 HDFS 开启 HA3.0.1
HDFS 开启 HA3.0.1
# HDFS 开启 HA
HDFS 装好以后,默认通常是单 NameNode。这个形态适合先把集群搭起来,但不适合长期运行:NameNode 一旦不可用,HDFS 入口就会跟着不可用,依赖 HDFS 的 Hive、HBase、Spark、Flink 等服务也会受影响。
Ambari Plus 里开启 HDFS HA 不需要手工改一堆 XML。正常路径就是进入 HDFS 运维向导,选择 Standby NameNode 和 JournalNode 主机,确认预览后让向导自动执行。本文按页面操作走一遍。
本次示例规划如下:
| 项目 | 本次选择 |
|---|---|
| Nameservice | haCluster |
| 当前 NameNode | hadoop1.test.com |
| 新增 Standby NameNode | hadoop2.test.com |
| JournalNode | hadoop1.test.com、hadoop2.test.com、hadoop3.test.com |
| HDFS 访问入口 | hdfs://haCluster |
注意
点击 进入执行 以后,向导会停止和启动相关服务,并完成 HA 元数据初始化。建议放在维护窗口里操作。
# 操作前看一眼
先进入 服务与组件,找到 HDFS。当前卡片显示的是 单 NameNode 模式,这说明它还没有开启 NameNode HA。
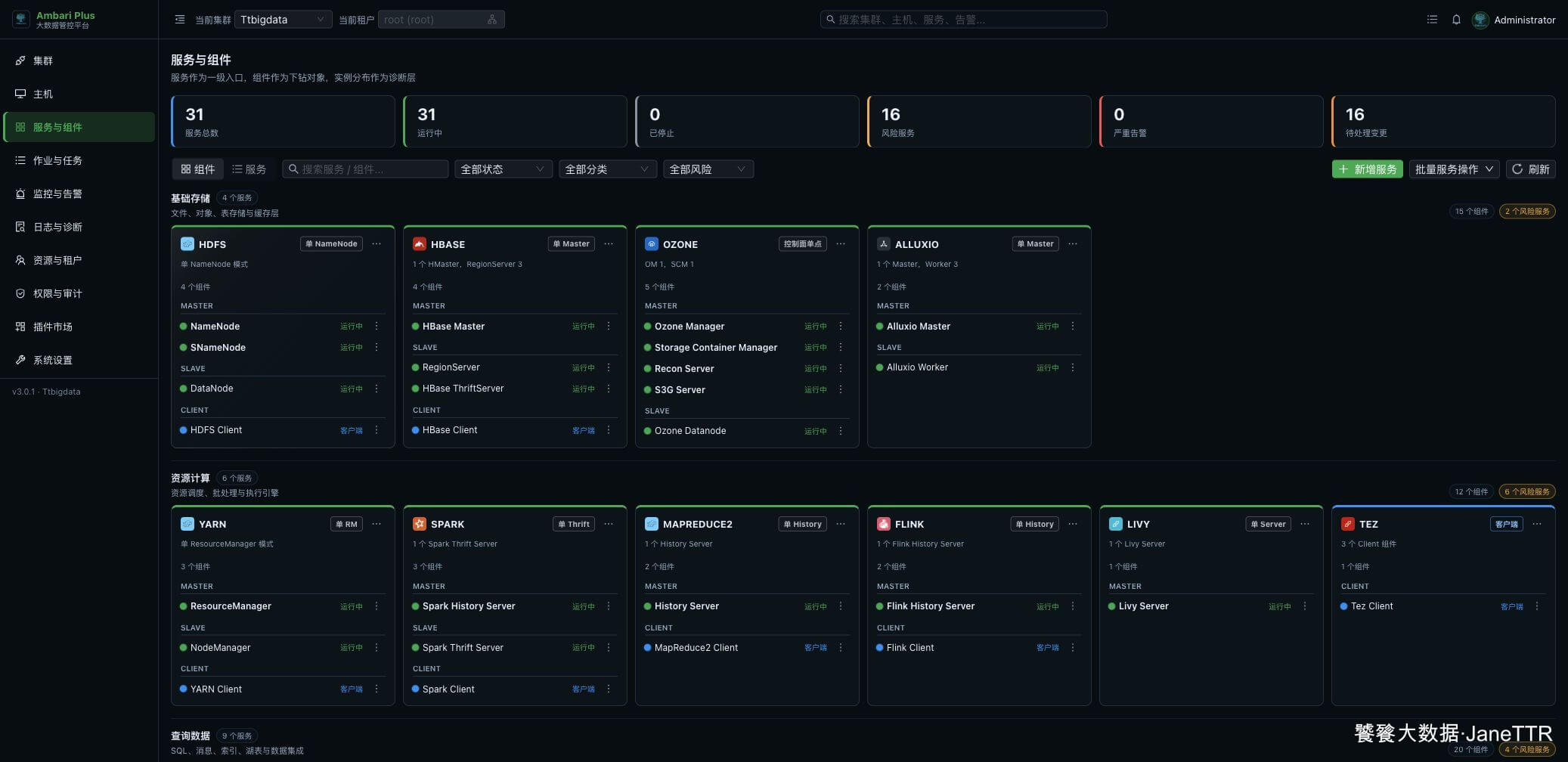
我会在这里先确认三件事:
| 检查项 | 为什么要看 |
|---|---|
| HDFS 是运行中 | 向导要基于当前 NameNode 做 checkpoint 和配置变更。 |
| ZooKeeper 已运行 | 后面 ZKFC 会依赖 ZooKeeper 做主备选举。 |
| 没有明显失败任务 | 如果服务本来就有失败任务,先处理掉会更稳。 |
如果页面已经显示 HA 已启用,就不要再按这篇做“首次开启”,应该直接去看现有 HA 拓扑。
# 进入 HDFS 运维向导
点击 HDFS 卡片进入详情页,右上角有 操作 按钮。
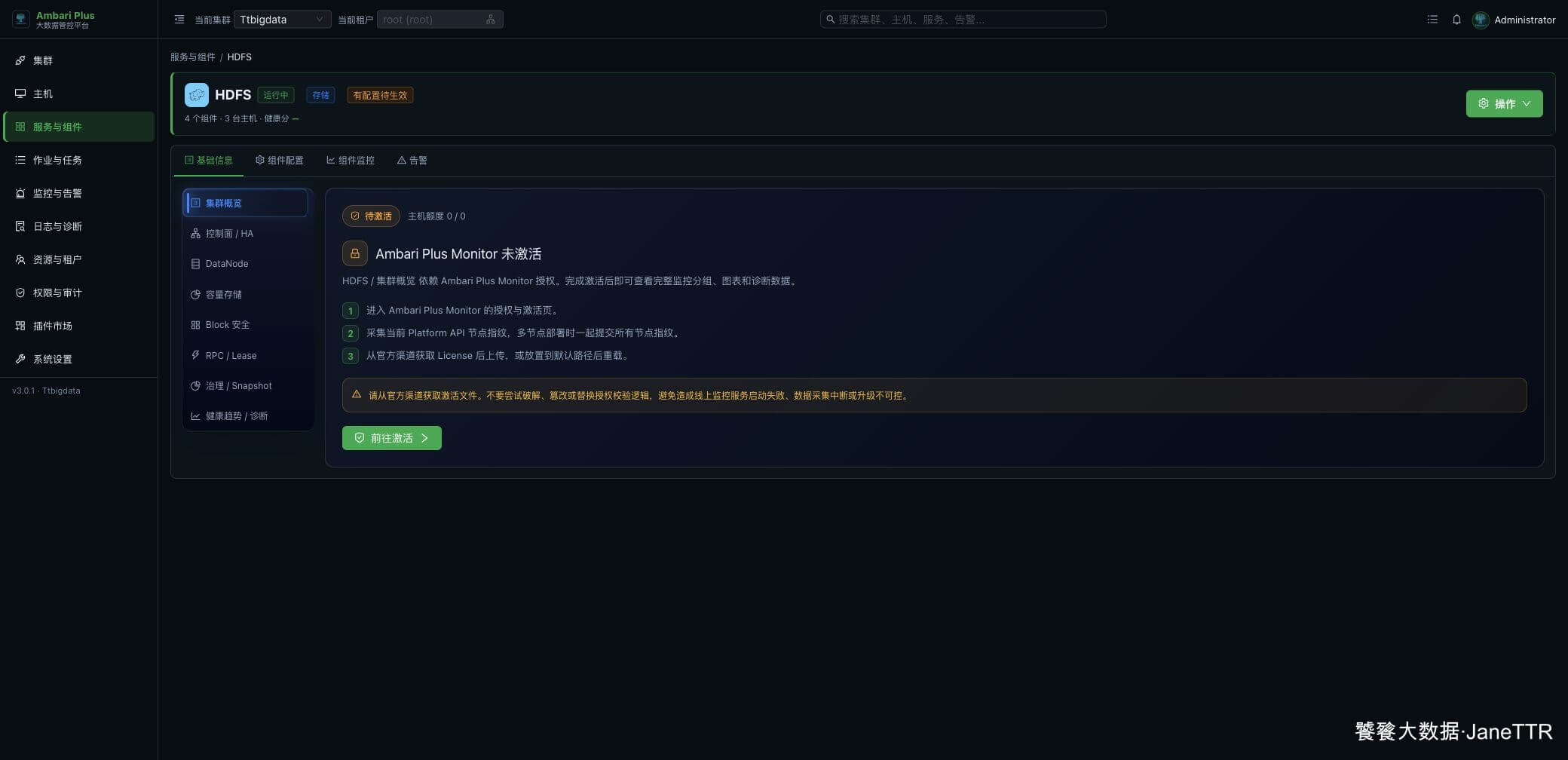
展开操作菜单,选择 HDFS 运维向导。
进入 HDFS Operations 页面以后,选择 启用 NameNode HA。
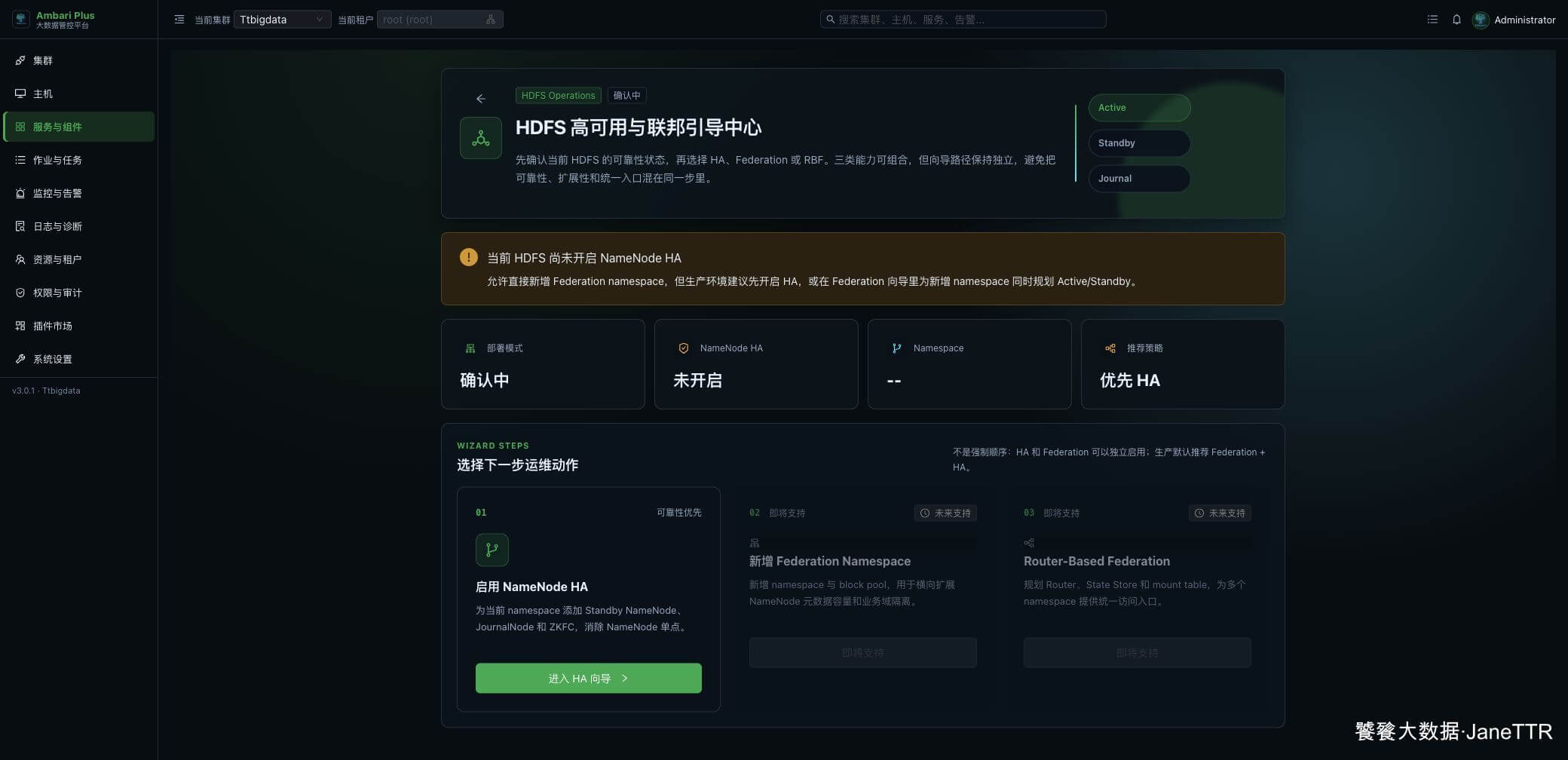
这个页面还会看到 Federation 相关入口。普通三节点环境先做 NameNode HA 就够了,不需要把 Federation 一起做进去。
# 填写 HA 参数
点击 进入 HA 向导,第一步是配置 HA 参数。页面会自动识别当前 NameNode,并要求选择一个新的 Additional NameNode。
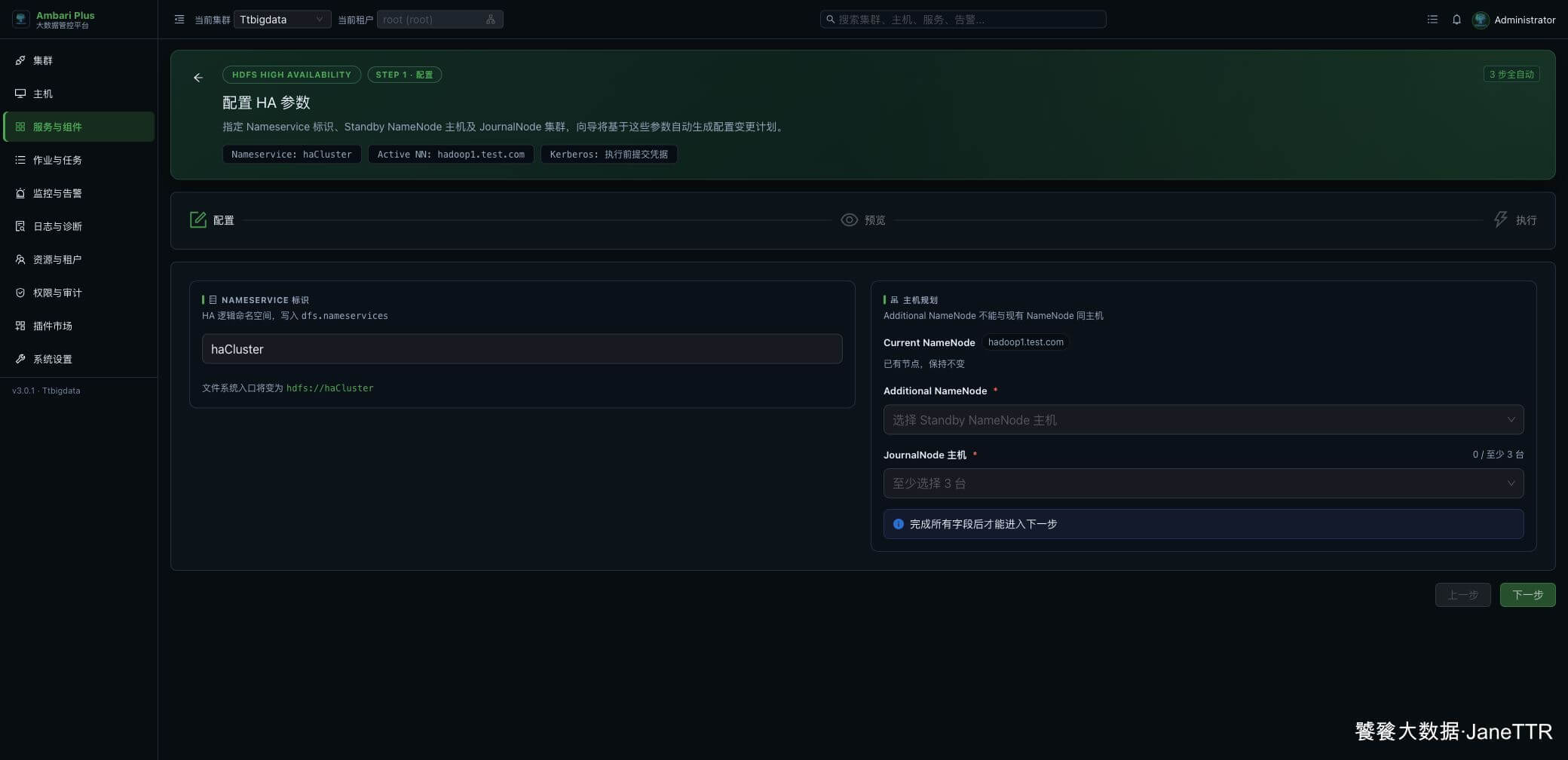
这里按规划填写:
| 参数 | 填写方式 |
|---|---|
| Nameservice | 保持 haCluster,或按自己的命名规范填写一个稳定名称。 |
| Current NameNode | 保持当前 NameNode,不需要调整。 |
| Additional NameNode | 选择另一台主机作为 Standby NameNode。 |
| JournalNode 主机 | 三节点环境建议三台都选。 |
选完后,页面会提示 主机规划完成,可以继续预览变更,右下角 下一步 会变成可点击。
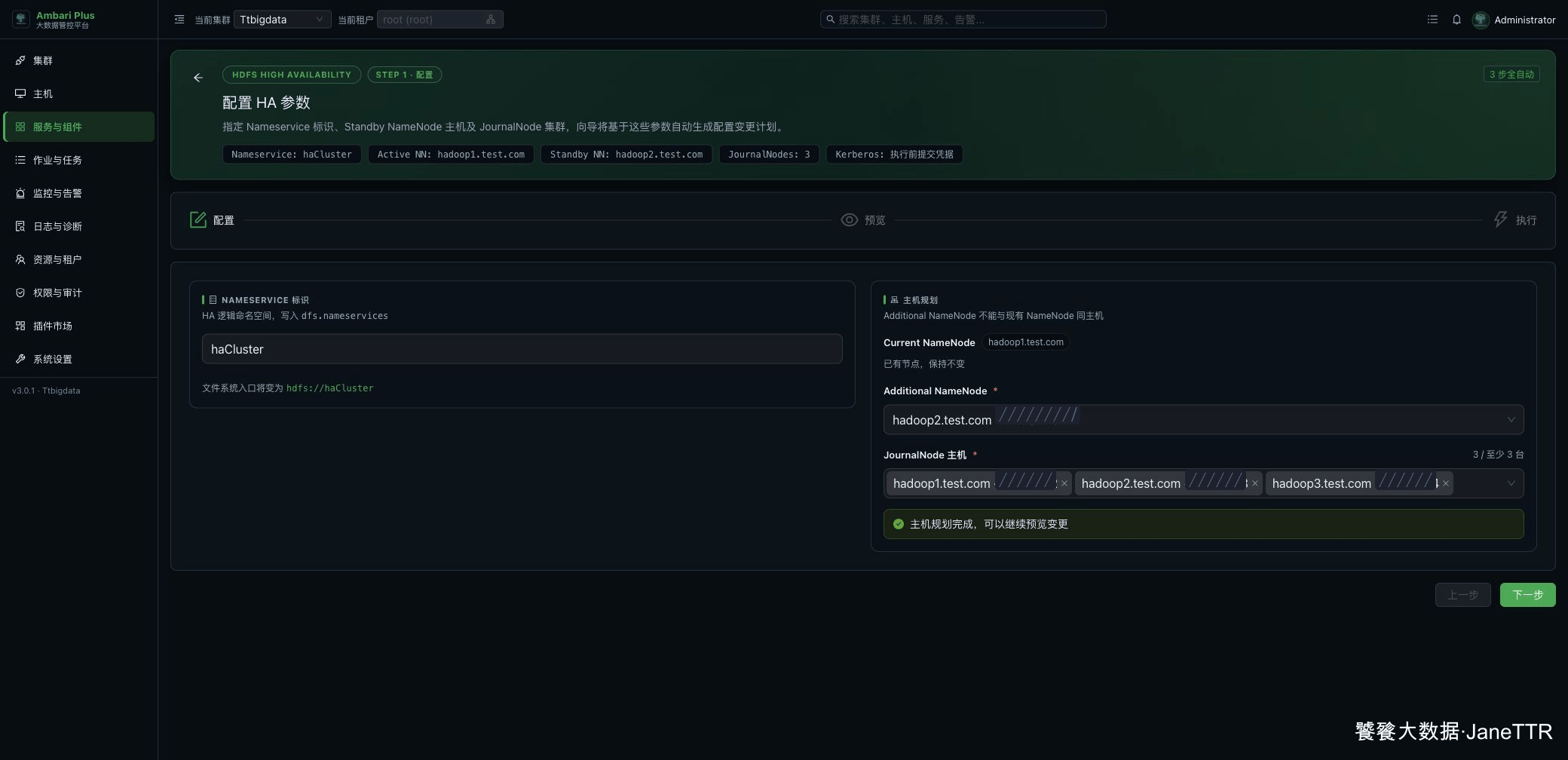
提示
Nameservice 会成为后续客户端访问 HDFS 的逻辑入口,例如 hdfs://haCluster。我建议用短一些、稳定一些的名字,不要写临时项目名。
# 预览并执行
点击 下一步 后进入预览页。这里先别急着执行,快速看两类信息:一类是组件操作计划,另一类是配置变更。
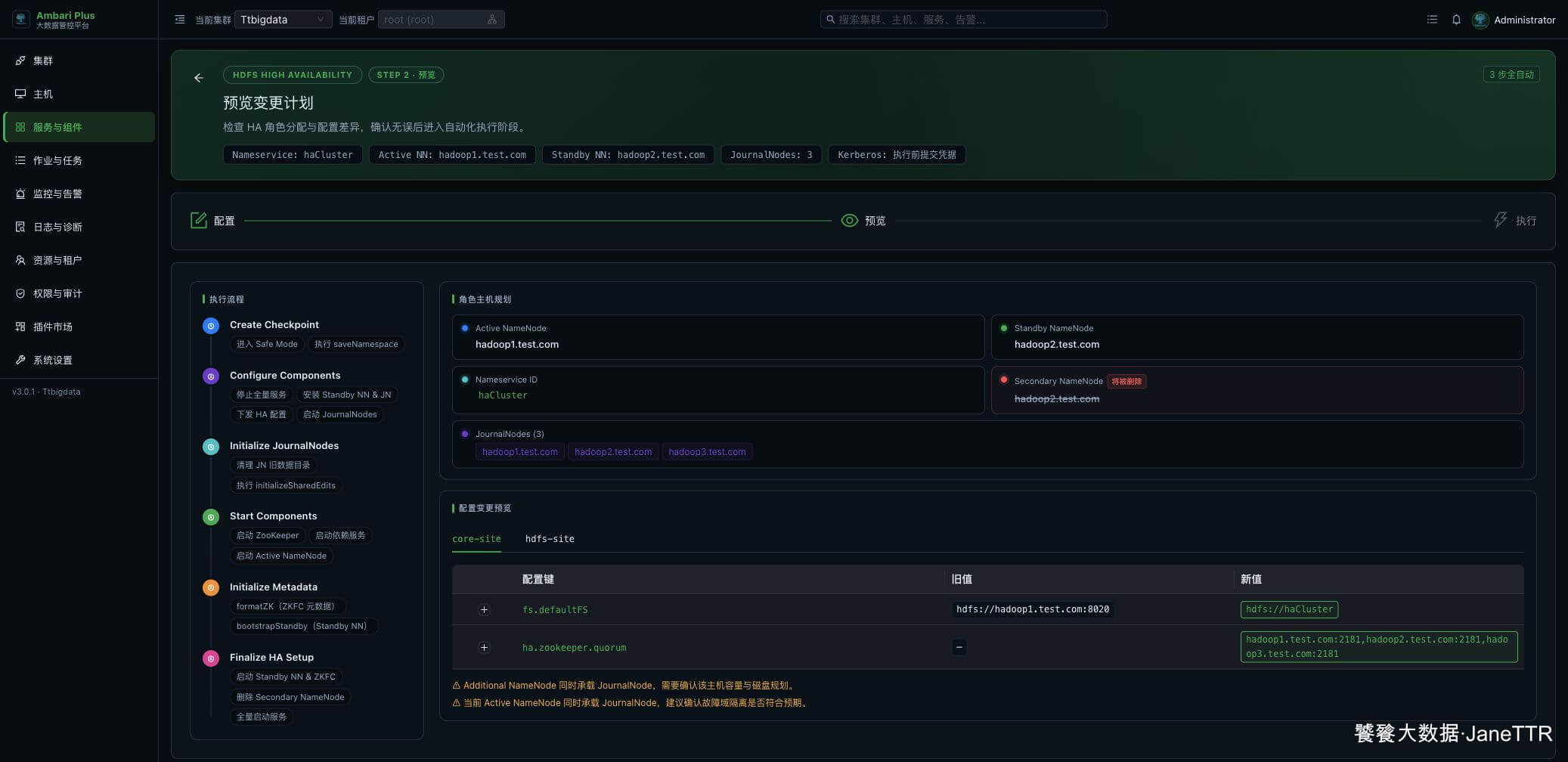
预览页里能看到向导会依次完成这些动作:
| 阶段 | 页面会做什么 |
|---|---|
| Create Checkpoint | 保存当前 NameNode 命名空间。 |
| Configure Components | 安装新增 NameNode、JournalNode,并下发 HA 配置。 |
| Initialize JournalNodes | 初始化共享 edits。 |
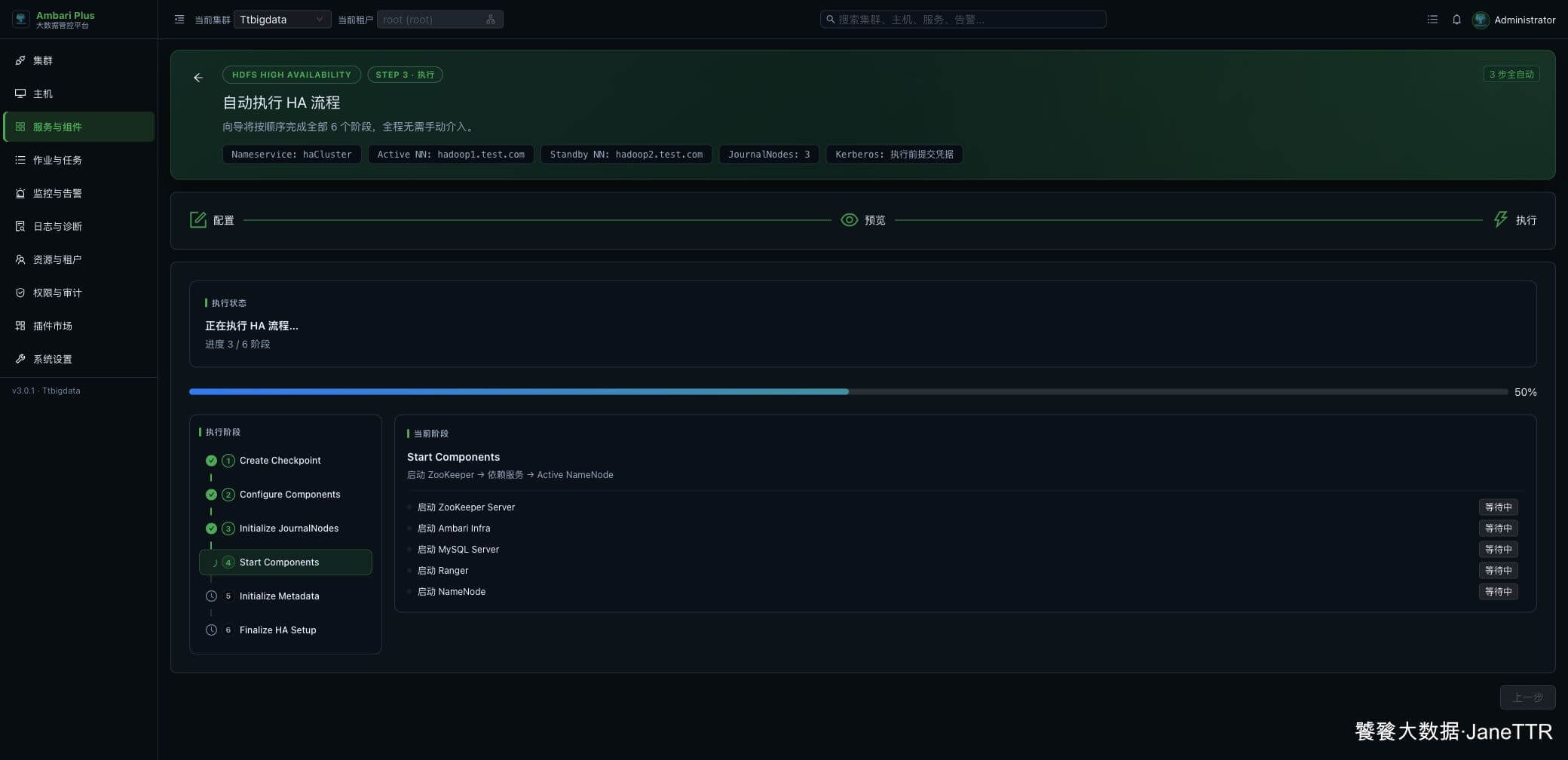
| Start Components | 启动 ZooKeeper、依赖服务和 Active NameNode。 |
| Initialize Metadata | 初始化 ZKFC 元数据并 bootstrap Standby NameNode。 |
| Finalize HA Setup | 启动 Standby NameNode 和 ZKFC,移除 Secondary NameNode。 |
确认无误后,点击 进入执行。如果环境启用了 Kerberos,页面会弹出凭据输入框,按你前面 Kerberos 教程里准备的管理员账号填写即可。
执行页会按阶段滚动推进。看到左侧阶段逐个变成绿色对勾,就说明向导正在正常往下走。
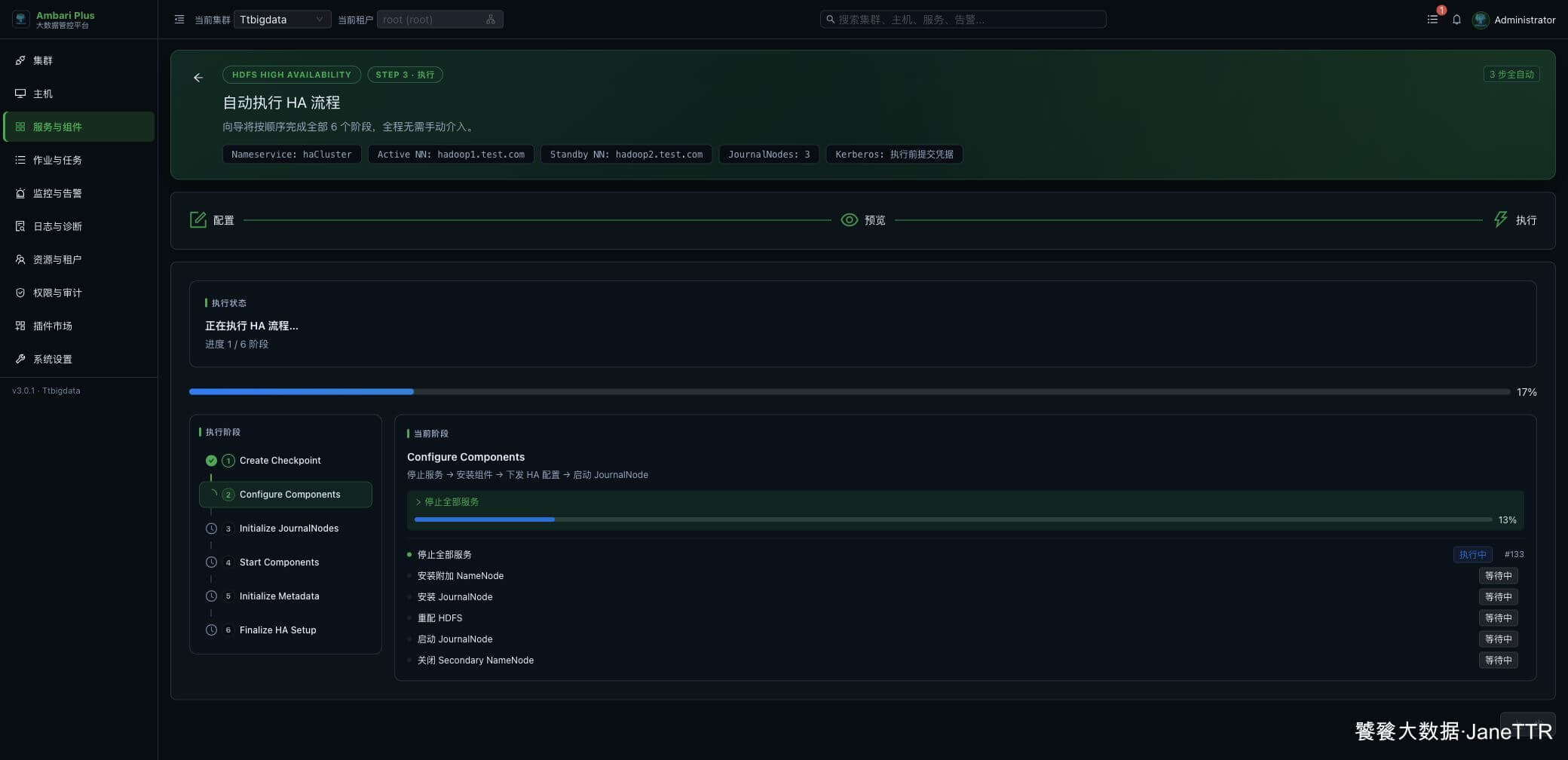
后面进入 Start Components 时,页面会启动 ZooKeeper、相关依赖服务和 Active NameNode。
笔记
如果最后一轮“启动全部服务”里有别的组件失败,先回到 HDFS 服务页看 HDFS 本身是否已经完成 HA。只要 HDFS 已经运行、NameNode / JournalNode / ZKFC 都正常,HDFS HA 就已经打开了;其他组件可以按各自服务再单独处理。
# 回到页面确认结果
向导完成后,回到 服务与组件 查看 HDFS。完成后的 HDFS 会从单 NameNode 模式变成 HA 拓扑,页面上能看到类似 双 NameNode 自动切换拓扑、HA 已启用 这样的状态。
然后进入 HDFS 详情页,重点看这几项:
| 位置 | 期望看到 |
|---|---|
| HDFS 服务状态 | 运行中 |
| NameNode | 运行中,有两个实例 |
| JournalNode | 运行中,三台主机都有 |
| ZKFailoverController | 运行中,两个 NameNode 主机上都有 |
| DataNode | 运行中 |
| Secondary NameNode | 不再作为 HA 架构里的实例出现 |
本次现场完成后,HDFS 服务为 STARTED,NameNode、JournalNode、ZKFC、DataNode 都是运行状态,HDFS 告警没有 Critical 和 Warning。客户端入口也已经切到 hdfs://haCluster。
对日常安装来说,看到这些页面状态就可以认为 HDFS HA 已经开启完成。后面如果 Hive、HBase、Spark、Flink、Hue 等服务提示配置待生效,按页面提示刷新客户端配置或重启对应服务即可。
可选:命令复核
页面已经能完成主要判断。生产变更后如果想再从服务器侧确认一次,可以用下面几条命令复核:
sudo -iu hdfs
hdfs getconf -confKey dfs.nameservices
hdfs getconf -confKey fs.defaultFS
hdfs getconf -confKey dfs.ha.namenodes.haCluster
2
3
4
期望看到:
haCluster
hdfs://haCluster
nn1,nn2
2
3
再看两个 NameNode 的主备状态:
hdfs haadmin -getServiceState nn1
hdfs haadmin -getServiceState nn2
2
一个应该返回 active,另一个返回 standby。最后可以做一次简单读写:
hdfs dfs -mkdir -p /tmp/ha-check
date | hdfs dfs -put -f - /tmp/ha-check/hdfs-ha-$(date +%Y%m%d%H%M%S).txt
hdfs dfs -ls /tmp/ha-check
2
3
本次现场复核结果是 nn1=standby、nn2=active,并成功写入 /tmp/ha-check/hdfs-ha-20260610184519.txt。
# 常见卡点
| 现象 | 处理思路 |
|---|---|
| Additional NameNode 选不了 | 确认不要和当前 NameNode 选在同一台主机。 |
| JournalNode 数量不足 | 至少准备 3 个 JournalNode,三节点环境通常三台都选。 |
| 执行页停在某个阶段 | 点开当前阶段的任务详情,看具体失败组件和日志。 |
| HDFS 已完成,但其他服务启动失败 | 先确认 HDFS HA 状态,再单独处理失败服务。 |
| 客户端还访问旧 NameNode | 刷新 HDFS Client 配置,必要时重启依赖 HDFS 的服务。 |
HDFS HA 做完以后,HDFS 的访问入口就从物理 NameNode 地址切到了逻辑 Nameservice。下一步如果要继续消除控制面单点,可以接着做 YARN ResourceManager HA。