 Zeppelin 安装0.10.1
Zeppelin 安装0.10.1
# Zeppelin 安装
Zeppelin 是 Web Notebook 类工具,适合做交互式数据分析、SQL 探索、Spark 任务调试和简单的数据协作。前面已经安装了 HDFS、YARN、Spark 和 Livy,这时再装 Zeppelin,解释器环境会更完整,后面调 Spark、Livy、JDBC 都方便。
这套栈里的 Zeppelin 只有一个服务端角色:ZEPPELIN_SERVER。它不需要额外的元数据库,也没有 Slave / Client 组件。
本次角色分配如下:
| 主机 | Zeppelin 角色 |
|---|---|
hadoop1.test.com | ZEPPELIN_SERVER |
hadoop2.test.com | 无 Zeppelin 组件 |
hadoop3.test.com | 无 Zeppelin 组件 |
# 1. 选择 Zeppelin 服务
进入 服务与组件,点击 新增服务,在增强组件列表里勾选 Zeppelin。
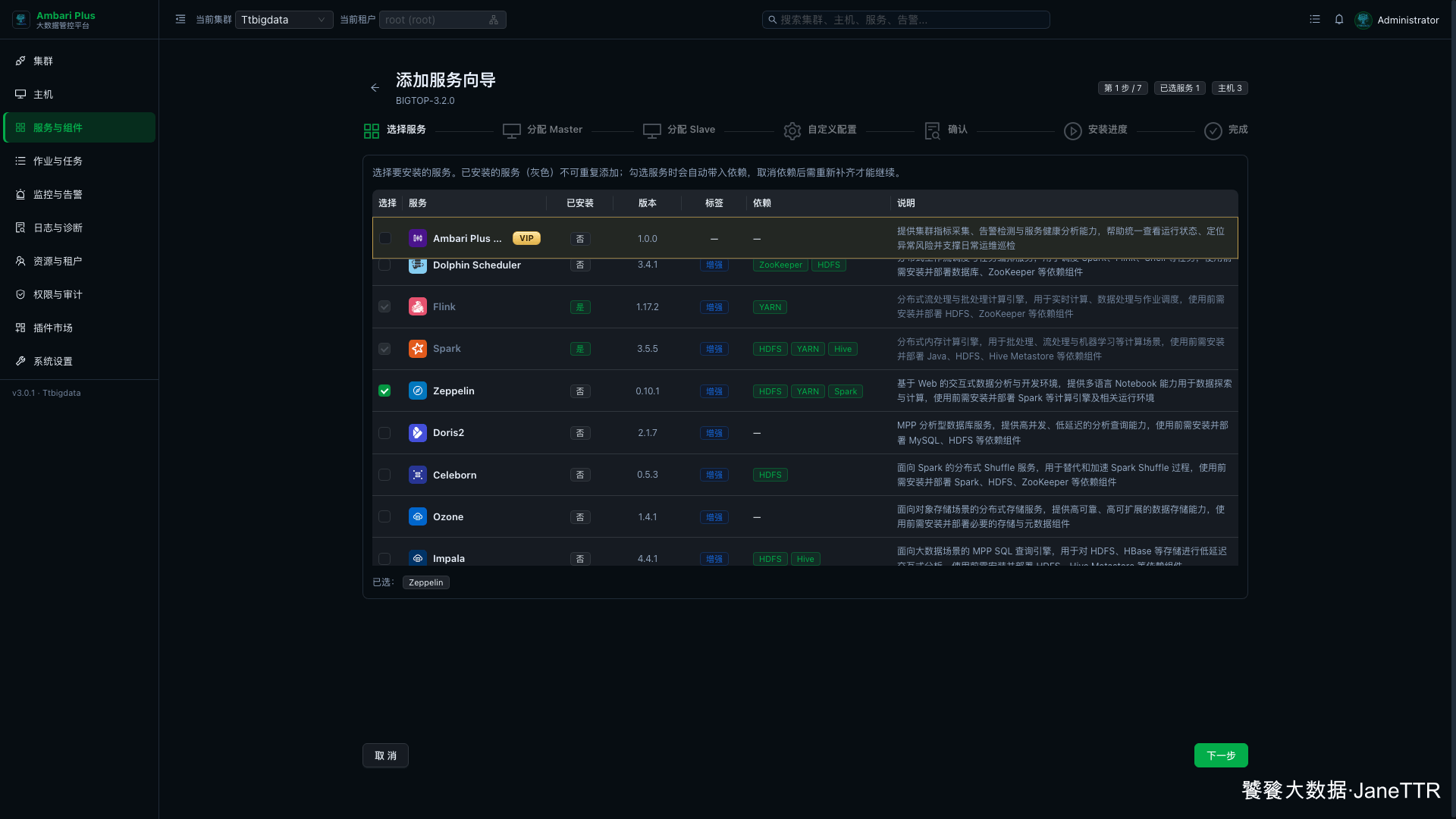
页面会显示 Zeppelin 依赖 HDFS、YARN、Spark。我这里已经把这些服务安装并启动,所以可以直接继续。
如果你的环境还没有 Spark,建议先回到 Spark 安装篇把 Spark History Server、Spark ThriftServer 和 Spark Client 装好,再回来安装 Zeppelin。
# 2. 分配 Zeppelin Server
Master 分配页里,Zeppelin 只有一个角色:ZEPPELIN_SERVER。
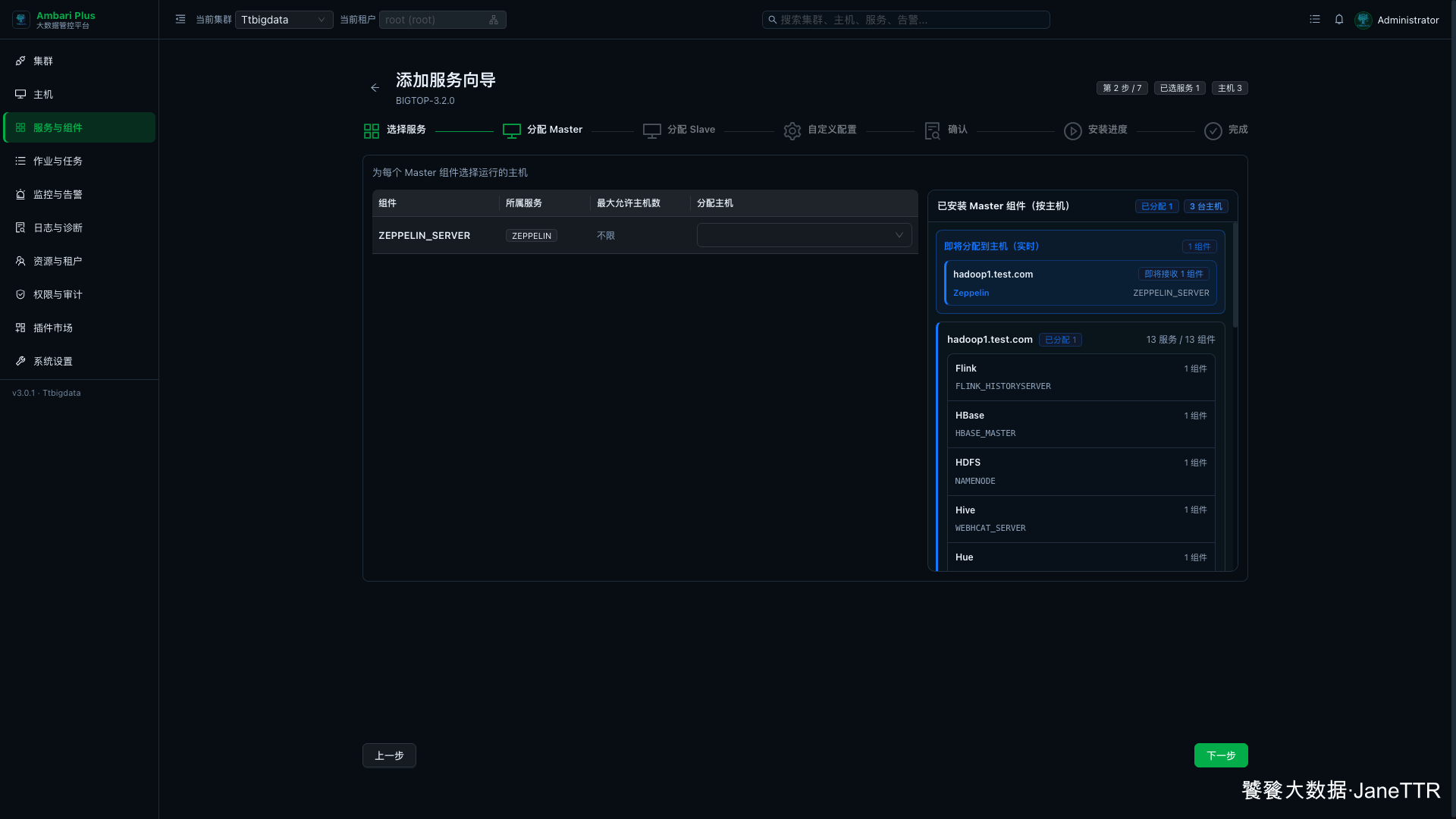
本次把它放在 hadoop1.test.com:
| 组件 | 主机 | 说明 |
|---|---|---|
ZEPPELIN_SERVER | hadoop1.test.com | 提供 Notebook Web 页面和解释器管理能力。 |
Zeppelin 是 Web 入口型服务,小集群里放在主节点最直观。生产环境如果多人同时使用 Notebook,可以再规划独立节点、反向代理和资源隔离。
# 3. 确认角色分配范围
Zeppelin 在这套栈里没有 Slave 组件,也没有 Client 组件。Slave / Client 页无需额外选择,直接下一步即可。
确认时重点看最终安装清单:只新增 ZEPPELIN,并且 ZEPPELIN_SERVER 指向 hadoop1.test.com。
# 4. 检查 Zeppelin Web 配置
进入自定义配置页后,先确认顶部状态:待填写 0。再进入 zeppelin-site,重点看 Web 端口、SSL、解释器顺序和 Notebook 存储方式。
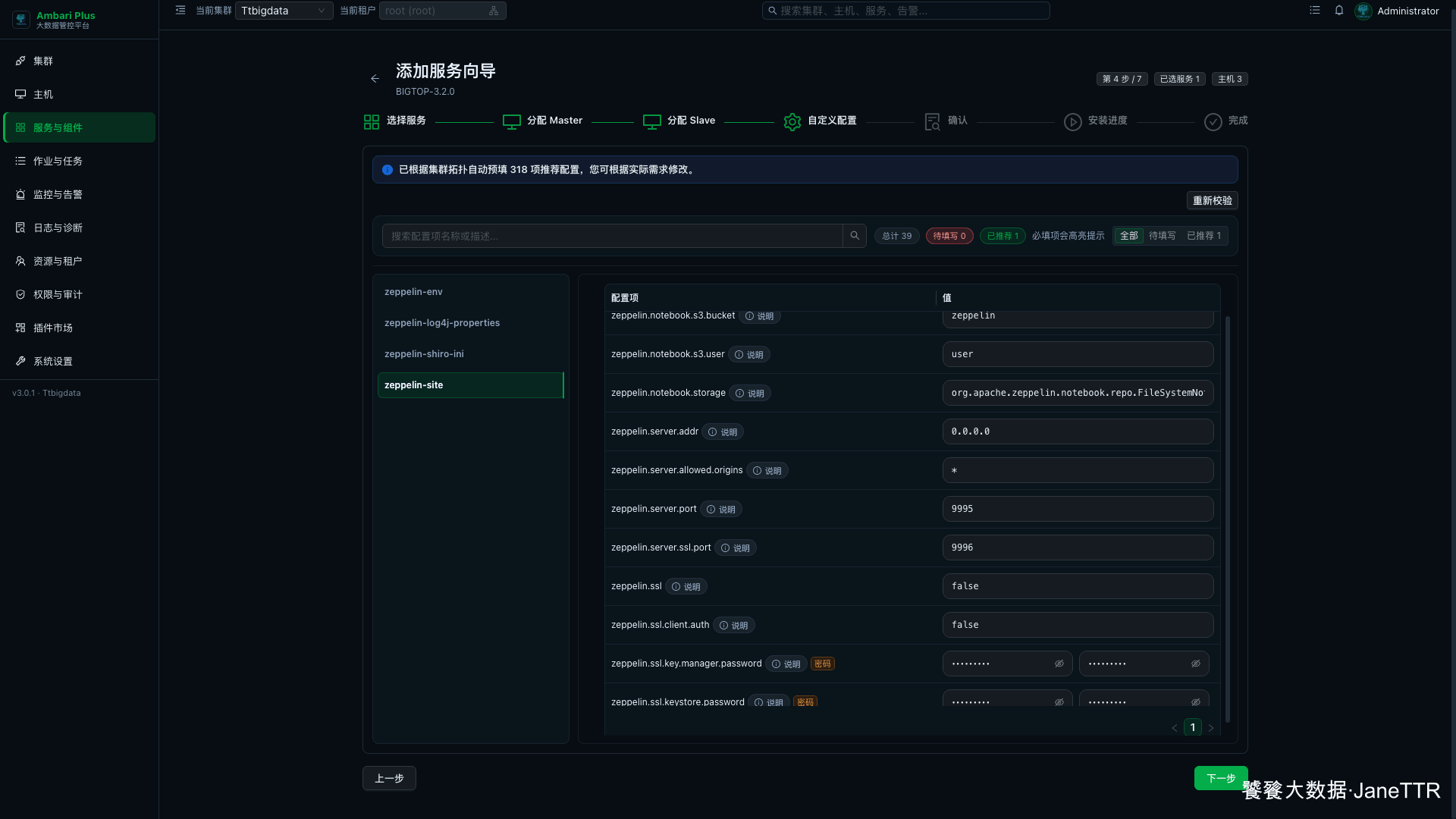
本次默认值如下:
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
zeppelin.server.addr | 0.0.0.0 | 监听所有网卡。 |
zeppelin.server.port | 9995 | Zeppelin HTTP 端口。 |
zeppelin.server.ssl.port | 9996 | Zeppelin HTTPS 端口。 |
zeppelin.ssl | false | 本篇先使用 HTTP;生产环境建议放到网关或反向代理后面。 |
zeppelin.interpreter.group.order | spark,angular,jdbc,livy,md,sh | 解释器显示顺序,能看到 spark 和 livy。 |
再看 zeppelin-env:
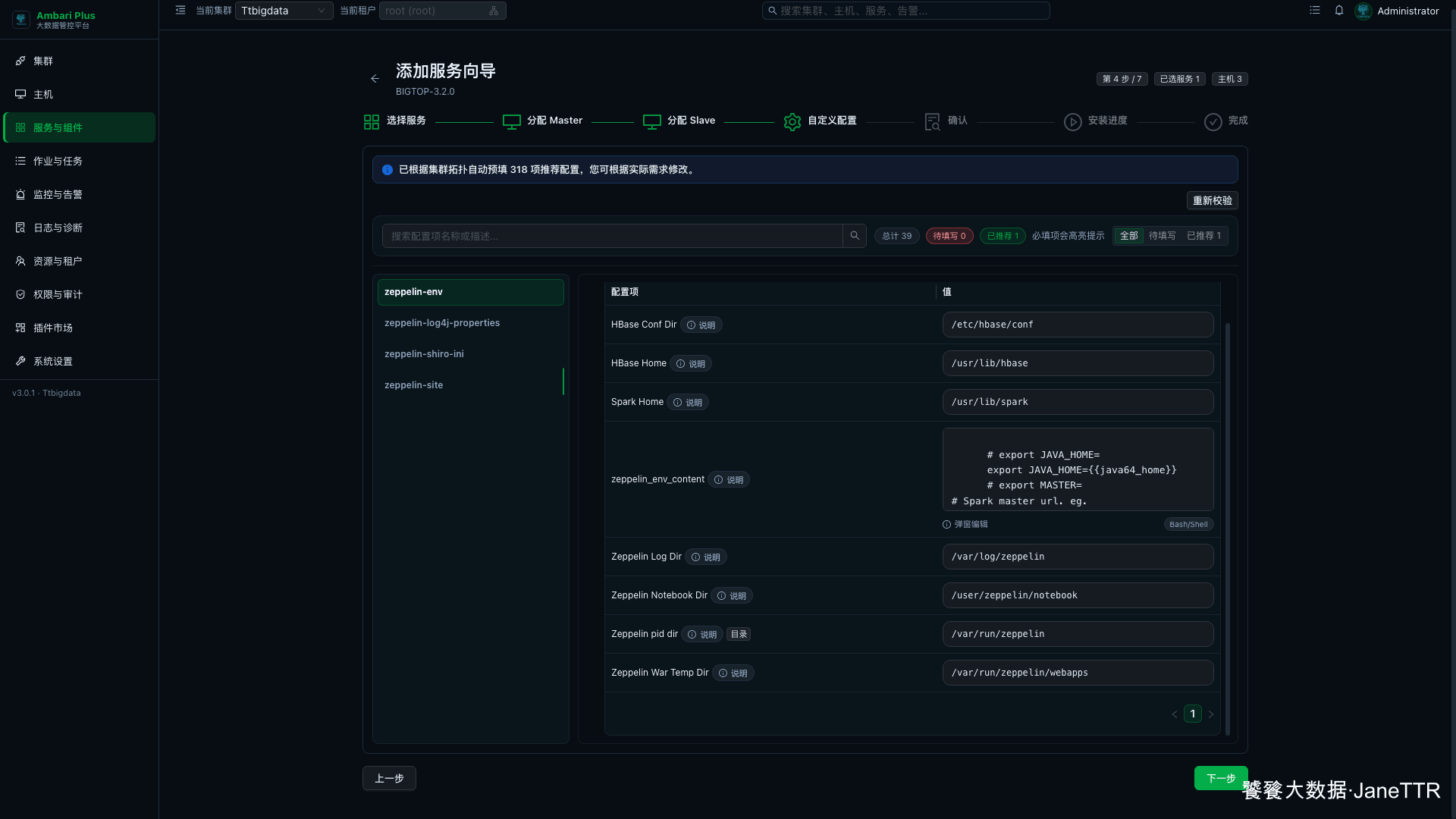
这里我会重点确认:
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
Spark Home | /usr/lib/spark | Zeppelin 调用 Spark 解释器时使用。 |
HBase Home | /usr/lib/hbase | 后续使用 HBase 相关解释器时会用到。 |
Zeppelin Log Dir | /var/log/zeppelin | 服务日志目录。 |
Zeppelin Notebook Dir | /user/zeppelin/notebook | Notebook 存储目录。 |
Zeppelin pid dir | /var/run/zeppelin | PID 目录。 |
第一次安装不建议急着改解释器模板。先让服务启动和页面访问跑通,后面再根据团队习惯配置 Spark、Livy、JDBC、Hive 等解释器。
# 5. 确认安装清单
确认页会列出本次新增的 Zeppelin 服务。
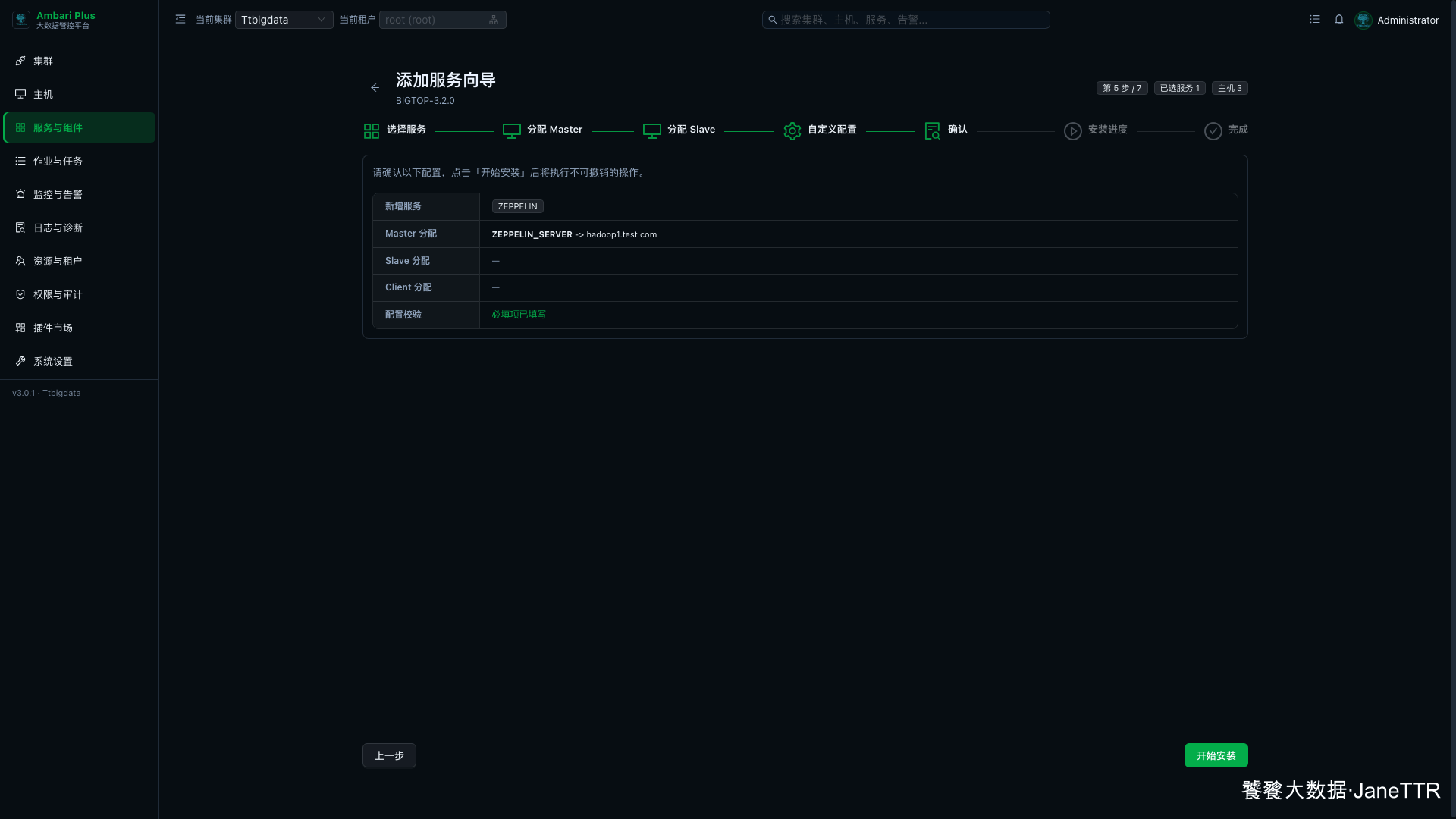
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | ZEPPELIN |
| Master 分配 | ZEPPELIN_SERVER -> hadoop1.test.com |
| Slave 分配 | 无 |
| Client 分配 | 无 |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 6. 提交 Kerberos 授权并等待启动
开启 Kerberos 的集群中,新增 Zeppelin 会要求提交 KDC 管理员凭据。提交后,安装向导会为 Zeppelin 生成 principal / keytab,并继续安装和启动 ZEPPELIN_SERVER。
这个阶段主要看:
| 阶段 | 期望结果 |
|---|---|
| 安装软件包 | ZEPPELIN_SERVER 安装完成。 |
| Kerberos | Zeppelin keytab 生成并分发完成。 |
| 启动服务 | Zeppelin Server 启动完成。 |
如果启动失败,优先看 /var/log/zeppelin 下的服务日志,以及 Spark、HDFS、YARN 客户端配置是否已经在 Zeppelin 所在主机上准备好。
# 7. 回到服务列表确认状态
回到 服务与组件 页面,Zeppelin 会出现在 接入工作台 分类下。
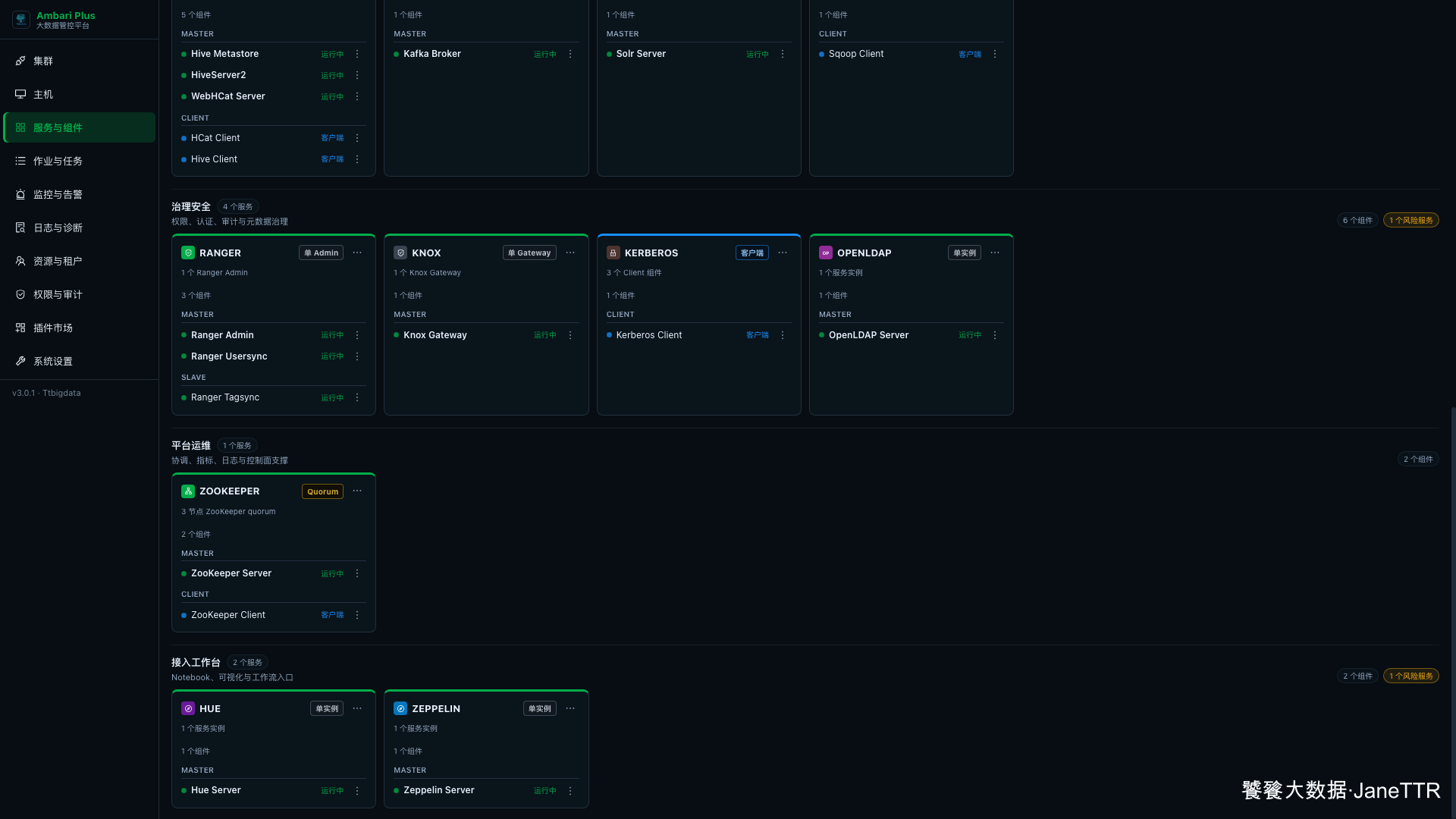
页面里可以看到:
| 组件 | 状态 |
|---|---|
Zeppelin Server | 运行中 |
服务端也可以确认 9995 端口已经监听:
ss -lntp | grep 9995
正常会看到 9995 处于监听状态,进程名为 java。
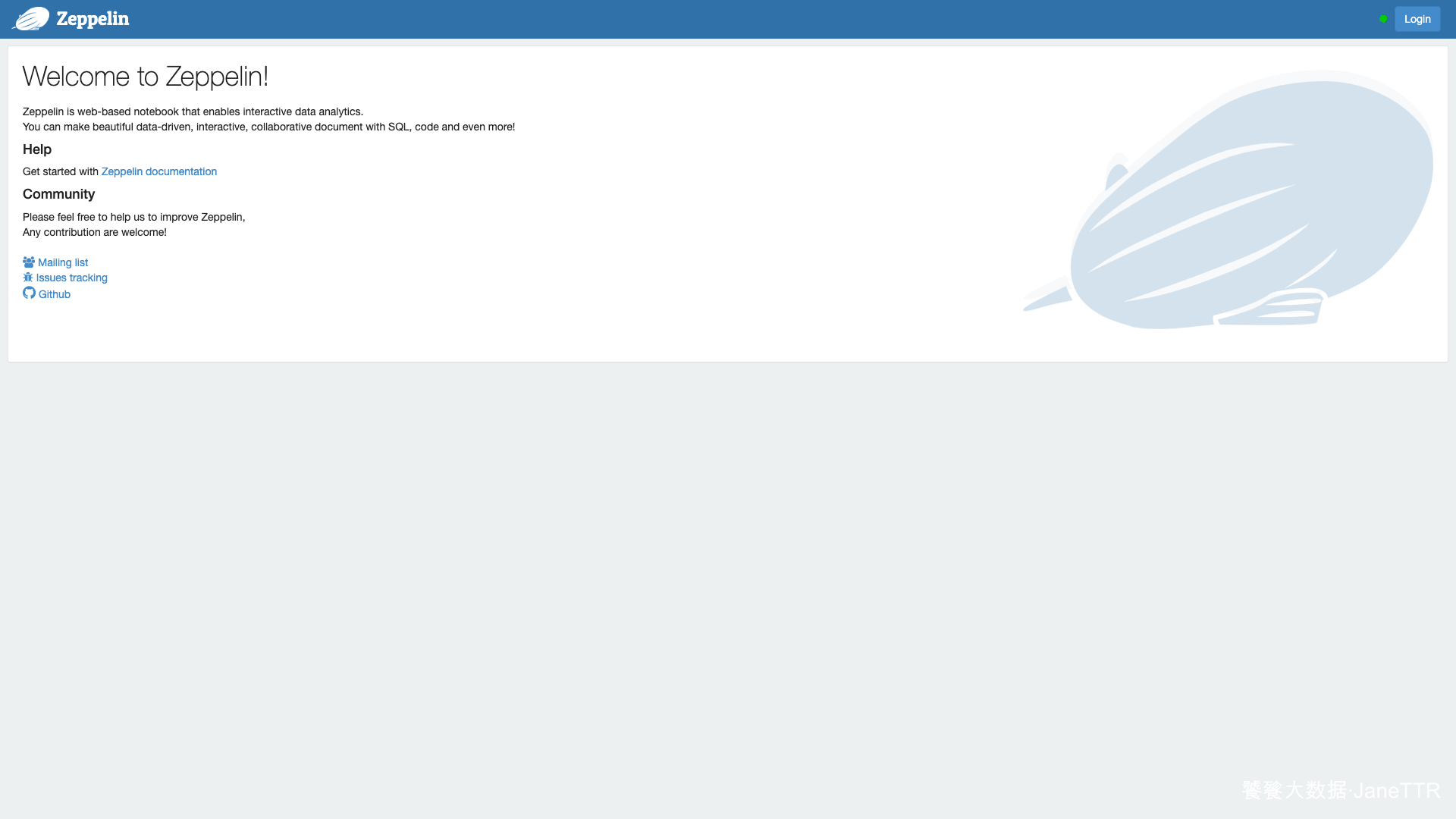
# 8. 打开 Zeppelin Web 页面
浏览器访问:
http://hadoop1.test.com:9995/
页面能打开并看到 Zeppelin 的欢迎页和登录入口,就说明 Web 服务已经可访问。
到这里,Zeppelin 的基础安装完成。下一篇可以继续安装 DolphinScheduler,把工作流调度能力接到这套已经跑通的 HDFS、YARN、Spark、Hive 环境上。