 Alluxio 安装2.2.2+
Alluxio 安装2.2.2+
# 一、基于 Ambari 安装 Alluxio 服务
在 Ambari 管理的大数据环境中,通过 添加服务向导 安装 Alluxio,可以将其纳入统一的:
- 服务生命周期管理
- 配置集中分发与变更
- 服务启停与运行状态监控
避免手工部署时常见的版本不一致、节点遗漏、配置漂移等问题。
本文环境说明
- 集群管理:Ambari 3.0.0
- 发行版:
ttr-2.2.2+ - 安全模式:Kerberos 已开启
- 目标:通过 Ambari 部署 Alluxio,为 Spark / SQL / 批处理任务提供高速数据访问层
从 Ambari 首页点击 Add Service / 添加服务,进入服务安装向导。

# 二、选择 Alluxio 组件
# 1. 在服务列表中勾选 Alluxio
在可选服务列表中,勾选 Alluxio 组件:

Alluxio 在集群中并不是“可有可无”的工具型组件,而是真正参与数据读写链路的基础设施,因此更适合以下场景:
- 已有稳定运行的 HDFS 集群
- Spark 作业数量较多、数据复用率高
- IO 成为计算性能瓶颈
Alluxio 在集群中的核心职责
- 提供 内存级 / 本地磁盘级缓存能力
- 屏蔽底层存储差异(HDFS / OSS / S3 等)
- 为 Spark、MapReduce 提供 统一、高速的数据访问接口
- 显著降低重复计算对 HDFS 的 IO 压力
在安装 Alluxio 之前,建议确认集群中已具备稳定运行的 HDFS 与计算引擎。
确认后点击 NEXT。
# 三、分配 Alluxio 组件节点
# 1. Master 节点规划
Ambari 会提示为 Alluxio Master 选择部署节点:

Alluxio Master 主要负责:
- 元数据管理(缓存文件分布情况)
- Worker 状态汇总
- 客户端请求调度
Master 节点规划建议
- 尽量与 NameNode / ResourceManager 分离
- 稳定性优先于算力
- 初期可单 Master 部署
- 生产环境建议规划 HA 架构
# 2. Worker 节点分配
随后进入 Alluxio Worker 的节点分配页面:
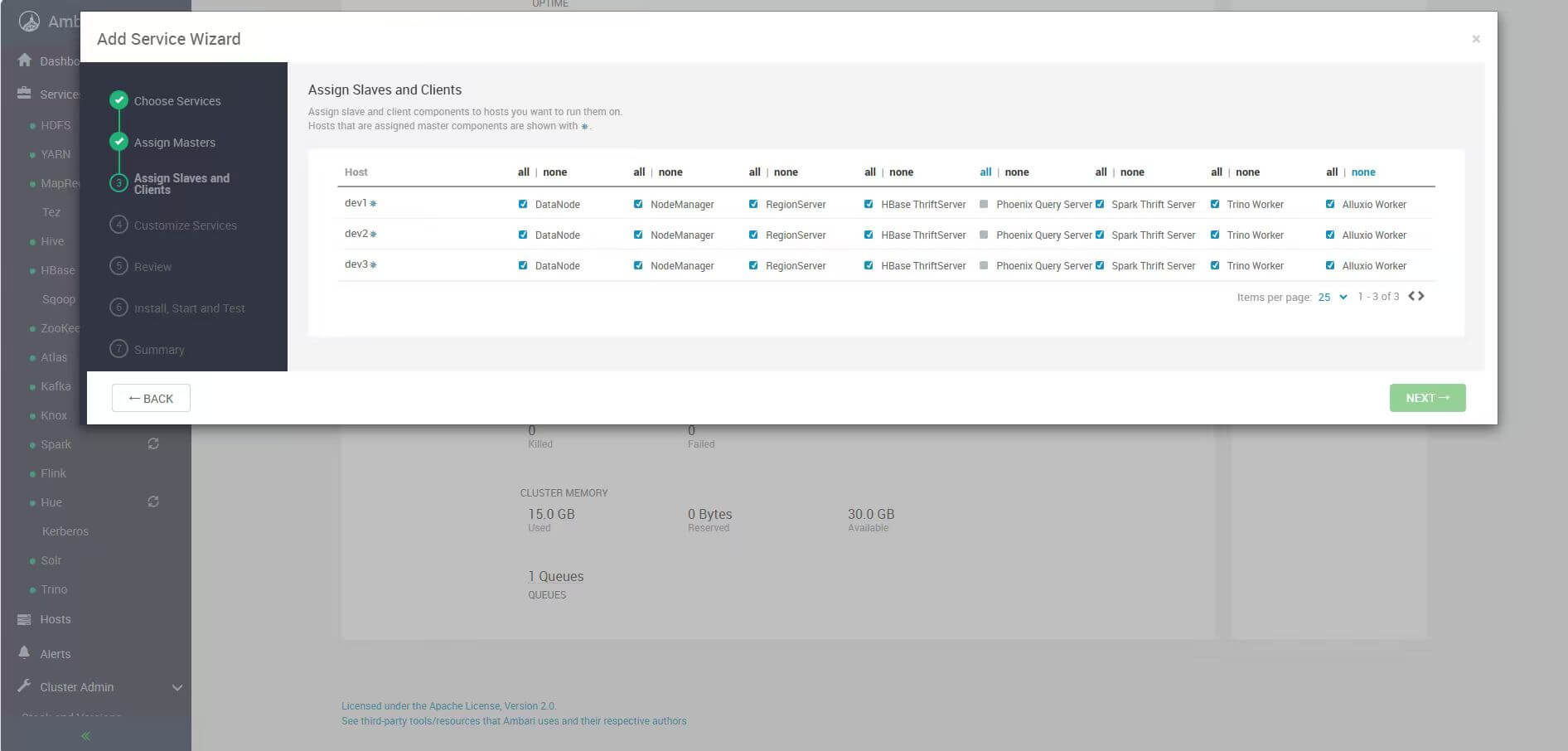
Alluxio Worker 是实际承载缓存数据的角色,性能主要取决于:
- 本地磁盘 IO
- 可用内存大小
- 与计算进程的物理距离
Worker 选择建议
- 通常部署在 计算节点(DataNode / Spark Executor 节点)
- 内存与本地磁盘资源直接影响缓存效果
- 不建议部署在纯管理节点
确认组件分布后,继续下一步。
# 3. 组件配置
在配置页面中,首次安装建议 保持默认配置即可,无需提前做复杂调整。

点击 NEXT 进入下一步。
# 四、蓝图清单与配置确认
# 1. 蓝图摘要页面
Ambari 会展示 Alluxio 的完整安装蓝图,包括:
- Master / Worker 的部署主机
- 组件与节点映射关系
- 依赖与配置校验结果

提醒
我们开启了 Kerberos
认证,所以安装过程多了些票据步骤,我们也整理了相关文档,涵盖了一些避坑指南,请参考下面章节:开启Kerberos——专题
确认无误后,进入正式安装阶段。
# 五、安装过程与结果确认
# 1. 观察安装执行过程
进入安装执行页面后,Ambari 会自动完成:
- Alluxio 相关包的分发
- 配置文件渲染与下发
- Kerberos 环境下的权限校验
- 服务注册与进程启动

Kerberos 环境说明
由于本集群在 开启 Kerberos 后 才安装 Alluxio,因此安装步骤会明显多于非安全环境,这是正常现象。
# 2. 安装完成后的服务状态
安装完成后,回到 Ambari 服务总览页,Alluxio 状态应为 Started / 绿色:

到这里说明什么?
- Alluxio 已成功接入 Ambari 管理体系
- Master / Worker 进程正常启动
- 服务具备对外提供缓存能力的基础条件
# 六、访问 Alluxio Web UI 验证服务状态
通过 Ambari 页面中的 Web UI 入口,可以访问 Alluxio 的管理界面:

默认 Worker 页面地址类似:
http://dev1:19999/workers

在该页面中可以重点关注:
- Worker 是否全部为 LIVE
- 每个 Worker 的内存 / 磁盘容量
- 当前缓存使用情况

当页面可正常访问、Worker 状态正常时,说明:
Alluxio 服务安装成功,已具备承载缓存数据的能力