 Spark 安装3.5.5
Spark 安装3.5.5
# Spark 安装
Spark 是批处理、SQL、流处理和机器学习场景里很常用的计算引擎。本篇在已经安装 HDFS、YARN、Hive、Flink、Kafka 的基础上继续安装 Spark。
这套环境里 Spark 使用 YARN 作为资源调度,使用 Hive Metastore 做表元数据入口。安装时会部署 Spark History Server、Spark ThriftServer 和 Spark Client。
本次角色分配如下:
| 主机 | Spark 角色 |
|---|---|
hadoop1.test.com | SPARK_JOBHISTORYSERVER、SPARK_THRIFTSERVER、SPARK_CLIENT |
hadoop2.test.com | SPARK_CLIENT |
hadoop3.test.com | SPARK_CLIENT |
# 1. 选择 Spark 服务
进入 服务与组件,点击 新增服务,勾选 Spark。
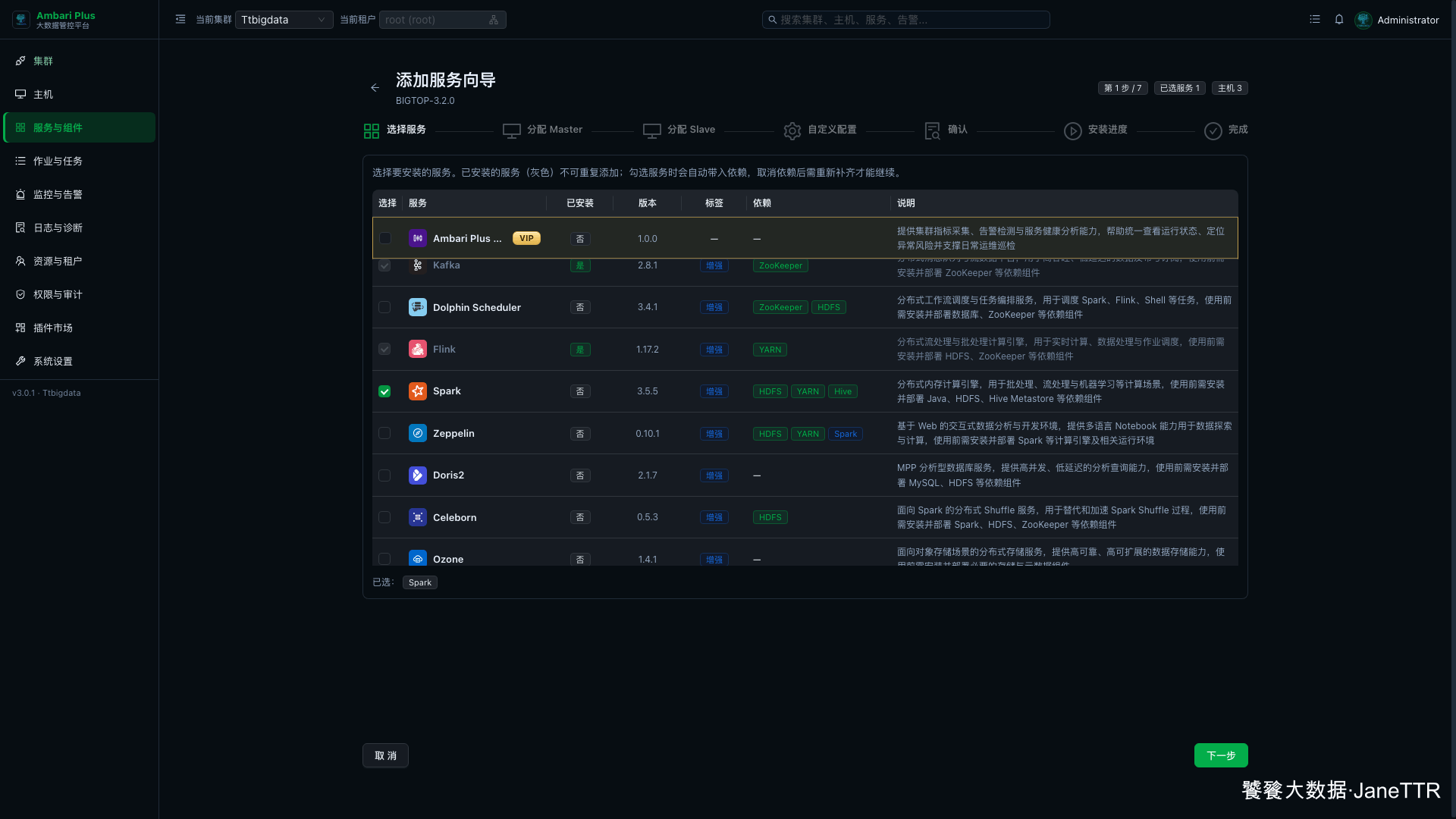
页面会显示 Spark 依赖 HDFS、YARN、Hive。前面的文章已经把这些组件安装完成,所以这里可以直接下一步。
# 2. 分配 Spark History Server
Master 分配页里,Spark 的常驻 Master 角色是 SPARK_JOBHISTORYSERVER。
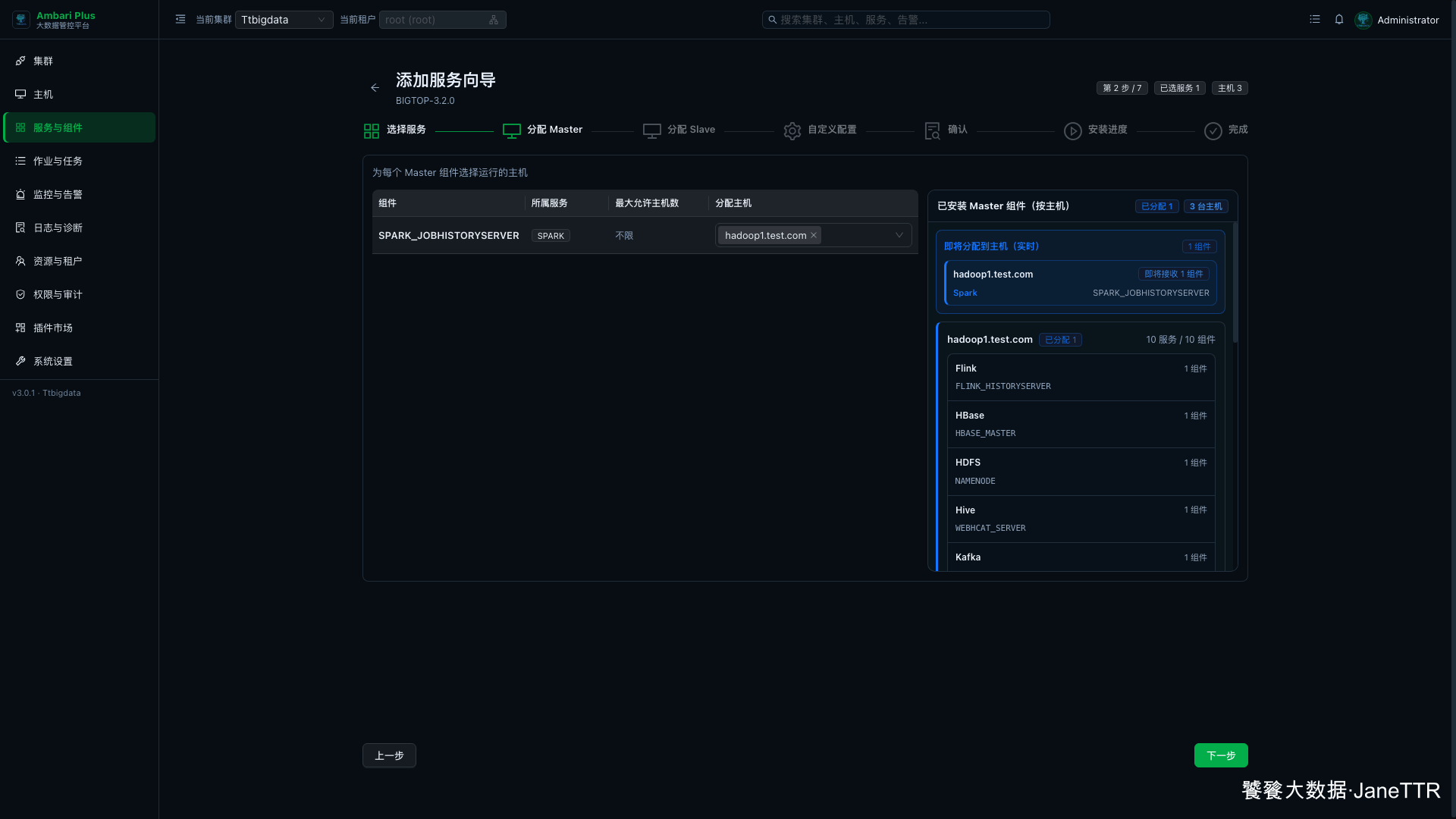
本次把它放在 hadoop1.test.com:
| 组件 | 主机 | 说明 |
|---|---|---|
SPARK_JOBHISTORYSERVER | hadoop1.test.com | 用来查看 Spark 历史作业。 |
Spark on YARN 的 Driver 和 Executor 会随作业提交到 YARN,不需要在 Ambari 里固定分配。
# 3. 分配 Spark ThriftServer 和 Client
Slave 与 Client 分配页里,Spark 有一个 SPARK_THRIFTSERVER,还有 SPARK_CLIENT。
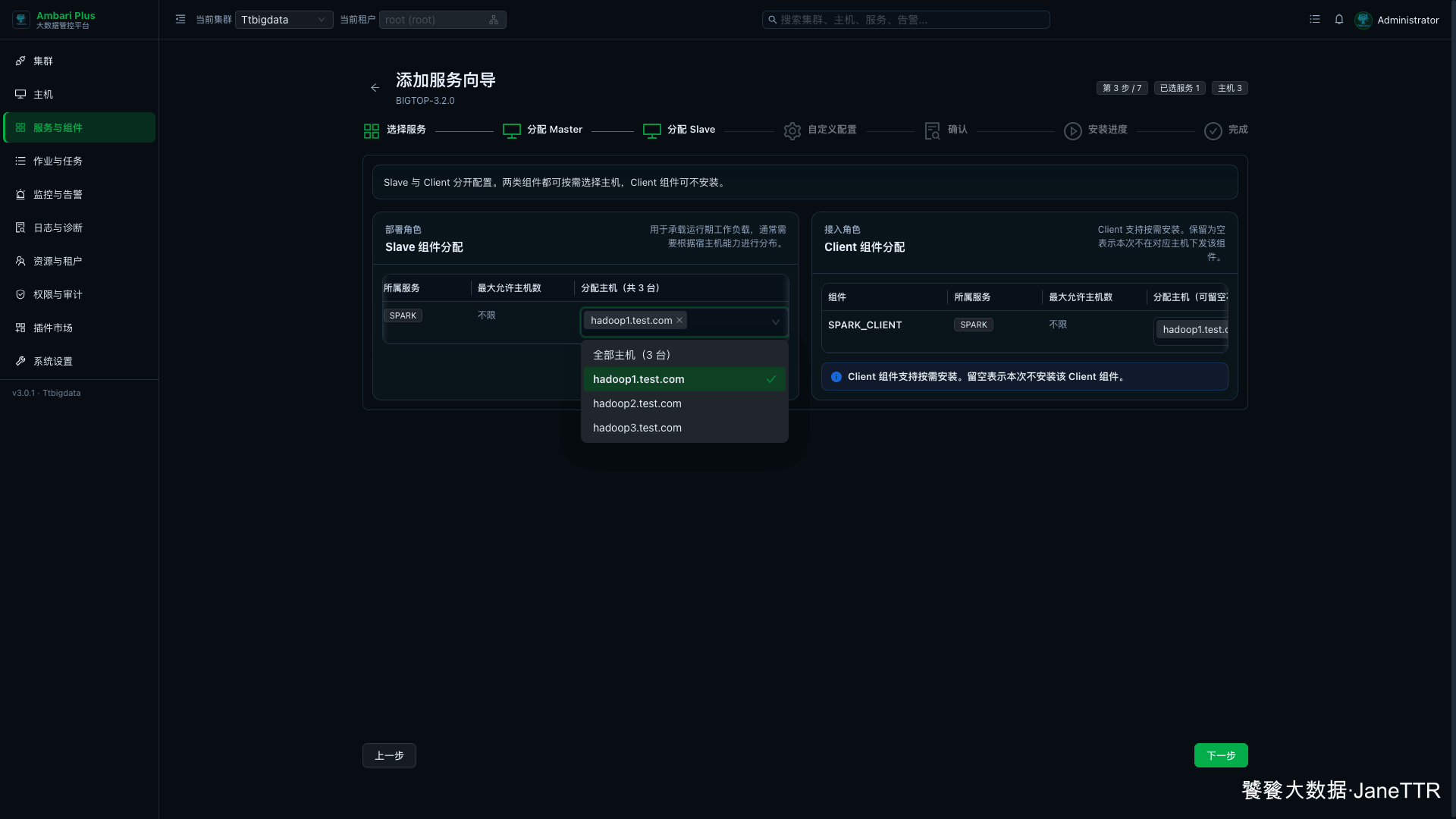
本次这样分配:
| 组件 | 分配主机 | 说明 |
|---|---|---|
SPARK_THRIFTSERVER | hadoop1.test.com | 提供 Spark SQL Thrift 入口。 |
SPARK_CLIENT | hadoop1.test.com、hadoop2.test.com、hadoop3.test.com | 下发 Spark 命令和配置。 |
如果后面要让 Hue 连接 Spark SQL,ThriftServer 建议先装上。生产环境可根据查询压力规划独立节点。
# 4. 检查 Spark 推荐配置
进入自定义配置页后,先确认 待填写 0。
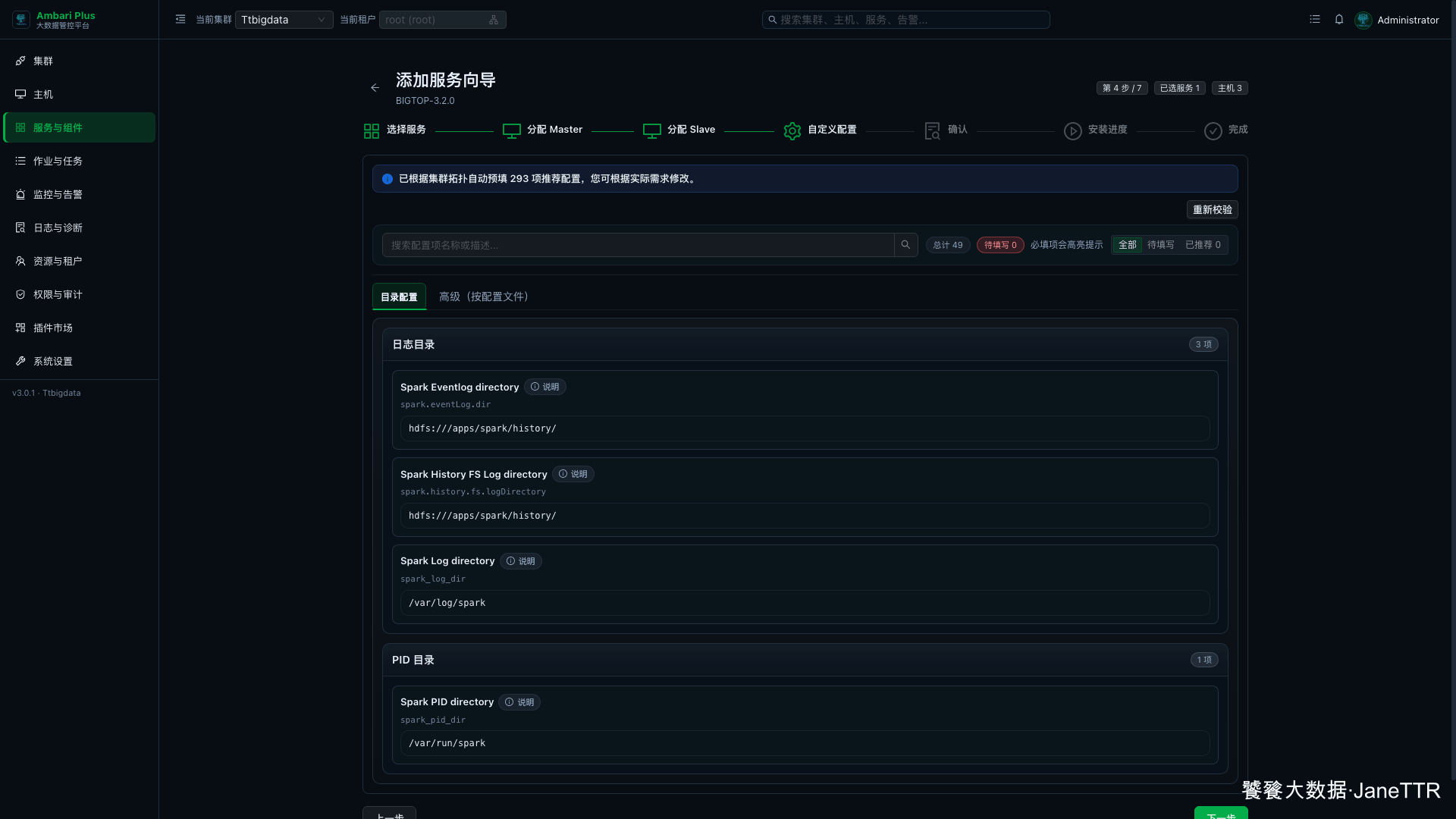
这一页重点看目录类配置:
| 配置项 | 说明 |
|---|---|
spark.eventLog.dir | Spark 事件日志目录。 |
spark.history.fs.logDirectory | History Server 读取历史日志的位置。 |
spark_log_dir | Spark 本地日志目录。 |
spark_pid_dir | Spark PID 目录。 |
第一次安装先保留推荐配置,让服务启动和 Service Check 先跑通。后面再按作业规模调整 Driver、Executor、Shuffle、History 日志保留等参数。
# 5. 确认安装清单
确认页会列出 Spark 的三类角色。
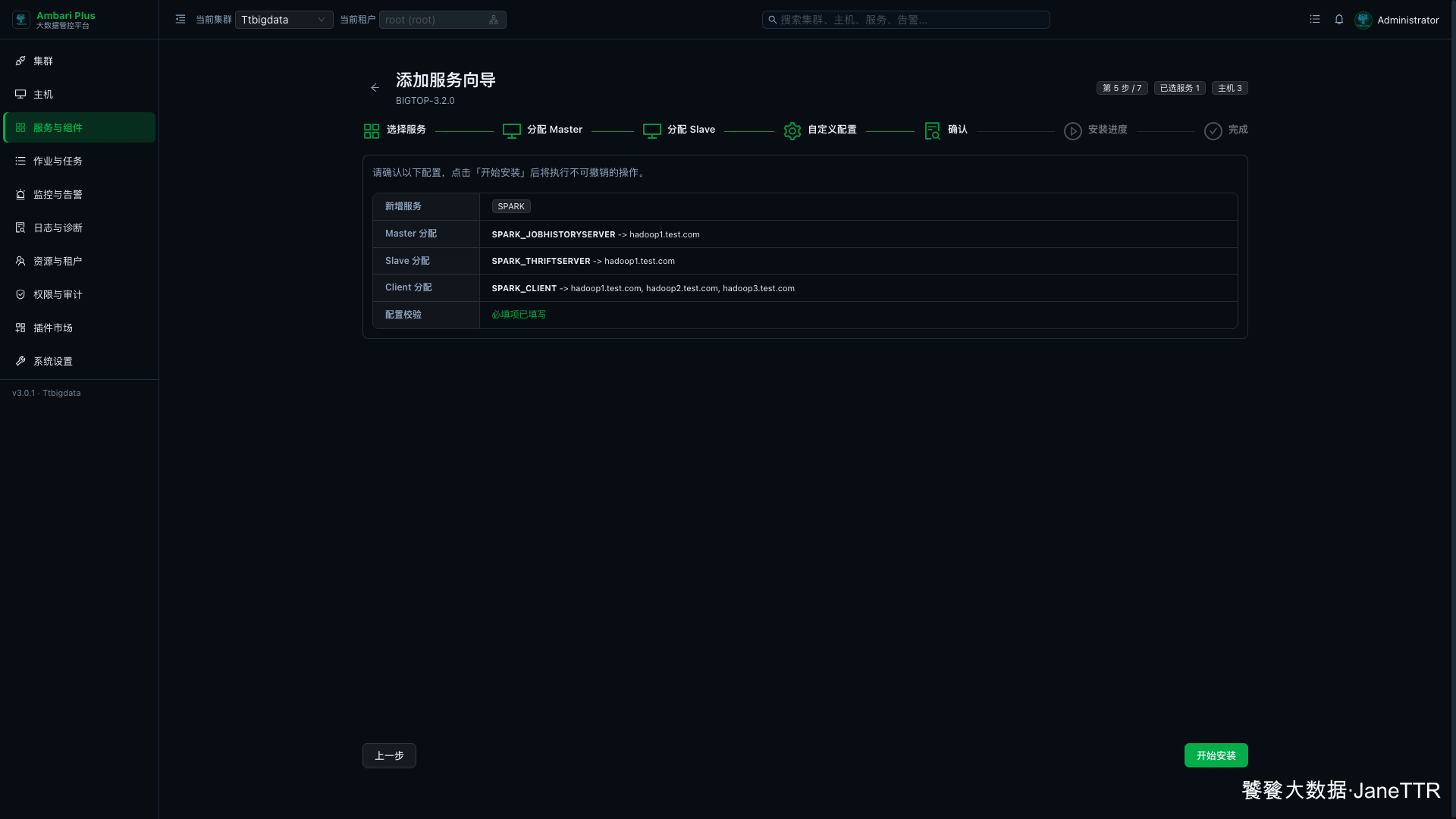
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | SPARK |
| Master 分配 | SPARK_JOBHISTORYSERVER -> hadoop1.test.com |
| Slave 分配 | SPARK_THRIFTSERVER -> hadoop1.test.com |
| Client 分配 | 三台主机都有 SPARK_CLIENT |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 6. 提交 Kerberos 管理员凭据
开启 Kerberos 的集群中,新增 Spark 同样需要提交 KDC 管理员凭据。
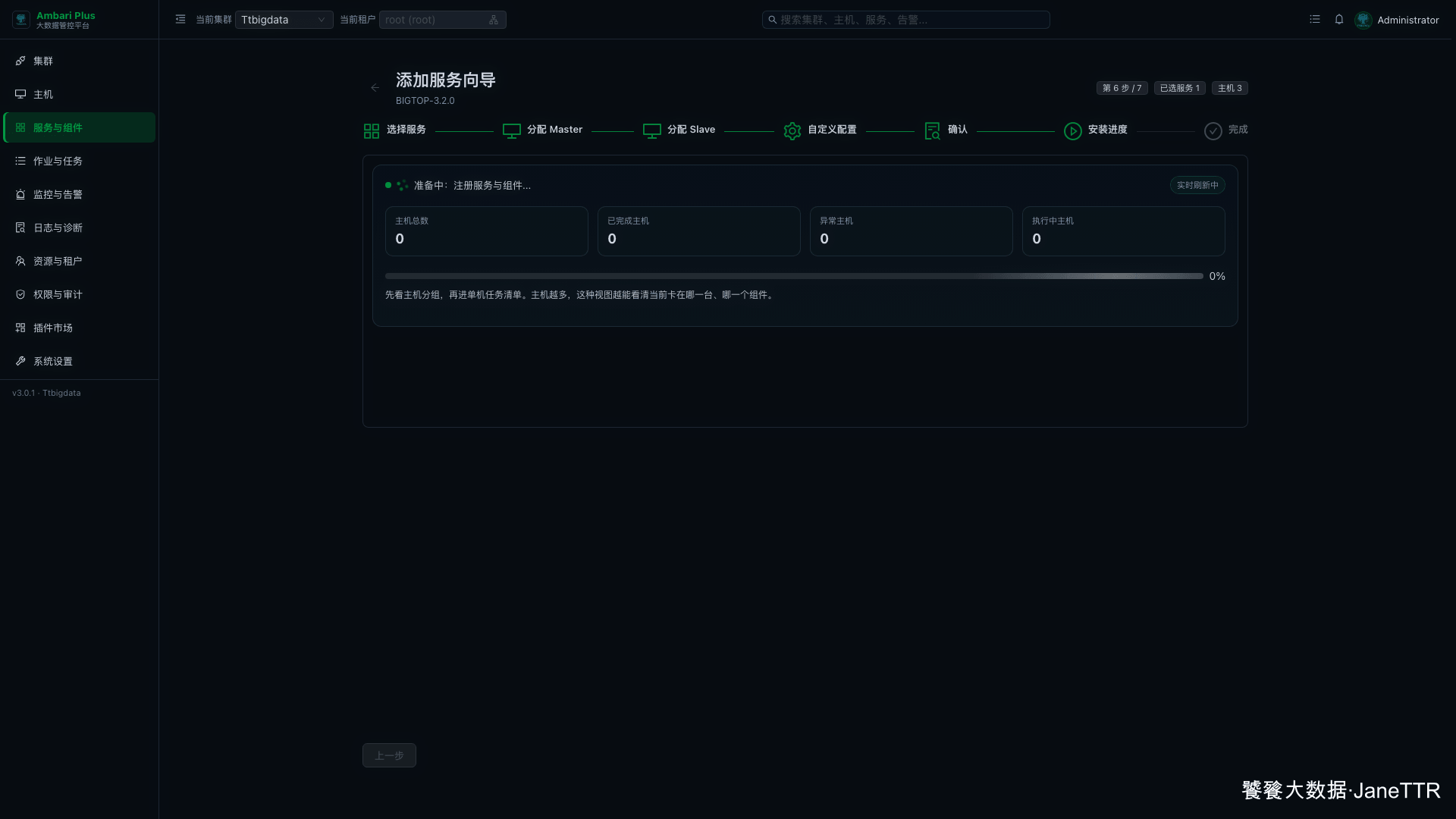
提交后,系统会生成 Spark 使用的 principal / keytab,并继续安装组件。
# 7. 等待 Spark 安装完成
安装进度页会按主机展示任务。
这个阶段主要看:
| 阶段 | 期望结果 |
|---|---|
| Client 安装 | 三台主机的 SPARK_CLIENT 安装完成。 |
| 服务端安装 | SPARK_JOBHISTORYSERVER、SPARK_THRIFTSERVER 安装完成。 |
| Kerberos | Spark keytab 分发完成。 |
| 启动服务 | History Server 和 ThriftServer 启动完成。 |
| Service Check | Spark 示例检查通过。 |
安装完成后,向导会显示 SPARK 已成功安装。
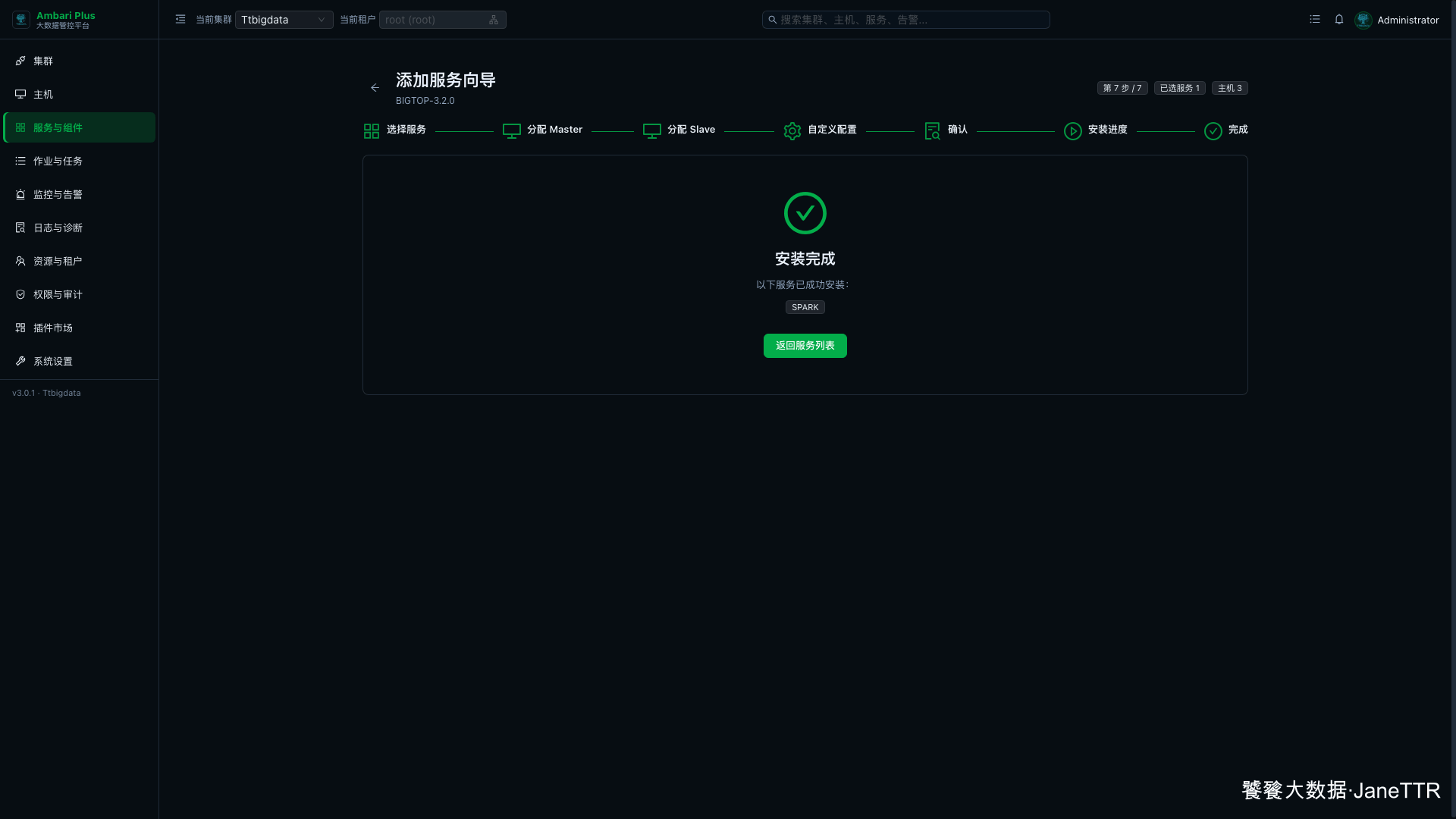
# 8. 回到服务列表确认状态
回到 服务与组件 页面,Spark 会出现在 资源计算 分类下。
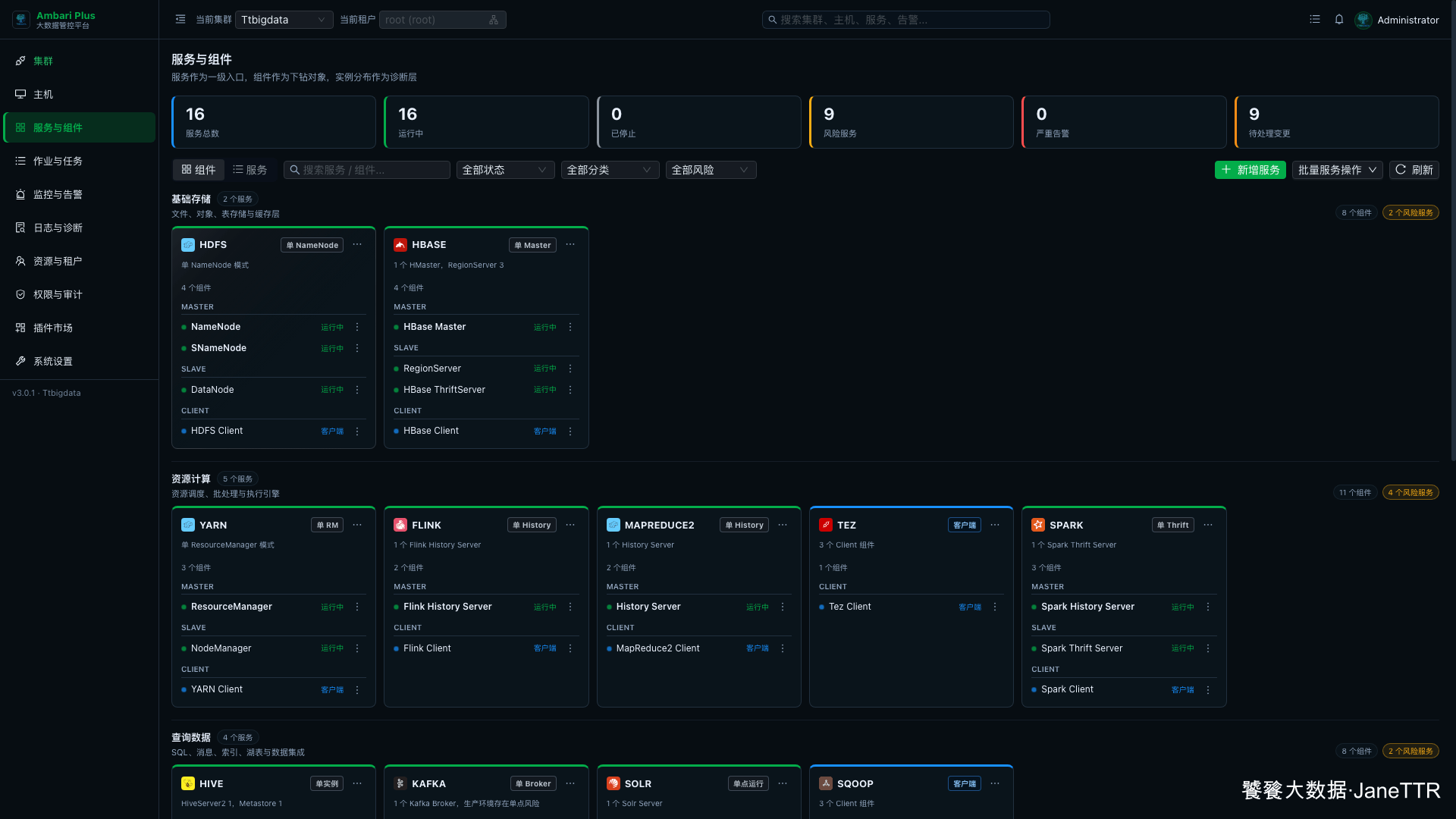
页面里可以看到:
| 组件 | 状态 |
|---|---|
Spark History Server | 运行中 |
Spark Thrift Server | 运行中 |
Spark Client | 客户端 |
命令行可以做一个版本确认:
spark-submit --version
正常会看到类似结果:
version 3.5.5
Using Scala version 2.12.18
2
到这里,Spark 的基础安装完成。下一步继续安装 Hue,把前面的 HDFS、Hive、Spark 等入口统一放到 Web 页面里使用。