 Celeborn 安装0.5.3
Celeborn 安装0.5.3
# Celeborn 安装
Celeborn 是分布式 Shuffle 服务,常见用途是把 Spark 等计算引擎里的 Shuffle 数据从 Executor 本地磁盘里拆出来,交给独立服务承接。集群任务量上来后,这个组件的价值会更明显:Executor 重启、动态伸缩、磁盘压力和大 Shuffle 场景,都会比纯本地 Shuffle 更容易治理。
本篇继续沿用三台 FQDN 主机:
| 主机 | Celeborn 角色 |
|---|---|
hadoop1.test.com | CELEBORN_MASTER、CELEBORN_WORKER、CELEBORN_CLIENT |
hadoop2.test.com | CELEBORN_WORKER、CELEBORN_CLIENT |
hadoop3.test.com | CELEBORN_WORKER、CELEBORN_CLIENT |
这里把 Master 放在 hadoop1.test.com,Worker 覆盖三台机器,Client 也分发到三台机器。这样后续 Spark、Flink 或其他计算服务接入时,每台节点上都能拿到 Celeborn 客户端配置。
提示
Celeborn 的服务安装完成,不代表 Spark 已经自动使用 Celeborn。安装服务只是把 Master、Worker、Client 部署好;真正让 Spark 任务走远端 Shuffle,还需要后续在 Spark 配置里接入 Celeborn 的 Shuffle Manager 和 Master 地址。
# 1. 选择 Celeborn 服务
进入 服务与组件,点击 新增服务,在增强组件列表里勾选 Celeborn。
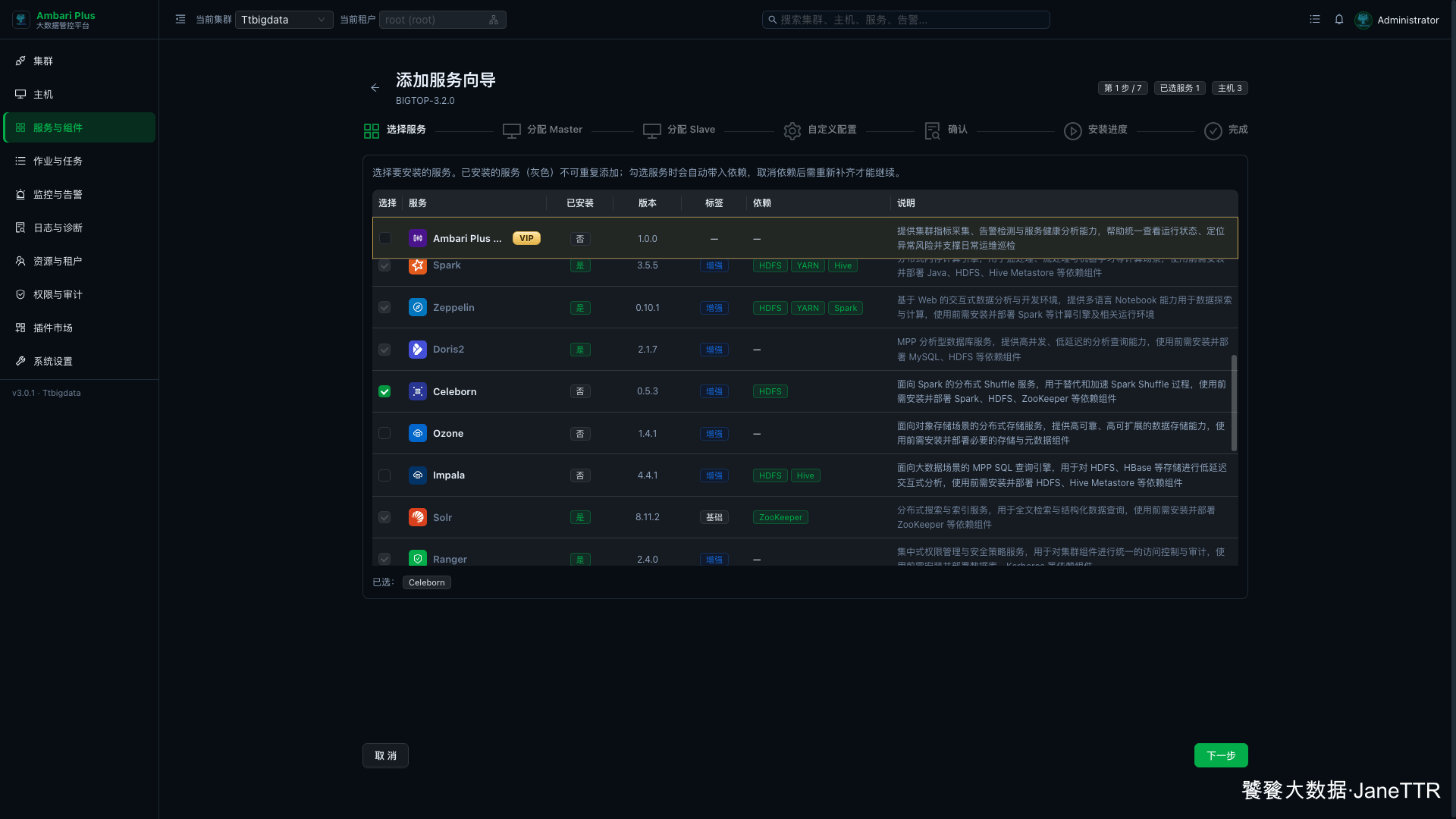
本篇只安装 Celeborn。分布式 Shuffle 组件安装时会改动多台主机的 Worker 和 Client,建议单独跑一遍,失败时也更容易定位到是哪台机器、哪个角色的问题。
# 2. 分配 Celeborn Master
Master 分配页里会出现 CELEBORN_MASTER。
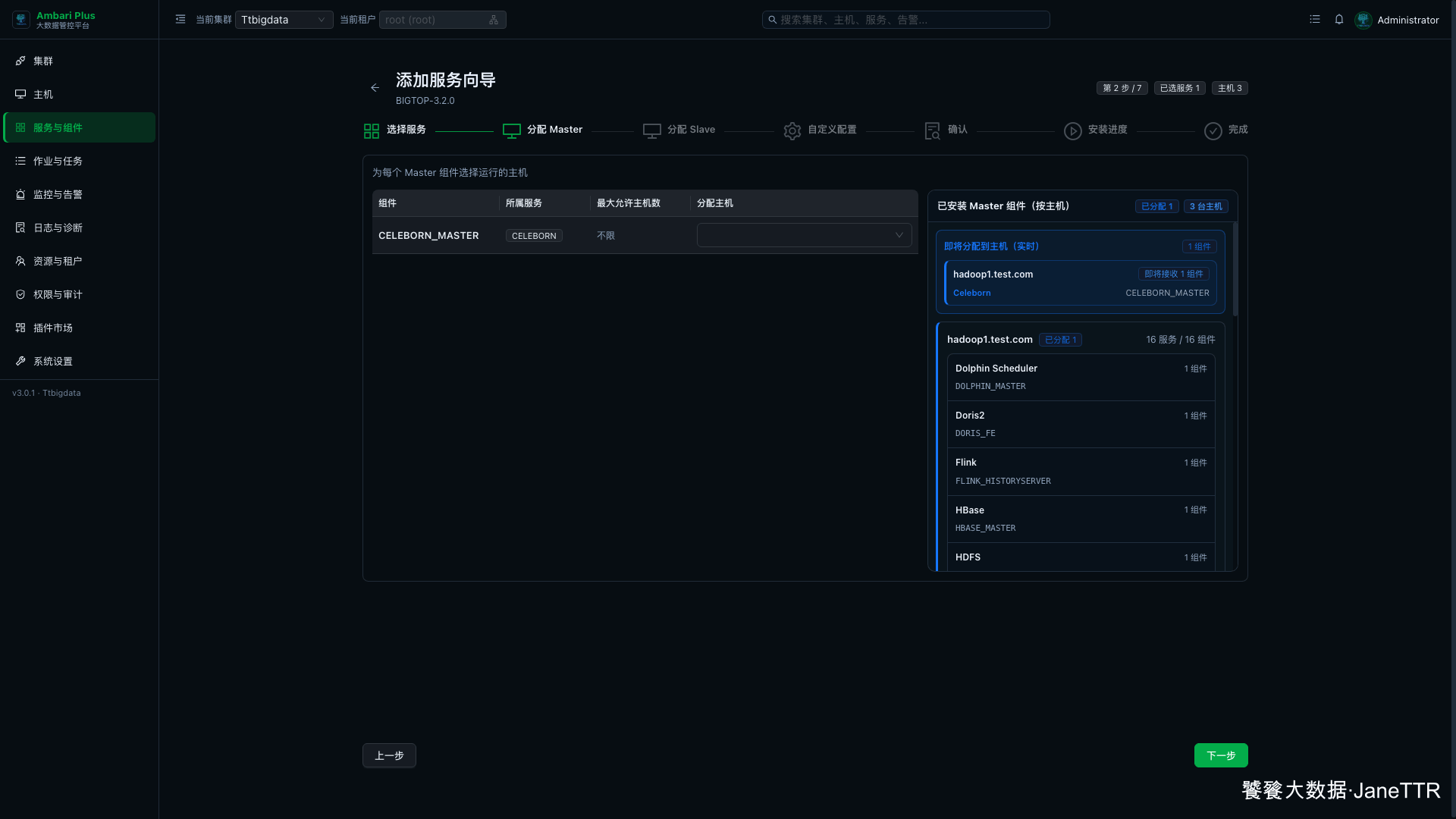
本次把 Master 放在 hadoop1.test.com:
| 组件 | 主机 | 说明 |
|---|---|---|
CELEBORN_MASTER | hadoop1.test.com | 负责 Worker 注册、心跳和 Shuffle 元数据调度。 |
如果是生产环境,我更建议把 Master 高可用提前规划好,避免单 Master 成为控制面单点。教程环境先用单 Master 跑通链路,后面再根据业务规模扩展。
# 3. 分配 Worker 和 Client
Slave 分配页里会同时看到 CELEBORN_WORKER 和 CELEBORN_CLIENT。
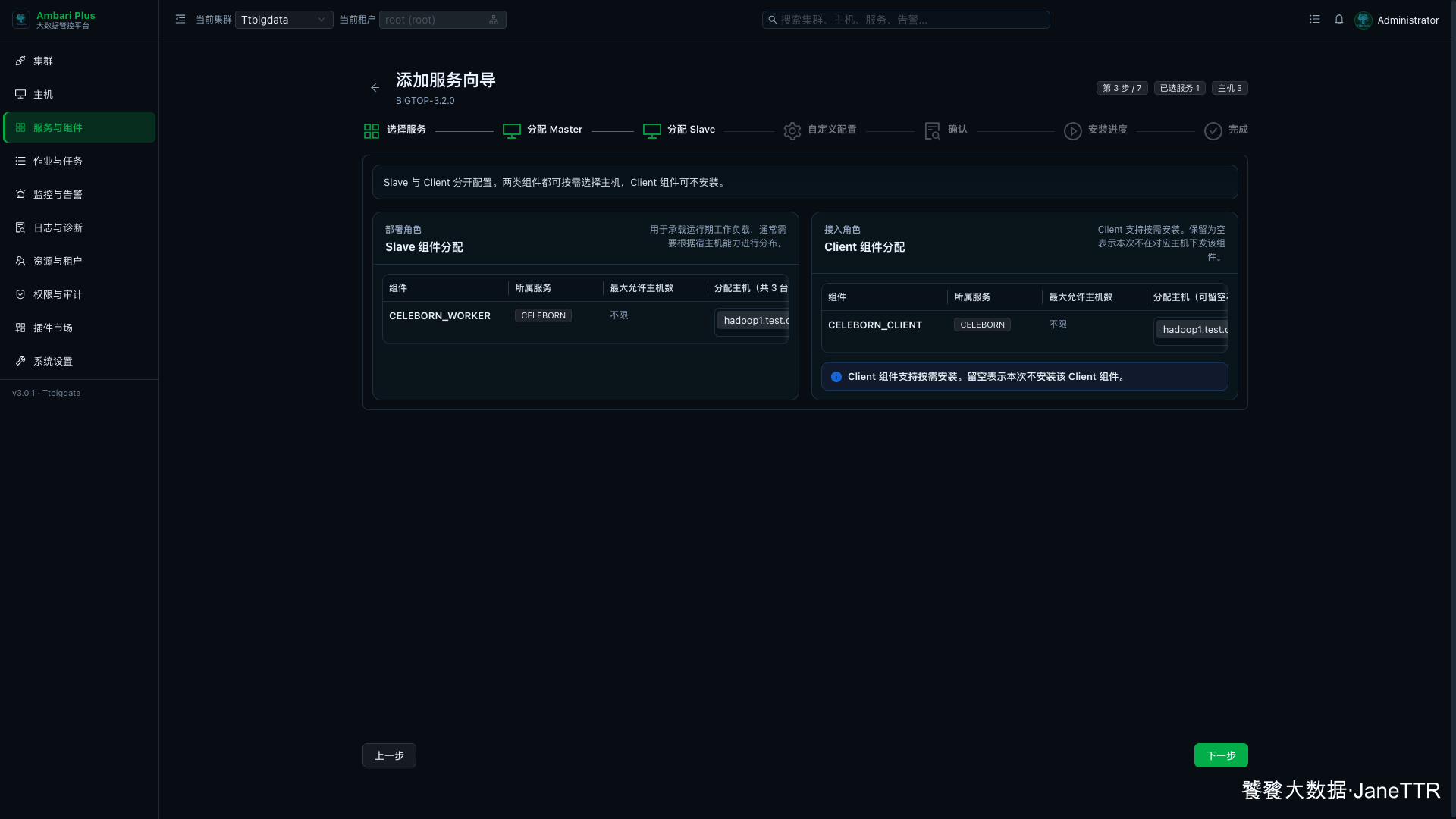
本次分配如下:
| 组件 | 分配主机 | 说明 |
|---|---|---|
CELEBORN_WORKER | 三台主机 | 承接 Shuffle 数据写入和读取。 |
CELEBORN_CLIENT | 三台主机 | 给计算服务提供客户端配置和依赖。 |
Worker 覆盖三台主机后,Shuffle 数据不会只压在单机上。Client 也建议全量分发,后面 Spark、Flink、YARN 任务在哪台机器启动,都能读取到 Celeborn 客户端配置。
# 4. 检查 celeborn-defaults 配置
进入自定义配置页后,先看顶部状态。这里 待填写 0,说明必填项已经满足;不过 Celeborn 的端口和存储目录仍然建议逐项确认。
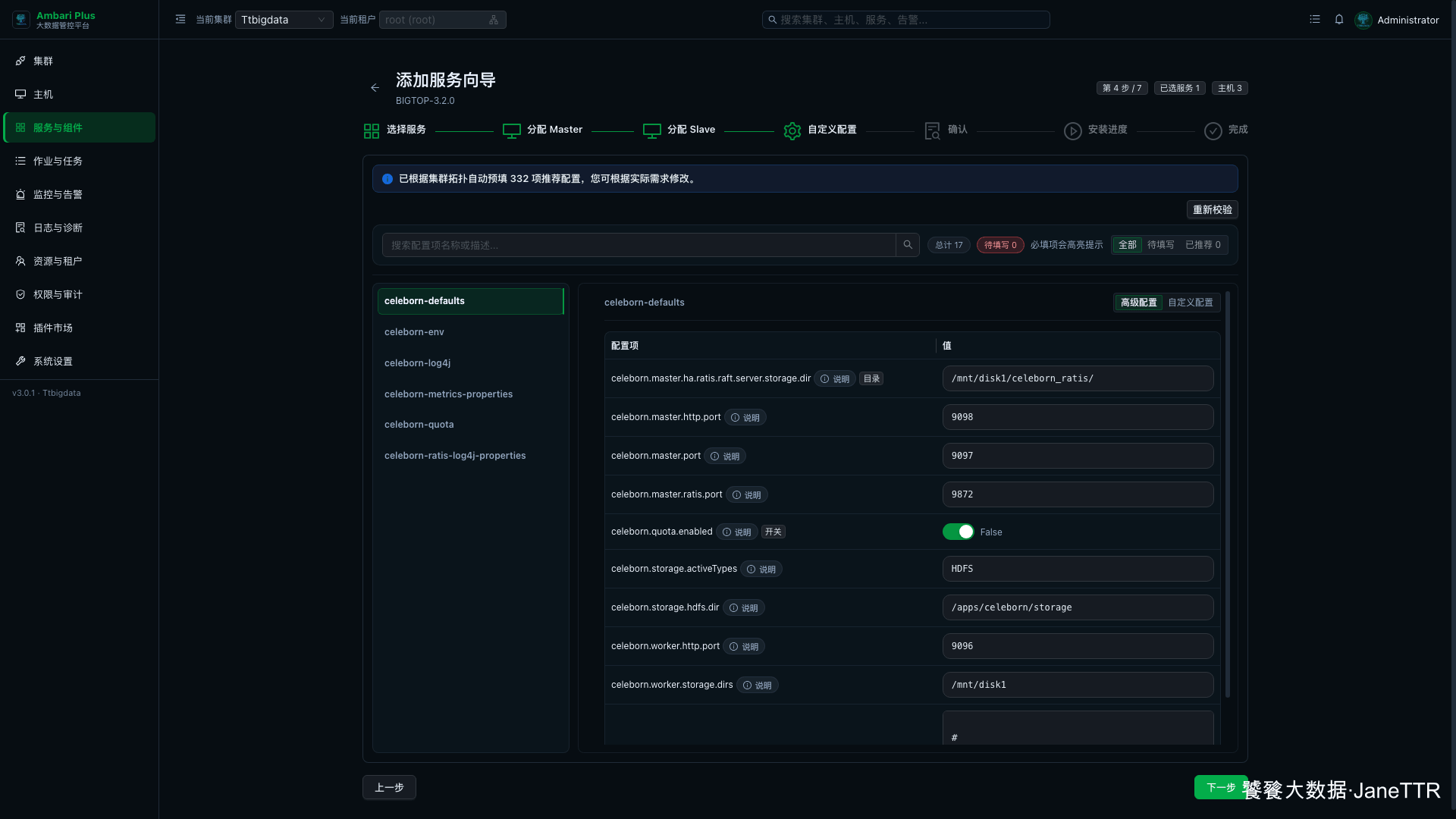
这页重点看下面几项:
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
celeborn.master.port | 9097 | Master RPC 服务端口。 |
celeborn.master.http.port | 9098 | Master HTTP 页面端口。 |
celeborn.master.ratis.port | 9872 | Master HA 相关端口。 |
celeborn.storage.activeTypes | HDFS | 本次使用 HDFS 作为远端存储类型。 |
celeborn.storage.hdfs.dir | /apps/celeborn/storage | Celeborn 写入 HDFS 的存储目录。 |
celeborn.worker.http.port | 9096 | Worker HTTP 服务端口。 |
celeborn.worker.storage.dirs | /mnt/disk1 | Worker 本地存储目录。 |
celeborn.worker.storage.dirs 最好提前结合磁盘规划确认。教程环境用 /mnt/disk1,生产环境建议使用独立数据盘,并确认目录权限、磁盘容量和文件系统稳定性。
# 5. 检查 celeborn-env 配置
再切到 celeborn-env,确认日志目录和 PID 目录。
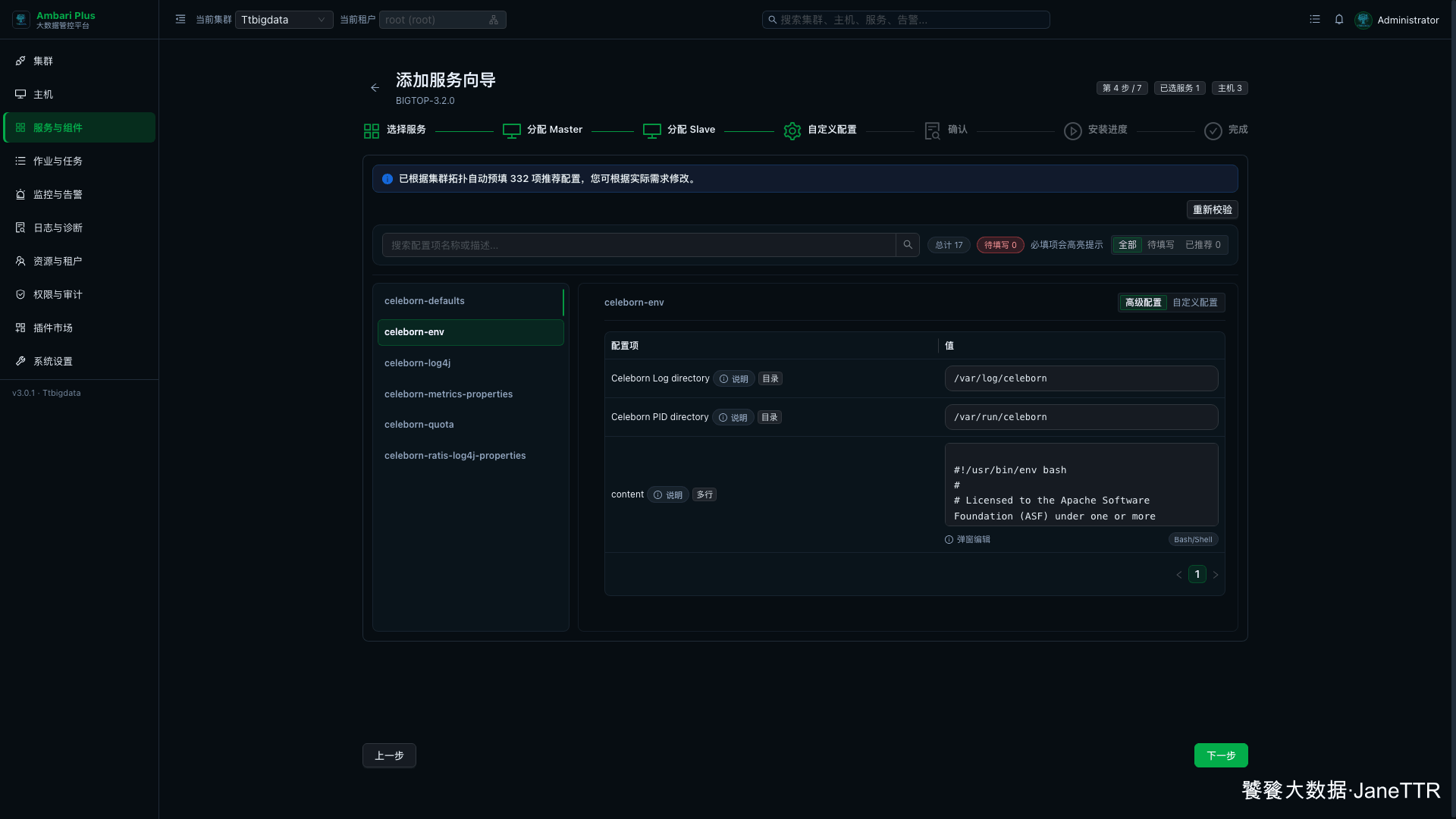
| 配置项 | 本次示例值 | 说明 |
|---|---|---|
Celeborn Log directory | /var/log/celeborn | Master、Worker 日志目录。 |
Celeborn PID directory | /var/run/celeborn | 进程 PID 文件目录。 |
这两个目录看起来不起眼,但排障时很关键。安装失败或服务启动异常时,我会先看对应主机上的 Celeborn 日志,再结合 Ambari 任务日志判断是包安装、目录权限、端口占用还是 Kerberos 凭据问题。
# 6. 确认安装清单
确认页会把新增服务、Master 分配、Slave 分配、Client 分配和配置校验集中列出来。
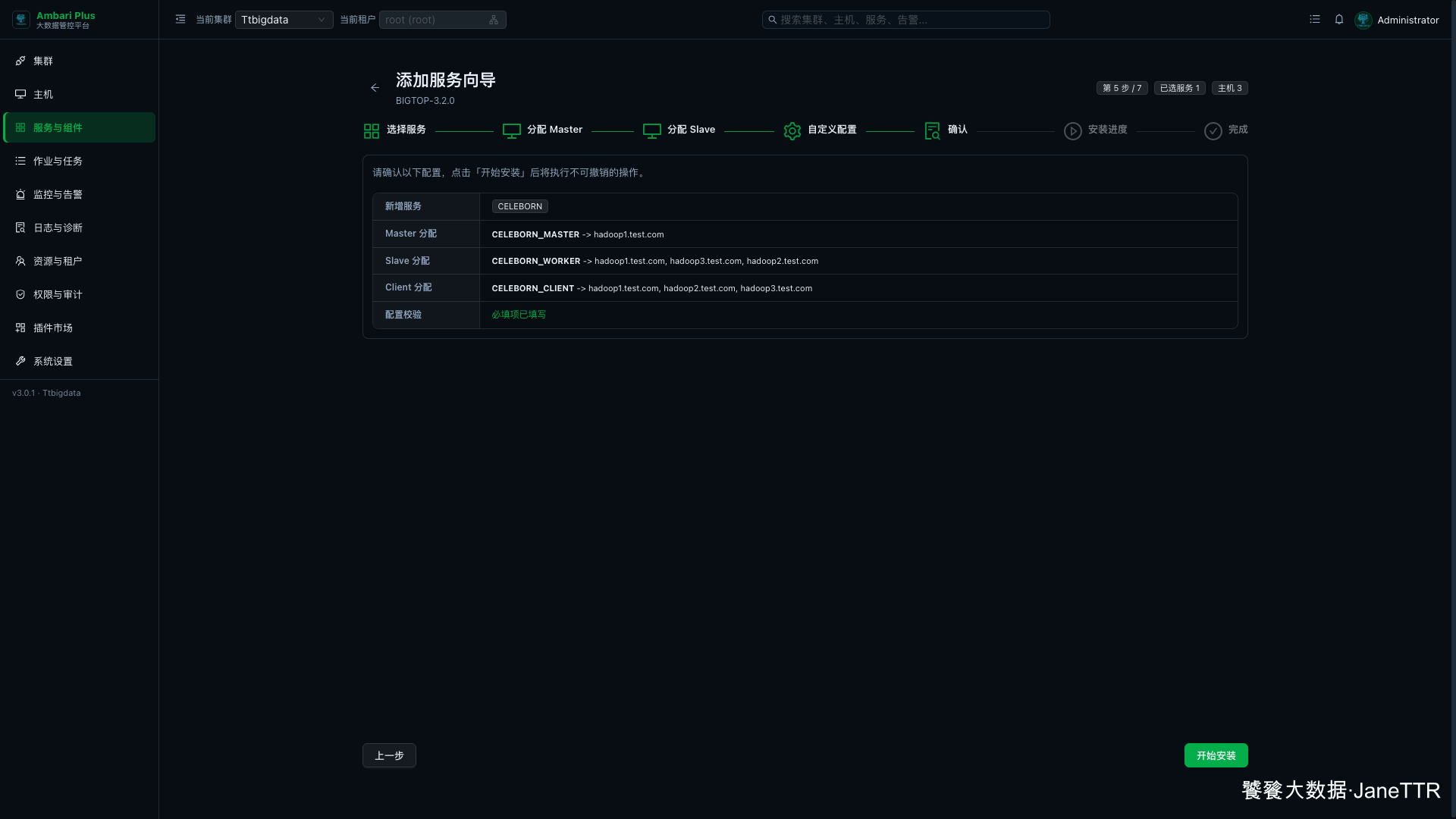
本次确认结果如下:
| 检查项 | 本次结果 |
|---|---|
| 新增服务 | CELEBORN |
| Master 分配 | CELEBORN_MASTER -> hadoop1.test.com |
| Slave 分配 | CELEBORN_WORKER -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| Client 分配 | CELEBORN_CLIENT -> hadoop1.test.com, hadoop2.test.com, hadoop3.test.com |
| 配置校验 | 必填项已填写 |
确认无误后点击 开始安装。
# 7. 等待 Celeborn 安装完成
开启 Kerberos 的集群中,新增 Celeborn 时会要求提交 KDC 管理员凭据。这里填写的是 KDC 管理员 Principal 和密码,用于生成并分发 Celeborn 相关 principal / keytab。
安装任务会依次完成软件包安装、配置下发、Kerberos 凭据生成和服务启动。完成页显示 CELEBORN 后,就可以返回服务列表。
如果安装过程中失败,先展开失败主机的任务日志。Celeborn 常见问题主要集中在三类:Worker 本地目录不存在或不可写、端口被占用、Kerberos 凭据生成失败。
# 8. 回到服务列表确认状态
回到 服务与组件 页面,Celeborn 会出现在 其他服务 分类下。
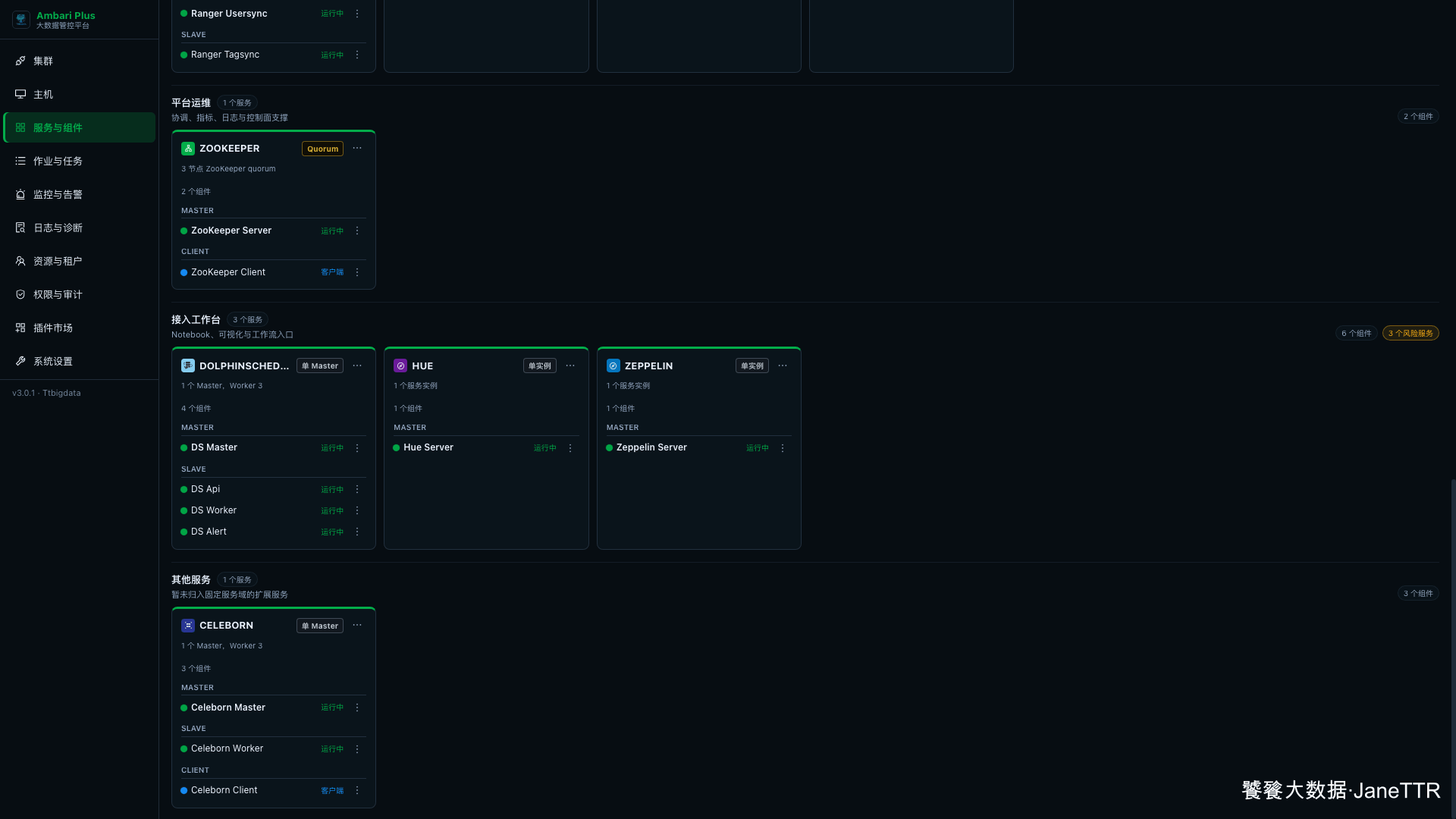
页面里可以看到:
| 组件 | 数量 | 状态 |
|---|---|---|
Celeborn Master | 1 | 运行中 |
Celeborn Worker | 3 | 运行中 |
Celeborn Client | 3 | 客户端 |
如果想在命令行再看一眼端口,可以在 hadoop1.test.com 上确认 Master 和本机 Worker 端口:
ss -lntp | egrep ':(9097|9098|9096)\b'
能看到 9097、9098 和 9096 处于监听状态,就说明 Celeborn Master 与本机 Worker 已经起来。后面接入 Spark 时,重点配置 Master 地址,例如 hadoop1.test.com:9097,再结合计算引擎自己的 Shuffle 配置做验证。
到这里,Celeborn 的基础安装完成。下一篇继续安装 Ozone,把对象存储和 S3 Gateway 这条链路补上。