 Paimon 安装1.0.1
Paimon 安装1.0.1
# Paimon 安装
Paimon 是湖仓表格式组件,常见用法是配合 Flink、Spark、Hive Metastore 和 HDFS,承接流批一体写入、增量更新和表管理。前面已经安装了 HDFS、Hive、Flink、Spark、Trino 等组件,这里补上 Paimon Client,后面在计算引擎里接 catalog 时就有基础环境了。
本篇继续使用三台 FQDN 主机:
| 主机 | Paimon 角色 |
|---|---|
hadoop1.test.com | PAIMON Client |
hadoop2.test.com | PAIMON Client |
hadoop3.test.com | PAIMON Client |
Paimon 在这套安装包里没有常驻 Master / Worker 服务,主要是下发客户端、配置 Hive Metastore 连接、Kerberos principal 和默认 warehouse 路径。所以安装完成后看到服务状态是“已安装”、实例分布是 0/1,这和 HDFS、YARN 这类常驻服务不一样。
提示
Paimon 本身不需要单独创建 MySQL / MariaDB 数据库。它在本文里使用 Hive Metastore 作为 catalog,warehouse 放到 HDFS 的 /warehouse/paimon。
# 1. 选择 Paimon 服务
进入 服务与组件,点击 新增服务,在服务列表中勾选 Paimon。
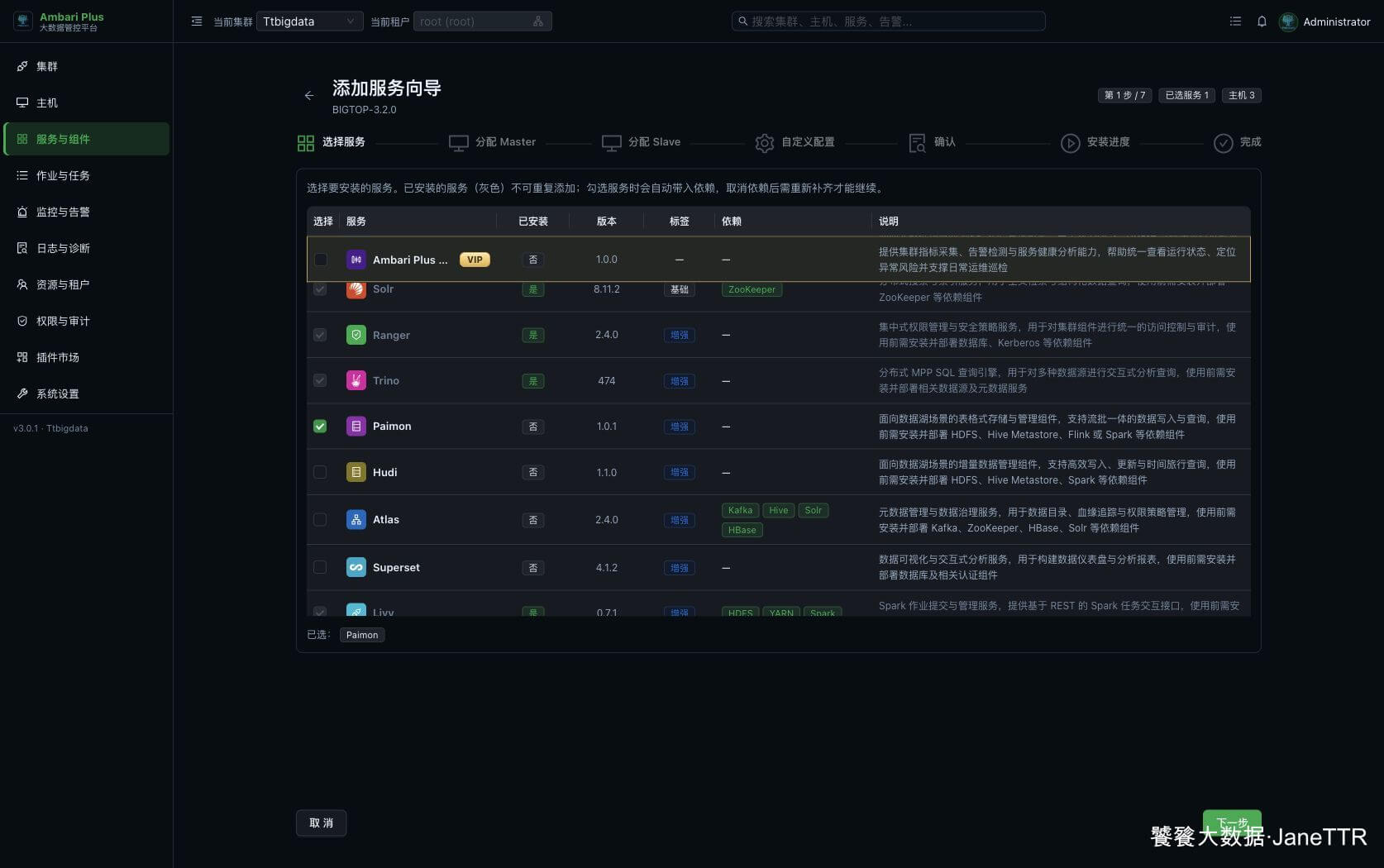
这里能看到 Paimon 版本是 1.0.1,安装状态为“否”。如果 HDFS、Hive、Flink、Spark 这些基础组件已经安装完成,直接勾选 Paimon 进入下一步即可。
# 2. Master 分配页直接下一步
Paimon 没有 Master 组件,所以 Master 分配页会提示“所选服务无 Master 组件,直接下一步”。
这一步不需要手工选择主机。页面左侧会列出当前集群里已经存在的 Master 角色,主要用于确认当前主机规划是否符合预期。
# 3. 分配 Paimon Client
Slave / Client 分配页也没有 Slave 组件,只有 PAIMON Client。
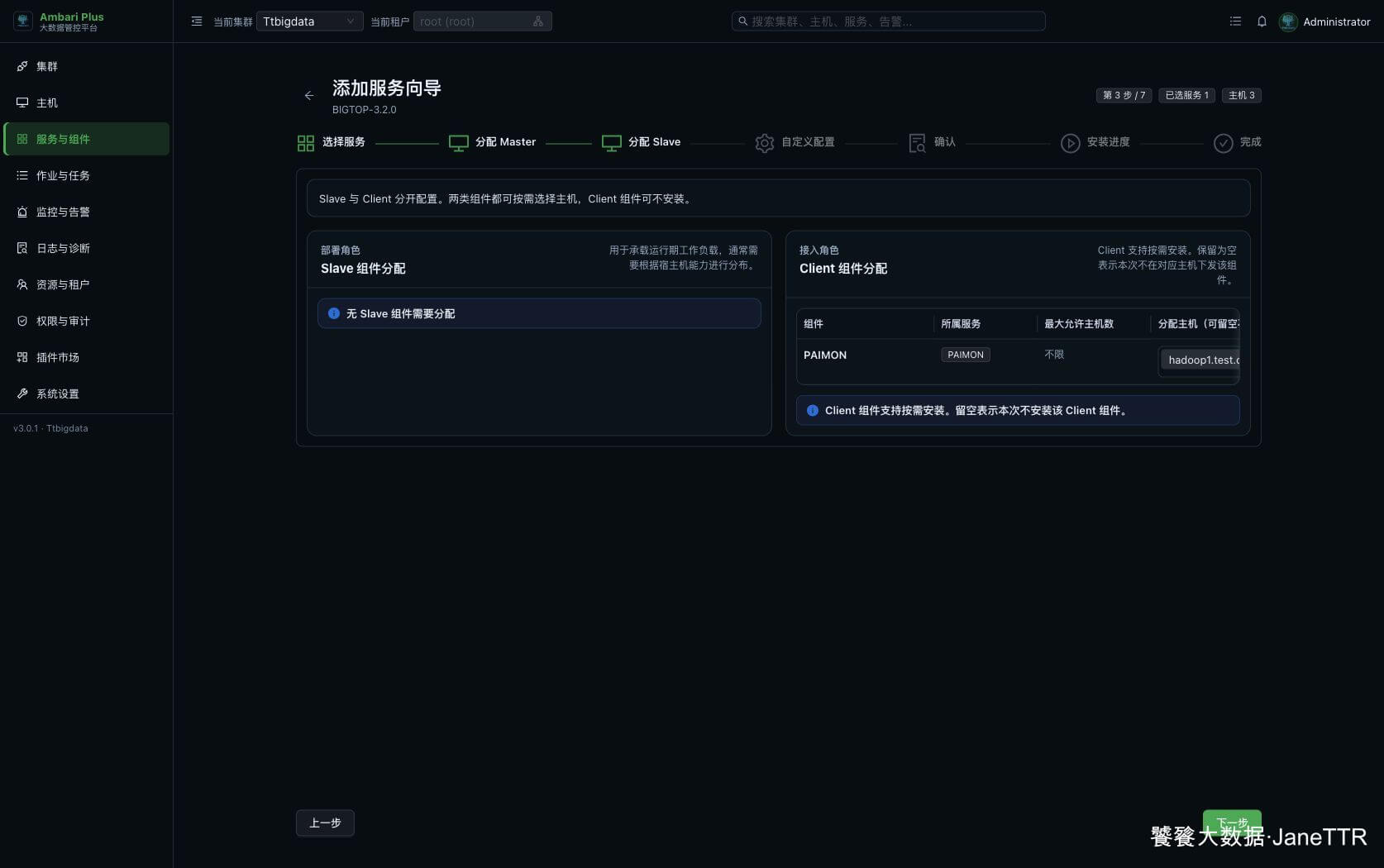
本次把 Paimon Client 分发到三台主机:
| 组件 | 分配主机 | 说明 |
|---|---|---|
PAIMON | hadoop1.test.com、hadoop2.test.com、hadoop3.test.com | 下发 Paimon 相关客户端文件和配置,方便后续从任意节点配合 Flink / Spark / Hive 调试。 |
这里我建议三台都安装。Paimon 后面通常会被不同计算引擎调用,如果只装在一台机器上,排查 Flink、Spark 或命令行作业时容易出现“某台机器缺少客户端文件”的问题。
# 4. 检查 Paimon 配置
进入自定义配置页后,先看 paimon-site。页面会根据集群拓扑预填配置,但 Paimon 这里有几个值一定要人工确认。
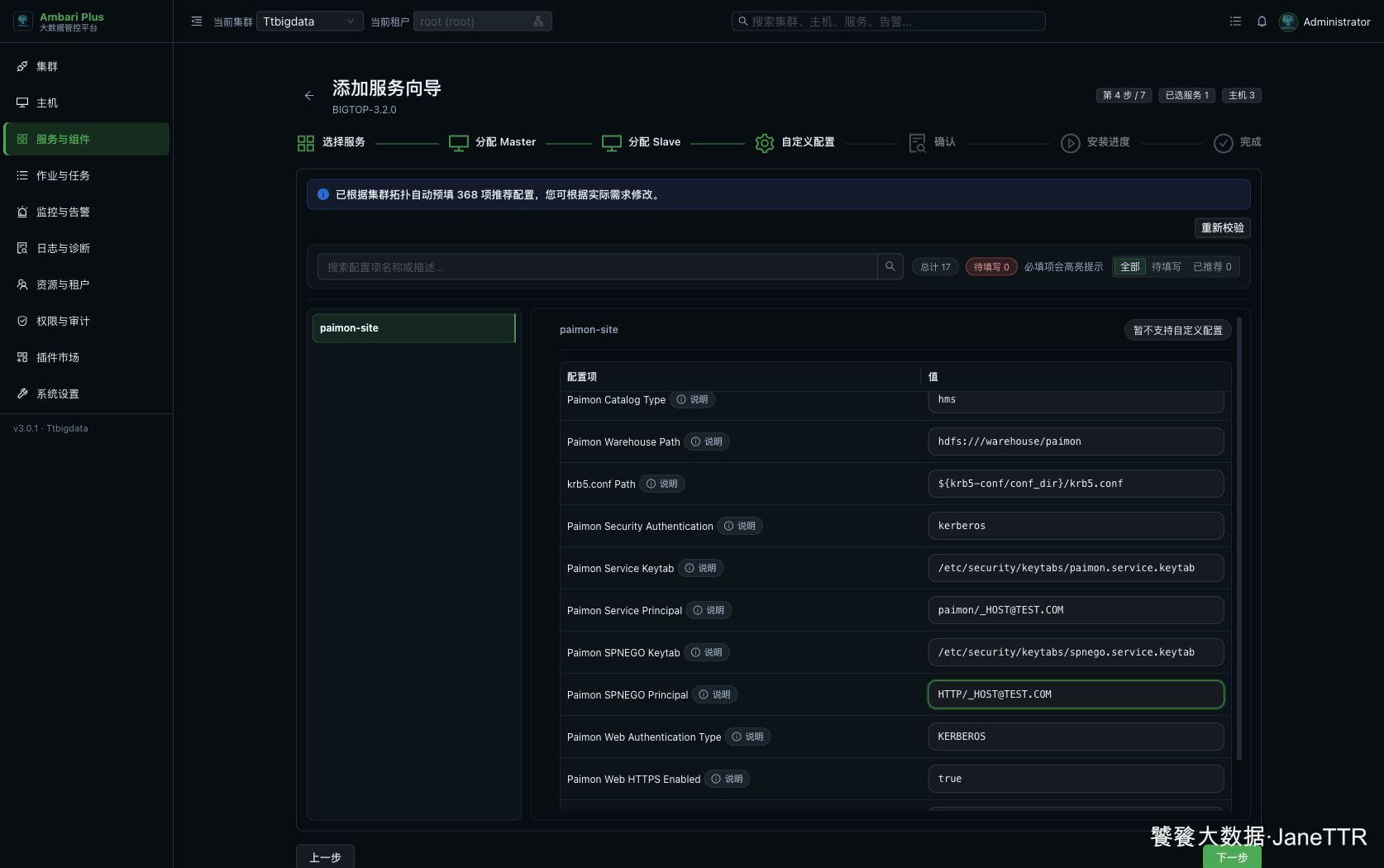
本篇环境里重点确认下面这些配置:
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
hive.metastore.uris | thrift://hadoop2.test.com:9083 | 指向当前 Hive Metastore。不要保留模板变量。 |
hive.metastore.principal | hive/[email protected] | Kerberos 集群里必须和 Hive 的 Metastore principal 一致。 |
paimon.catalog.type | hms | 使用 Hive Metastore 作为 Paimon catalog。 |
paimon.catalog.warehouse | hdfs:///warehouse/paimon | Paimon 默认 warehouse 目录。 |
paimon.security.authentication | kerberos | 当前集群已开启 Kerberos。 |
paimon.service.principal | paimon/[email protected] | Paimon 服务 principal。 |
paimon.web.authentication.kerberos.principal | HTTP/[email protected] | Web / SPNEGO principal。 |
如果页面里看到 EXAMPLE.COM,要改成当前集群的 realm。本文环境使用 TEST.COM。如果 hive.metastore.uris 仍然显示 ,也要改成实际 Metastore 地址。
# 5. 确认安装清单
确认页会展示本次新增服务、组件分配和配置校验结果。
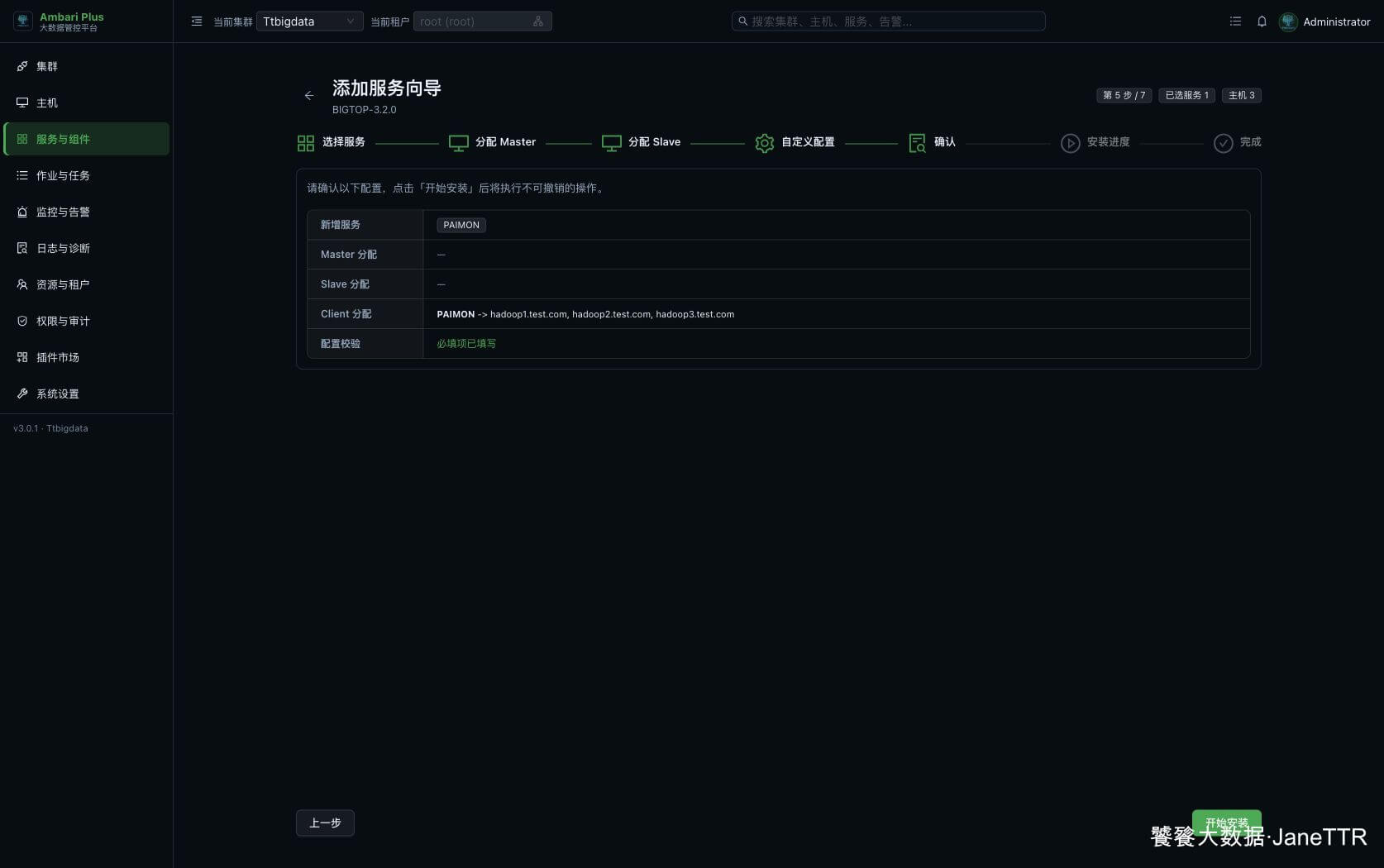
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | PAIMON |
| Master 分配 | 无 |
| Slave 分配 | 无 |
| Client 分配 | PAIMON -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 6. 提交 Kerberos 凭据并等待安装
开启 Kerberos 的集群中,新增 Paimon 会要求提交 KDC 管理员凭据。这里填写 KDC 管理员 Principal 和密码,用于生成并分发 Paimon 相关 principal / keytab。
凭据提交后,安装页会进入主机任务视图。Paimon 是客户端组件,主要任务是安装软件包、分发 keytab、刷新 Kerberos Client 和下发配置。
三台主机执行完成后,页面会显示 PAIMON 安装成功。
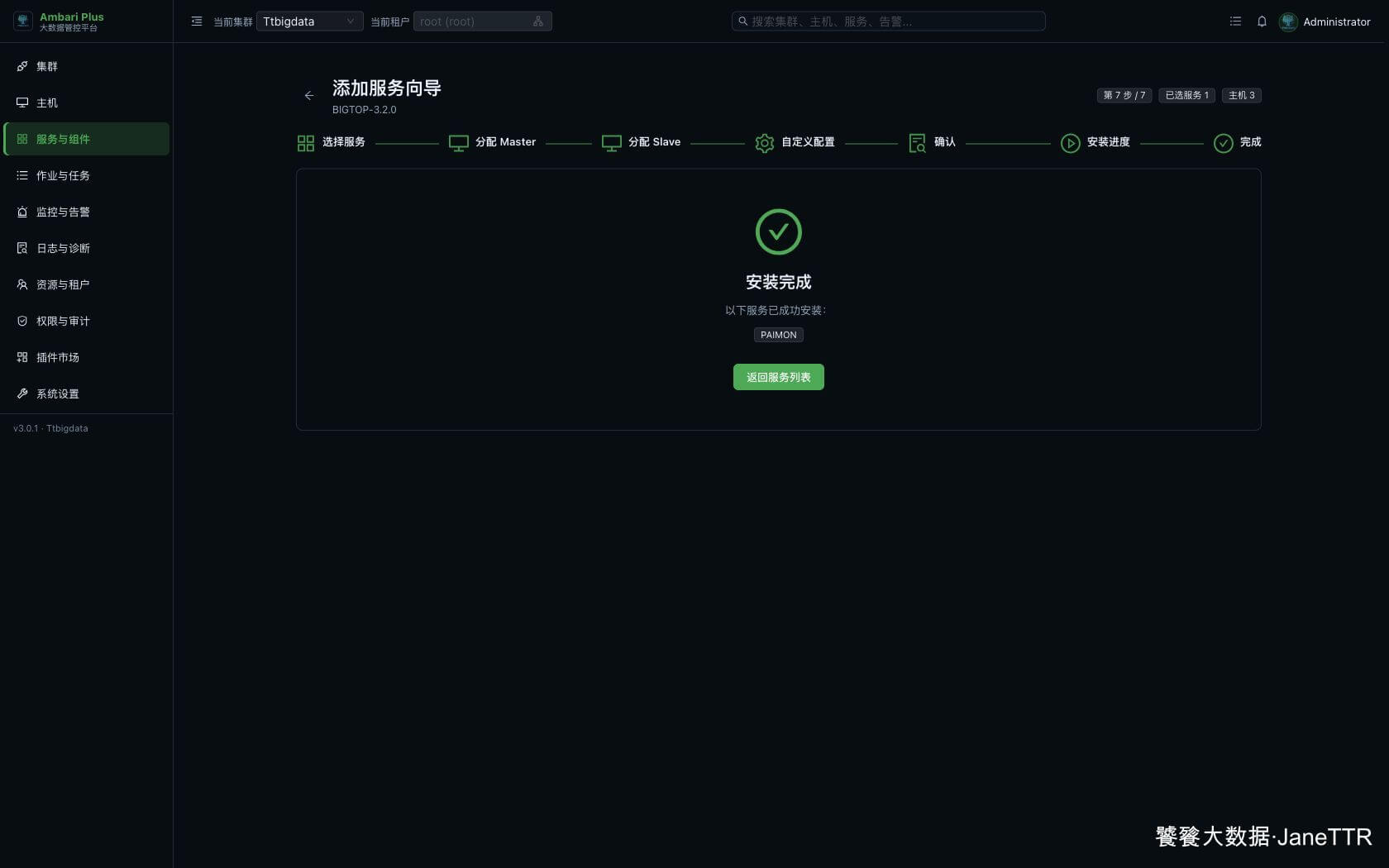
如果安装阶段失败,优先打开失败主机的任务日志。Paimon 常见问题主要集中在 Kerberos 凭据、客户端包安装和配置值不正确。
# 7. 回到服务列表确认 Paimon
返回 服务与组件 页面,可以看到查询数据分类下新增了 PAIMON。
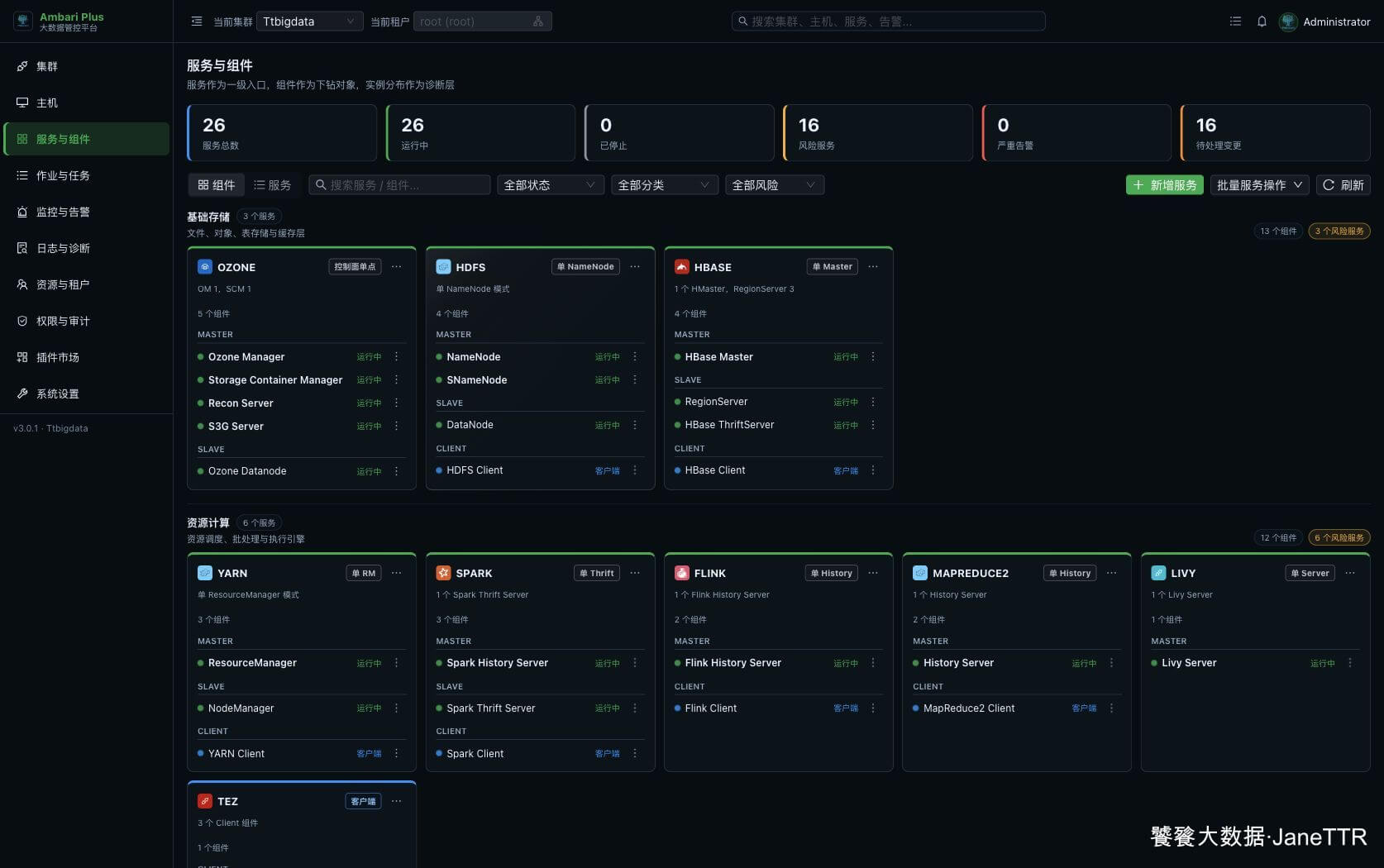
页面里会显示 3 个 Client 组件,这说明三台主机都已经下发 Paimon Client。Paimon 没有常驻进程,所以这里不会像 Trino Worker、HiveServer2 那样显示运行中的服务进程数。
# 8. 查看实例分布
进入 PAIMON 详情页,打开 实例分布。
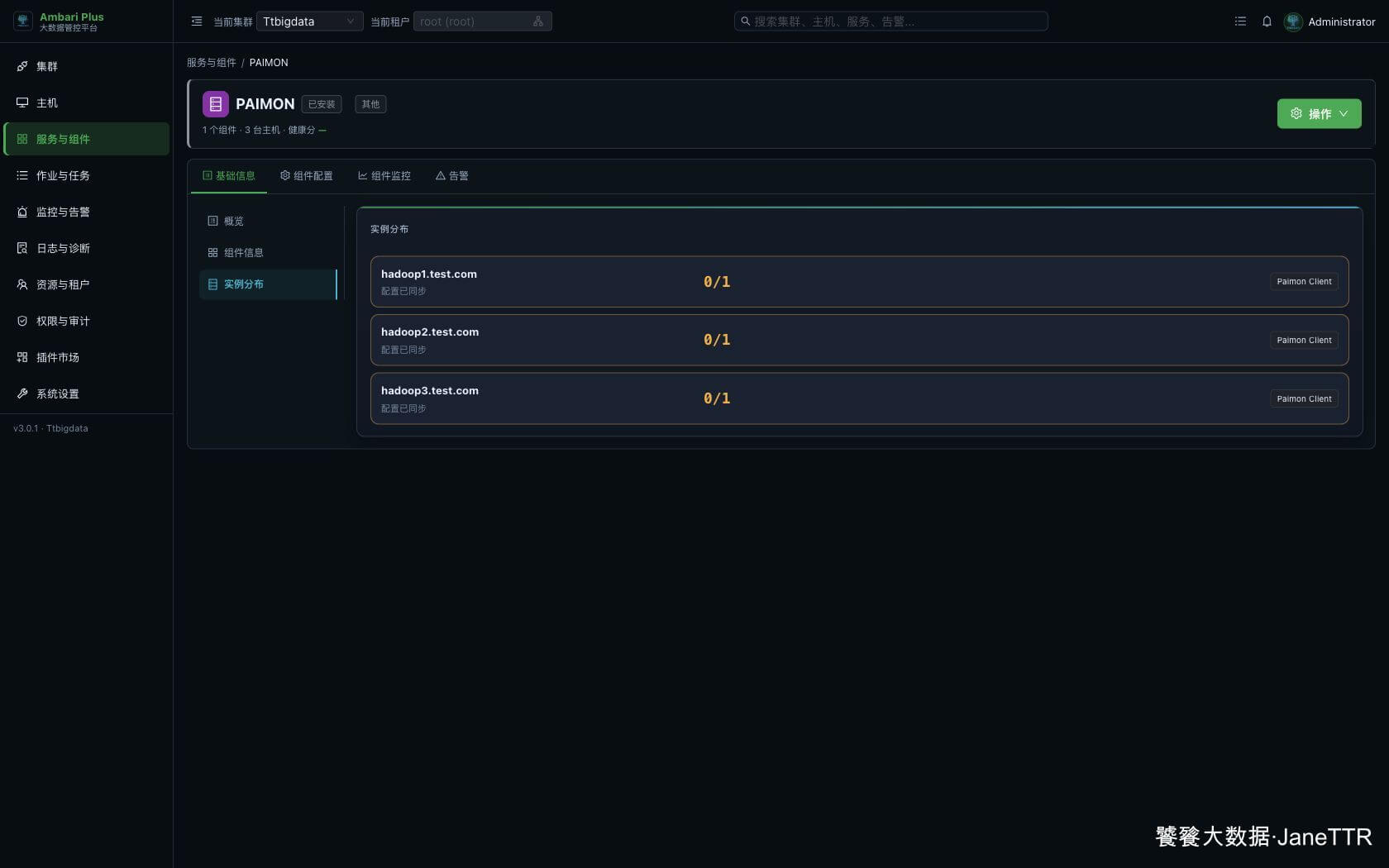
页面里可以看到:
| 主机 | 组件 | 状态说明 |
|---|---|---|
hadoop1.test.com | Paimon Client | 客户端已安装 |
hadoop2.test.com | Paimon Client | 客户端已安装 |
hadoop3.test.com | Paimon Client | 客户端已安装 |
这里三台主机都显示 0/1 是正常现象。Paimon Client 不是常驻服务,不会有运行中的进程;只要页面显示配置已同步,且组件出现在三台主机上,就说明客户端分发完成。
# 9. 安装后再看一次关键配置
Paimon 安装完成后,我会再回到 组件配置,确认最终生效的配置。
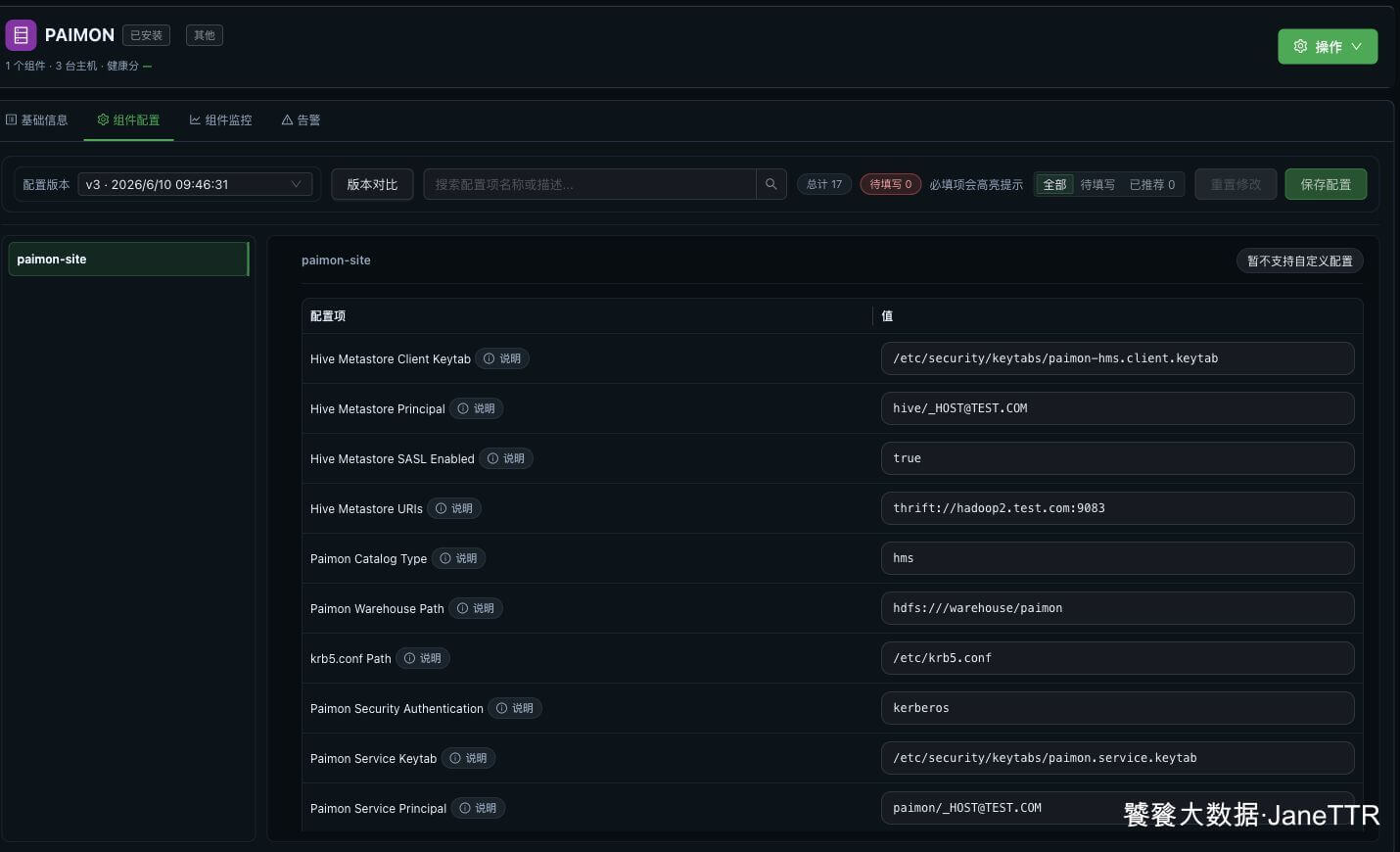
这张图里重点看三件事:
| 检查项 | 期望值 |
|---|---|
| Hive Metastore Principal | hive/[email protected] |
| Hive Metastore URIs | thrift://hadoop2.test.com:9083 |
| Paimon Warehouse Path | hdfs:///warehouse/paimon |
如果这里仍然是 或 EXAMPLE.COM,建议先改成实际值再继续往后接 Flink / Spark catalog。
# 10. 确认 HDFS warehouse 目录
最后确认一下 warehouse 目录。当前集群开启了 Kerberos,所以先用 HDFS 的 keytab 认证,再检查目录:
kinit -kt /etc/security/keytabs/hdfs.headless.keytab [email protected]
hdfs dfs -ls -d /warehouse/paimon
2
期望能看到类似结果:
drwxrwxr-x - paimon hadoop 0 2026-06-10 09:31 /warehouse/paimon
如果目录不存在,可以创建并授权:
hdfs dfs -mkdir -p /warehouse/paimon
hdfs dfs -chown -R paimon:hadoop /warehouse/paimon
hdfs dfs -chmod 775 /warehouse/paimon
2
3
到这里,Paimon Client 已经安装到三台主机,Hive Metastore、Kerberos principal 和 HDFS warehouse 也确认完成。后面再接 Flink / Spark 的 Paimon catalog 时,就不用回头补客户端和基础目录了。
下一篇继续安装 Hudi,把另一个常用湖表组件的客户端环境也补齐。