 Superset 安装4.1.2
Superset 安装4.1.2
# Superset 安装
Superset 是大数据平台里很常见的数据可视化入口。前面已经把 HDFS、Hive、Trino、Spark、Atlas 等组件装好,这时再补 Superset,后面就可以逐步接入 Hive、Trino、Doris 等查询引擎,做仪表盘和交互式分析。
本篇继续使用三台 FQDN 主机,Superset Server 放在 hadoop1.test.com:
| 主机 | Superset 角色 |
|---|---|
hadoop1.test.com | SUPERSET |
hadoop2.test.com | 无 |
hadoop3.test.com | 无 |
Superset 需要一套独立的元数据库,用来保存用户、权限、数据源连接、图表、看板和查询记录。本文使用 hadoop1.test.com 上的 MySQL / MariaDB,演示库名、用户名和密码都使用 superset。生产环境请使用高复杂度密码,并按组件单独授权。
# 1. 准备 Superset 元数据库
先在 hadoop1.test.com 上用数据库管理员账号创建 Superset 元库和访问用户。演示环境里数据库管理员账号是 root / root:
CREATE DATABASE IF NOT EXISTS superset
DEFAULT CHARACTER SET utf8mb4
COLLATE utf8mb4_unicode_ci;
CREATE USER IF NOT EXISTS 'superset'@'%' IDENTIFIED BY 'superset';
ALTER USER 'superset'@'%' IDENTIFIED BY 'superset';
GRANT ALL PRIVILEGES ON superset.* TO 'superset'@'%';
FLUSH PRIVILEGES;
2
3
4
5
6
7
8
这里我建议把 Superset 元库和 Hive、Ranger、DolphinScheduler 这些组件的元库分开。以后做备份、迁移、权限收敛时,边界会清楚很多。
# 2. 选择 Superset 服务
进入 服务与组件,点击 新增服务,在服务列表里找到并勾选 Superset。
页面里可以看到 Superset 版本是 4.1.2,状态为“否”。本篇只安装 Superset 一个服务,安装后的问题更容易定位。
# 3. 分配 Superset Server
Master 分配页会出现 SUPERSET。
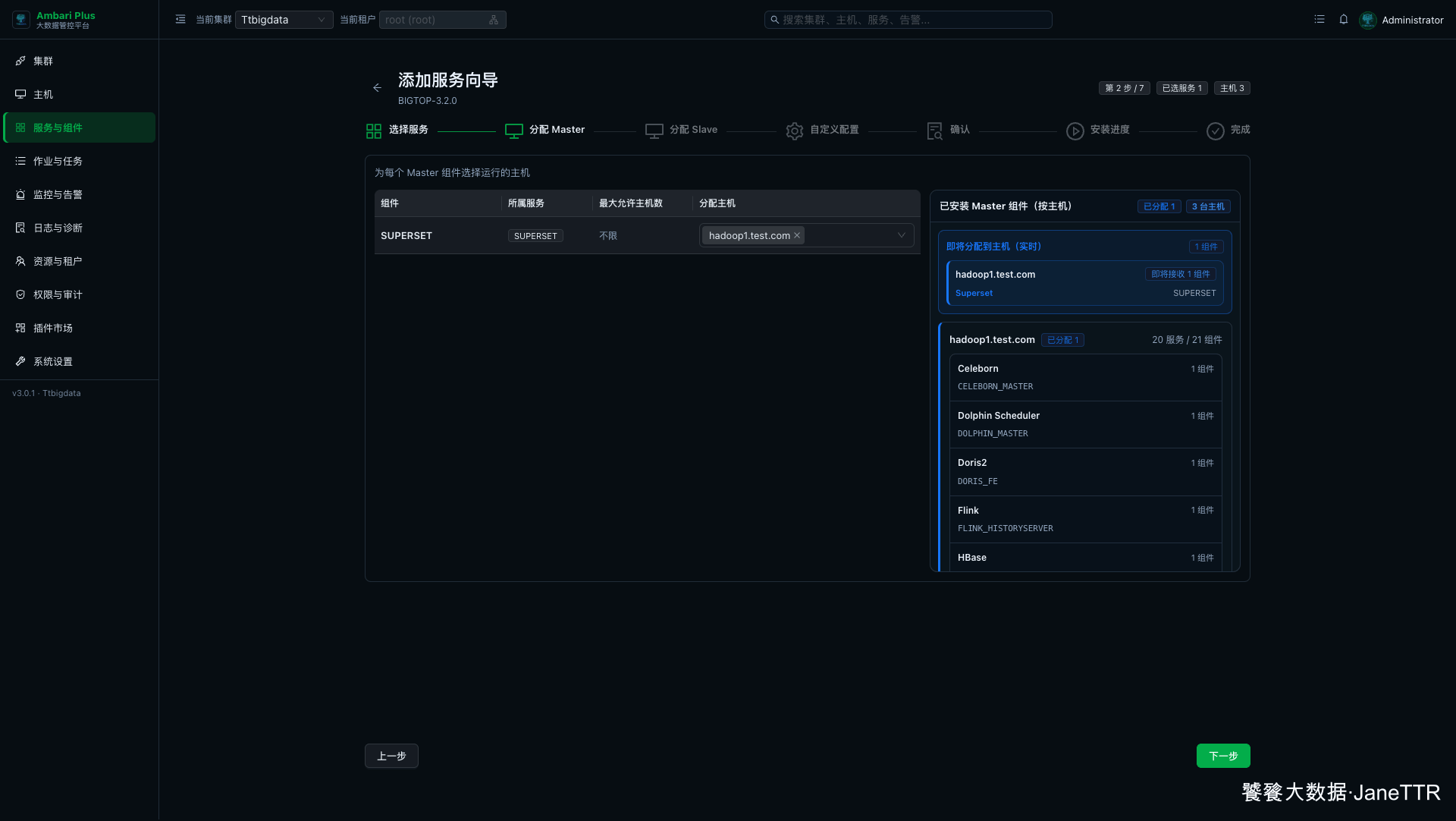
本次把 Superset Server 放在 hadoop1.test.com:
| 组件 | 分配主机 | 说明 |
|---|---|---|
SUPERSET | hadoop1.test.com | Superset Web、初始化任务和后台运行进程。 |
教程环境里 Superset 和数据库放在同一台机器,方便先把安装链路跑通。生产环境可以根据访问量、网关、负载均衡和数据库压力,把 Superset 放到独立的应用节点。
# 4. Slave / Client 页面直接下一步
Superset 没有 Slave 组件,也没有 Client 组件。
这个页面保持空即可。Superset 是单实例 Web 服务,真正要关注的是数据库、SECRET_KEY、监听端口和服务启动状态。
# 5. 填写数据库配置
进入自定义配置页后,切到 元数据存储配置。页面会自动推荐一部分配置,本篇按下面这样填写:
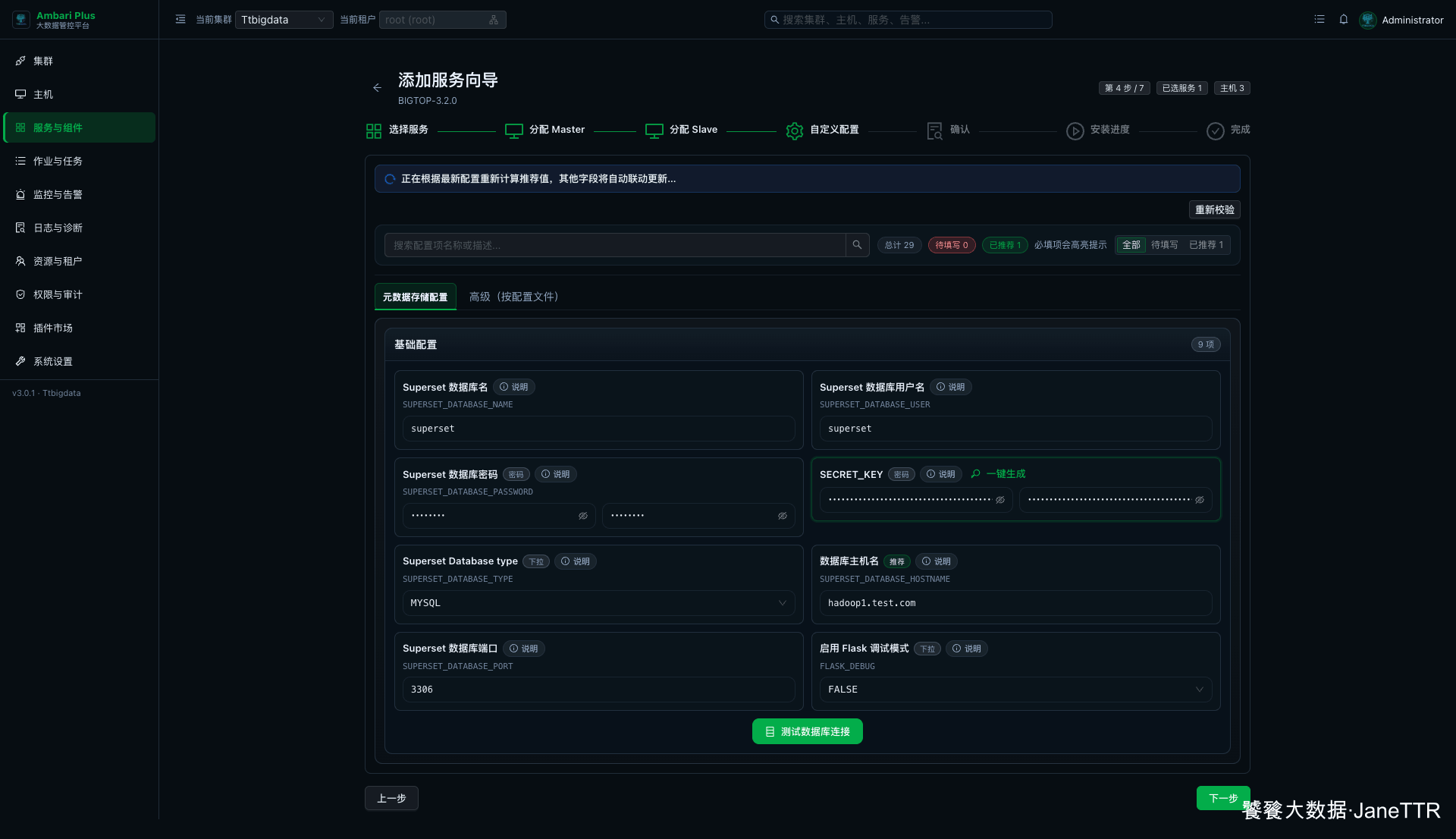
| 配置项 | 本文填写 |
|---|---|
| Superset 数据库名 | superset |
| Superset 数据库用户名 | superset |
| Superset 数据库密码 | superset |
| Superset Database type | MYSQL |
| 数据库主机名 | hadoop1.test.com |
| Superset 数据库端口 | 3306 |
| 启用 Flask 调试模式 | FALSE |
填写完成后,可以点击 测试数据库连接。只要数据库主机、端口、账号、密码和授权都正确,测试会很快完成。这里不建议把测试日志截图直接放到公开文档里,因为日志里可能会出现连接串和演示账号信息。
# 6. 生成 SECRET_KEY
Superset 需要 SECRET_KEY 来保护会话、签名和部分安全相关数据。页面提供了 一键生成。
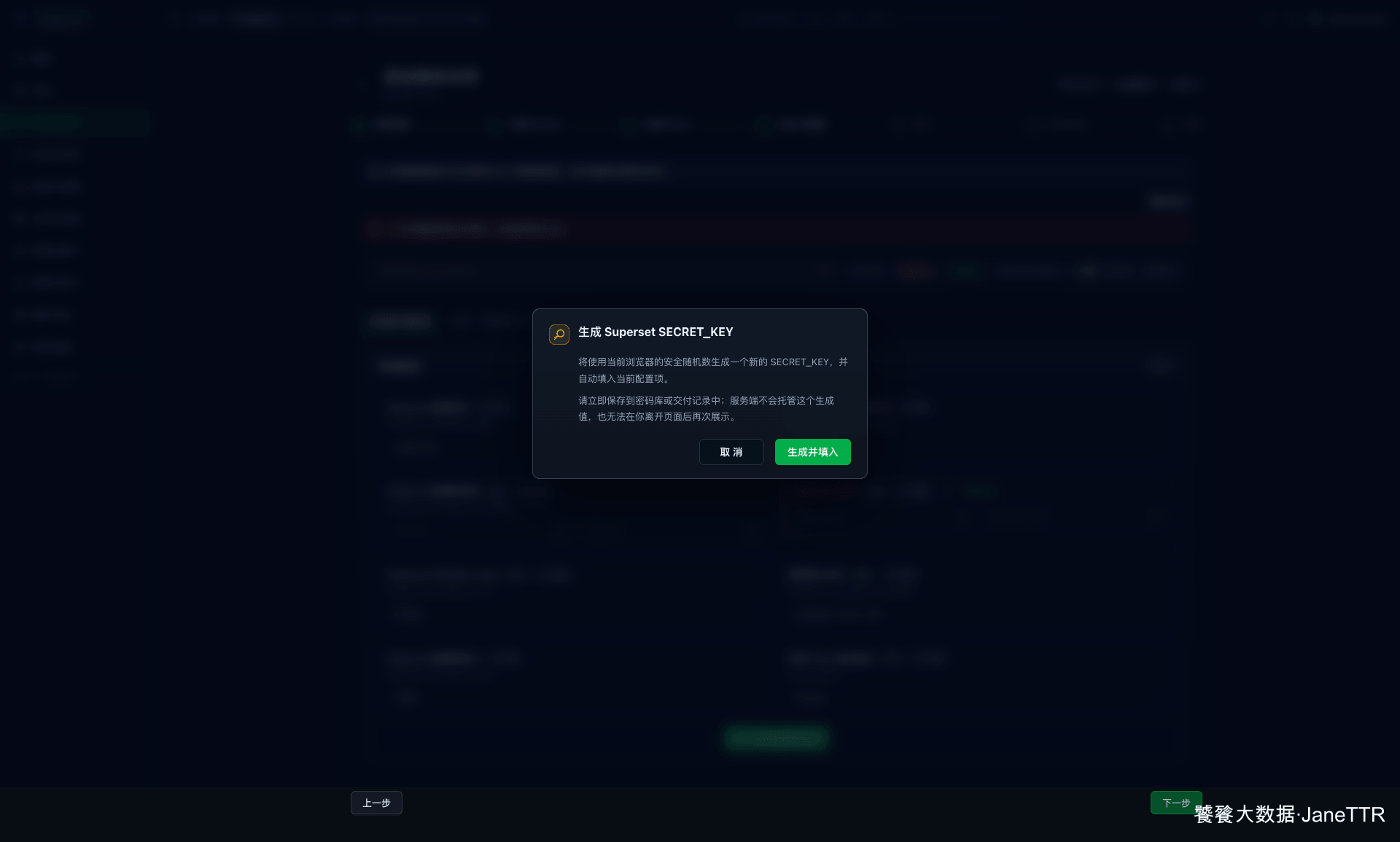
点击 生成并填入 后,页面会把生成结果写回配置框。这个值后续不要随意更换,也不要贴到公开文档或截图里。生产环境建议把它纳入密钥管理,升级、迁移和恢复时保持一致。
# 7. 确认安装清单
确认页会列出本次新增服务、Master 分配、Slave / Client 分配和配置校验结果。
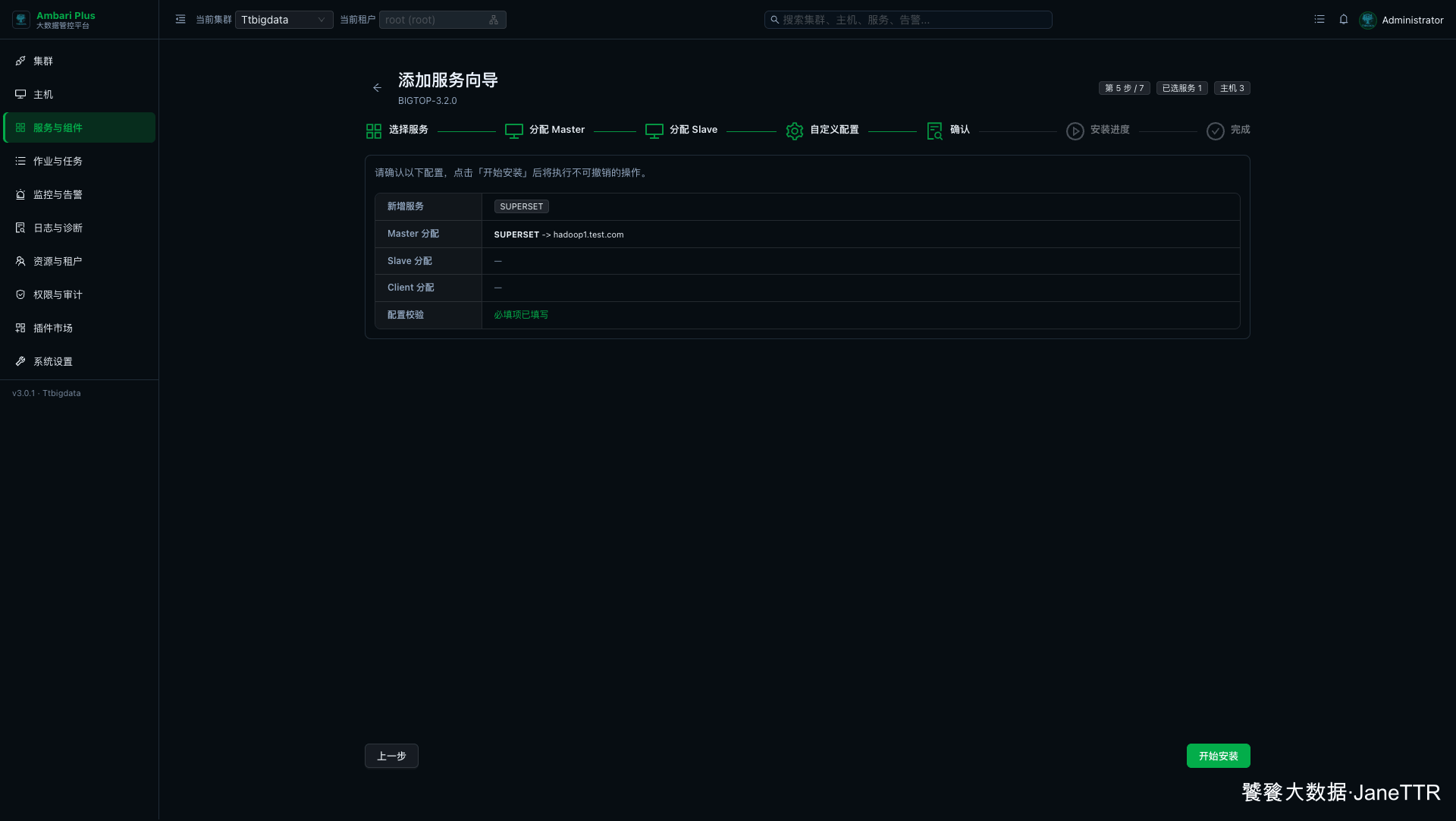
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | SUPERSET |
| Master 分配 | SUPERSET -> hadoop1.test.com |
| Slave 分配 | 无 |
| Client 分配 | 无 |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 8. 提交 Kerberos 凭据并等待安装
当前集群已经开启 Kerberos,新增 Superset 时会要求提交 KDC 管理员凭据。这里填写 KDC 管理员 Principal 和密码,用于生成并分发服务需要的凭据。
凭据提交后进入安装进度页。Superset 的安装任务会完成软件包安装、配置下发、Kerberos Client 刷新等动作。
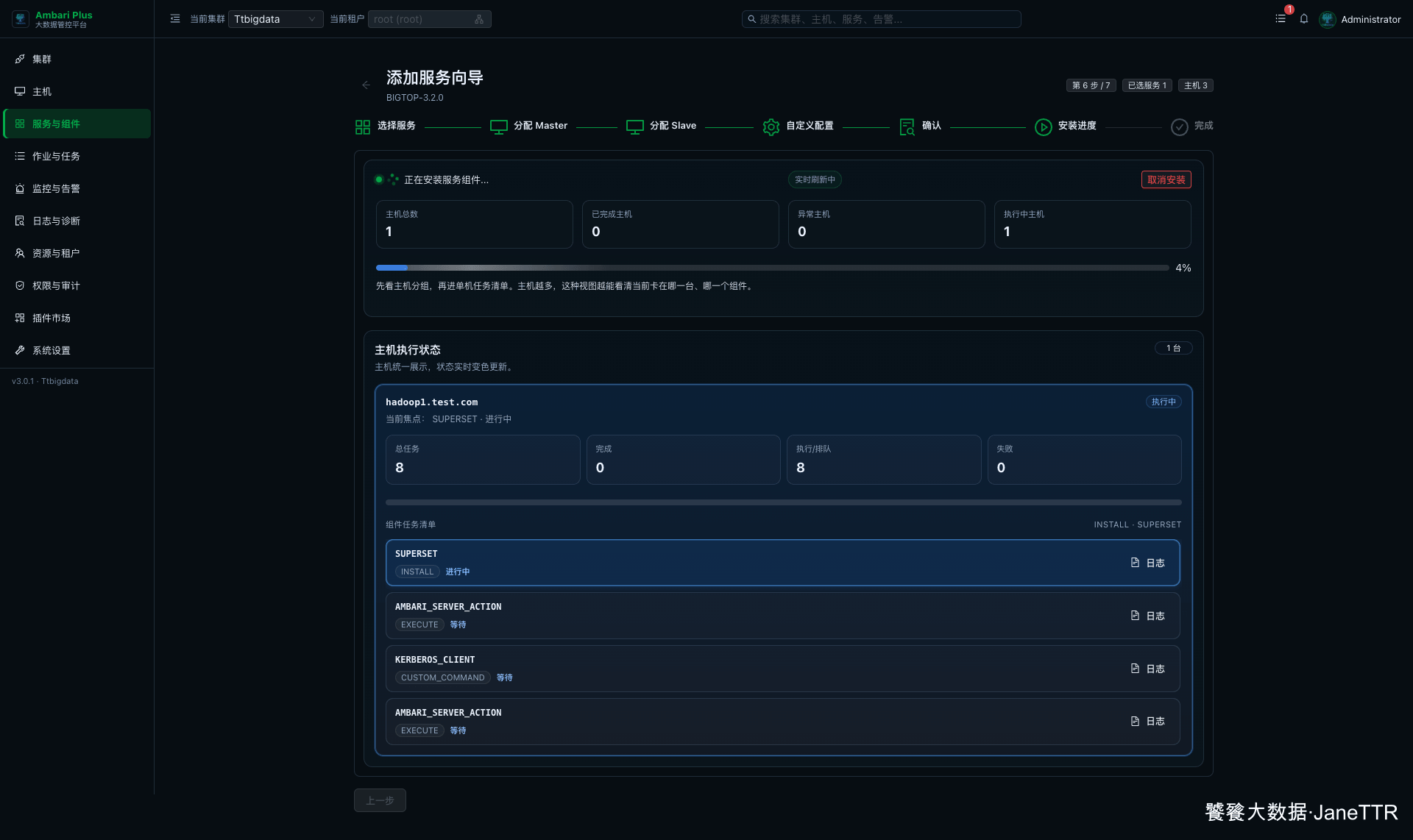
安装完成后,Superset 有时会先停留在“已安装”状态。这个时候不要以为失败了,回到服务页启动 Superset Server,启动阶段会继续完成元库初始化、管理员用户创建和 Web 进程拉起。
# 9. 启动后确认服务卡片
回到 服务与组件,搜索 superset。服务卡片里能看到 Superset Server 显示“运行中”。
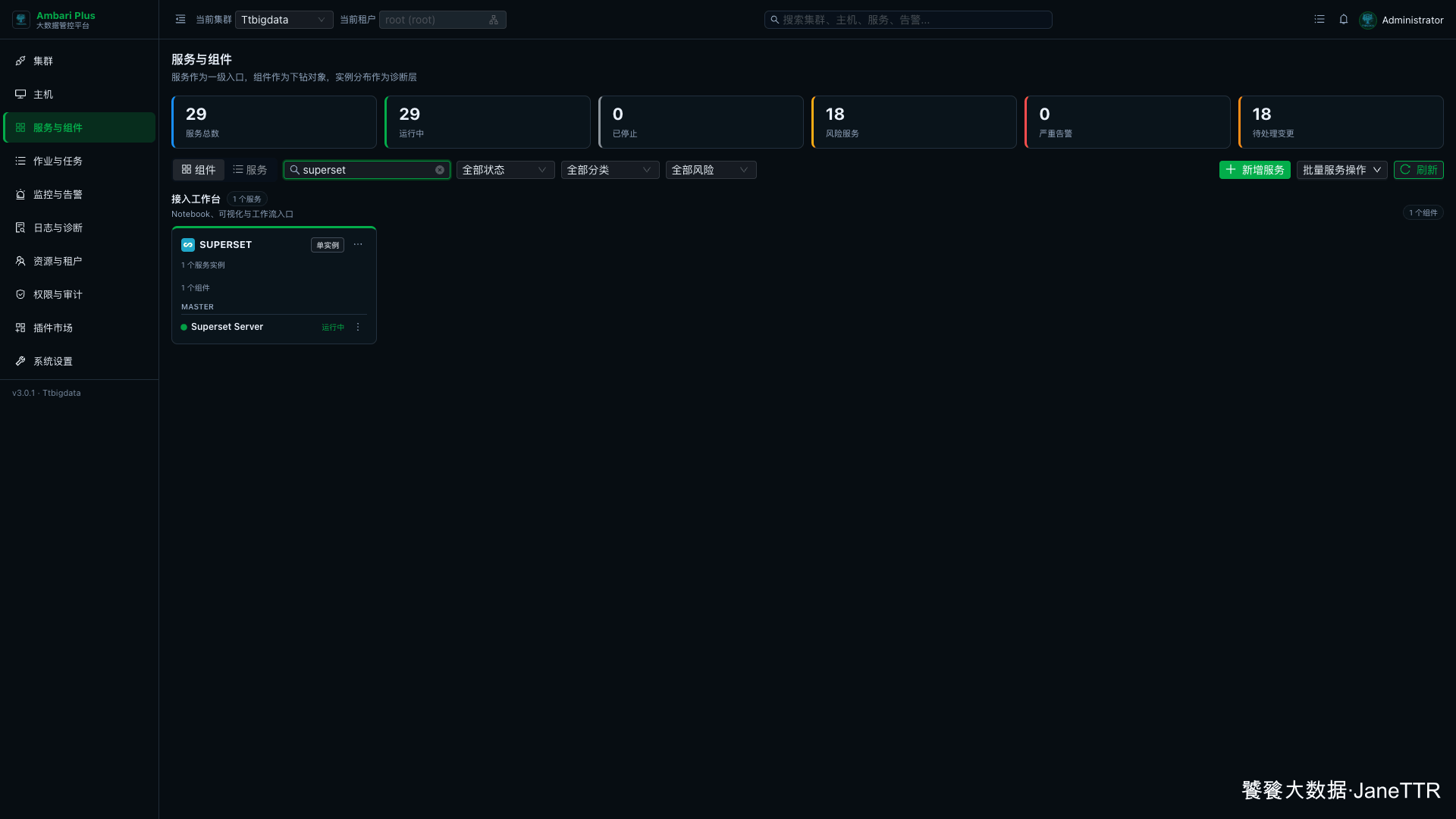
这一步我会重点确认三件事:
| 检查项 | 期望结果 |
|---|---|
| 服务总数 | 新增后服务总数增加到 29。 |
| Superset Server | 状态为“运行中”。 |
| 已停止服务 | 数量为 0。 |
如果卡片显示“已停止”,进入服务操作里启动 Superset。启动失败时,优先看 hadoop1.test.com 上的 Superset 日志和数据库连接配置。
# 10. 访问 Superset Web 页面
Superset 默认监听端口是 18088,浏览器访问:
http://hadoop1.test.com:18088/
能看到 Superset 登录页,就说明 Web 入口已经起来。
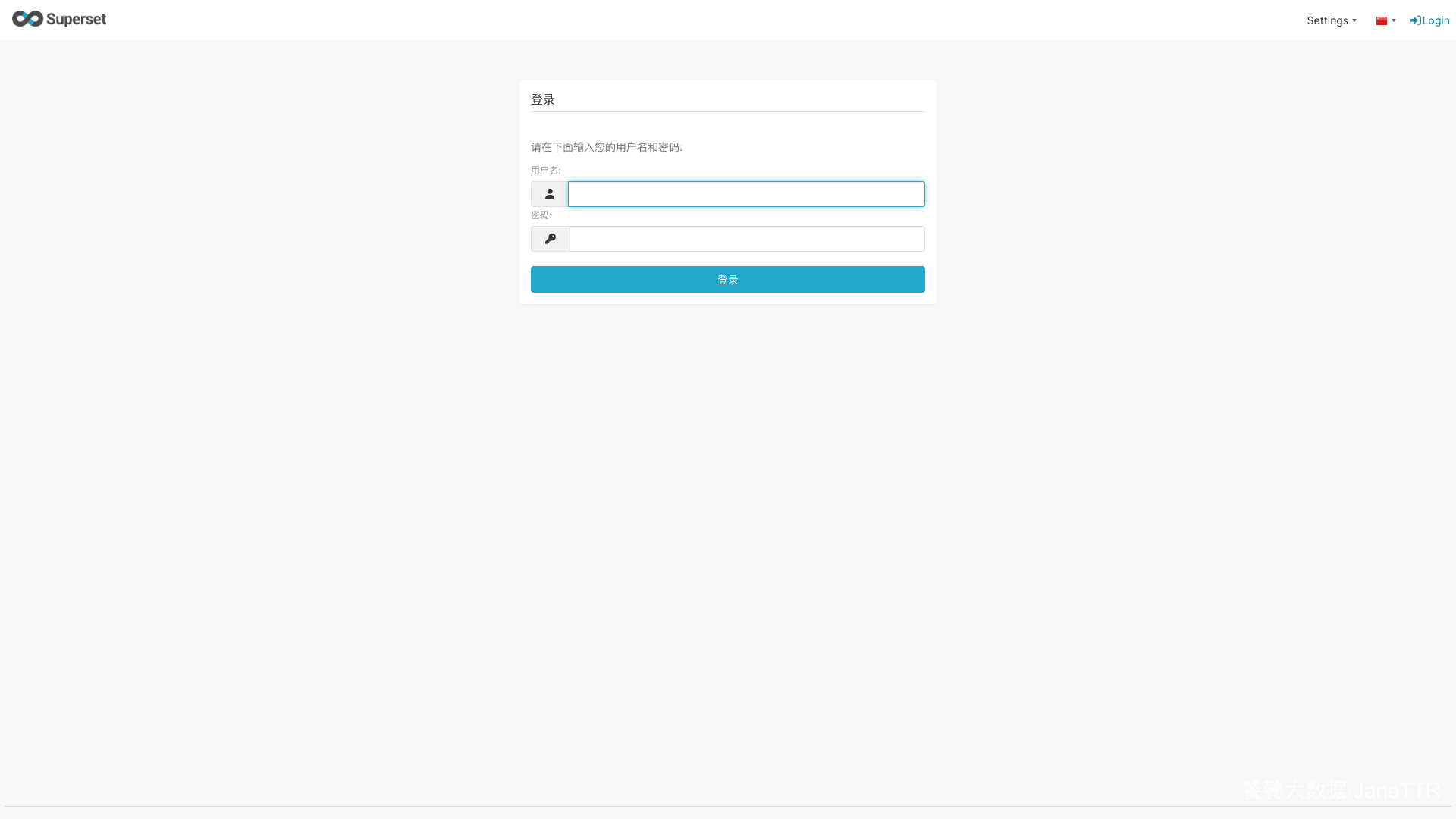
演示环境里初始管理员使用默认的 admin / admin。第一次登录后建议马上修改密码,生产环境更不要保留默认密码。
登录后进入 Superset Home 页面,可以看到看板、图表、数据集、SQL 等入口。
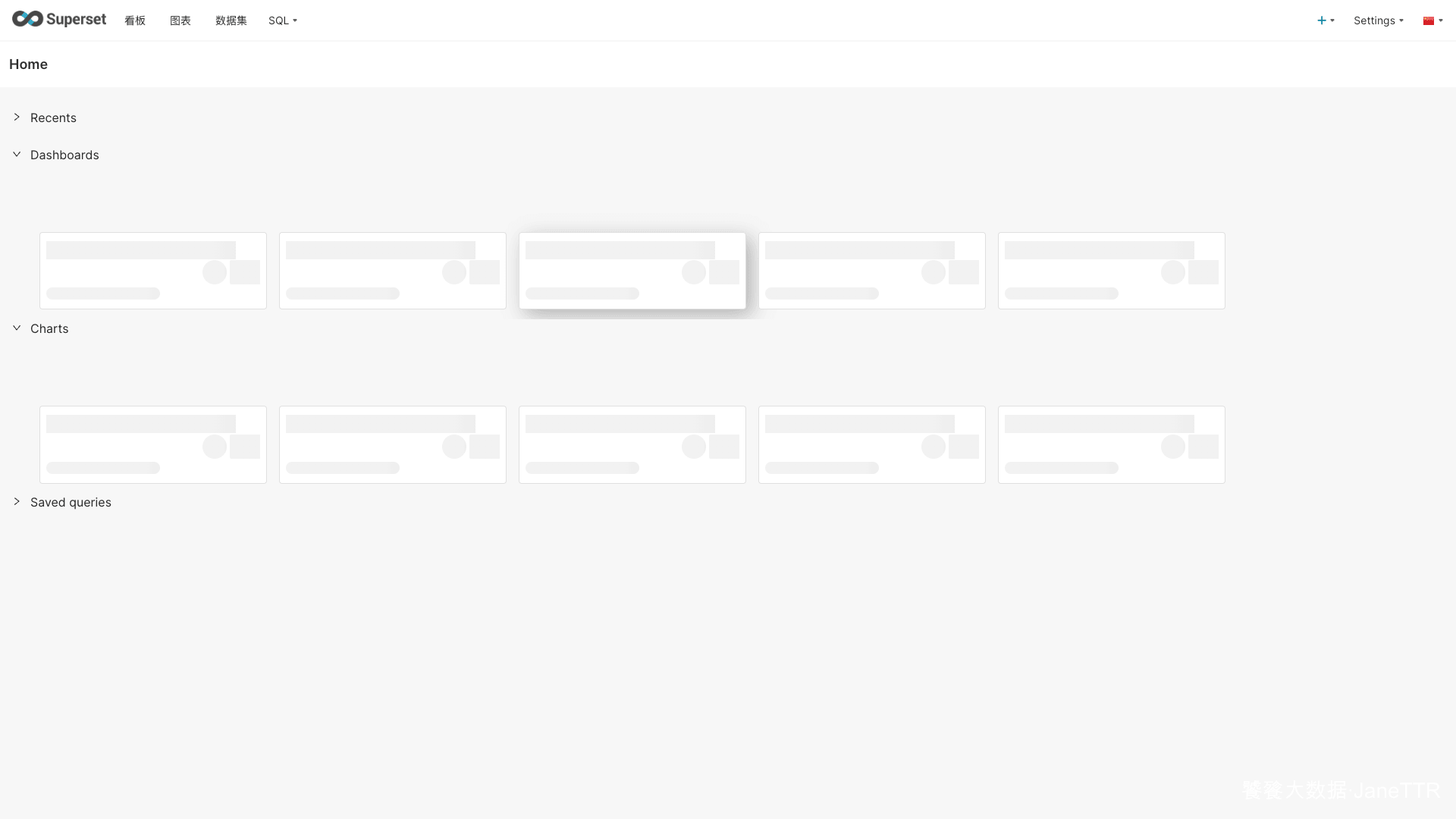
到这里,Superset 的基础安装完成。下一篇继续安装 Alluxio,给集群补一个数据编排与缓存层。