 Impala 安装4.4.1
Impala 安装4.4.1
# Impala 安装
Impala 是面向交互式分析查询的 MPP SQL 引擎,常见用法是直接读取 HDFS / Hive 表,为报表、数据探查、低延迟明细查询提供一个更快的入口。它不像 Hive 那样偏批处理,也不像 Doris 那样自带独立存储,Impala 更依赖前面已经搭好的 HDFS、Hive Metastore、Kerberos 和 Ranger。
本篇继续沿用三台 FQDN 主机:
| 主机 | Impala 角色 |
|---|---|
hadoop1.test.com | IMPALA_CATALOG、IMPALA_DAEMON |
hadoop2.test.com | IMPALA_STATE_STORE、IMPALA_DAEMON |
hadoop3.test.com | IMPALA_DAEMON |
这里把 Catalog 放在 hadoop1.test.com,StateStore 放在 hadoop2.test.com,Daemon 覆盖三台主机。教程环境这样分配比较直观:元数据、集群协调和查询执行角色分开看,后续排查也容易定位。
提示
如果集群已经开启 Kerberos 和 Ranger,新增 Impala 时会自动走对应的凭据生成、配置下发和 Ranger 侧服务接入。这里不要把 Impala 和其他新组件混在一次向导里安装,单独安装更容易看清每个角色的状态。
# 1. 选择 Impala 服务
进入 服务与组件,点击 新增服务,在增强组件列表里勾选 Impala。
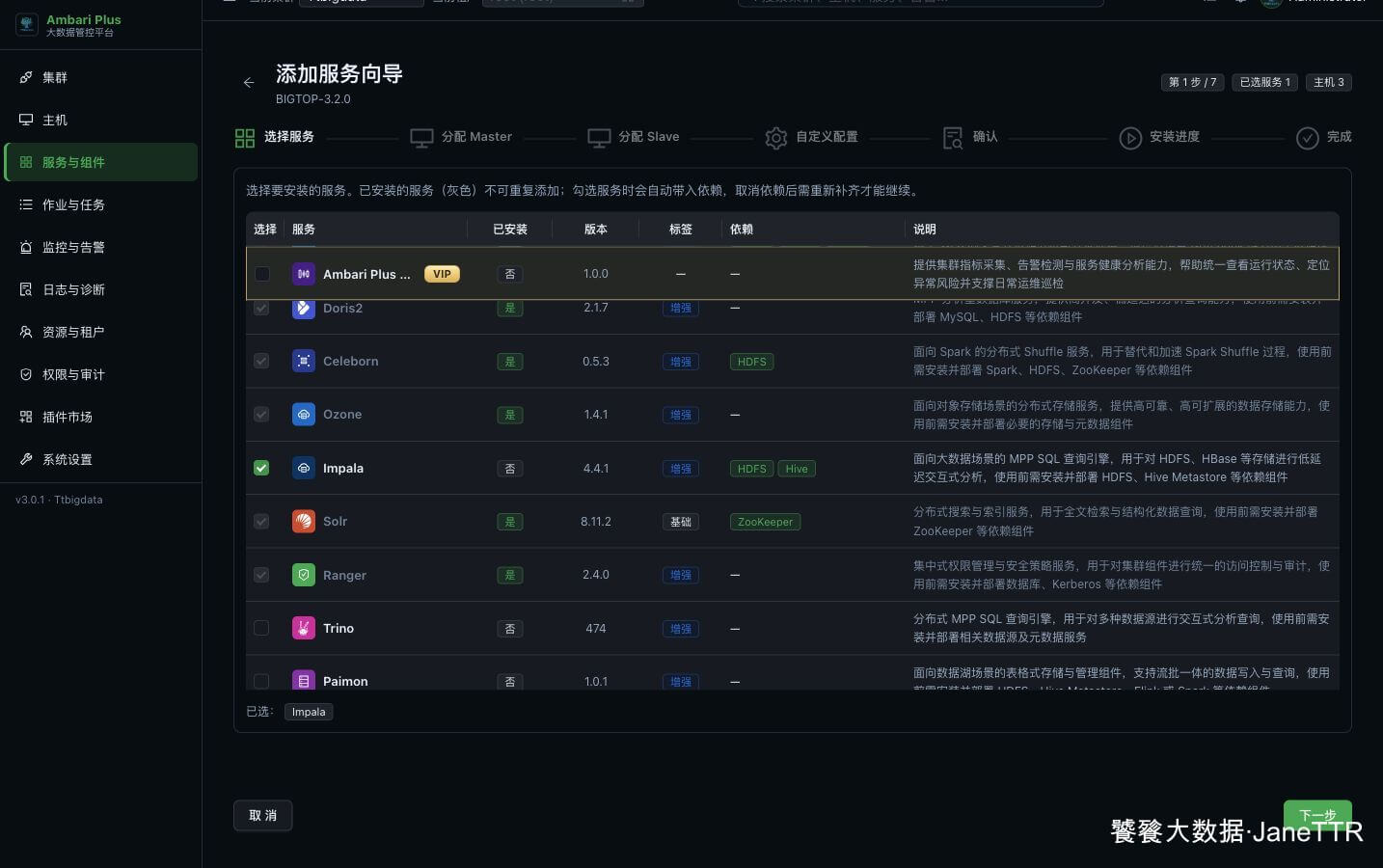
Impala 依赖 HDFS、Hive Metastore 和 ZooKeeper。前面的安装顺序里已经把 HDFS、YARN、Tez、Hive、HBase、Kafka、Flink、Spark、Hue、Livy、Zeppelin、DolphinScheduler、Doris、Celeborn、Ozone 这些基础和上层服务装好,所以这里直接进入下一步。
# 2. 分配 Catalog 和 StateStore
Master 分配页里有两个核心角色:IMPALA_CATALOG 和 IMPALA_STATE_STORE。
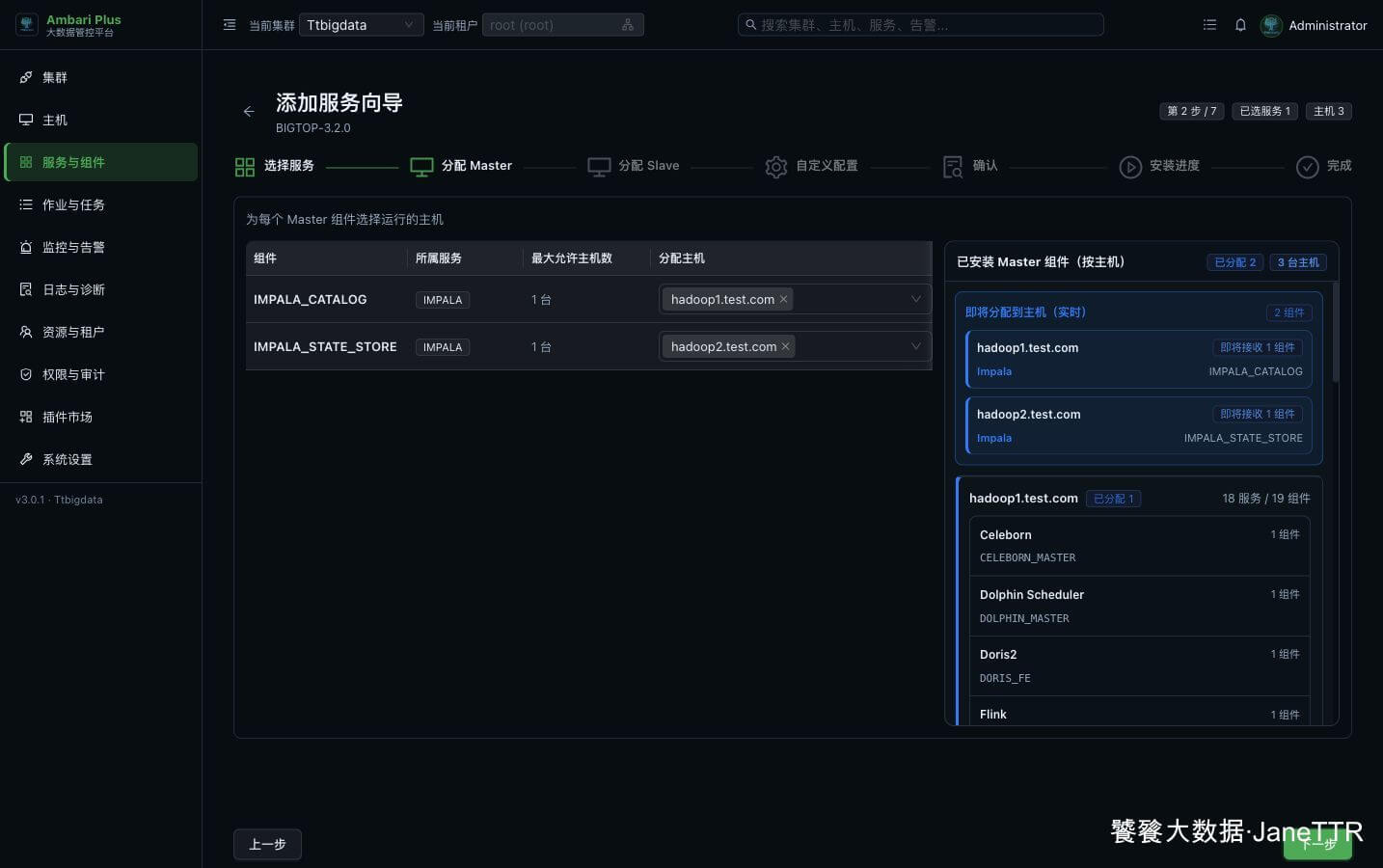
本次分配如下:
| 组件 | 主机 | 说明 |
|---|---|---|
IMPALA_CATALOG | hadoop1.test.com | 负责 Hive Metastore 元数据缓存、表结构变更同步和 Catalog 服务。 |
IMPALA_STATE_STORE | hadoop2.test.com | 负责 Daemon 成员状态、心跳和查询调度相关的集群状态维护。 |
Catalog 和 StateStore 都是控制面角色。小集群里各放一台机器就可以把职责分清楚;生产环境再结合高可用、查询并发和节点规模做进一步规划。
# 3. 分配 Impala Daemon
Slave 分配页里主要看 IMPALA_DAEMON。
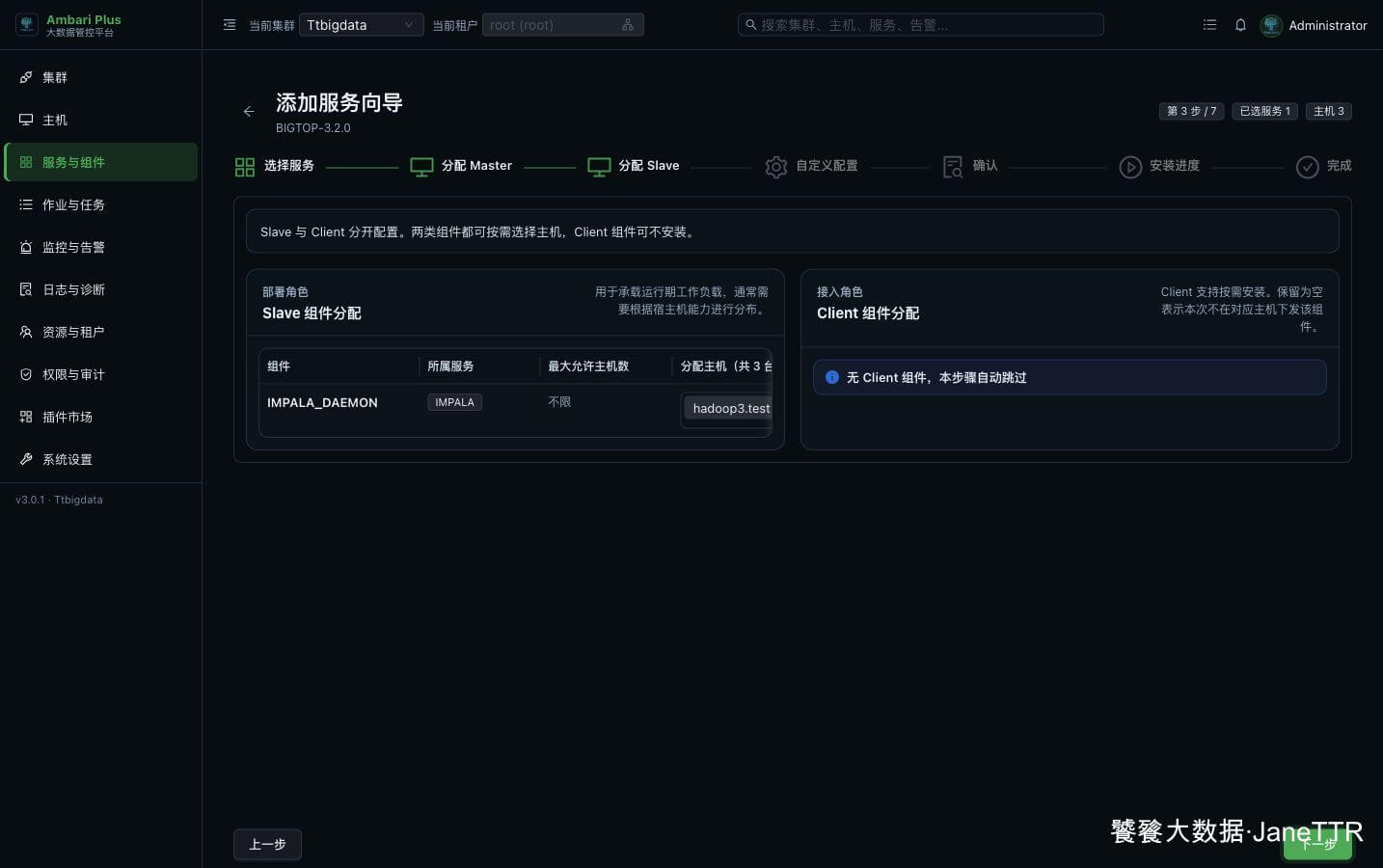
本次把 Daemon 分配到三台主机:
| 组件 | 分配主机 | 说明 |
|---|---|---|
IMPALA_DAEMON | hadoop1.test.com、hadoop2.test.com、hadoop3.test.com | 承接 SQL 查询执行、数据扫描、Join、聚合等计算任务。 |
Impala Daemon 是真正跑查询的角色。教程环境里三台都装,能让后续测试更接近真实集群;如果生产环境有独立计算节点,可以把 Daemon 只放在计算节点上。
# 4. 检查默认配置
进入自定义配置页后,先看顶部状态。这里 待填写 0,说明必填项已经满足;页面同时给出 2 项推荐配置。
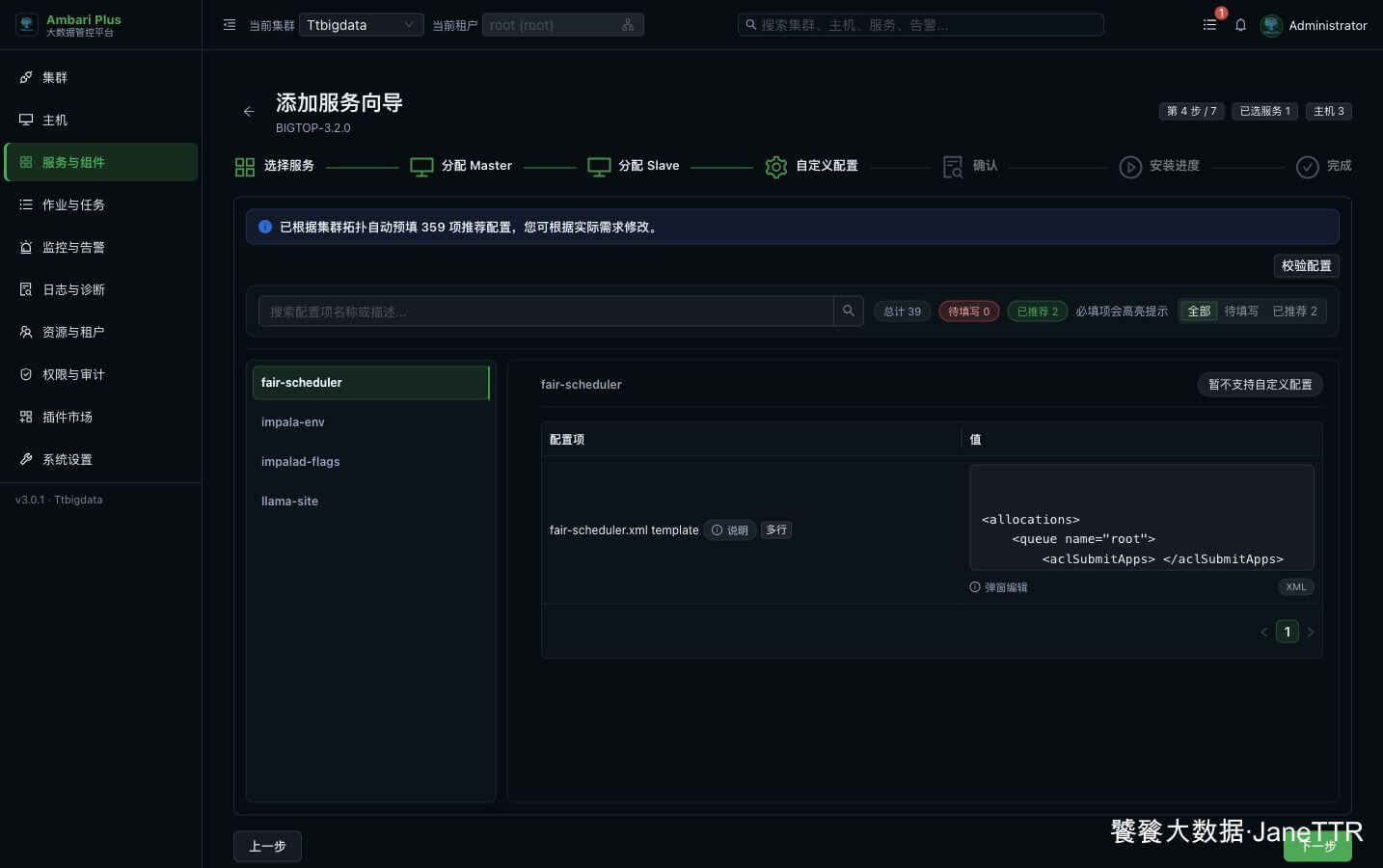
Impala 的配置项分散在几个标签页里:
| 配置页 | 重点内容 |
|---|---|
impala-env | 运行用户、日志目录、PID 目录、Catalog / StateStore / Daemon 启动参数、Ranger 开关。 |
impalad-flags | Impala Daemon 运行参数。 |
fair-scheduler | 查询准入、队列和资源调度相关配置。 |
llama-site | 资源准入相关配置,普通教程环境保持默认即可。 |
这一页不要急着点下一步,至少把 impala-env 看一遍。Impala 启动失败时,很多问题都和启动参数、Hive Metastore、Ranger 或 Kerberos 凭据有关。
# 5. 调整 impala-env
切到 impala-env,重点确认 Ranger 开关和 Catalog 参数。
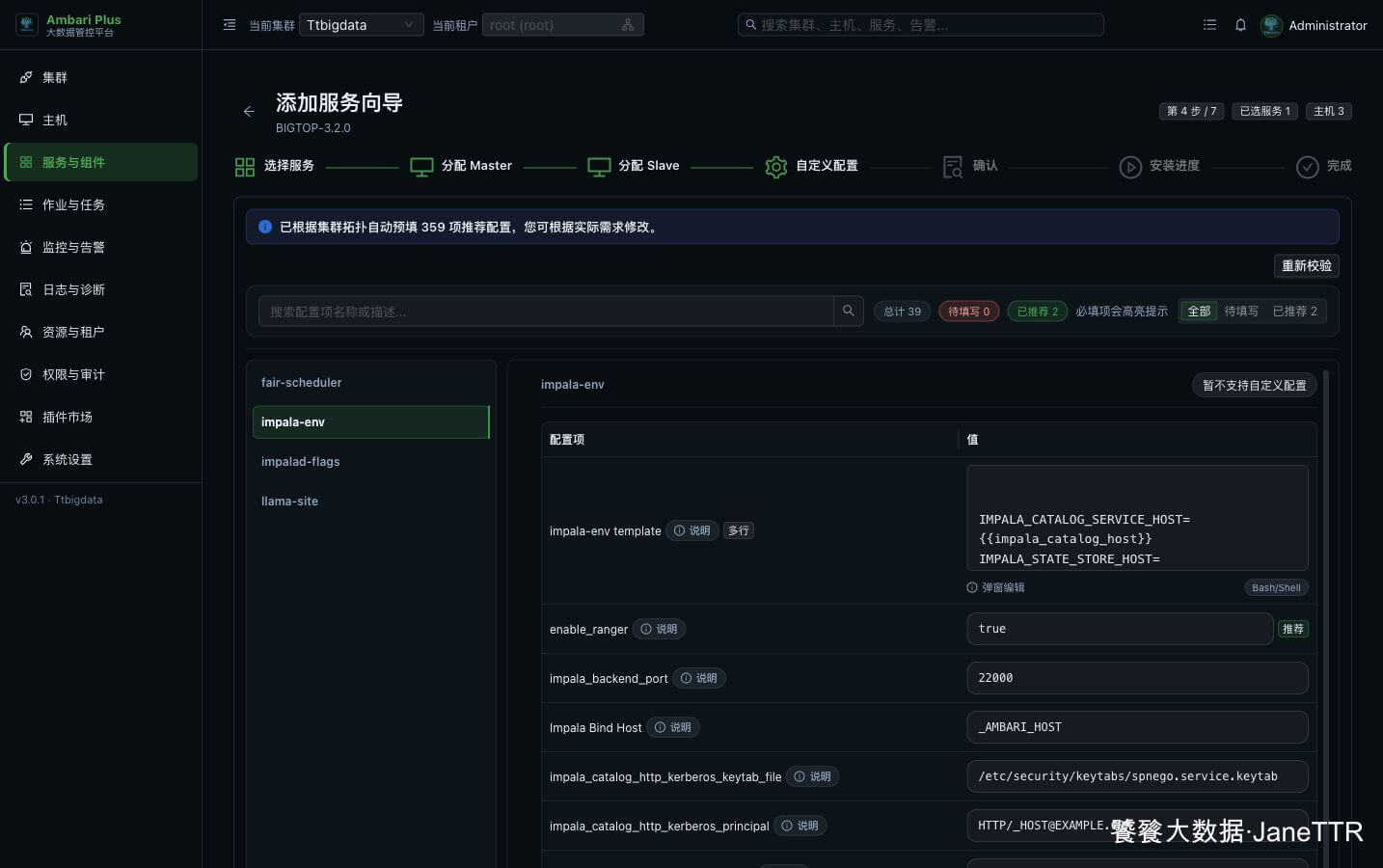
本次环境里,enable_ranger 保持开启,ranger_service_name 使用页面推荐值。这样 Impala 访问 Hive 表时,可以继续走 Ranger 侧的权限治理。
如果当前 Hive Metastore 的 notification event 还没有单独治理好,我建议在 Catalog 参数段里补上下面这一行,先让 Impala Catalog 稳定启动:
-hms_event_polling_interval_s=0 \
这个参数可以放在 IMPALA_CATALOG_ARGS 里,紧跟 -invalidate_global_metadata_on_event_processing_failure=true \ 后面。它的作用是关闭 Catalog 对 Hive Metastore event 的轮询,适合教程环境先跑通服务链路;生产环境如果要依赖 Metastore 事件做更及时的元数据同步,再单独治理 Hive Metastore notification 相关配置。
笔记
Impala 自己不需要新建独立业务库。它读取的是已有 Hive Metastore 元数据,所以这里不需要像 Hive、Hue、DolphinScheduler 那样再配置一组 MySQL / MariaDB 元数据库。
# 6. 确认安装清单
确认页会把新增服务、Master 分配、Slave 分配和配置校验集中列出来。
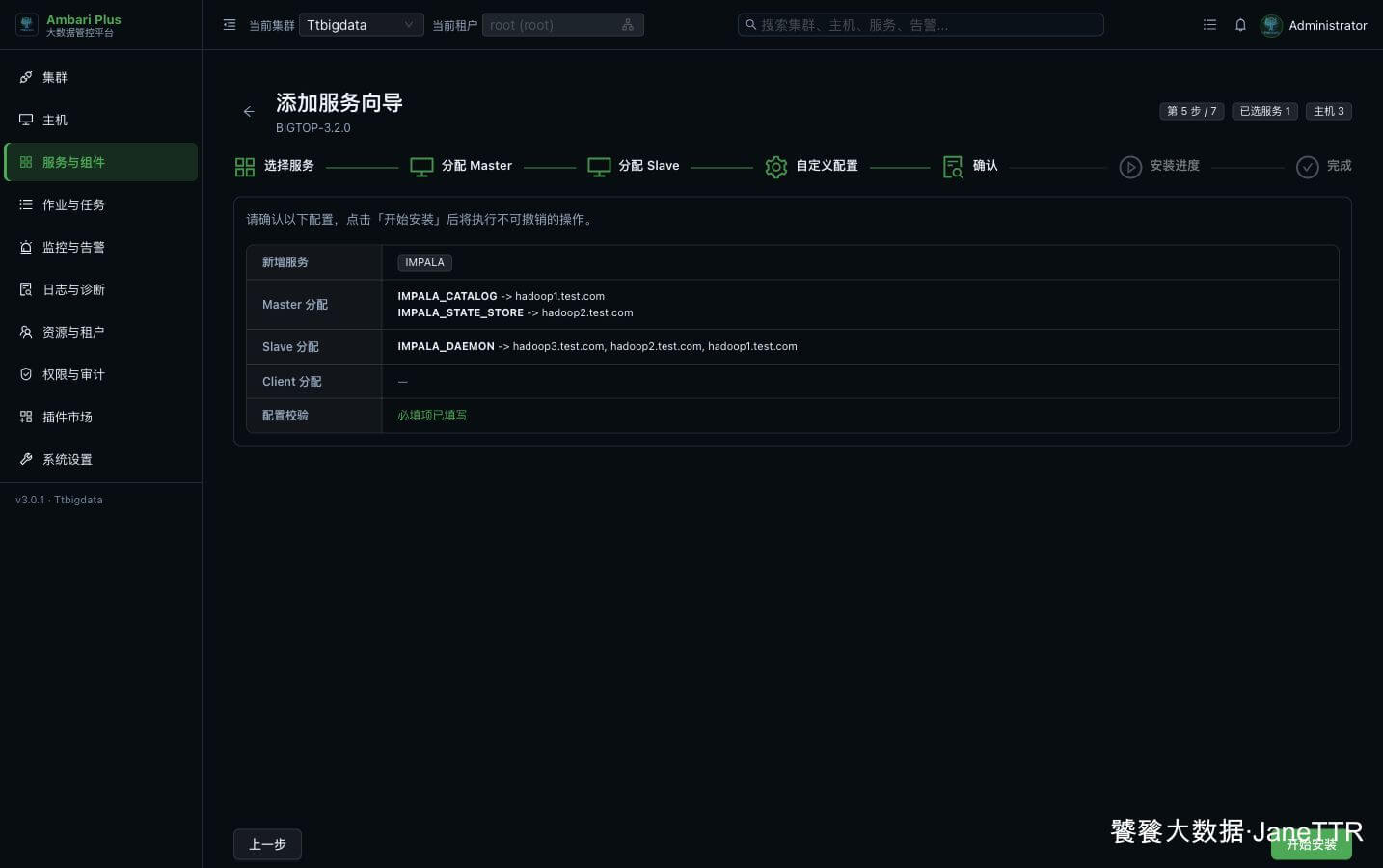
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | IMPALA |
| Master 分配 | IMPALA_CATALOG -> hadoop1.test.com;IMPALA_STATE_STORE -> hadoop2.test.com |
| Slave 分配 | IMPALA_DAEMON -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| Client 分配 | 无 |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 7. 等待 Impala 安装完成
开启 Kerberos 的集群中,新增 Impala 时会要求提交 KDC 管理员凭据。这里填写的是 KDC 管理员 Principal 和密码,用于生成并分发 Impala 相关 principal / keytab。
安装任务会依次完成软件包安装、配置下发、Kerberos 凭据生成和服务启动。
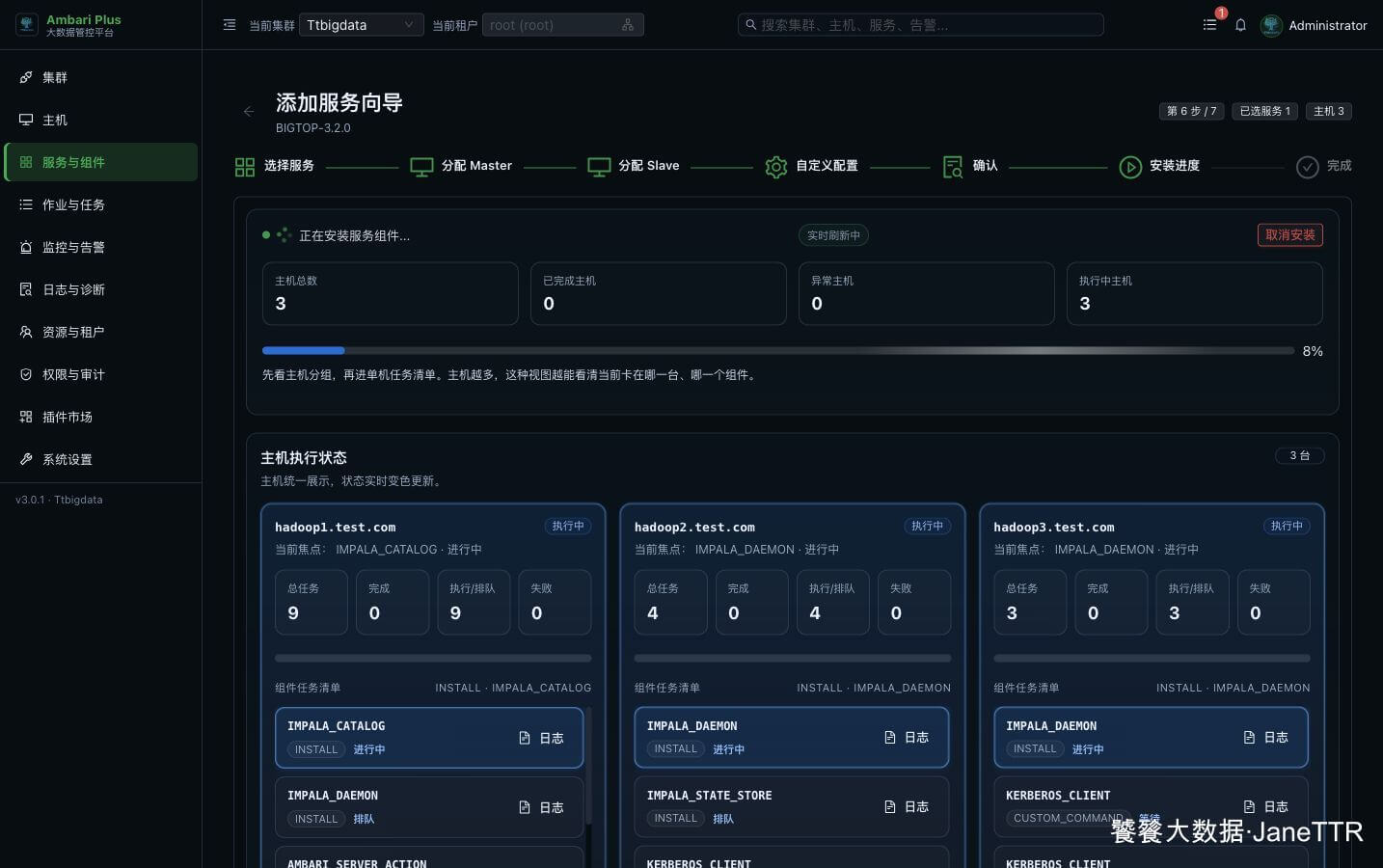
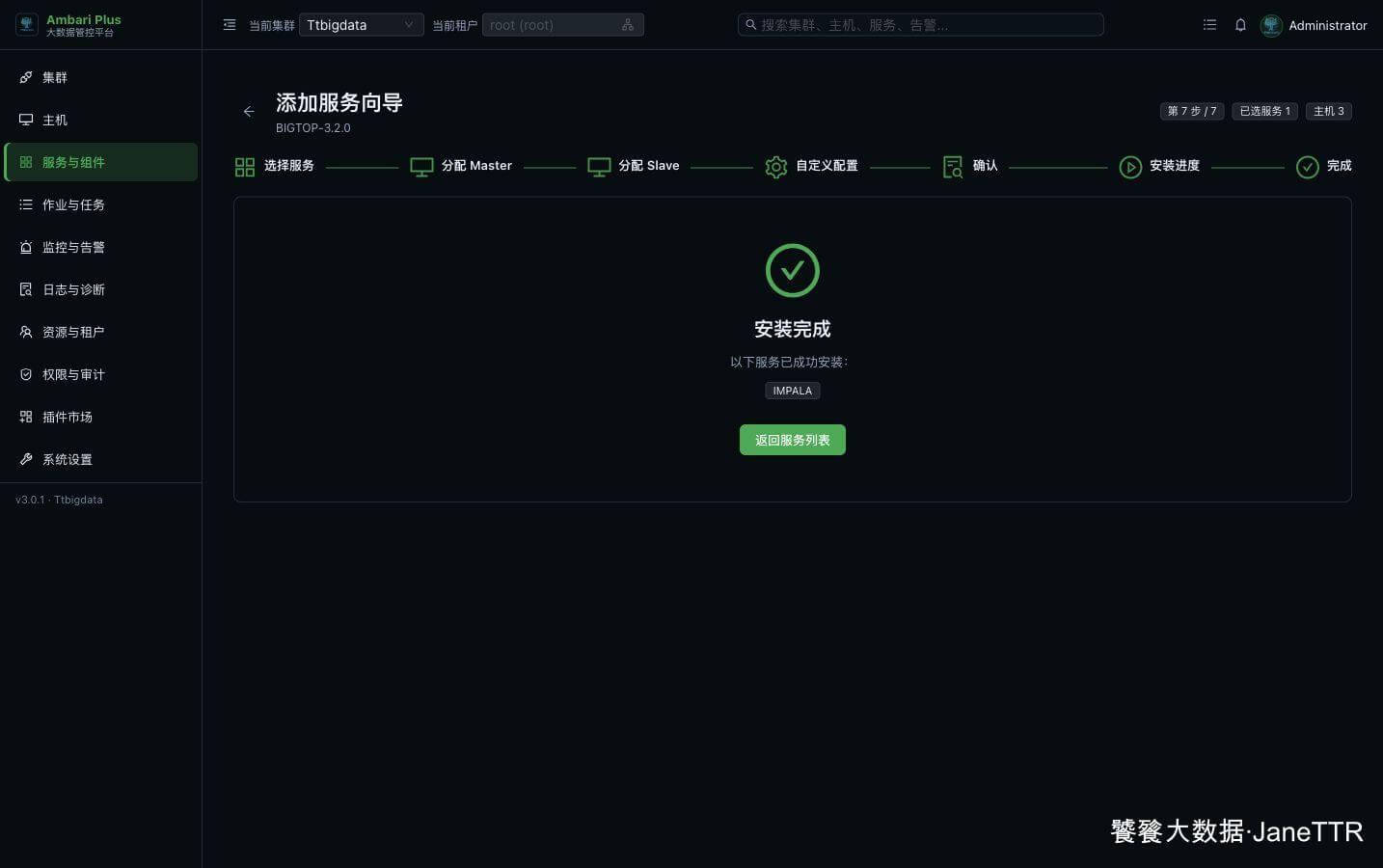
Impala 包比较大,安装阶段需要一点耐心。完成页显示 IMPALA 后,就可以返回服务列表。
注意
如果安装进度页在包安装阶段中断,不要马上重复清理环境。可以先到对应主机确认 Impala RPM 是否已经安装完成;如果包已经落地,再回到向导里 返回重试,通常可以继续后面的配置下发、凭据生成和服务启动。
# 8. 回到服务列表确认状态
回到 服务与组件 页面,Impala 会出现在 查询数据 分类下。
页面里可以看到:
| 组件 | 数量 | 状态 |
|---|---|---|
Impala StateStore | 1 | 运行中 |
Impala Catalog | 1 | 运行中 |
Impala Daemon | 3 | 运行中 |
如果想在服务端再看一眼端口,可以在对应主机上检查 Impala 常用端口:
ss -lntp | egrep ':(21000|21050|25000|25010|25020|24000|22000)\b'
hadoop1.test.com 上能看到 Catalog 和本机 Daemon 相关端口,hadoop2.test.com 上能看到 StateStore 和本机 Daemon 相关端口,三台主机都应该能看到 Daemon 端口。到这里,Impala 的基础安装完成。下一篇继续安装 Trino,把另一条交互式 SQL 查询入口也补上。