 Hudi 安装1.1.0
Hudi 安装1.1.0
# Hudi 安装
Hudi 是数据湖场景里很常见的增量数据管理组件,通常会和 HDFS、Hive Metastore、Spark、Flink、Trino 这些组件配合使用。前面已经把 HDFS、Hive、Spark、Flink、Trino、Paimon 安装完成,这里继续补 Hudi Client,让三台节点都具备 Hudi 相关命令、bundle 和 Kerberos 凭据。
本篇继续使用三台 FQDN 主机:
| 主机 | Hudi 角色 |
|---|---|
hadoop1.test.com | HUDI Client |
hadoop2.test.com | HUDI Client |
hadoop3.test.com | HUDI Client |
Hudi 在这套安装包里是客户端型服务,没有独立 Master / Worker 进程,也不需要单独创建 MySQL / MariaDB 数据库。安装完成后页面显示“已安装”,实例分布里三台主机都是 0/1,这是正常现象:Hudi Client 不是常驻服务,重点是客户端文件、配置和 keytab 是否下发到位。
提示
如果后面要用 Spark 或 Flink 写 Hudi 表,我建议三台都安装 Hudi Client。这样不管作业在哪台机器提交,都能找到相同的 Hudi bundle 和客户端环境。
# 1. 选择 Hudi 服务
进入 服务与组件,点击 新增服务,在服务列表里找到并勾选 Hudi。
页面里可以看到 Hudi 版本是 1.1.0,标签为“增强”,状态为“否”。Hudi 依赖前面已经准备好的 HDFS、Hive Metastore、Spark 等基础组件,所以这里直接勾选进入下一步即可。
# 2. Master 分配页直接下一步
Hudi 没有 Master 组件,所以 Master 分配页会提示“所选服务无 Master 组件,直接下一步”。
这一步不需要选择主机。右侧展示的是当前集群已有 Master 组件,用来确认当前主机规划是否符合预期。
# 3. 分配 Hudi Client
Slave / Client 分配页也没有 Slave 组件,只有 HUDI Client。
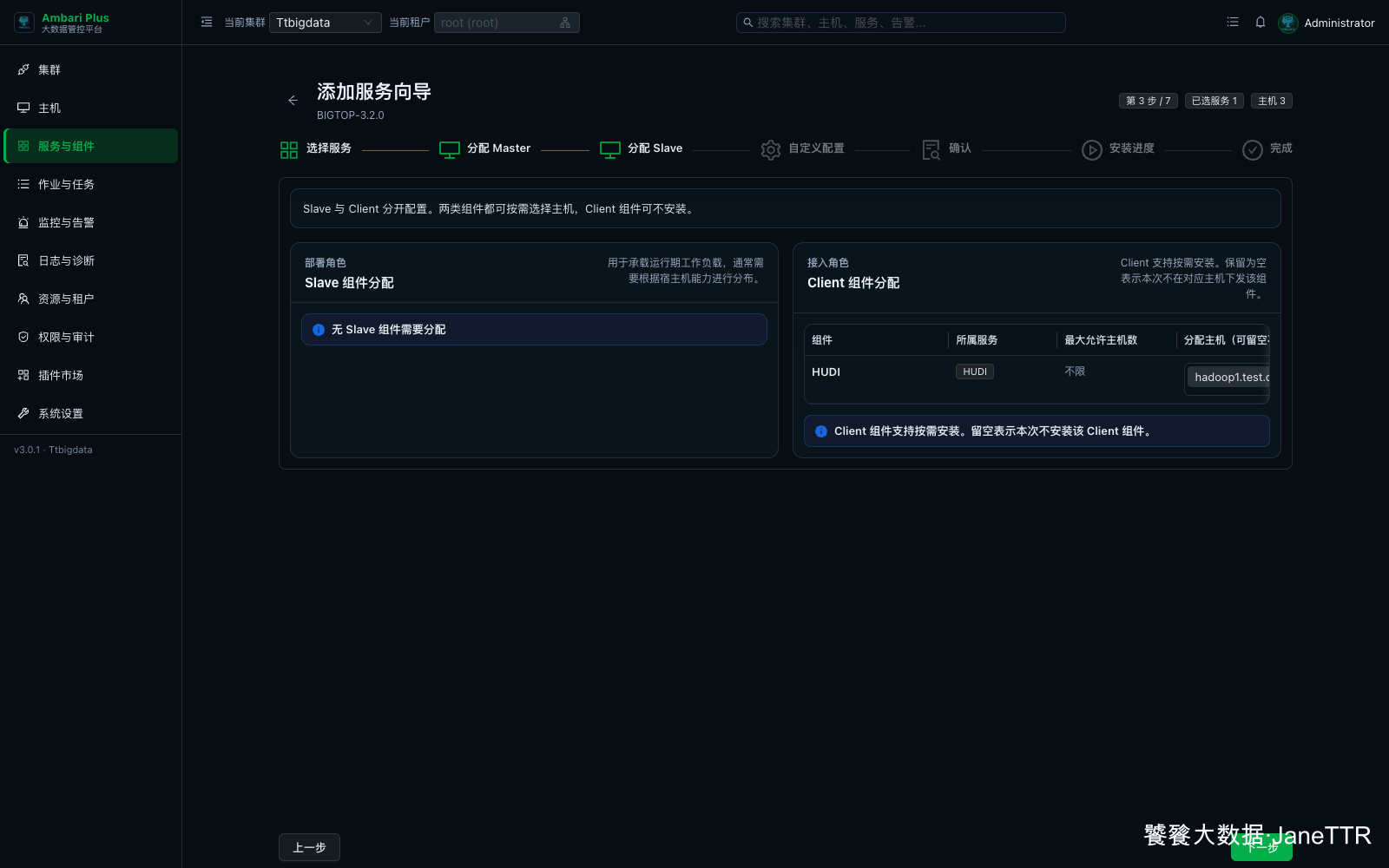
本次把 Hudi Client 分发到三台主机:
| 组件 | 分配主机 | 说明 |
|---|---|---|
HUDI | hadoop1.test.com、hadoop2.test.com、hadoop3.test.com | 下发 Hudi CLI、Spark / Flink / Hive / Trino 相关 bundle,以及 Kerberos 环境需要的客户端文件。 |
这里可以理解成给集群里的每台机器补齐 Hudi 工具箱。后面从 Spark、Flink 或命令行调 Hudi 时,不会因为作业切到某台节点就缺少本地依赖。
# 4. 自定义配置页无需额外填写
Hudi 当前没有需要手工维护的配置项,进入自定义配置页后会看到“该服务暂无可配置项”。
这一步保持默认即可。Hudi 真正需要关心的表路径、Hive Sync、Spark / Flink 写入参数,通常是在作业侧配置,而不是在 Ambari 里创建一个常驻服务配置。
# 5. 确认安装清单
确认页会展示本次新增服务、Master 分配、Slave 分配、Client 分配和配置校验结果。
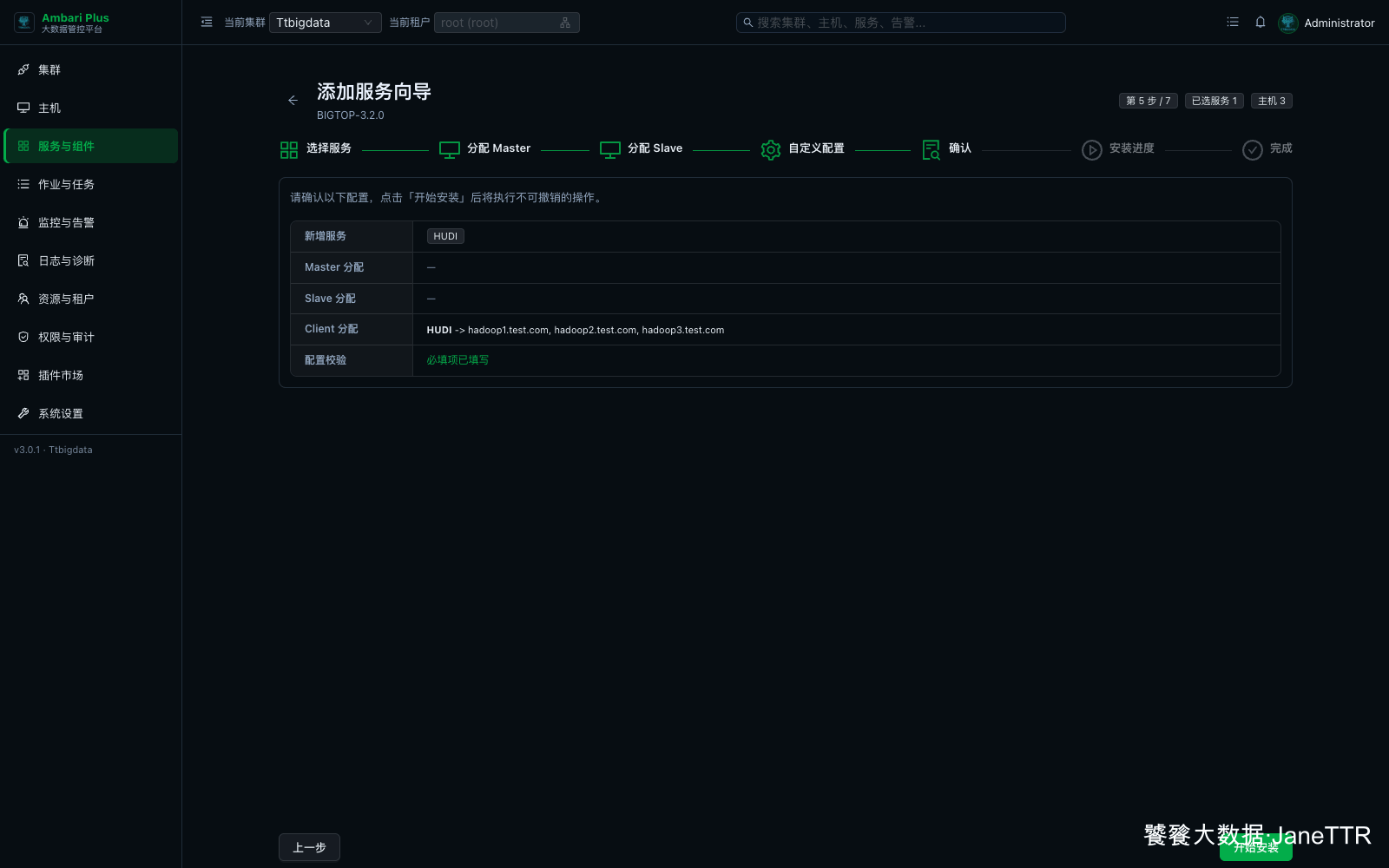
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | HUDI |
| Master 分配 | 无 |
| Slave 分配 | 无 |
| Client 分配 | HUDI -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 6. 提交 Kerberos 凭据并等待安装
当前集群已经开启 Kerberos,新增 Hudi 时会要求提交 KDC 管理员凭据。这里填写 KDC 管理员 Principal 和密码,用于生成并下发 Hudi 相关 principal / keytab。
凭据提交后,安装页会进入主机任务视图。Hudi 是客户端组件,主要任务是安装软件包、刷新 Kerberos Client、生成 keytab 和同步客户端文件。
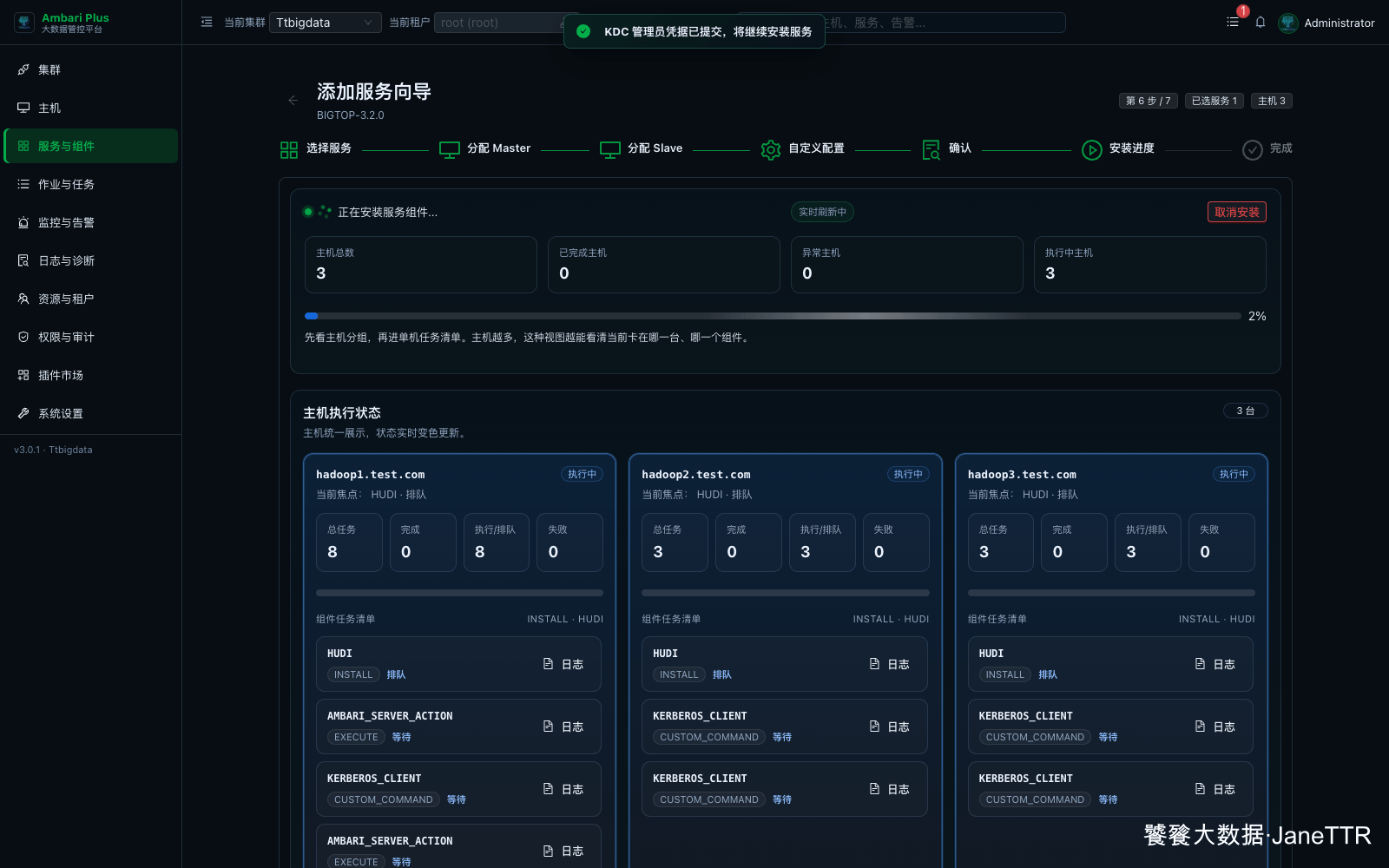
如果安装阶段失败,优先打开失败主机的任务日志。Hudi 常见问题通常集中在软件包仓库、Kerberos 凭据、keytab 生成和客户端文件权限。
# 7. 回到服务列表确认 Hudi
安装完成后回到 服务与组件 页面,搜索 hudi,可以看到新增的 HUDI 服务卡片。
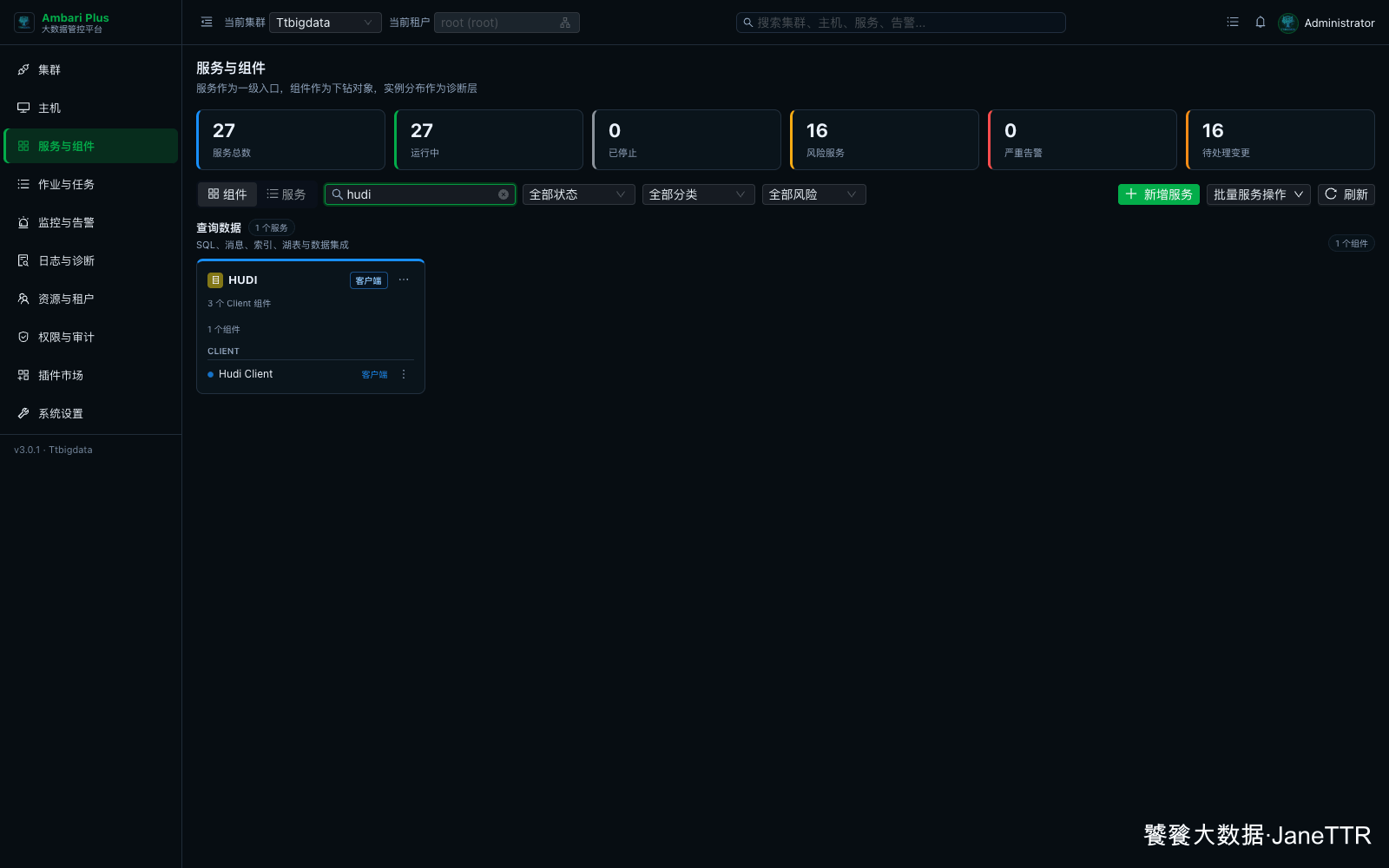
页面里会显示 3 个 Client 组件,说明三台主机都已经分发 Hudi Client。这里不会显示运行中的 Hudi Server,因为 Hudi 在本文环境里没有常驻服务进程。
# 8. 查看 Hudi 详情页
进入 HUDI 详情页,基础信息里可以看到服务状态为“已安装”,组件数为 1,部署主机为 3。
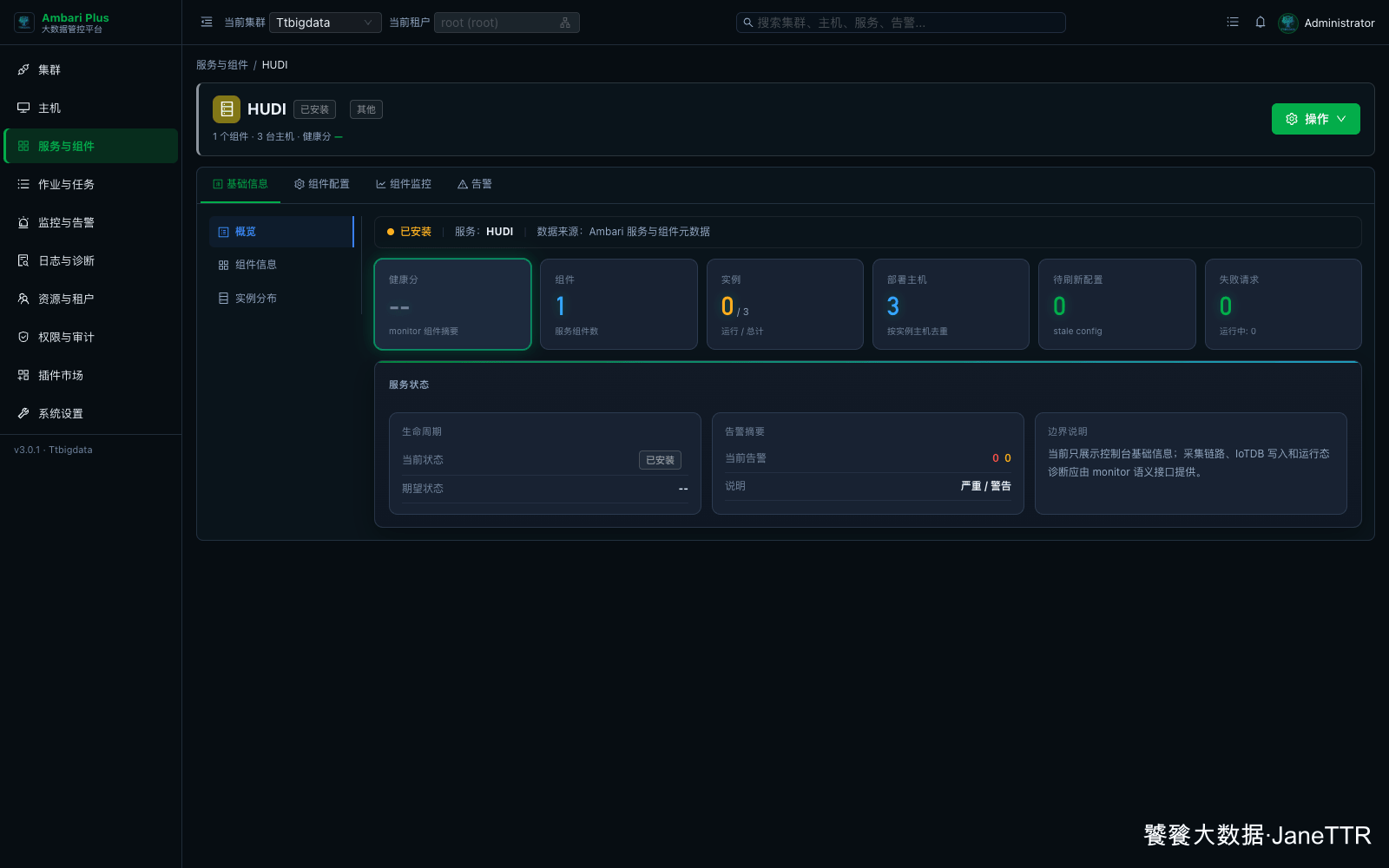
这里的实例运行数显示 0/3 是正常的。它表示没有常驻进程运行,不表示安装失败。判断 Hudi Client 是否就绪,主要看服务状态、实例分布和主机上的客户端文件。
# 9. 查看实例分布
在 HUDI 详情页打开 实例分布。
页面里可以看到:
| 主机 | 组件 | 状态说明 |
|---|---|---|
hadoop1.test.com | Hudi Client | 配置已同步 |
hadoop2.test.com | Hudi Client | 配置已同步 |
hadoop3.test.com | Hudi Client | 配置已同步 |
三台主机都显示 0/1,这和 Paimon、Sqoop 这类客户端型组件类似。只要配置已同步,且组件出现在三台主机上,就说明客户端分发完成。
# 10. 在主机上确认客户端文件
最后可以在任意安装了 Hudi Client 的主机上看一下文件是否存在:
ls -l /usr/bigtop/3.2.0/usr/lib/hudi/bin/hudi-cli
ls -l /usr/bigtop/3.2.0/usr/lib/hudi/bundles | grep hudi-spark
ls -l /etc/security/keytabs/hudi.service.keytab
2
3
能看到 hudi-cli、Hudi bundle 和 hudi.service.keytab,就说明客户端文件和 Kerberos 凭据已经落到本机。
到这里,Hudi Client 已经安装到三台主机。后面如果要真正验证写入链路,可以从 Spark 或 Flink 作业侧创建 Hudi 表,再接 Hive Sync、Trino 查询和 Ranger 权限策略。
下一篇继续安装 Atlas,把元数据治理、标签和血缘入口补上。