 Alluxio 安装2.9.4
Alluxio 安装2.9.4
# Alluxio 安装
Alluxio 可以理解成大数据和 AI 场景里的数据编排与缓存层。它可以把底层 HDFS、对象存储或其他存储系统抽象成统一访问入口,并通过 Worker 缓存提升上层计算访问数据的效率。前面已经把 HDFS、YARN、Spark、Hive、Trino 等组件装好,这里继续补 Alluxio。
本篇继续使用三台 FQDN 主机:
| 主机 | Alluxio 角色 |
|---|---|
hadoop1.test.com | ALLUXIO_MASTER、ALLUXIO_WORKER |
hadoop2.test.com | ALLUXIO_WORKER |
hadoop3.test.com | ALLUXIO_WORKER |
Alluxio 不需要额外的 MySQL / MariaDB 元数据库。安装时重点看 Master 放在哪台机器、Worker 是否覆盖需要缓存的计算节点、underFS 是否指向正确的 HDFS 路径,以及 Kerberos 凭据是否正常生成。
# 1. 选择 Alluxio 服务
进入 服务与组件,点击 新增服务,在服务列表里找到并勾选 Alluxio。
页面里可以看到 Alluxio 版本是 2.9.4,依赖 HDFS。本文只安装 Alluxio 一个服务,先把 Master、Worker 和 Web 页面跑通,后面再结合 Spark、Trino、Hive 讲使用方式。
# 2. 分配 Alluxio Master
Master 分配页会出现 ALLUXIO_MASTER。
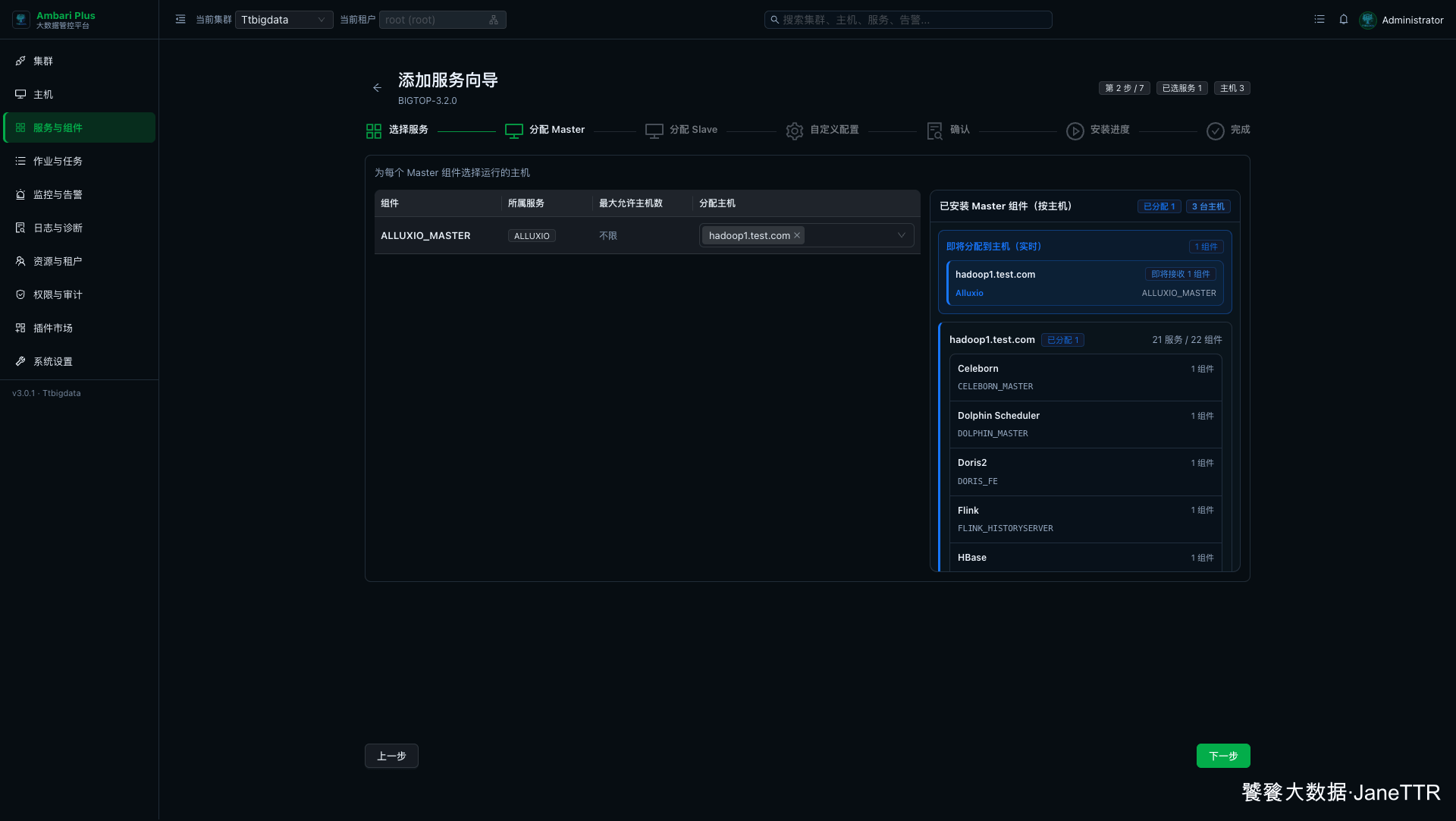
本次把 Alluxio Master 放在 hadoop1.test.com:
| 组件 | 分配主机 | 说明 |
|---|---|---|
ALLUXIO_MASTER | hadoop1.test.com | Alluxio 控制面和 Web 管理入口。 |
教程环境里先使用单 Master。生产环境如果要提高可用性,可以进一步规划 Alluxio Master HA、Journal、独立数据盘和监控告警。
# 3. 分配 Alluxio Worker
Slave 分配页会出现 ALLUXIO_WORKER。
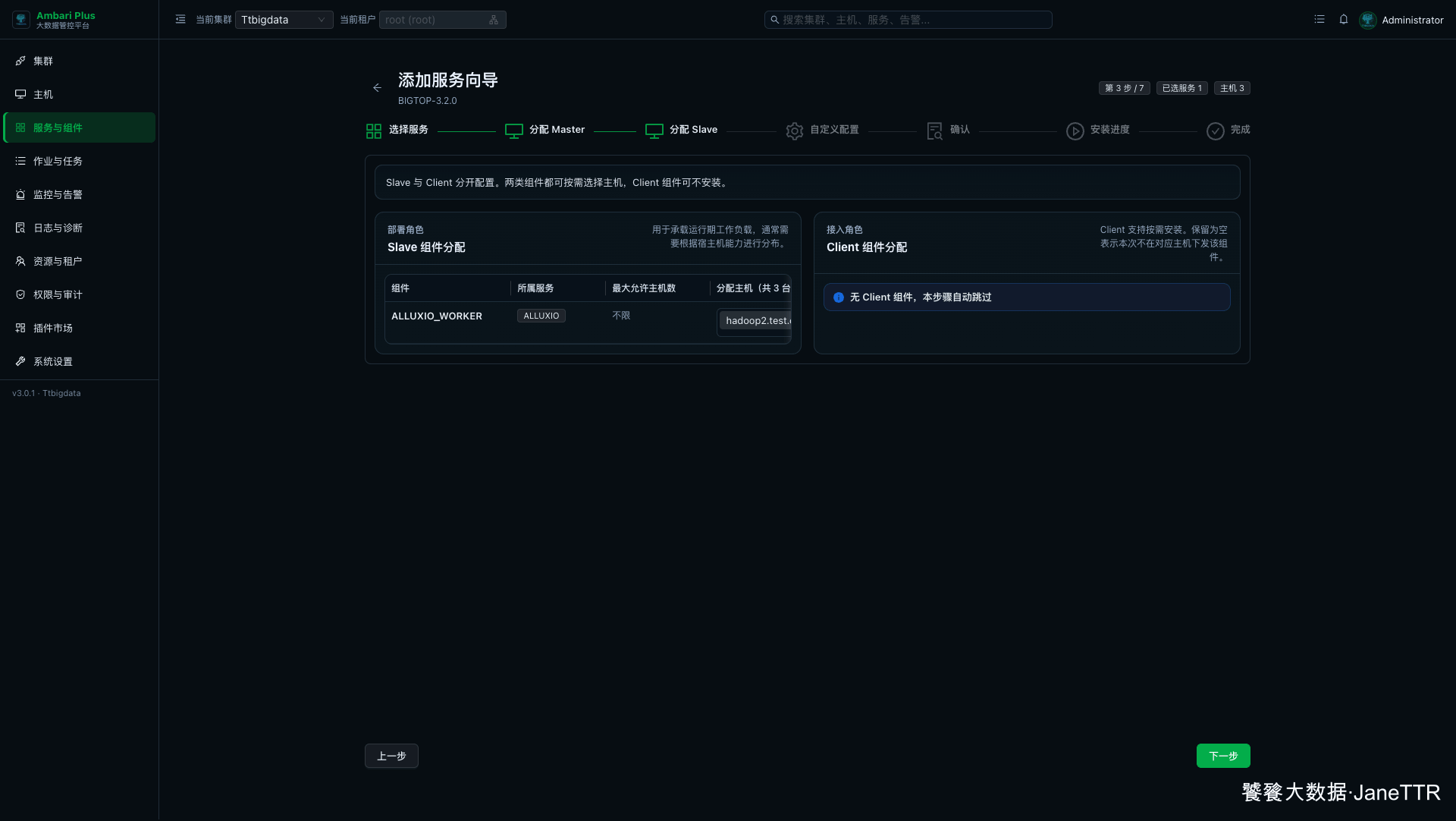
本次把 Worker 分配到三台主机:
| 组件 | 分配主机 | 说明 |
|---|---|---|
ALLUXIO_WORKER | hadoop1.test.com、hadoop2.test.com、hadoop3.test.com | 提供缓存和数据读写服务。 |
如果你的集群里计算节点更多,通常会把 Alluxio Worker 放到靠近 Spark、Trino、Hive 查询负载的机器上。这里三台都放 Worker,方便后续测试缓存和数据访问路径。
# 4. 检查 Alluxio 配置
进入自定义配置页后,当前环境会自动预填推荐配置,并且没有必填项缺失。
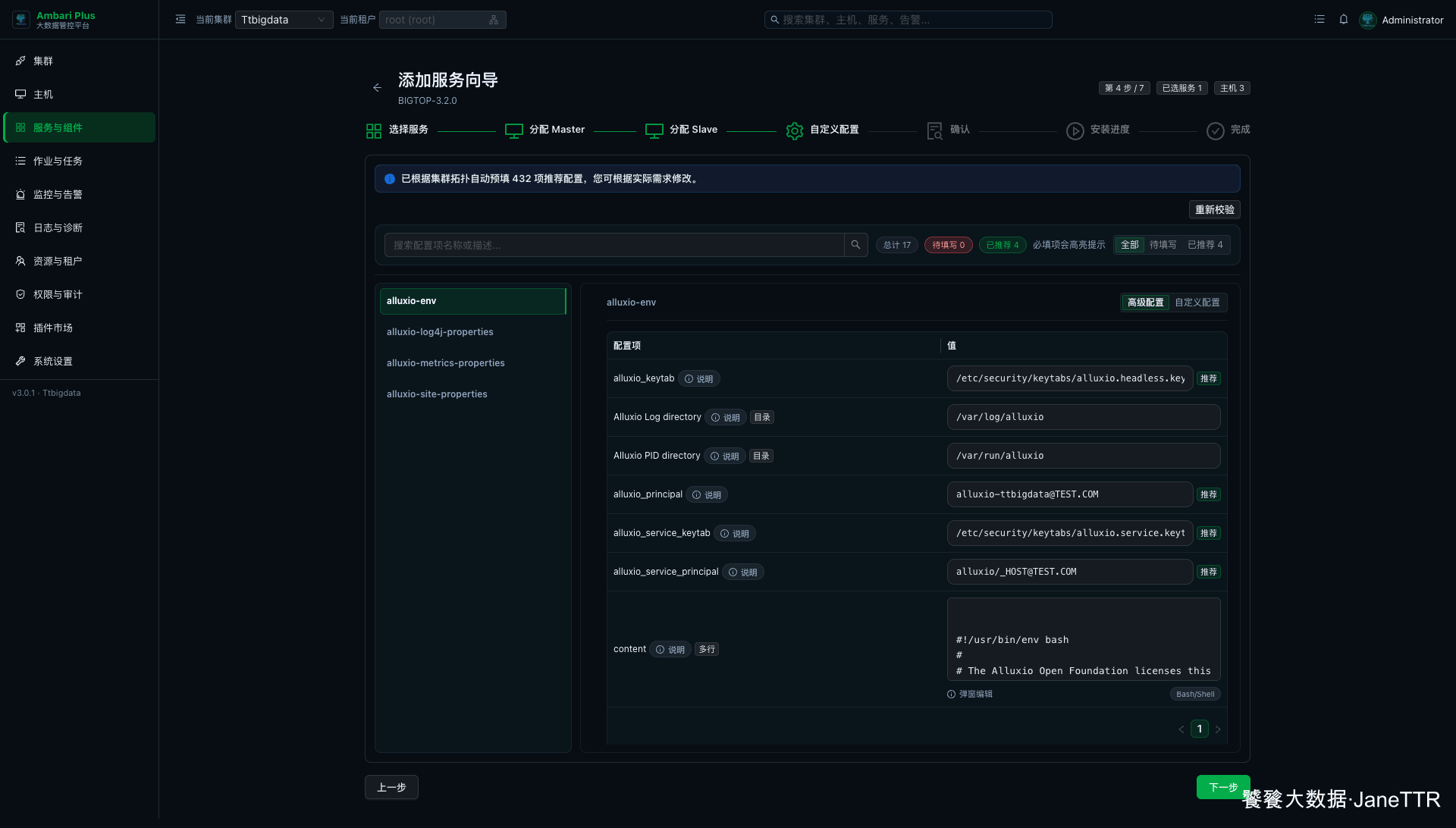
这一步我会重点看下面几类配置:
| 配置项 | 本文示例值 | 说明 |
|---|---|---|
alluxio.master.rpc.port | 19998 | Master RPC 端口。 |
alluxio.master.web.port | 19999 | Master Web 端口。 |
alluxio.worker.rpc.port | 29999 | Worker RPC 端口。 |
alluxio.worker.web.port | 30000 | Worker Web 端口。 |
alluxio.worker.memory | 1GB | Worker 内存缓存容量。 |
alluxio.underfs.hdfs.address | /apps/alluxio/underFSStorage | Alluxio 默认 underFS 路径。 |
alluxio.master.metastore.dir | /usr/bigtop/current/alluxio/metastore | Master 本地元数据目录。 |
如果后续要承载真实业务数据,Worker 缓存目录、容量和磁盘类型需要结合机器资源重新规划。演示环境先保持默认即可。
# 5. 确认安装清单
确认页会展示本次新增服务、Master 分配、Slave 分配和配置校验结果。
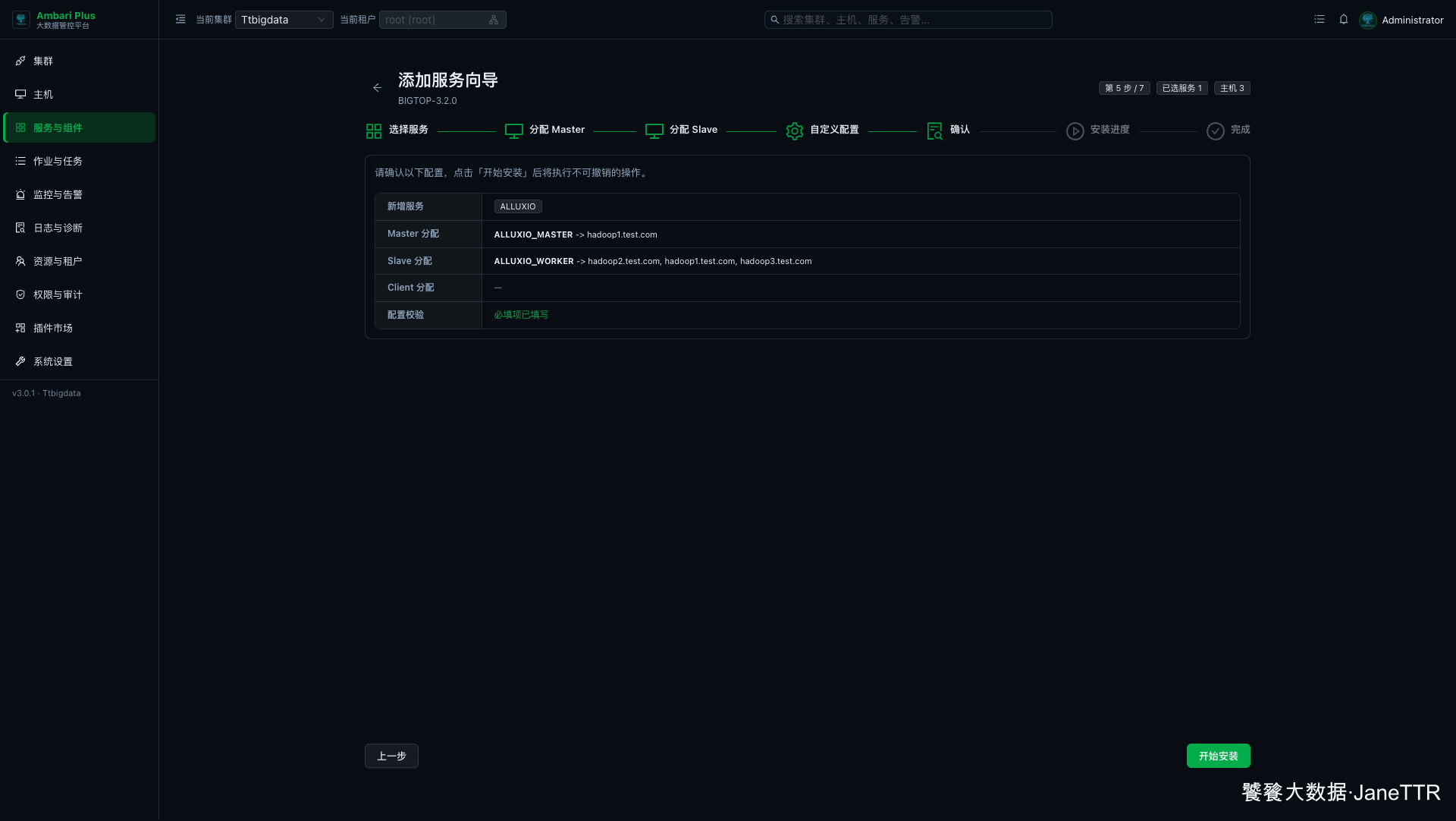
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | ALLUXIO |
| Master 分配 | ALLUXIO_MASTER -> hadoop1.test.com |
| Slave 分配 | ALLUXIO_WORKER -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| Client 分配 | 无 |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 6. 提交 Kerberos 凭据并等待安装
当前集群已经开启 Kerberos,新增 Alluxio 时会要求提交 KDC 管理员凭据。这里填写 KDC 管理员 Principal 和密码,用于生成 Alluxio 相关 principal 和 keytab。
凭据提交后进入安装进度页。Alluxio 会在三台主机上安装包、同步配置、刷新 Kerberos Client,并准备 Master / Worker 运行环境。
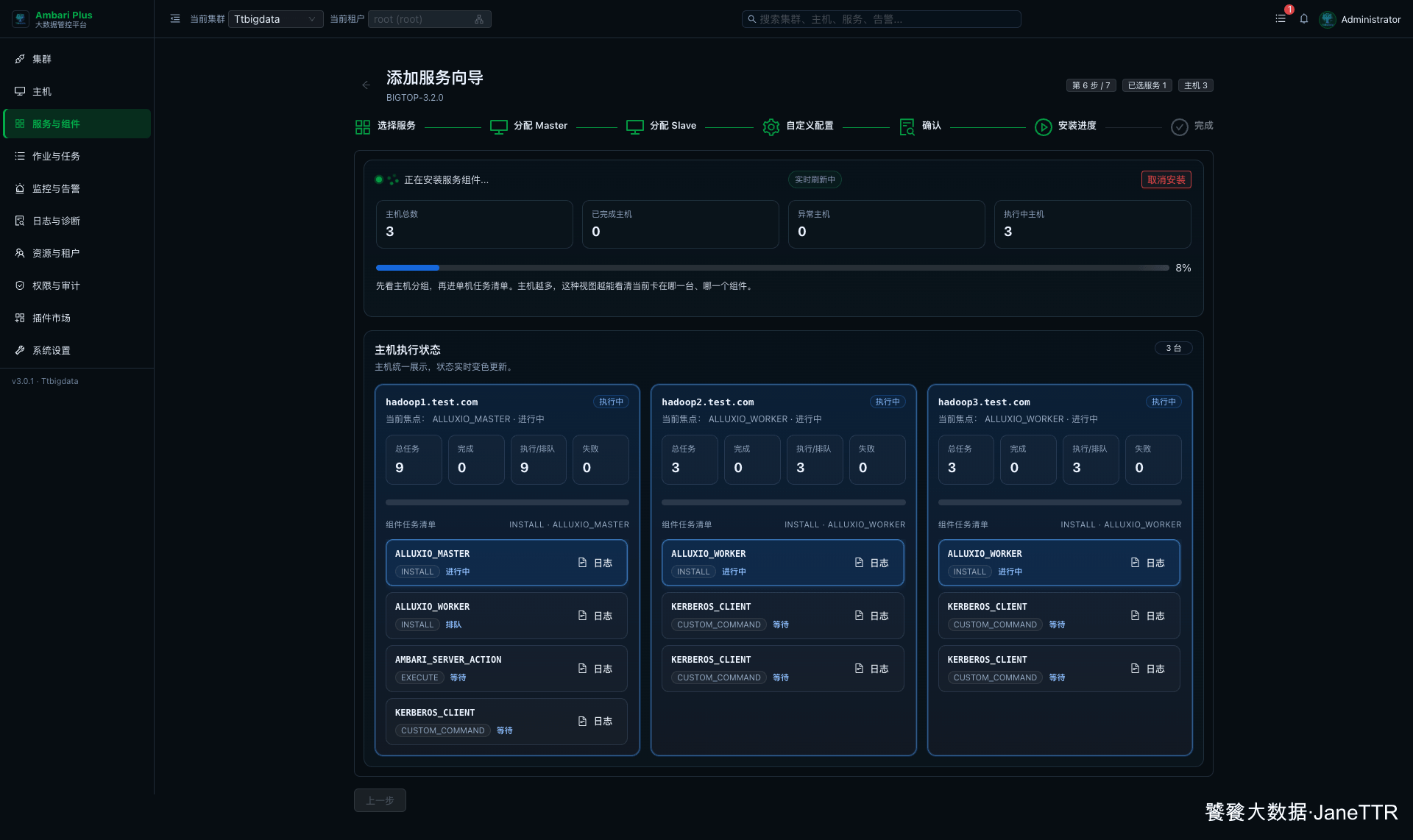
安装完成后,如果服务页显示 Alluxio 已安装但未运行,就进入服务操作启动 ALLUXIO。启动阶段会拉起 Master 和三台 Worker。
# 7. 回到服务列表确认 Alluxio
回到 服务与组件,搜索 alluxio。服务卡片里能看到 Alluxio Master 和 Alluxio Worker 都是运行中。
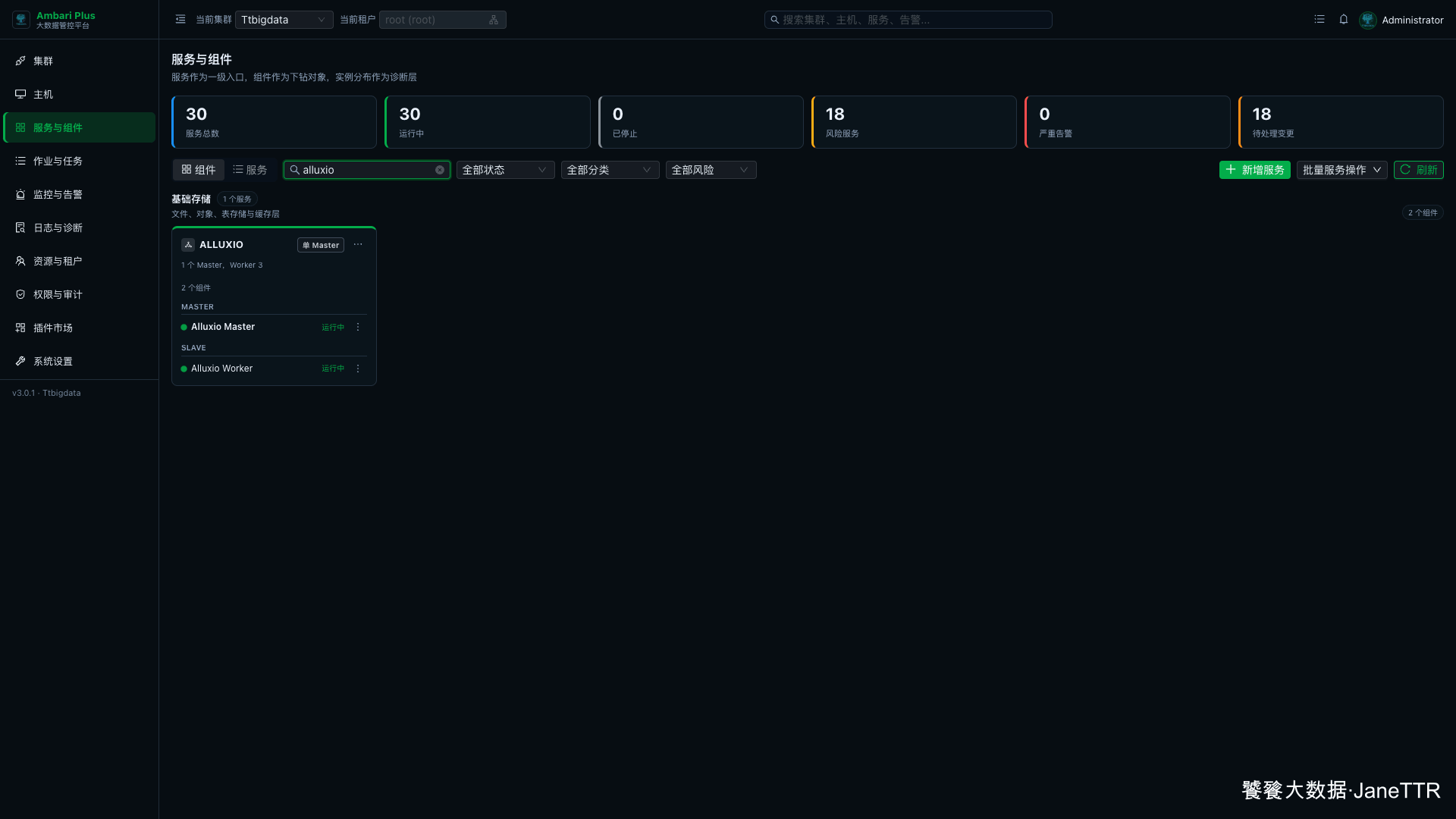
这一步我会重点确认:
| 检查项 | 期望结果 |
|---|---|
| Alluxio Master | 运行中。 |
| Alluxio Worker | 运行中,三台主机都有 Worker。 |
| 服务总数 | 新增后服务总数增加到 30。 |
如果 Worker 启动失败,优先看缓存目录、内存配置、HDFS underFS 权限和 Kerberos keytab。
# 8. 访问 Alluxio Web 页面
Alluxio Master Web 默认监听 19999,浏览器访问:
http://hadoop1.test.com:19999/
能看到 Alluxio Overview 页面,就说明 Master Web 已经起来。
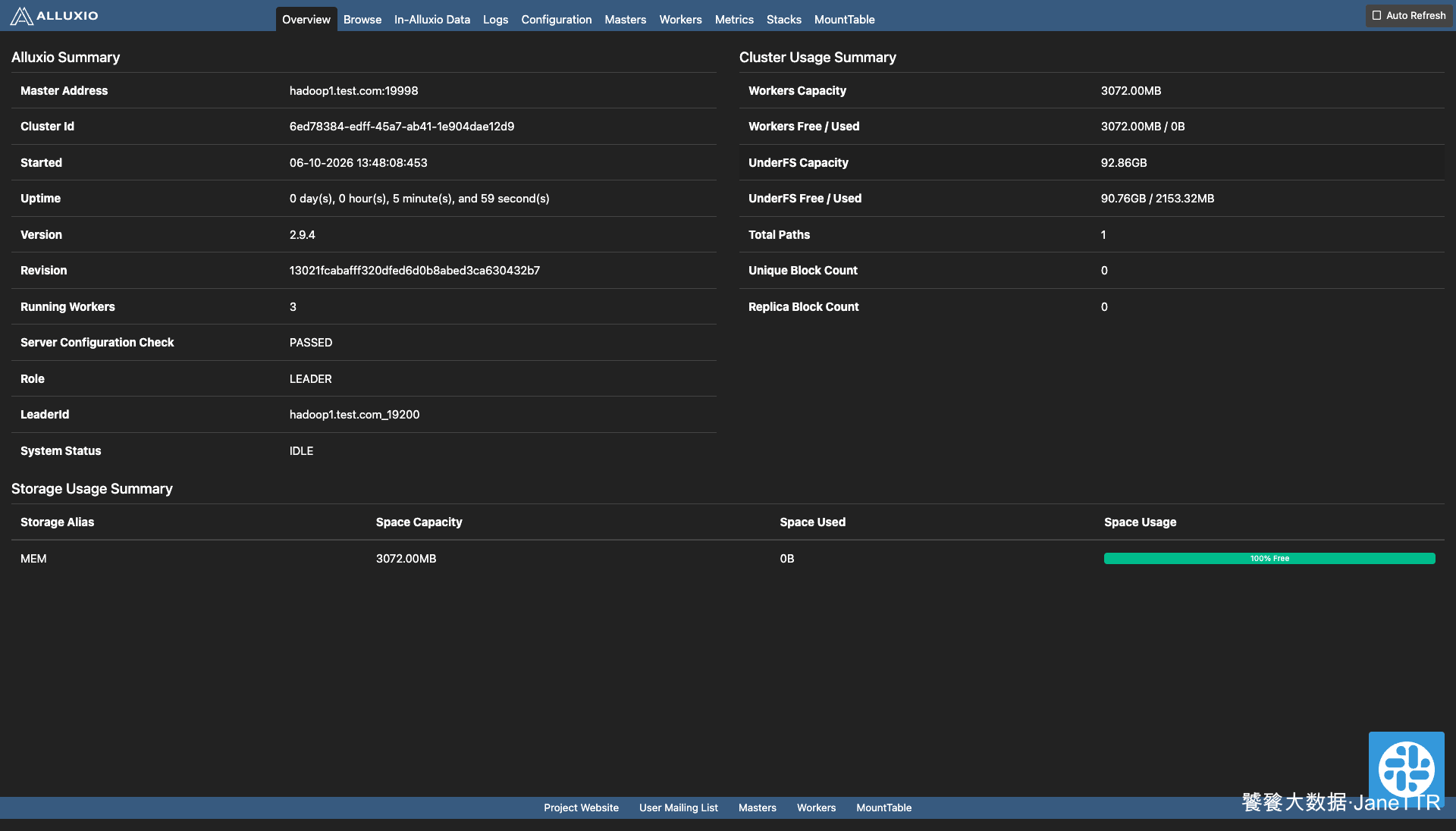
页面里可以重点看:
| 页面项 | 期望结果 |
|---|---|
| Master Address | hadoop1.test.com:19998 |
| Version | 2.9.4 |
| Running Workers | 3 |
| Server Configuration Check | PASSED |
到这里,Alluxio 的基础安装完成。后面如果要验证缓存效果,可以再结合 Spark 或 Trino 访问 Alluxio 路径,并观察 Worker 使用量变化。