 Trino 安装474
Trino 安装474
# Trino 安装
Trino 是分布式 MPP SQL 查询引擎,适合把 Hive、Iceberg、Paimon、Hudi、Kafka、MySQL 等多个数据源统一到一个 SQL 查询入口里。前面已经安装了 HDFS、Hive、Ranger、Kerberos、Ozone 和 Impala,这里继续补 Trino,后面做湖仓表格式、查询入口和权限治理时就更完整。
本篇继续使用三台 FQDN 主机:
| 主机 | Trino 角色 |
|---|---|
hadoop1.test.com | TRINO_COORDINATOR、TRINO_WORKER、TRINO_CLI |
hadoop2.test.com | TRINO_WORKER、TRINO_CLI |
hadoop3.test.com | TRINO_WORKER、TRINO_CLI |
这里把 Coordinator 放在 hadoop1.test.com,Worker 覆盖三台机器,Client 也分发到三台机器。教程环境这样做比较直观:hadoop1.test.com 是查询入口,其余节点一起承担查询执行。
提示
Trino 安装完成只是把 Coordinator、Worker 和 CLI 部署好。真正查询 Hive、Iceberg、Paimon、Hudi 等数据源,还要继续配置对应 catalog。本文先把 Trino 服务本身安装起来。
# 1. 选择 Trino 服务
进入 服务与组件,点击 新增服务,在增强组件列表里勾选 Trino。
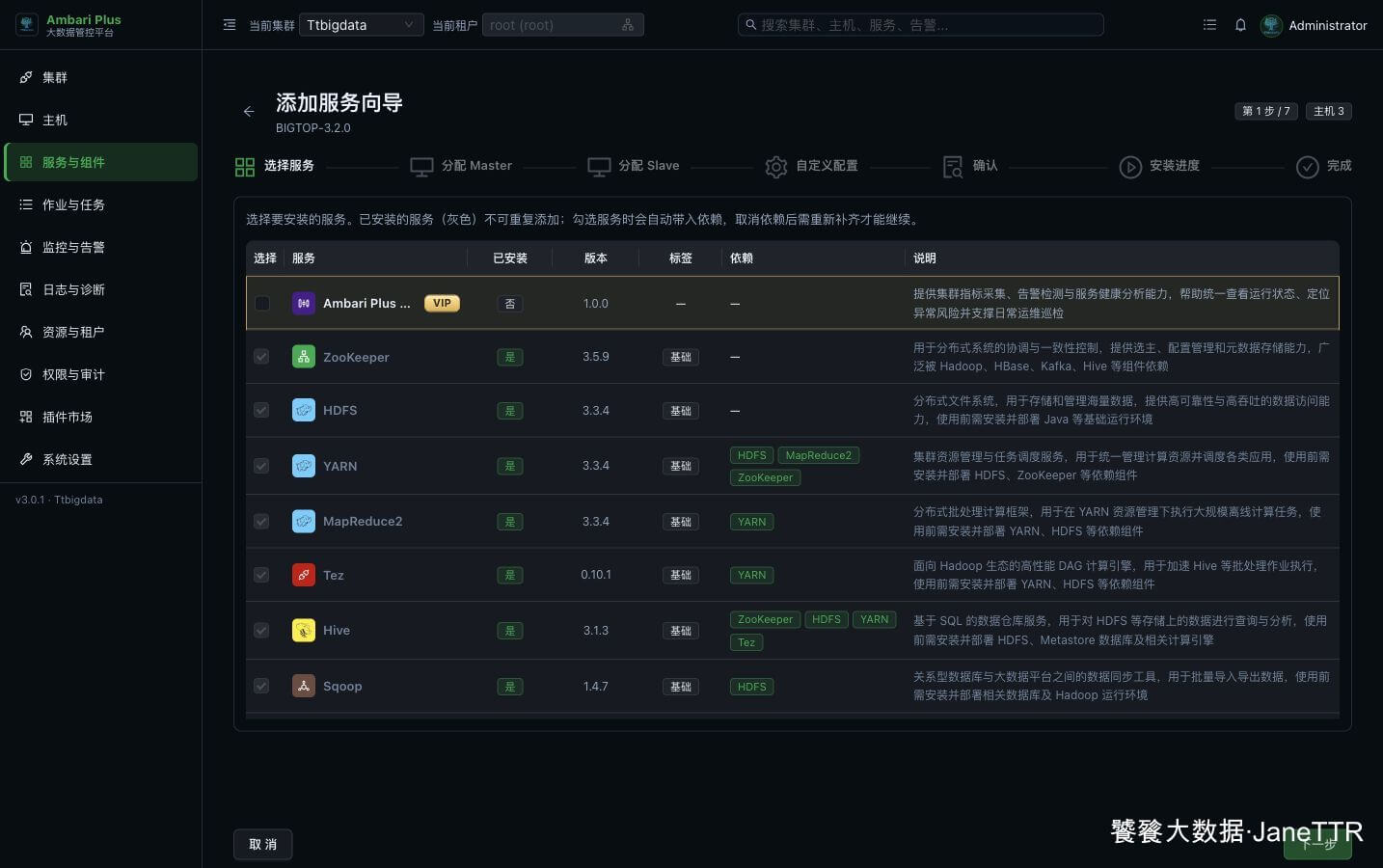
本篇只安装 Trino。Trino 本身不需要像 Hive、Hue 那样准备独立元数据库,它更多依赖后续 catalog 配置去连接外部数据源。
# 2. 分配 Trino Coordinator
Master 分配页里只有一个核心角色:TRINO_COORDINATOR。
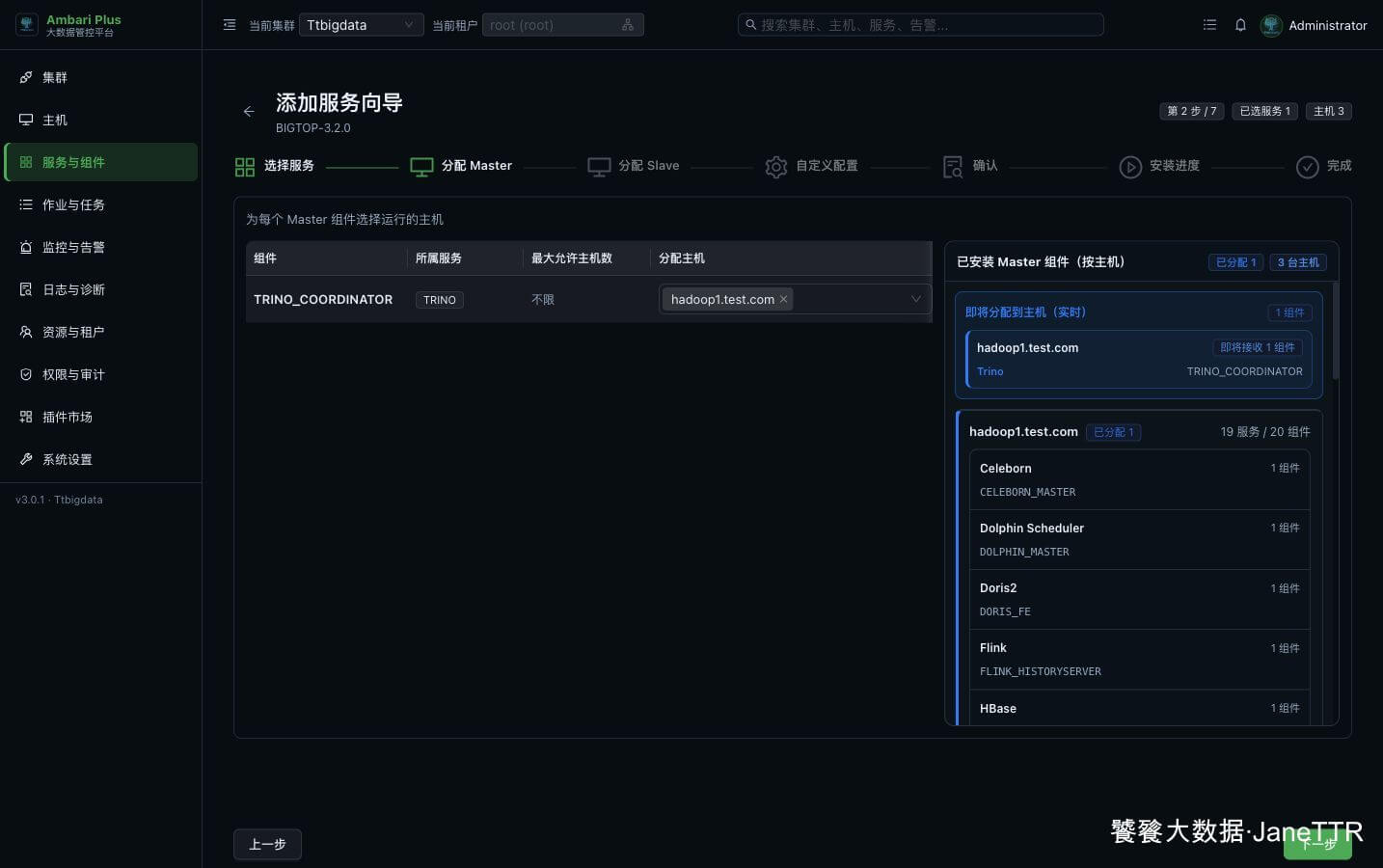
本次把 Coordinator 放在 hadoop1.test.com:
| 组件 | 主机 | 说明 |
|---|---|---|
TRINO_COORDINATOR | hadoop1.test.com | 接收 SQL 请求、解析查询计划、协调 Worker 执行任务。 |
小集群里 Coordinator 放在管理节点最清晰。生产环境如果并发较高,可以结合 Coordinator 专用节点、负载均衡、资源隔离和 catalog 数量重新规划。
# 3. 分配 Worker 和 Client
Slave / Client 分配页里会看到两个角色:TRINO_WORKER 和 TRINO_CLI。
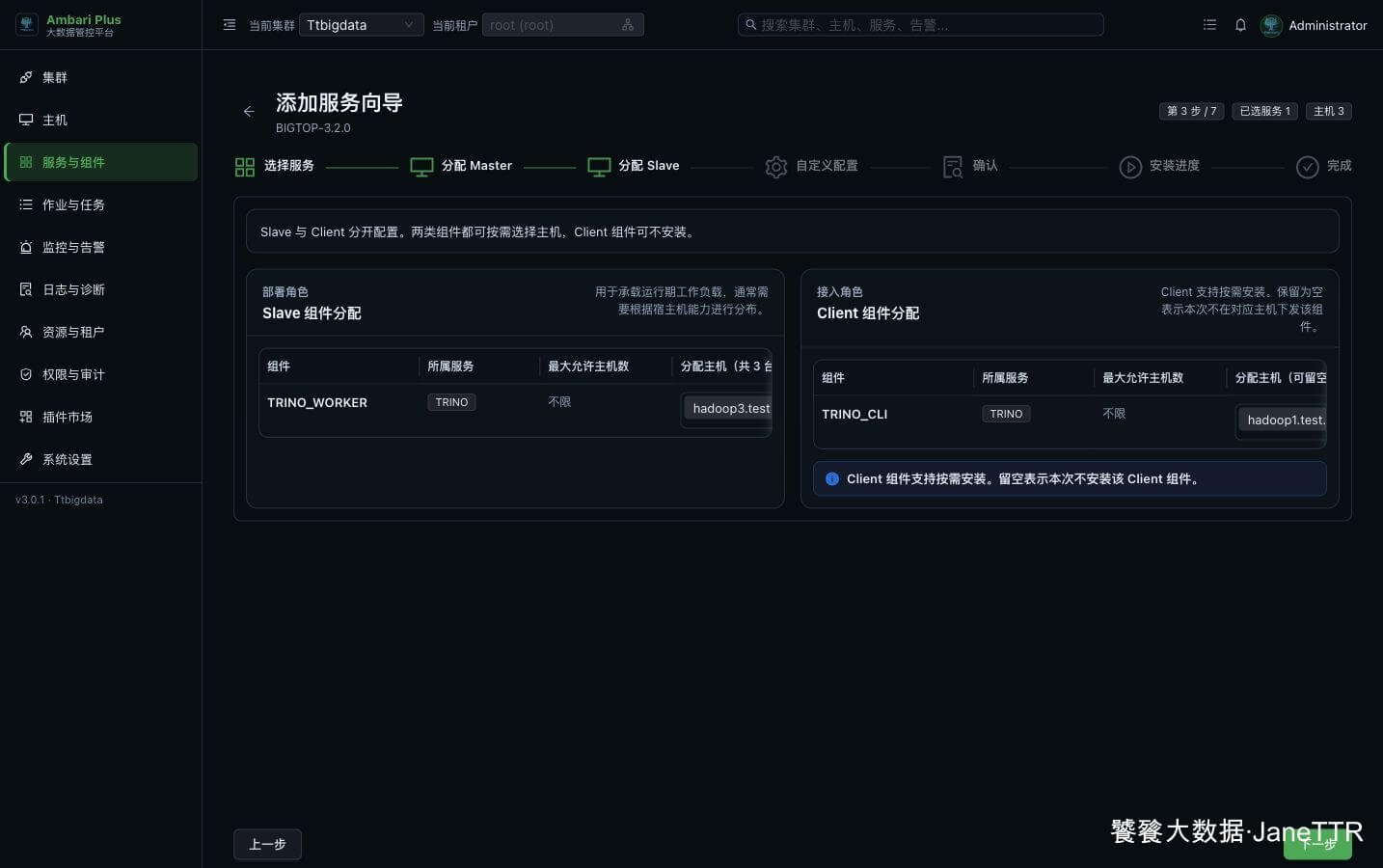
本次分配如下:
| 组件 | 分配主机 | 说明 |
|---|---|---|
TRINO_WORKER | 三台主机 | 承接查询执行任务。 |
TRINO_CLI | 三台主机 | 下发 Trino 命令行客户端,方便在各节点调试连接。 |
Worker 覆盖三台后,查询任务能分散到所有节点上执行。Client 也建议三台都装,后面排查 catalog、Kerberos 或 Hive 连接问题时,不必只在一台机器上调试。
# 4. 检查 Trino 基础配置
进入自定义配置页后,先看顶部状态。这里 待填写 0,说明必填项已经满足;页面同时给出 7 项推荐配置。
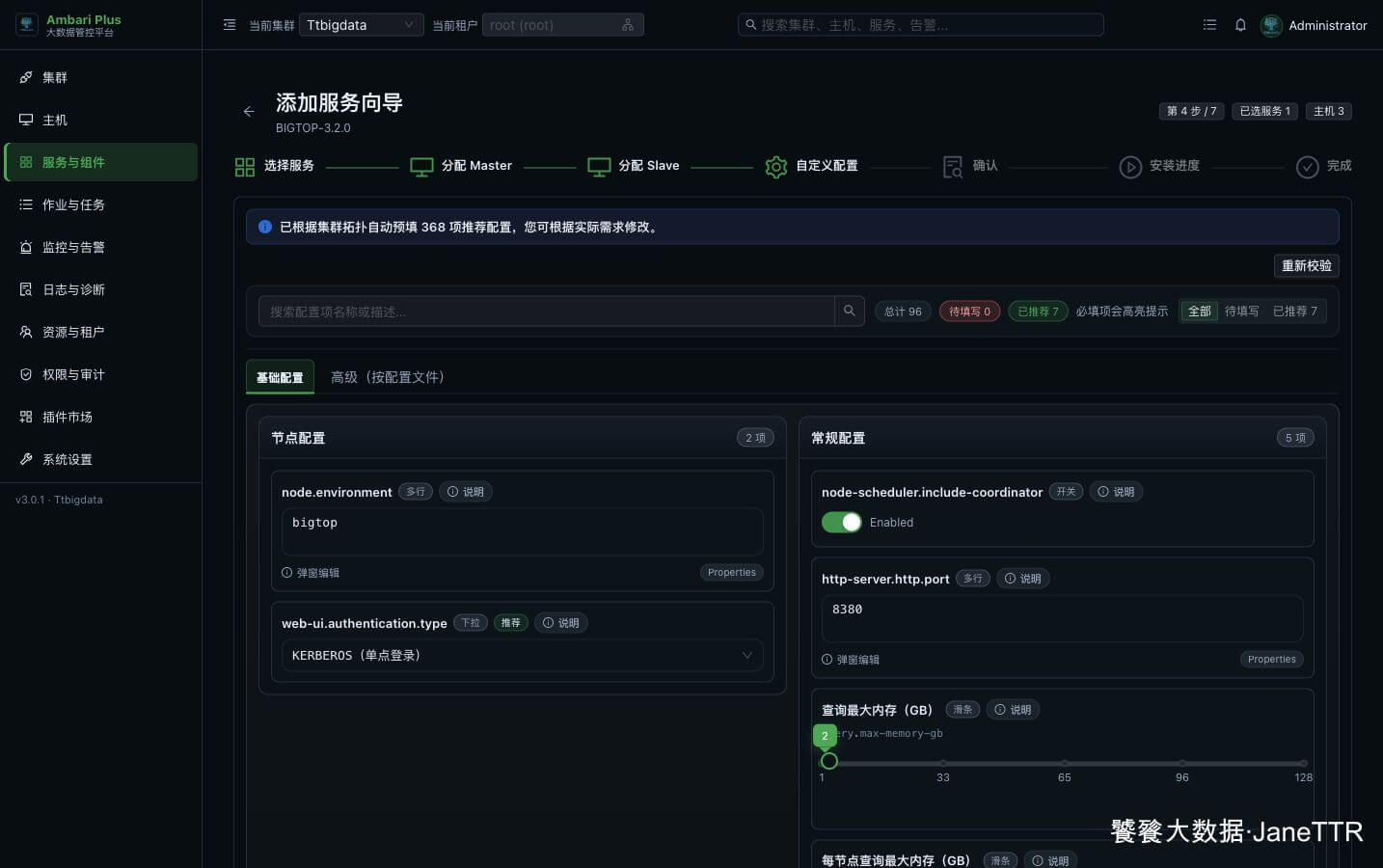
这页重点看下面几项:
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
node.environment | bigtop | Trino 节点环境名,同一集群内保持一致。 |
web-ui.authentication.type | KERBEROS | Web UI 使用 Kerberos 认证。 |
node-scheduler.include-coordinator | Enabled | 教程环境允许 Coordinator 也参与执行任务。 |
http-server.http.port | 8380 | Trino Web / HTTP 入口端口。 |
query.max-memory-gb | 2 | 单个查询的总内存上限。 |
query.max-memory-per-node-gb | 1 | 单个查询在每个节点上的内存上限。 |
discovery.uri | | 由服务角色和模板自动渲染。 |
教程环境里内存值偏保守,是为了先把服务稳定跑起来。生产环境需要结合机器内存、查询并发、catalog 数量和资源隔离策略重新调整。
# 5. 确认安装清单
确认页会把新增服务、Master 分配、Slave 分配、Client 分配和配置校验集中列出来。
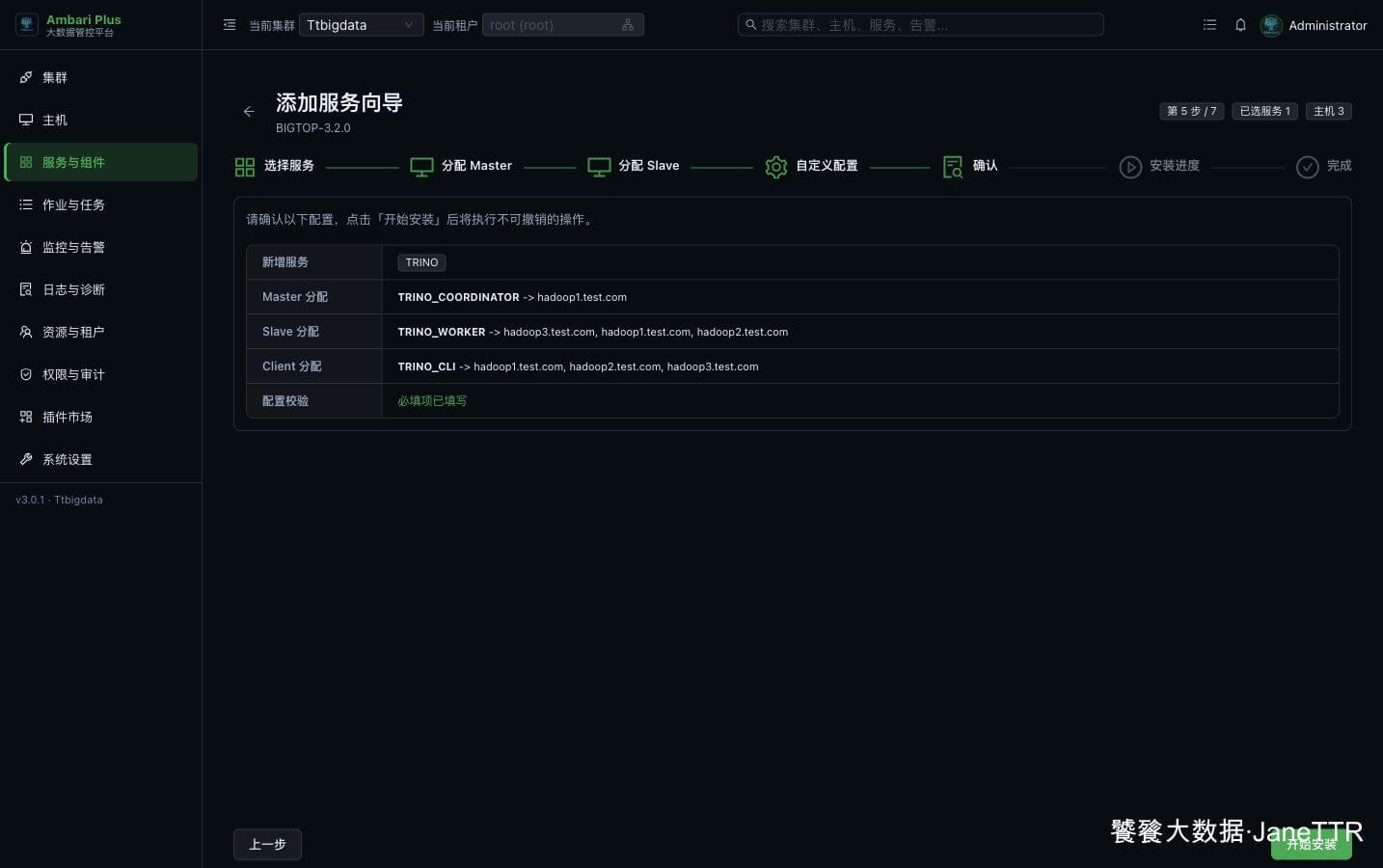
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | TRINO |
| Master 分配 | TRINO_COORDINATOR -> hadoop1.test.com |
| Slave 分配 | TRINO_WORKER -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| Client 分配 | TRINO_CLI -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
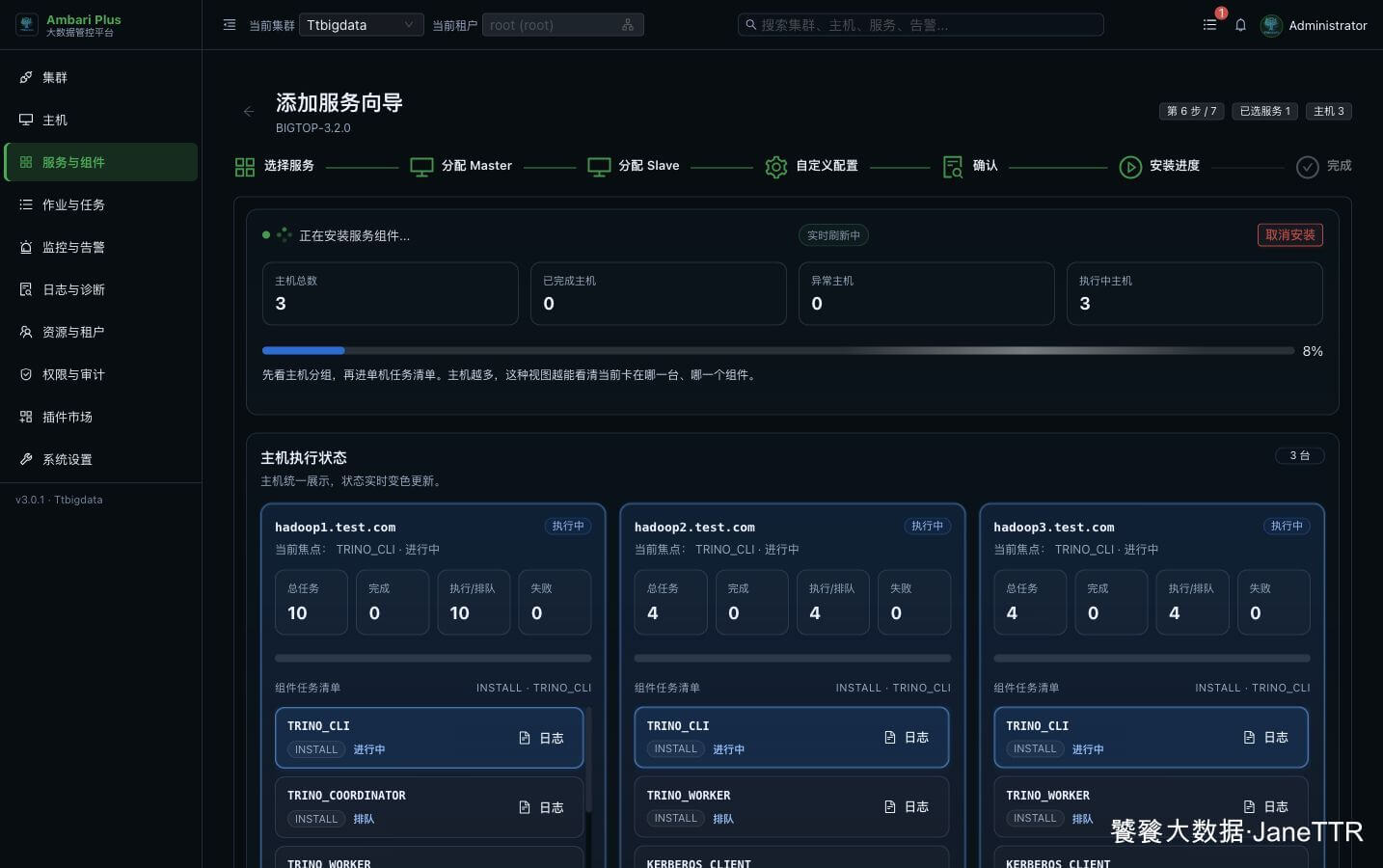
# 6. 等待 Trino 安装完成
开启 Kerberos 的集群中,新增 Trino 时会要求提交 KDC 管理员凭据。这里填写的是 KDC 管理员 Principal 和密码,用于生成并分发 Trino 相关 principal / keytab。
安装任务会依次完成软件包安装、配置下发、Kerberos 凭据生成和服务启动。
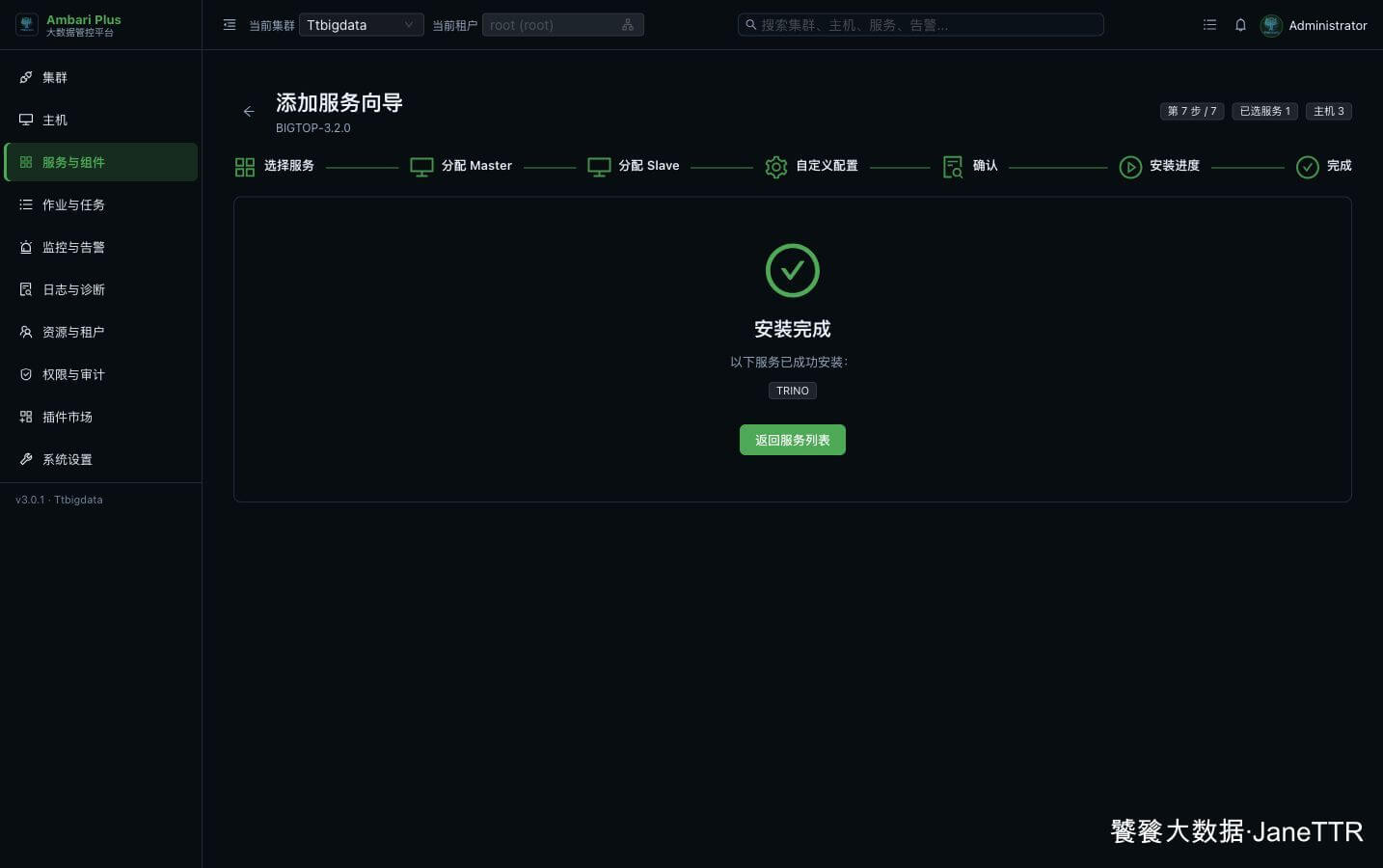
完成页显示 TRINO 后,就可以返回服务列表。
如果安装失败,优先看失败主机上的 TRINO_COORDINATOR 或 TRINO_WORKER 任务日志。Trino 常见问题一般集中在端口占用、Kerberos 凭据、Java 环境和配置模板渲染。
# 7. 回到服务列表确认状态
回到 服务与组件 页面,Trino 会出现在查询类服务列表里。
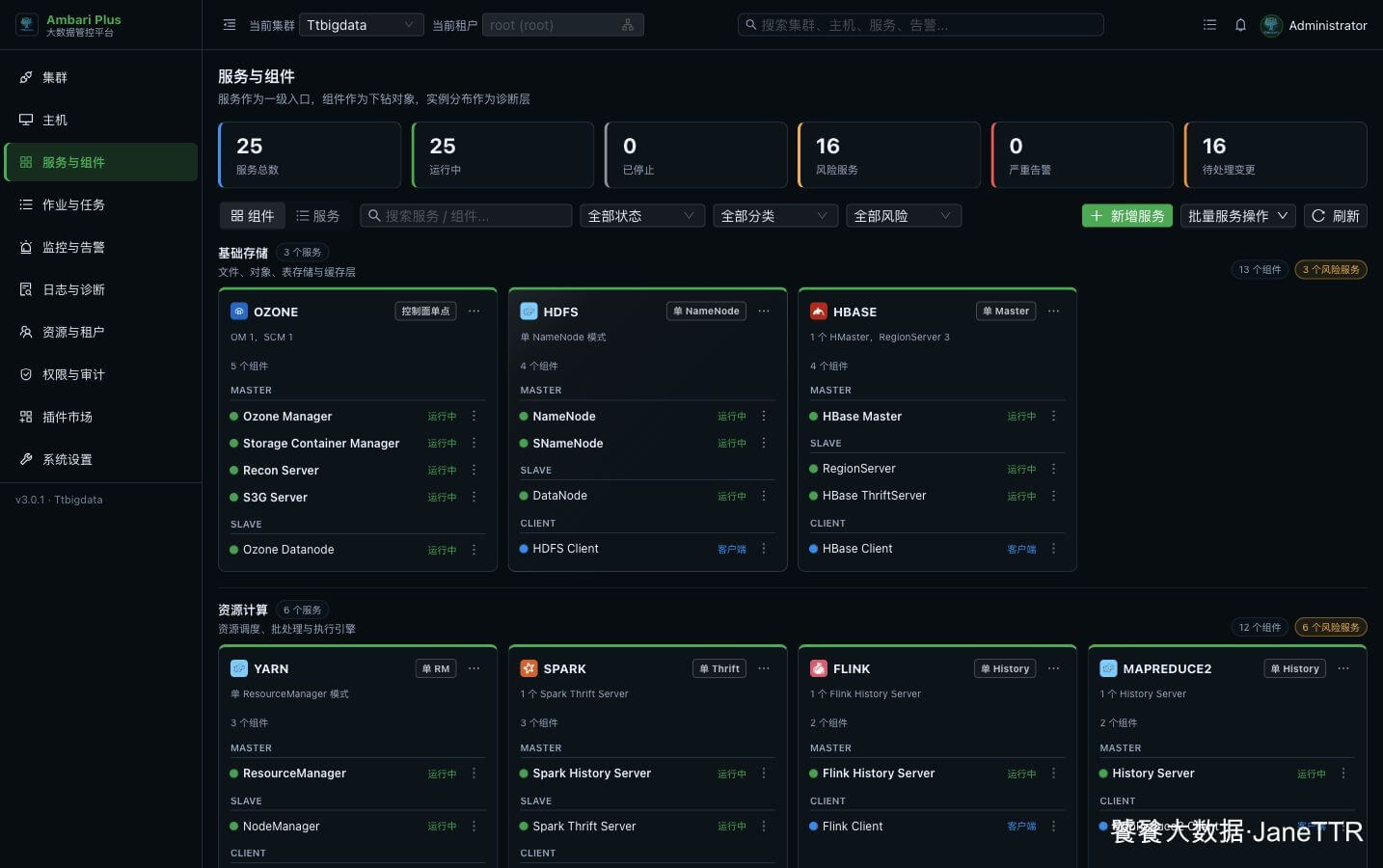
页面里可以看到:
| 组件 | 数量 | 状态 |
|---|---|---|
Trino Coordinator | 1 | 运行中 |
Trino Worker | 3 | 运行中 |
Trino Client | 3 | 客户端 |
如果想从服务端看端口,可以在 hadoop1.test.com 上确认 8380 已经监听:
ss -lntp | grep 8380
# 8. 查看实例分布
进入 TRINO 详情页,打开 实例分布。
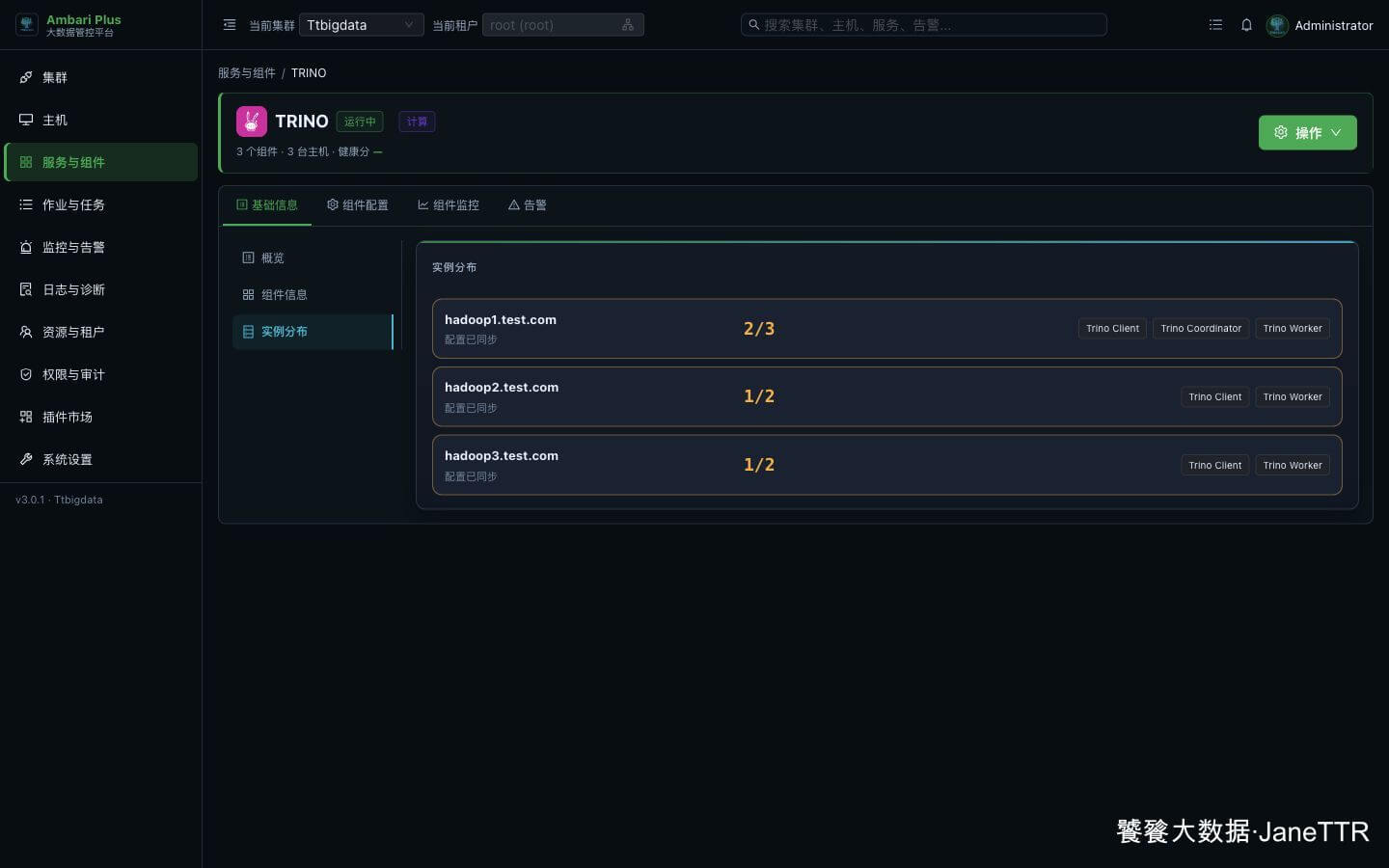
页面里可以看到:
| 主机 | 运行组件 |
|---|---|
hadoop1.test.com | Trino Client、Trino Coordinator、Trino Worker |
hadoop2.test.com | Trino Client、Trino Worker |
hadoop3.test.com | Trino Client、Trino Worker |
这里 hadoop1.test.com 显示 2/3,另外两台显示 1/2,这是正常现象:Trino Client 是客户端文件分发,不是常驻服务进程;真正运行的是 Coordinator 和 Worker。
Trino Web 入口可以这样访问:
http://hadoop1.test.com:8380/
当前 Web UI 使用 Kerberos 认证。后续如果要通过 Trino 查询 Hive、Iceberg、Paimon、Hudi 或 MySQL,还需要继续配置对应 catalog,并结合 Ranger / Kerberos 策略做权限验证。到这里,Trino 的基础安装完成。
下一篇继续安装 Paimon,把湖仓表格式客户端、Hive Metastore catalog 和 HDFS warehouse 基础配置补上。