Livy 安装2.2.0+
Livy 安装2.2.0+
# 一、基于 Ambari 安装 Livy 服务
Livy 是运行在集群中的 Spark 作业网关服务,提供一套 REST/HTTP 接口来提交 Spark 任务、创建交互式 Session,并为 Zeppelin、Jupyter 等 Notebook 工具提供统一的后台执行引擎。
在使用 Ambari 管理的大数据集群中,可以通过 添加服务向导 一键集成 Livy,避免手动拷贝包、改配置、写 systemd 的繁琐流程。
本文环境说明
- 集群管理:Ambari 3.0.0
- 发行版:
ttr-2.2.0+版本均支持 - 目标:通过 Ambari 安装并启用 Livy,后续为 Spark SQL / Notebook / BI 工具提供统一入口
从 Ambari 首页点击 Add Service / 添加服务:
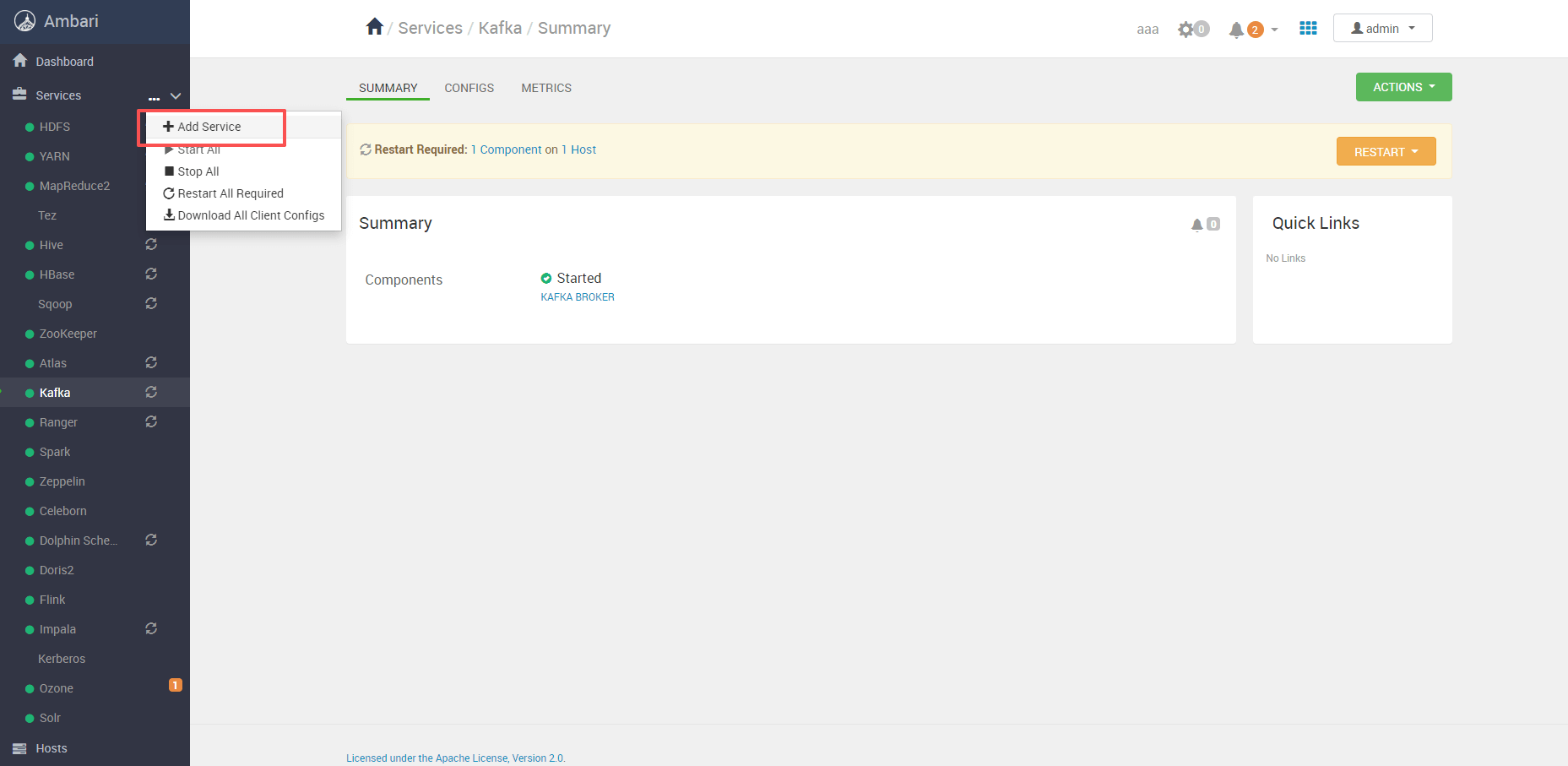
# 二、选择 Livy 组件
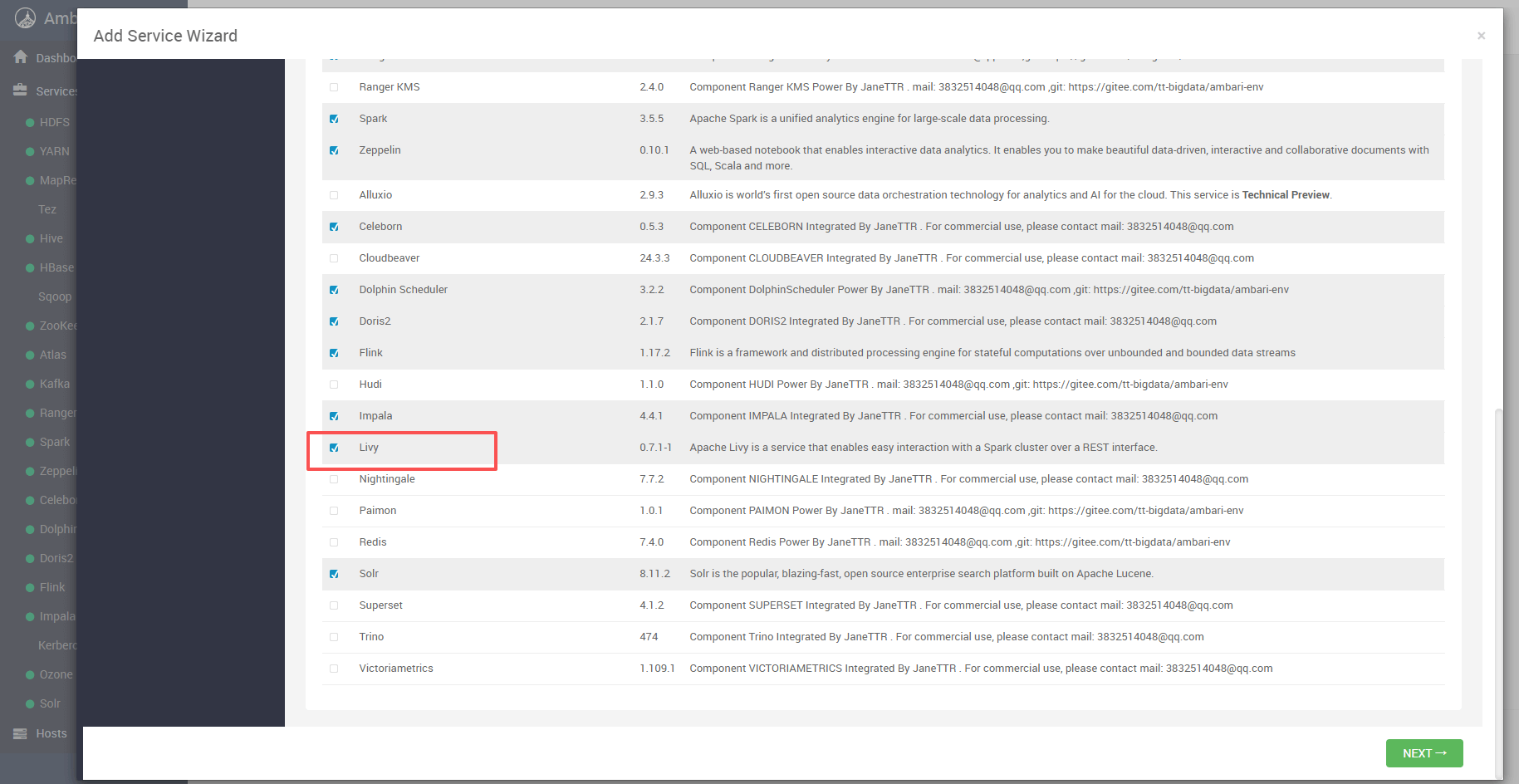
# 1. 在服务列表中勾选 Livy
进入添加服务向导后,在可选服务列表中勾选 Livy:
小提示
Livy 主要职责是:
- 提供 REST 接口 将 Spark 作业提交到 YARN / Standalone 集群
- 提供 Session 管理(交互式、批任务)
- 为 Zeppelin / Jupyter / Superset / 自研应用 提供统一 Spark 后端能力
安装前建议确保集群中已存在可用的 Spark 和 YARN。
点击 NEXT 进入下一步。
# 三、分配 Livy Server 节点
# 1. 选择部署主机
Ambari 会要求为 Livy Server 选择部署节点:

节点选择建议
- 优先选择 与 Spark History Server / Zeppelin 网络较近的节点
- CPU、内存不需要夸张,但要保证有一定富余,避免被大批 Session 打爆
- 初期可以 单实例部署,后续量大了再做横向扩展或前置反向代理
确认后继续 NEXT。
# 2. Slave/Client 自动勾选
Slave/Client直接跳过了,会来到配置页面
这里通常无需额外修改,保持 Ambari 默认规划即可,直接点击下一步。
# 四、蓝图清单与配置确认
# 1. 蓝图摘要页面
Ambari 会展示一次蓝图/变更清单,包括 Livy 组件将安装到哪些主机、会下发哪些配置:
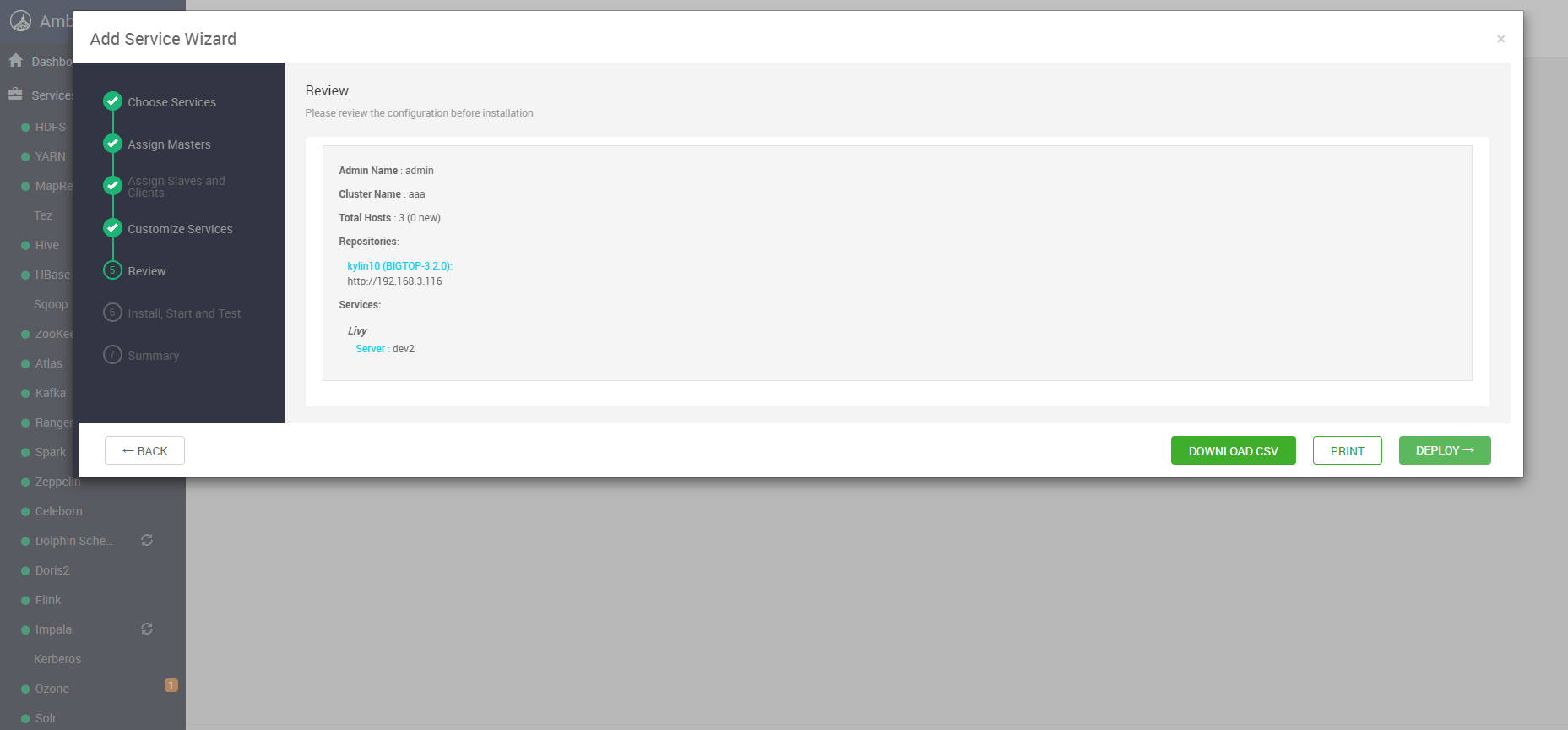
可以重点确认的配置点
- Livy 绑定的 主机名与端口(如:
8998) - 是否已经关联到正确的 Spark 版本
- 与 YARN 的集成方式(
spark.master是否为yarn)
如果只是快速安装验证,可以先保持默认,后续再通过 Configs 页面精细调优即可。
点击下一步,进入正式安装阶段。
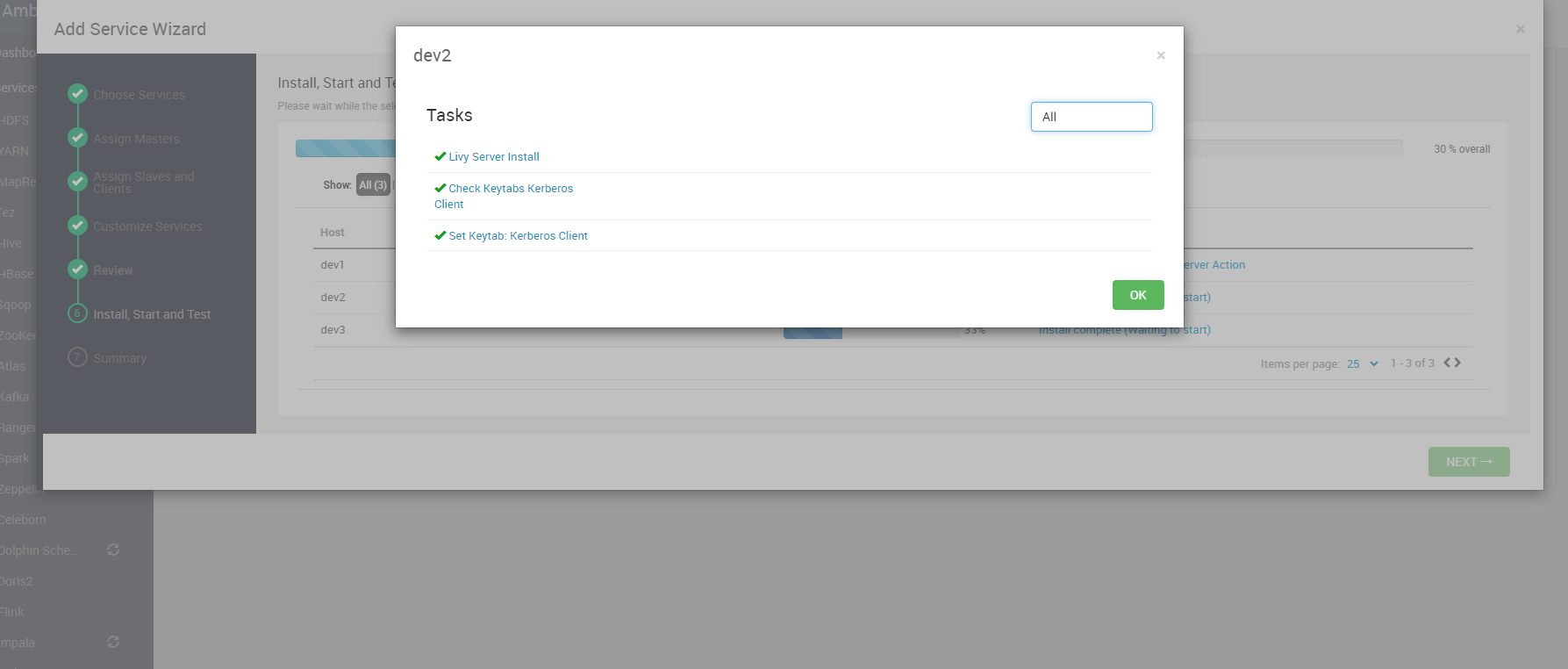
# 五、安装过程与结果确认
# 1. 观察安装进度
进入安装执行界面后,Ambari 会自动完成:
- 从 Bigtop 仓库拉取 Livy 相关包
- 下发 Livy 配置文件(如
livy.conf、livy-env.sh等) - 注册 Livy 服务并尝试启动
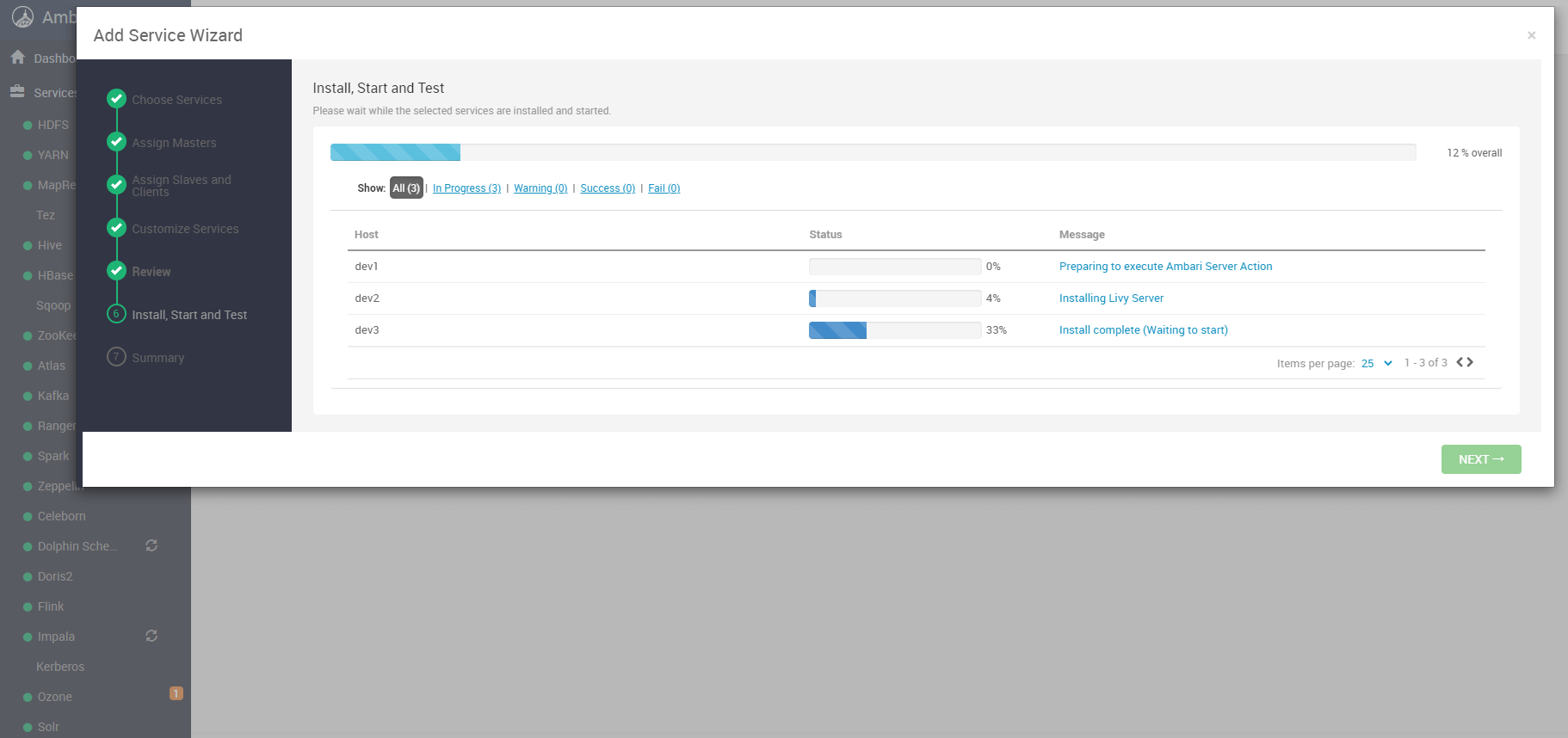
可以展开 Task 详情查看具体安装命令、日志输出。
# 2. 安装完成后的服务状态
安装流程跑完后,Ambari 会回到服务概览页,Livy 的状态应为 Started / 绿色: