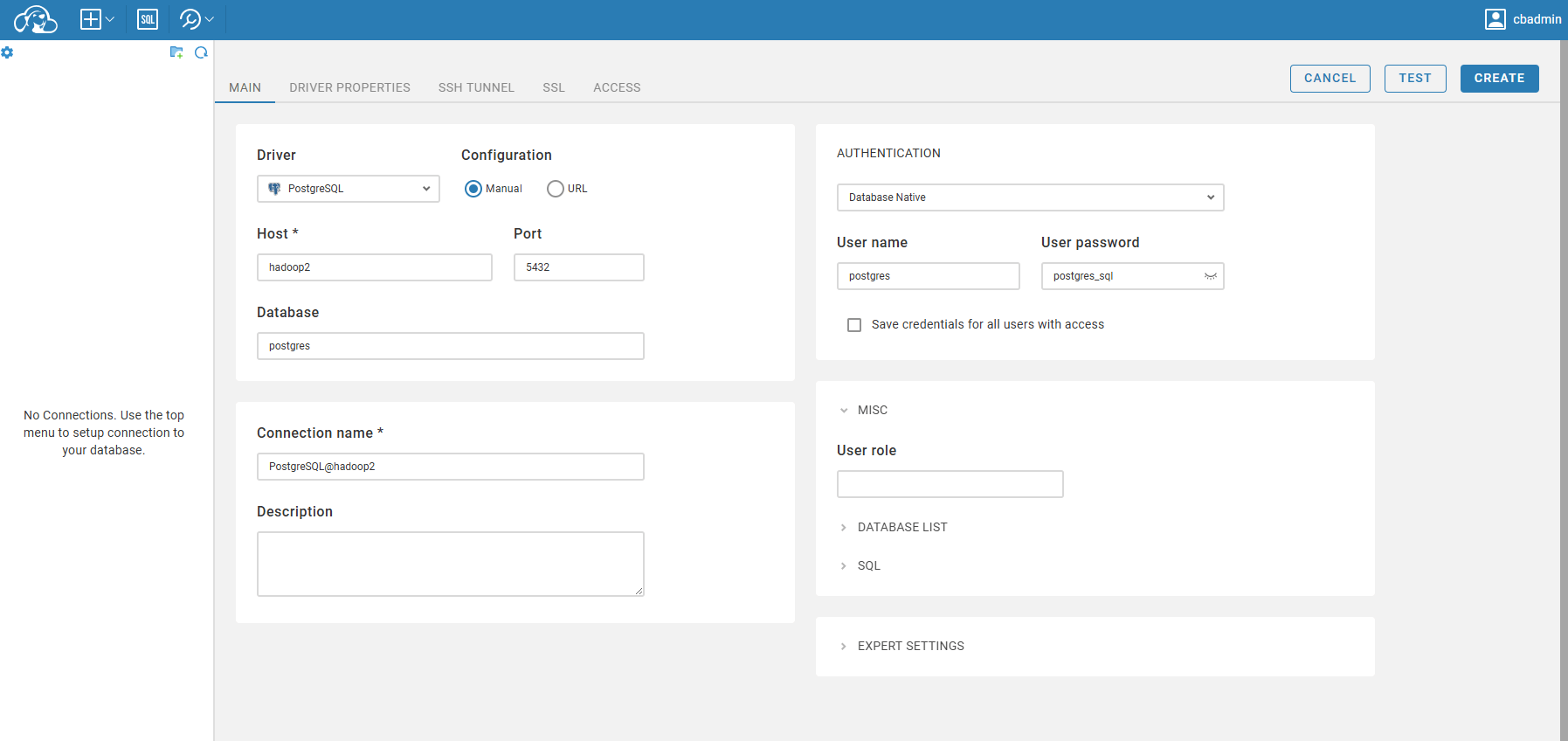
点击 Test 测试连接,成功后点击 Create 即可。
# 10. 使用 SQL 编辑器执行查询
连接成功后,Cloudbeaver 会自动加载该数据库结构。我们可以选择一个数据库,打开 SQL 窗口,直接运行查询语句,例如:
select * from ambari_sequences;
查询结果会在下方展示,支持导出、分页、列筛选等功能。
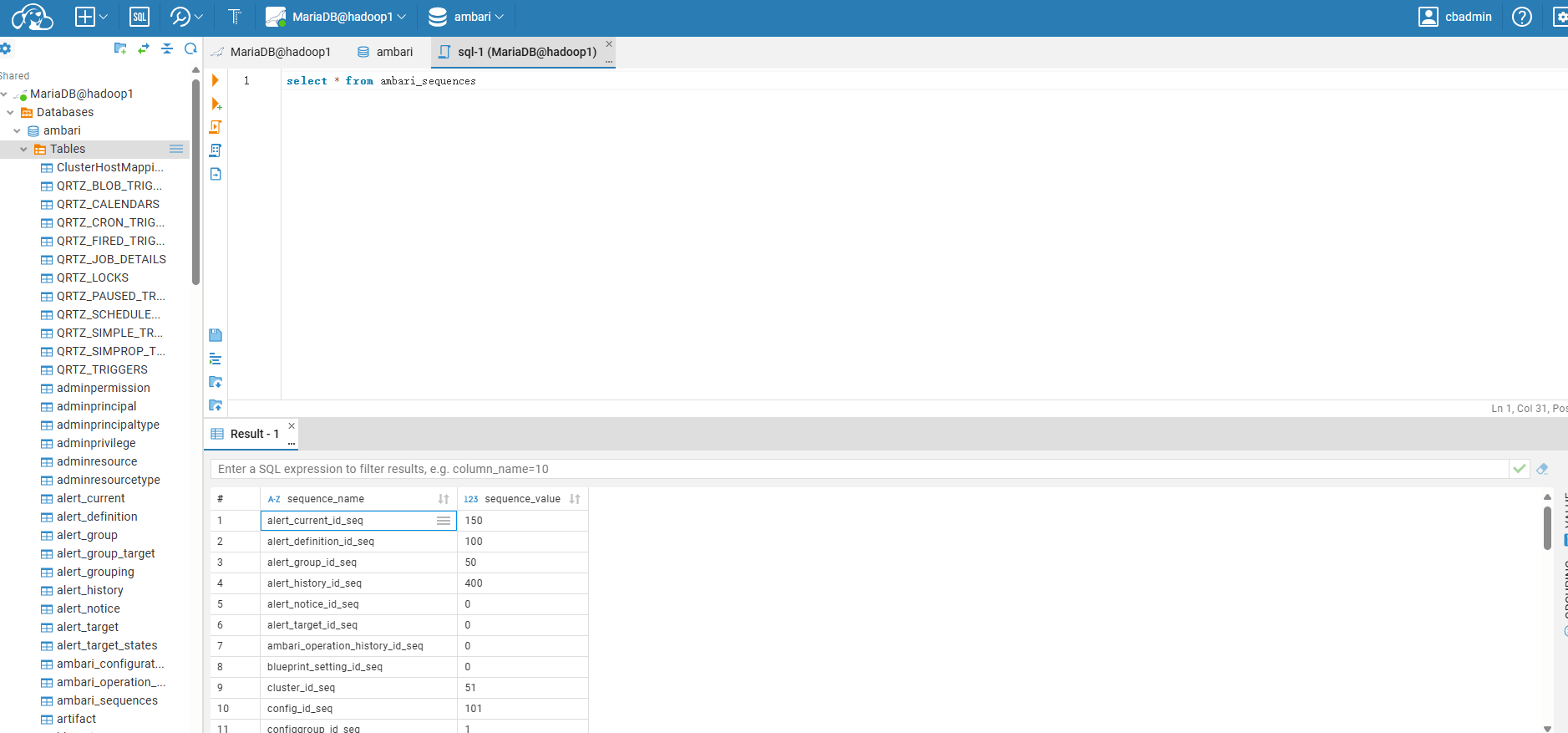
提示
Cloudbeaver 不仅支持 SQL 查询,还能查看表结构、编辑表、执行 DDL 等操作,功能媲美 Navicat。