 Livy 安装0.7.1
Livy 安装0.7.1
# Livy 安装
Livy 是 Spark 的 REST 服务入口。它不会替代 Spark History Server,也不会自己负责资源调度;它的作用更像一个网关:外部系统通过 HTTP 提交 Spark Session、Statement 或批任务,Livy 再把任务交给 Spark on YARN。
我会把 Livy 放在 Spark 后面安装。前面已经完成 HDFS、YARN、Hive、Spark,并且集群已经开启 Kerberos,所以 Livy 安装时重点看三件事:LIVY_SERVER 放在哪台机器、Livy 是否继续使用 YARN cluster 模式、Kerberos 凭据是否能正常生成。
本次角色分配如下:
| 主机 | Livy 角色 |
|---|---|
hadoop1.test.com | LIVY_SERVER |
hadoop2.test.com | 无 Livy 组件 |
hadoop3.test.com | 无 Livy 组件 |
Livy 不需要单独的元数据库,也没有 Slave / Client 组件。第一次安装建议单独勾选 Livy,不要和 Zeppelin、Superset、Atlas 这类组件混在一个向导里安装,排查会更清楚。
# 1. 选择 Livy 服务
进入 服务与组件,点击 新增服务,在增强组件列表里勾选 Livy。
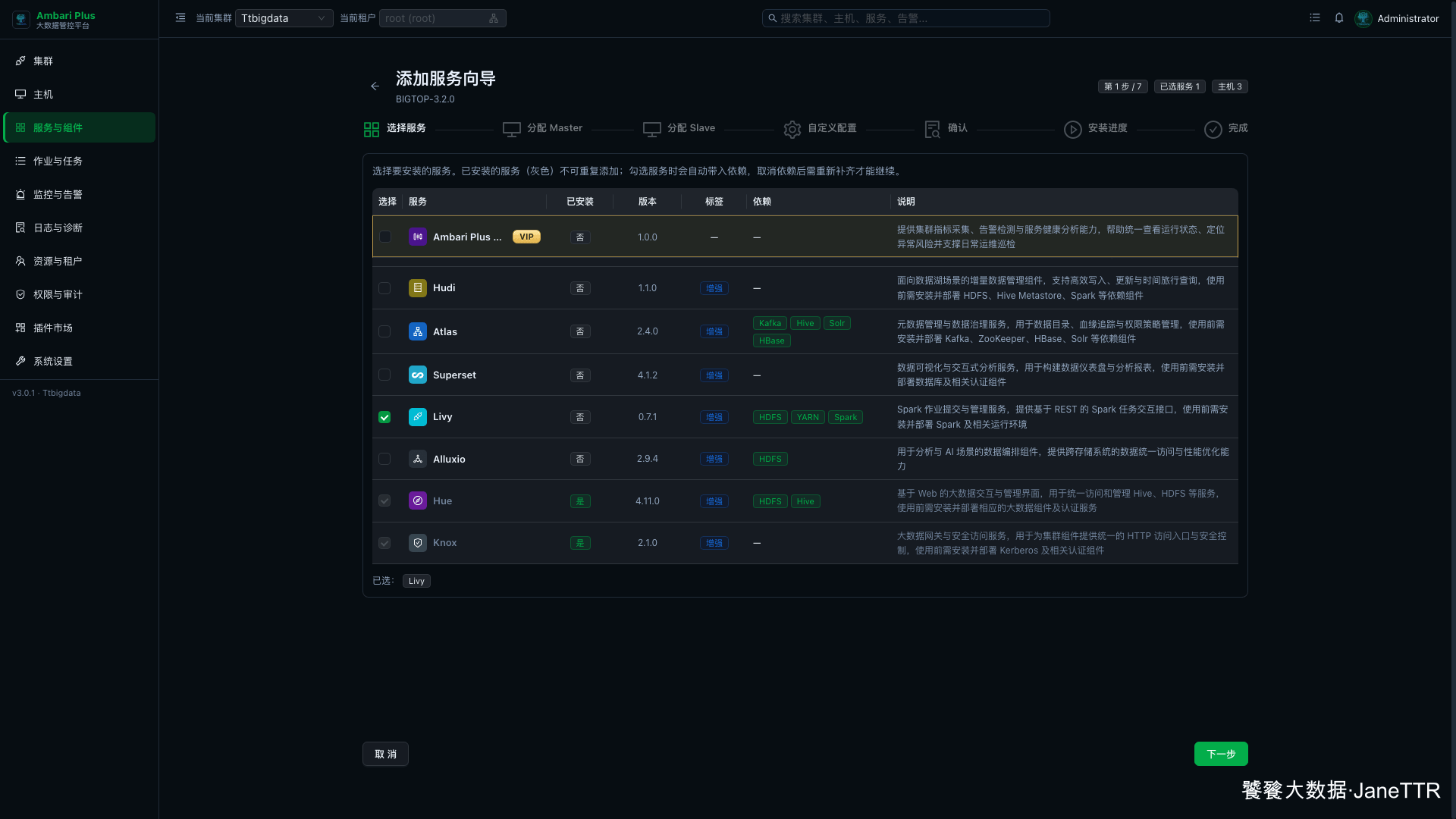
页面会显示 Livy 依赖 HDFS、YARN、Spark。如果这三个服务没有先装好,Livy 即使能进入向导,后面启动和作业提交也容易失败。
本篇环境里三项依赖都已经运行中,勾选 Livy 后直接点击 下一步。
# 2. 分配 Livy Server
Master 分配页里,Livy 只有一个常驻角色:LIVY_SERVER。
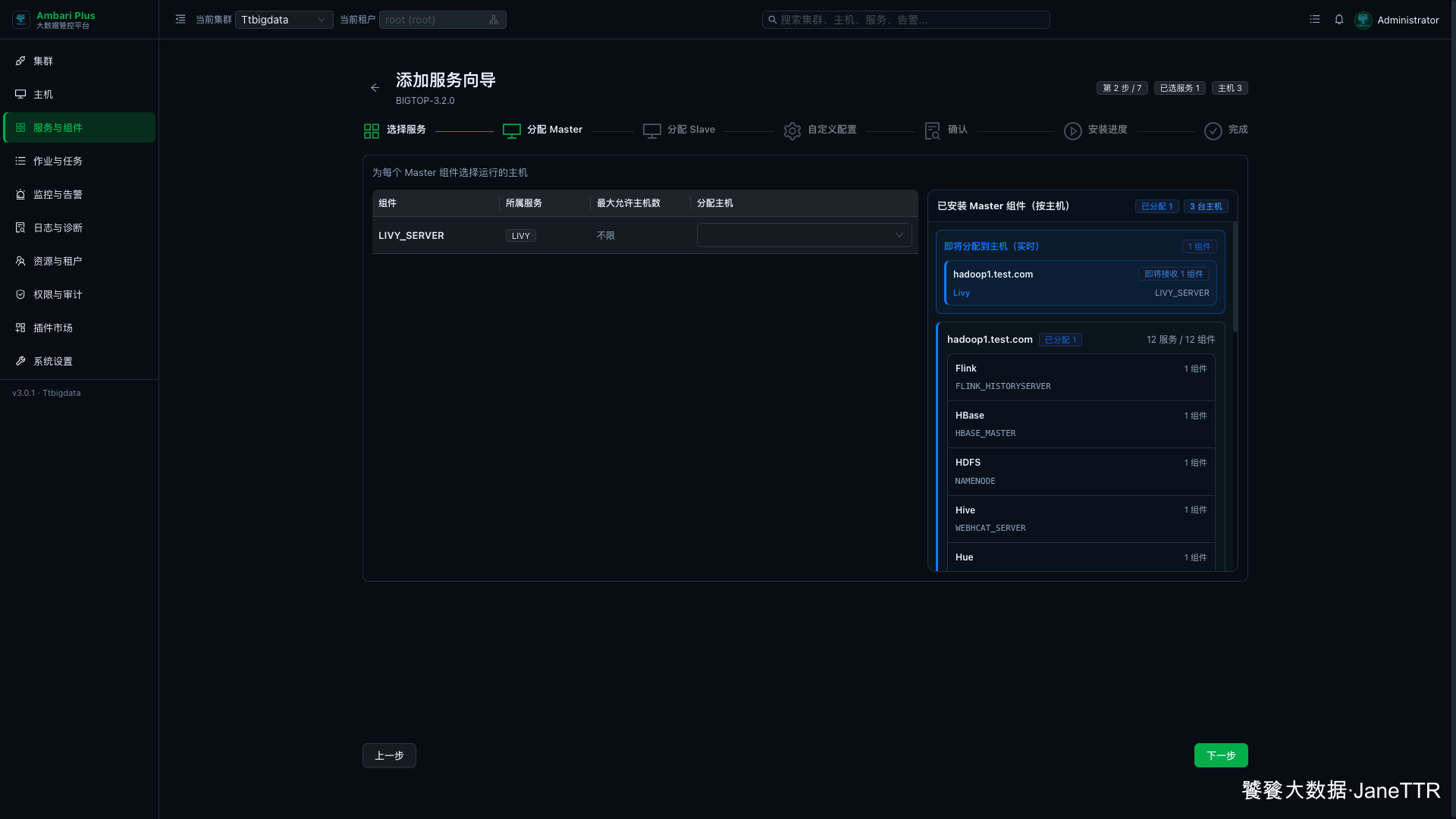
本次把它放在 hadoop1.test.com:
| 组件 | 主机 | 说明 |
|---|---|---|
LIVY_SERVER | hadoop1.test.com | 提供 Spark REST 会话与任务提交入口。 |
小集群里把 Livy 放在主节点比较直观,后续接 Knox 或外部 Notebook 时也方便定位入口。生产环境如果 Livy 会承载大量并发 Session,可以再规划独立节点和反向代理。
# 3. 确认没有 Slave 和 Client
Livy 在这套栈里没有 Slave 组件,也没有 Client 组件。
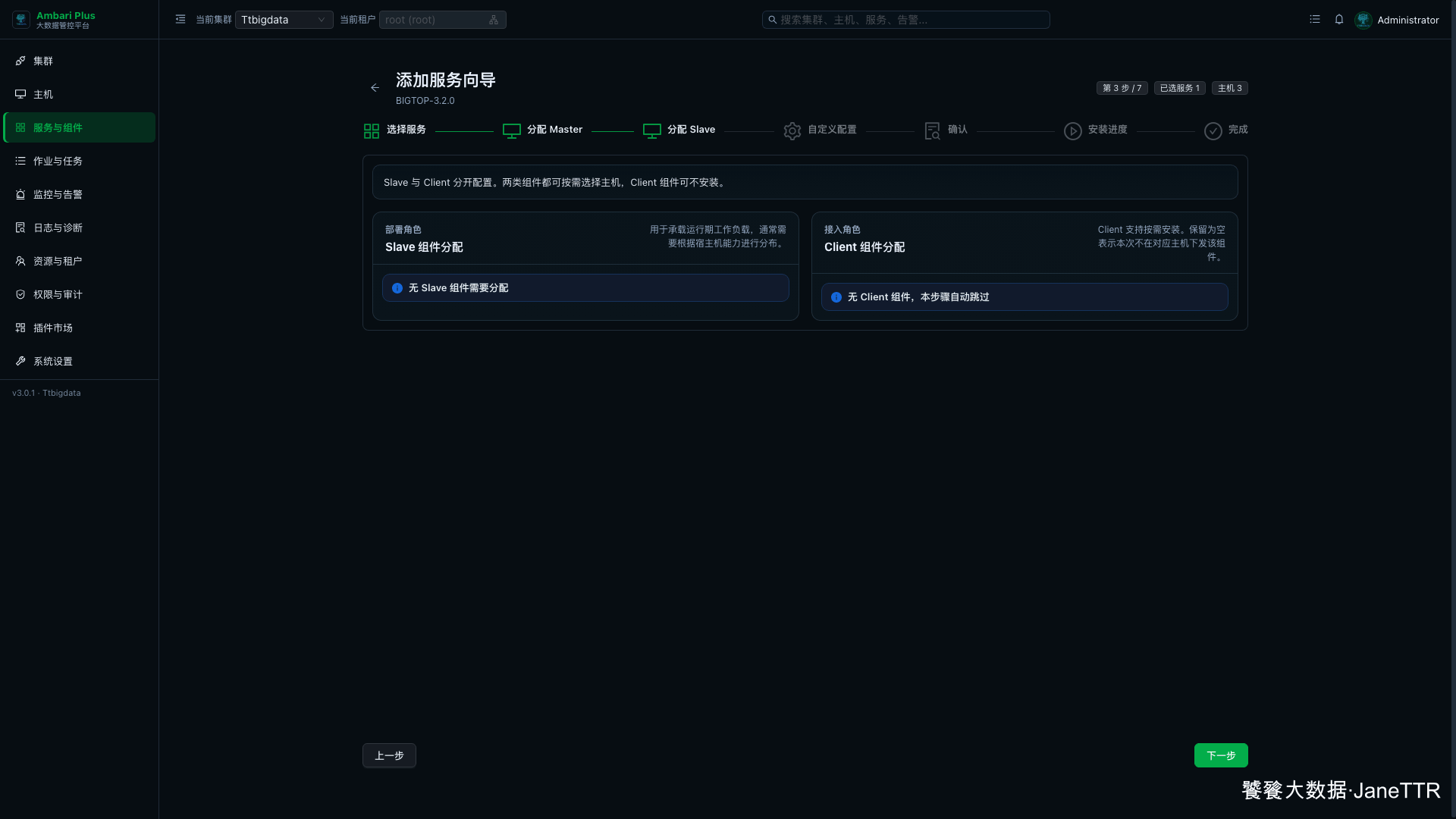
这一页看到 无 Slave 组件需要分配、无 Client 组件,本步骤自动跳过 就可以继续。Livy 的可用性主要取决于 Server 端配置、Spark 依赖和 Kerberos 凭据。
# 4. 检查 Livy 核心配置
进入自定义配置页后,先确认顶部状态:待填写 0。这说明安装向导已经把必填项补齐。
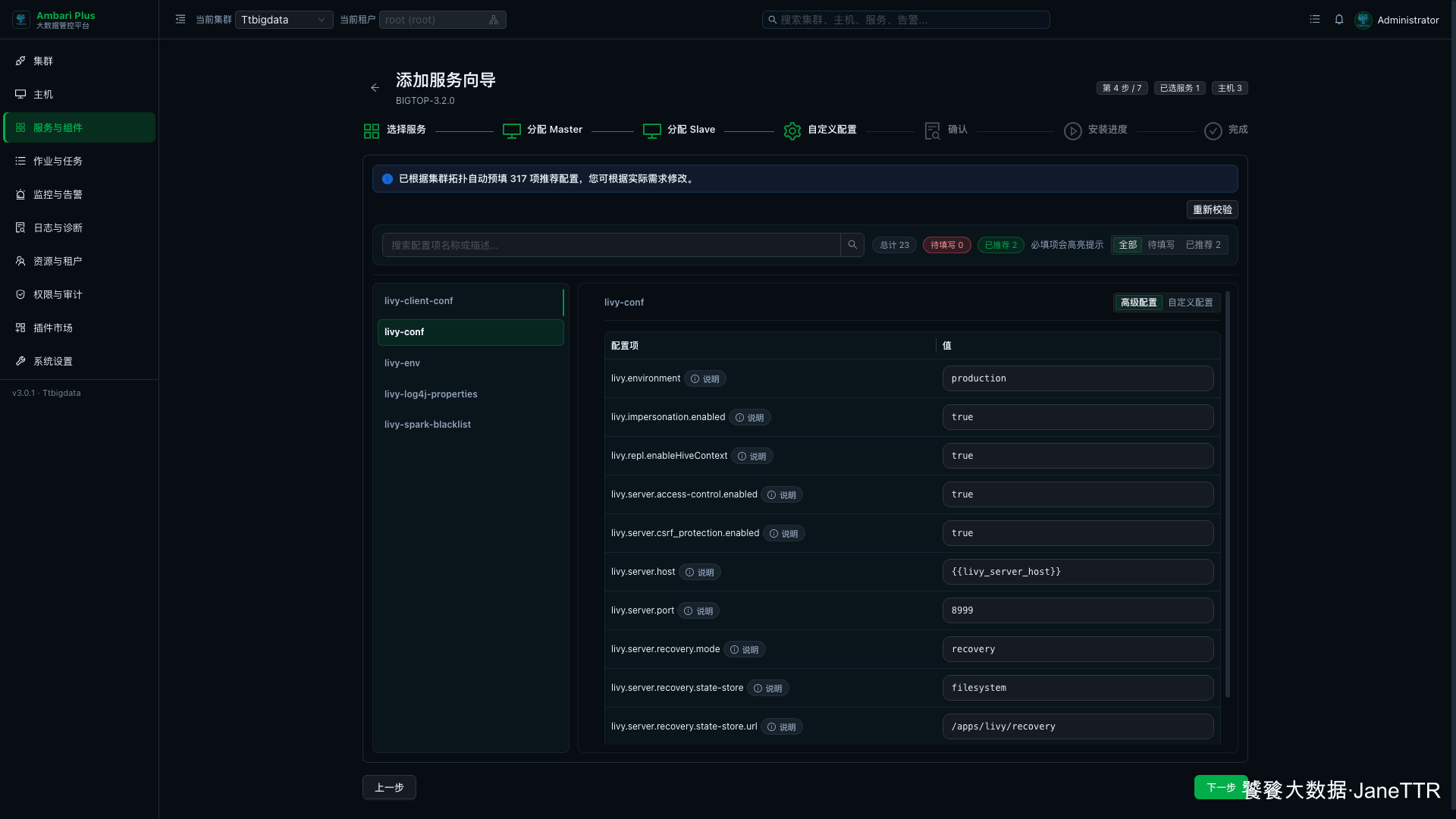
这一屏先看端口和恢复目录:
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
livy.server.port | 8999 | Livy Server 的 HTTP 端口。 |
livy.server.host | | 由安装向导根据 Master 分配自动渲染。 |
livy.server.recovery.mode | recovery | 开启会话恢复。 |
livy.server.recovery.state-store | filesystem | 使用文件系统保存恢复信息。 |
livy.server.recovery.state-store.url | /apps/livy/recovery | 恢复状态存放路径。 |
继续往下看 Spark 运行模式:
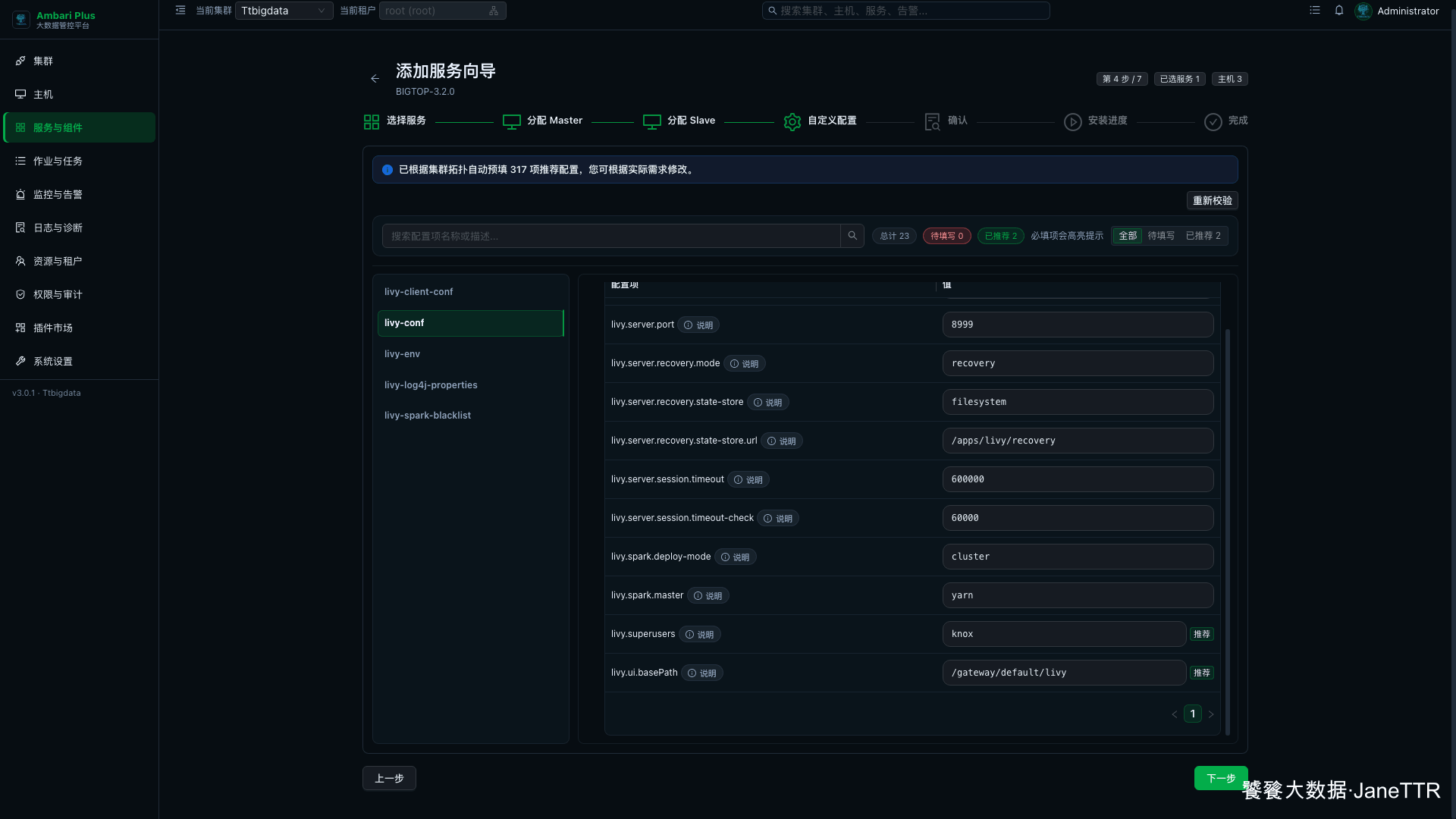
这里我会重点确认这几项:
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
livy.spark.master | yarn | Livy 提交 Spark 作业时走 YARN。 |
livy.spark.deploy-mode | cluster | Driver 运行在 YARN 集群中。 |
livy.impersonation.enabled | true | 允许按提交用户进行代理。 |
livy.superusers | knox | 给 Knox 代理入口预留超级用户能力。 |
livy.ui.basePath | /gateway/default/livy | 后续接 Knox 时使用的路径。 |
第一次安装先保留推荐值。等 Livy 跑通后,再根据实际使用方式调整 Session 超时、并发会话数、黑名单配置和 Knox 代理路径。
# 5. 确认安装清单
确认页会汇总本次新增服务、角色分配和配置校验结果。
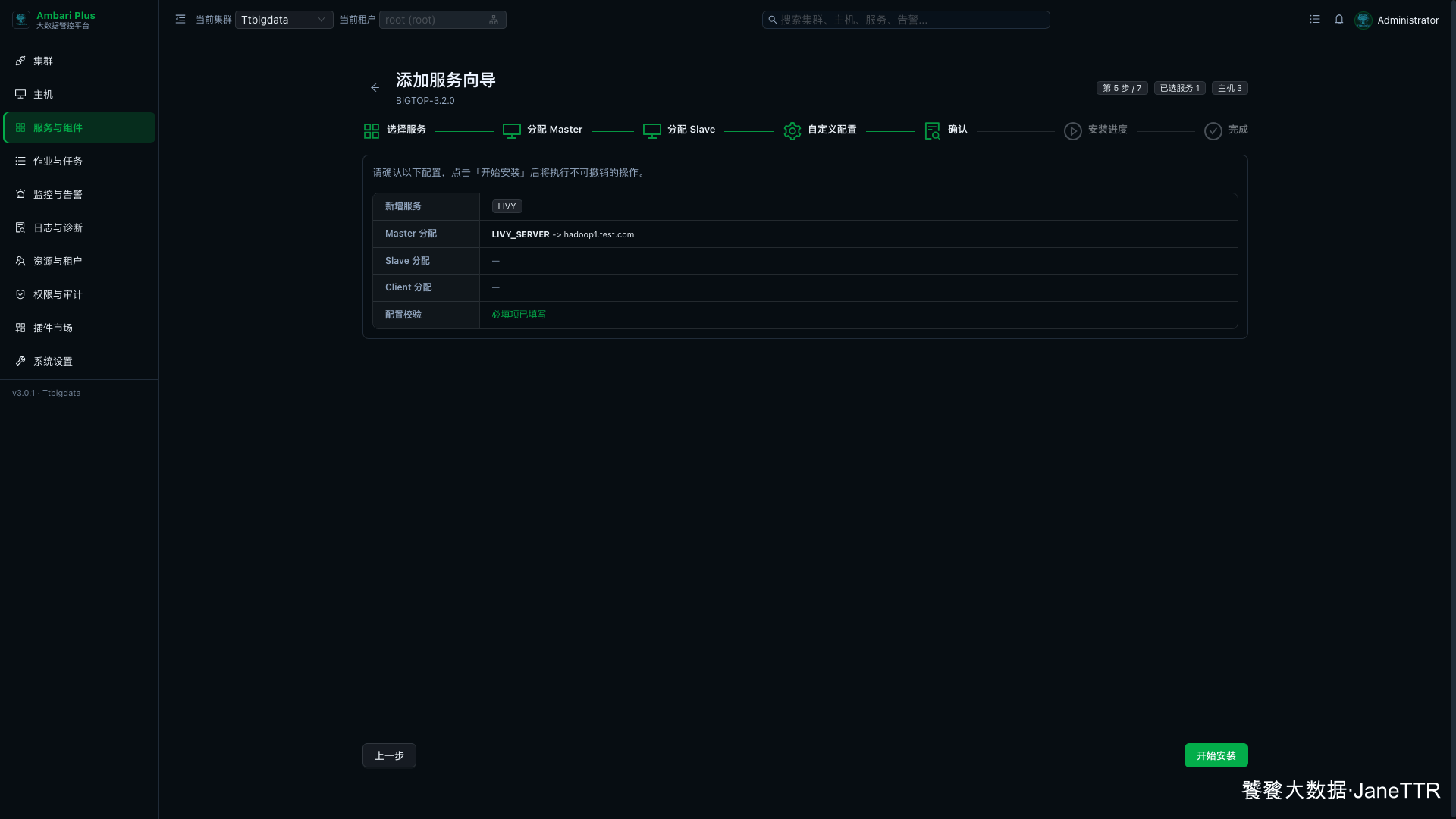
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | LIVY |
| Master 分配 | LIVY_SERVER -> hadoop1.test.com |
| Slave 分配 | 无 |
| Client 分配 | 无 |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 6. 提交 Kerberos 授权并等待完成
开启 Kerberos 的集群中,新增 Livy 会要求提交 KDC 管理员凭据。这里填写的是 KDC 管理员 Principal 和密码,用于生成 Livy 的 principal / keytab,不是 Ambari 登录密码,也不是某个组件数据库密码。
提交凭据后,向导会继续执行安装、凭据分发和服务启动。安装完成时可以看到 LIVY 已成功安装。
如果这一步失败,我会优先看两类问题:
| 现象 | 常见原因 | 处理方向 |
|---|---|---|
| KDC 凭据提交失败 | Principal 或密码不对 | 重新确认 KDC 管理员账号。 |
| Livy Server 启动失败 | Spark、YARN、HDFS 客户端配置未就绪 | 回到前面组件检查服务状态和 Kerberos keytab。 |
# 7. 回到服务列表确认状态
回到 服务与组件 页面,Livy 会出现在 资源计算 分类下。
页面里可以看到:
| 组件 | 状态 |
|---|---|
Livy Server | 运行中 |
在服务端也可以确认 8999 端口已经监听:
ss -lntp | grep 8999
正常会看到 hadoop1.test.com 对应地址上的 8999 处于监听状态,进程名为 java。
到这里,Livy 的基础安装完成。下一篇可以继续安装 Zeppelin,把 Notebook 入口接到已经跑通的 HDFS、YARN、Spark 和 Livy 之上。